Omówienie projektu dystrybucji tabel
Gdy dane są ładowane do dedykowanych pul SQL usługi Synapse Analytics, zestawy danych są podzielone i rozproszone między węzłami obliczeniowymi na potrzeby przetwarzania, a następnie zapisywane w oddzielonej i skalowalnej warstwie magazynu. Ta akcja jest określana jako fragmentowanie.
Decyzje projektowe dotyczące dzielenia i rozpraszania tych danych między węzłami, a następnie do magazynu są ważne w przypadku wykonywania zapytań dotyczących obciążeń, ponieważ prawidłowy wybór minimalizuje przenoszenie danych, które jest główną przyczyną problemów z wydajnością w dedykowanym środowisku puli SQL usługi Azure Synapse.
Istnieją trzy główne dystrybucje tabel dostępne w pulach SQL usługi Synapse Analytics, które zostaną opisane poniżej:
Wybranie prawidłowej dystrybucji tabel może mieć wpływ na obciążenie danych i wydajność zapytań w następujący sposób:
Dystrybucja działania okrężnego
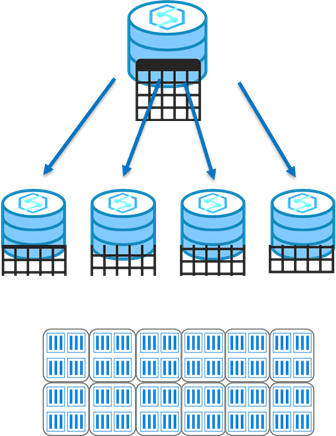
Jest to domyślna dystrybucja utworzona dla tabeli i zapewnia szybką wydajność podczas ładowania danych.
W tabeli dystrybuowanej przy użyciu działania okrężnego dane są dystrybuowane równomiernie w całej tabeli, bez dodatkowej optymalizacji. Rozkład jest najpierw wybierany losowo, a następnie wierszy są przypisywane do dystrybucji sekwencyjnie.
Ładowanie danych do tabeli okrężnej jest szybkie, ale wydajność zapytań może być często lepsza w przypadku tabel rozproszonych skrótów dla większych zestawów danych.
Sprzężenia w tabelach działania okrężnego mogą negatywnie wpływać na obciążenia zapytań, ponieważ dane zbierane do przetwarzania muszą zostać przetasowane w innych węzłach obliczeniowych, co wymaga dodatkowego czasu i przetwarzania.
Dystrybucja skrótów
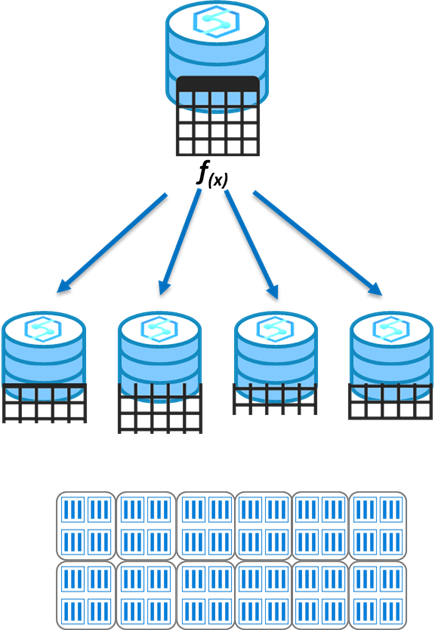
Ta dystrybucja może zapewnić najwyższą wydajność zapytań dla sprzężeń i agregacji w dużych tabelach.
Aby fragmentować dane, funkcja skrótu służy do deterministycznego przypisywania każdego wiersza do dystrybucji. W definicji tabeli jedna kolumna zostaje wyznaczona jako kolumna dystrybucji.
Istnieją zagadnienia dotyczące wydajności wyboru kolumny dystrybucji, takie jak odrębność, niesymetryczność danych i typy zapytań uruchamianych w systemie.
Zagadnienia dotyczące wydajności
Podczas wybierania kolumny skrótu najlepiej jest wybrać kolumnę, która równomiernie rozproszy dane we wszystkich dystrybucjach, co pozwoli na około taką samą liczbę wierszy w każdej dystrybucji.
- Wybierz kolumnę z dużą liczbą unikatowych wartości, na przykład jeśli organizacja może działać we wszystkich 50 stanach w Stany Zjednoczone, upewnij się, że masz dobrą dystrybucję każdego identyfikatora StateID, aby zapobiec niesymetryczności, która ma wpływ na czas zwracania poszczególnych wyników zapytania i wpływa na wydajność.
- Wybierz kolumnę bez wartości Null lub bardzo mało wartości null. Może to również spowodować brak równowagi danych w jednej dystrybucji.
- Nie wybieraj kolumny daty, ponieważ wszystkie dane dla określonej daty znajdą się w tym samym miejscu i jeśli jest to codzienny raport filtrujący użytkowników biznesowych przy użyciu tej samej daty, tylko 1 z 60 dystrybucji będzie ponosić większość obciążenia.
Tabele replikowane
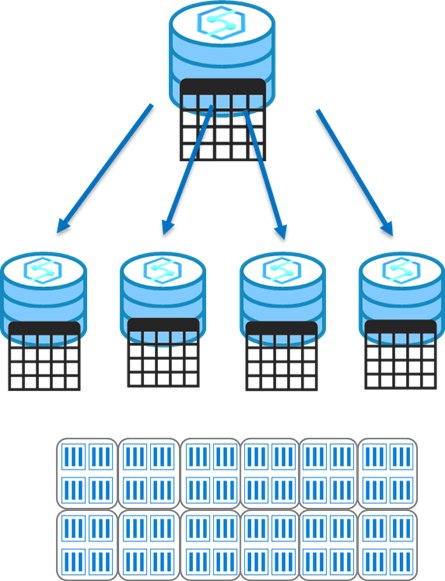
Tabela replikowana zapewnia najszybszą wydajność zapytań dla małych tabel, które z kompresją powinny być mniejsze niż 2 GB jako punkt wyjścia, dane statyczne mogą być większe.
Tabela replikowana buforuje pełną kopię tabeli w każdym węźle obliczeniowym. Dlatego replikowanie tabeli eliminuje konieczność przesyłania danych między węzłami obliczeniowymi przed operacją sprzężenia lub agregacji. W związku z tym wymagany jest dodatkowy magazyn i istnieje dodatkowe obciążenie związane z zapisywaniem danych, co sprawia, że duże tabele są niepraktyczne.
Modyfikacje danych spowodują unieważnienie buforowanej kopii i wymaganie ponownego odzyskania tabeli. Należy użyć sys.pdw_replicated_table_cache_state w zapytaniu, tak jak w poniższym, aby określić, które zreplikowane tabele zostały zmodyfikowane, ale nie zostały ponownie skompilowane.
SELECT [ReplicatedTable] = t.[name]
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Następnym krokiem będzie wymusić ponowne kompilowanie przy użyciu wyników z powyższego kodu, takich jak:
SELECT TOP 1 * FROM [ReplicatedTable]
Dodatkowe zagadnienia dotyczące wydajności tabeli replikowanej
Niektóre dodatkowe elementy, które należy wziąć pod uwagę podczas tworzenia zreplikowanej tabeli, obejmują następujące sytuacje, które negatywnie wpływają na wydajność:
- Tabela zawiera częste operacje wstawiania, aktualizowania i usuwania. Operacje języka manipulowania danymi (DML) wymagają ponownego skompilowania replikowanej tabeli. Ponowne kompilowanie często może spowodować niższą wydajność.
- Pula SQL jest często skalowana. Skalowanie puli SQL zmienia liczbę węzłów obliczeniowych, co powoduje ponowne skompilowanie replikowanej tabeli.
- Tabela zawiera dużą liczbę kolumn, ale operacje na danych zwykle uzyskują dostęp tylko do niewielkiej liczby kolumn. W tym scenariuszu zamiast replikować całą tabelę, może być bardziej efektywne dystrybuowanie tabeli, a następnie utworzenie indeksu w często używanych kolumnach. Jeśli zapytanie wymaga przenoszenia danych, pula SQL przenosi tylko dane dla żądanych kolumn.