Identyfikowanie i rozwiązywanie problemów z blokadami i zakleszczaniem
Blokowanie jest normalne w bazie danych, która używa blokady. Jedna transakcja utrzymuje blokadę. Czeka kolejna transakcja. Oczekuje się krótkiego blokowania, które trwa kilka milisekund. Staje się to problemem, gdy trwa wystarczająco długo, aby wpłynąć na użytkowników. Zakleszczenia są bardziej dotkliwą formą: dwie transakcje trwale blokują się nawzajem, a silnik bazy danych musi zakończyć jeden, aby przerwać cykl.
blokowanie
Blokowanie występuje, gdy jedna sesja przechowuje blokadę zasobu, a inna sesja żąda konfliktowej blokady tego samego zasobu. Sesja, która składa żądanie, czeka, aż pierwsza sesja zwolni blokadę.
Zasoby mogą być wierszami, stronami, a nawet całymi tabelami. Blokady mogą być udostępniane (w przypadku odczytów) lub wyłączne (w przypadku zapisów). Gdy sesja żąda blokady, która powoduje konflikt z istniejącą blokadą, zostaje zablokowana do czasu, aż pierwsza sesja zatwierdzi lub wycofa swoją transakcję i zwolni wszystkie swoje blokady.
Identyfikowanie łańcuchów blokujących
W usłudze Azure SQL Database domyślnie jest włączona funkcja izolacji zatwierdzonej migawki (RCSI), dlatego operacje odczytu używają wersjonowania wierszy zamiast współdzielonych blokad. To ustawienie znacznie zmniejsza blokowanie między czytelnikami i zapisującymi. Jednak blokowanie między dwoma piszącymi lub blokowanie spowodowane przez jawne transakcje z wyższym poziomem izolacji nadal występuje.
Sesja w górnej części łańcucha blokującego jest nazywana blokerem głównym. Wszystkie inne zablokowane sesje oczekują, bezpośrednio lub pośrednio, aż główny blokujący zwolni swoje blokady. Aby znaleźć bloker główny, wykonaj zapytanie sys.dm_exec_requests i poszukaj sesji, w których blocking_session_id nie ma wartościzerowej:
SELECT
r.session_id,
r.blocking_session_id,
r.wait_type,
r.wait_time,
r.wait_resource,
t.text AS query_text,
r.status,
r.command
FROM sys.dm_exec_requests AS r
CROSS APPLY sys.dm_exec_sql_text(r.sql_handle) AS t
WHERE r.blocking_session_id <> 0
ORDER BY r.wait_time DESC;
Aby znaleźć główny bloker w tych wynikach, poszukaj identyfikatora sesji, który blokuje inne, ale sam nie jest zablokowany. Załóżmy na przykład, że zapytanie zwraca następujące wiersze:
| session_id | blocking_session_id |
|---|---|
| 55 | 52 |
| 60 | 52 |
| 52 | 0 |
Sesje 55 i 60 są blokowane przez sesję 52, a sesja 52 ma parametr blocking_session_id o wartości 0, co oznacza, że nic jej nie blokuje. Sesja 52 jest głównym blokerem. Po zidentyfikowaniu go, wykonaj zapytanie sys.dm_exec_sessions i sys.dm_exec_requests przefiltrowane do tego identyfikatora sesji, aby sprawdzić, co jest uruchomione i dlaczego utrzymuje blokady.
Należy pamiętać, że rcSI eliminuje blokowanie między czytelnikami i pisarzami, ale nie między dwoma pisarzami. Rozważmy scenariusz, w którym sesja 52 uruchamia aktualizację wsadową wewnątrz jawnej transakcji.
-- Session 52
BEGIN TRANSACTION;
UPDATE Orders SET Status = 'Processing' WHERE Region = 'West';
-- Transaction stays open while application does other work
Ta aktualizacja uzyskuje wyłączne blokady dla każdego pasującego wiersza. Teraz sesja 55 próbuje zaktualizować jeden z tych samych wierszy:
-- Session 55
UPDATE Orders SET Priority = 1 WHERE OrderId = 4820;
Sesja 55 czeka, ponieważ sesja 52 zawiera już wyłączną blokadę w tym wierszu i nie została zatwierdzona. Zapytanie SELECT dla tych wierszy nadal powiedzie się w obszarze RCSI, ponieważ odczytuje wersję wiersza zamiast żądać udostępnionej blokady. W przypadku, gdy RCSI usuwa blokowanie czytanie-zapisanie domyślnie, blokowanie, na które napotkasz w Azure SQL Database, zazwyczaj dotyczy dwóch sesji, które obie muszą zapisywać do tych samych wierszy.
Rozpoznawanie typowych scenariuszy blokowania
Zrozumienie , dlaczego blokowanie ma miejsce, pomaga temu zapobiec. Aparat usługi Azure SQL Database automatycznie zarządza blokadami, ale niektóre wzorce prowadzą do dłuższego blokowania:
Długoterminowe zapytanie, które przechowuje blokady przez dłuższy czas. Zapytanie jest aktywnie wykonywane i robi postępy, ale utrzymuje blokady przez cały czas. Inne sesje, które wymagają blokad powodujących konflikt w tych samych zasobach, czekają na zakończenie zapytania. Aby rozwiązać ten problem, poszukaj sposobów optymalizacji zapytania, takich jak dodawanie indeksów lub ponowne zapisywanie go w celu dotknięcia mniejszej liczby wierszy.
Sesja uśpiona z niezatwierdzoną transakcją. Sesja wykonuje instrukcję w ramach jawnej transakcji, po czym zatrzymuje jej wykonywanie, ale nigdy nie dokonuje zatwierdzenia ani wycofania transakcji. Blokady z transakcji pozostają przechowywane na czas nieokreślony. Ten problem często występuje, gdy aplikacja napotyka przekroczenie limitu czasu zapytania lub jego anulowanie, ale nie wydaje odpowiadającego ROLLBACK. Użyj SET XACT_ABORT ON polecenia , aby błędy środowiska uruchomieniowego automatycznie wycofały transakcję.
Sesja, która nie pobrała wszystkich rekordów wynikowych. Aplikacja wysyła zapytanie, ale nie pobiera wszystkich wierszy z zestawu wyników. Blokady mogą pozostać przechowywane w wierszach, które nie zostały jeszcze pobrane. Upewnij się, że aplikacja pobiera wszystkie wiersze wyników do końca.
Sesja w stanie wycofywania. Zapytanie, które zostało zakończone (za pomocą KILL lub przez zakleszczenie), wycofuje swoje zmiany. Cofnięcie może trwać długo w przypadku dużych modyfikacji, a sesja nadal utrzymuje blokady podczas tego procesu. Poczekaj na zakończenie wycofywania i unikaj dużych modyfikacji wsadowych w okresach dużego obciążenia.
Osierocone połączenie. Aplikacja kliencka ulega awarii lub stacja robocza ponownie uruchamia się bez prawidłowego zamknięcia połączenia z bazą danych. Serwer nie wykrywa natychmiast rozłączenia, dlatego blokady z tej sesji pozostają przechowywane. Zakończ oddzieloną sesję za pomocą polecenia KILL <session_id>;.
Uwaga / Notatka
Dwa z tych scenariuszy są domyślnie ograniczane w usłudze Azure SQL Database. Funkcja RCSI zmniejsza wpływ niepobranych wierszy wyników, ponieważ SELECT zapytania nie uzyskują udostępnionych blokad przy wersjonowaniu wierszy, więc niepobrane wiersze nie blokują procesów zapisujących. Przyspieszone odzyskiwanie bazy danych (ADR) sprawia, że długotrwałe wycofywanie jest rzadkie, ponieważ może cofnąć zmiany niemal natychmiast niezależnie od rozmiaru transakcji. Pozostałe trzy scenariusze (długotrwałe zapytania, sesje uśpienia z niezatwierdzonymi transakcjami i osierocone połączenia) pozostają w pełni istotne, ponieważ obejmują one wyłączne blokady zapisu, których RCSI i ADR nie mogą zwolnić wcześniej.
Rozwiązywanie problemów z aktywnym blokowaniem
Po znalezieniu aktywnego blokowania:
- Zidentyfikuj głównego blokera za pomocą wcześniej pokazanego zapytania DMV.
- Ustal, czy transakcja sesji blokującej może zakończyć się samodzielnie, czy też czeka na wejście zewnętrzne.
- Jeśli sesja blokująca jest osieroconą lub porzuconą połączeniem, zakończ ją przy użyciu
KILL <session_id>;. - Przejrzyj plan wykonywania zapytania blokującego pod kątem możliwości optymalizacji, takich jak brakujące indeksy.
Aby zapobiec blokowaniu cyklicznym, zachowaj krótkie transakcje. Wykonaj tylko minimalne wymagane instrukcje w ramach transakcji i natychmiast zatwierdź. Użyj SET XACT_ABORT ON w kodzie aplikacji, aby każdy błąd czasu wykonania automatycznie wycofywał całą transakcję, co zapobiega przetrzymywaniu blokad przez nieukończone transakcje na czas nieokreślony. Przenieś całą logikę interakcji z użytkownikiem poza granice transakcji.
Zakleszczenia
Zakleszczenie występuje, gdy co najmniej dwie transakcje tworzą zależność cykliczną. Każda transakcja posiada blokadę, której potrzebuje druga, i żadna nie może kontynuować. Oto konkretny przykład:
- Transaction A aktualizuje wiersz 1 i uzyskuje wyłączną blokadę.
- Transakcja B aktualizuje wiersz 2 i uzyskuje wyłączną blokadę.
- Transakcja A próbuje zaktualizować wiersz 2 i jest blokowana przez Transakcję B.
- Transakcja B próbuje zaktualizować wiersz 1 i jest blokowana przez transakcję A.
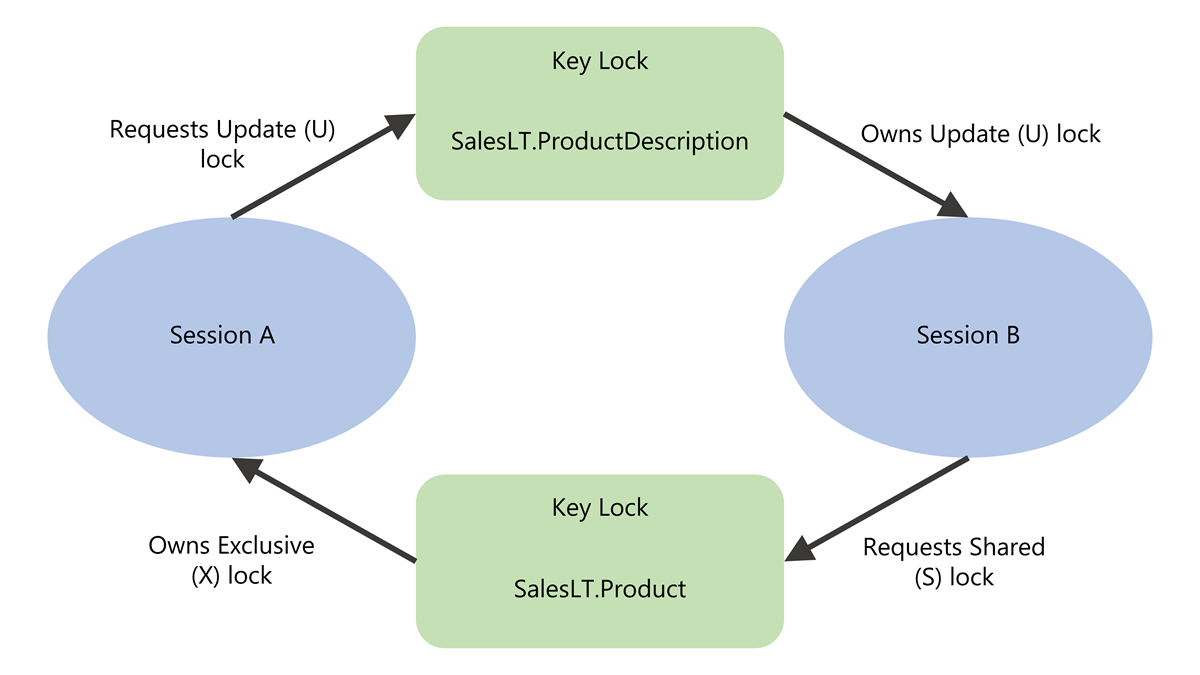
Żadna transakcja nie może zakończyć się. Monitor zakleszczenia silnika bazy danych okresowo sprawdza te cykle z domyślnym interwałem pięciu sekund, który może zmniejszyć się do 100 milisekund, gdy zakleszczenia występują często. Po wykryciu cyklu wybiera transakcję, która jest najmniej kosztowna do wycofania jako ofiara, cofa ją i zwraca błąd 1205 do aplikacji. To wycofanie umożliwia ukończenie innej transakcji.
Przechwytywanie informacji o impasie
W programie SQL Server i usłudze Azure SQL Managed Instance sesja system_health zdarzeń rozszerzonych domyślnie przechwytuje zdarzenia zakleszczenia. Możesz wykonać zapytanie dotyczące raportu zakleszczenia z buforu pierścienia przy użyciu parametrów sys.dm_xe_session_targets i sys.dm_xe_sessions.
W usłudze Azure SQL Database podejście jest inne. Tworzysz niestandardową sesję Zdarzeń Rozszerzonych, która przechwytuje zdarzenie sqlserver.database_xml_deadlock_report, i wykonujesz względem niego zapytania przy użyciu dynamicznych widoków zarządzania sys.dm_xe_database_sessions oraz sys.dm_xe_database_session_targets o zakresie bazy danych. Poniższy przykład tworzy sesję przechwytywania zakleszczenia i wykonuje zapytania dotyczące buforu pierścienia:
-- Create and start the session
CREATE EVENT SESSION [deadlocks] ON DATABASE
ADD EVENT sqlserver.database_xml_deadlock_report
ADD TARGET package0.ring_buffer
WITH (STARTUP_STATE = ON, MAX_MEMORY = 4 MB);
GO
ALTER EVENT SESSION [deadlocks] ON DATABASE STATE = START;
GO
-- Query deadlock events from the ring buffer
DECLARE @tracename sysname = N'deadlocks';
SELECT
d.value('(/event/@timestamp)[1]', 'datetime2') AS deadlock_time,
d.query('/event/data[@name=''xml_report'']/value/deadlock') AS deadlock_xml
FROM (
SELECT CAST(target_data AS XML) AS rb
FROM sys.dm_xe_database_sessions AS s
INNER JOIN sys.dm_xe_database_session_targets AS t
ON CAST(t.event_session_address AS BINARY(8)) = CAST(s.address AS BINARY(8))
WHERE s.name = @tracename
AND t.target_name = N'ring_buffer'
) AS ring_buffer
CROSS APPLY rb.nodes(
'/RingBufferTarget/event[@name=''database_xml_deadlock_report'']'
) AS xevent(d)
ORDER BY deadlock_time DESC;
Wykres zakleszczenia zawiera trzy sekcje. Lista ofiar określa, która transakcja została zakończona. Lista procesów zawiera każdy zaangażowany proces, w tym tekst zapytania, poziom izolacji i tryb blokady. Lista zasobów zawiera zablokowane zasoby oraz proces, który jest właścicielem i czeka na każdy z nich.
W usłudze Azure SQL Database można również skonfigurować alerty zakleszczenia za pośrednictwem witryny Azure Portal, aby otrzymywać powiadomienia, gdy wystąpią zakleszczenia.
Zapobieganie zakleszczeniom
Nie można wyeliminować wszystkich zakleszczeń, ale można znacznie zmniejszyć częstotliwość ich występowania:
- Uzyskiwanie dostępu do obiektów w spójnej kolejności: jeśli wszystkie transakcje modyfikują tabelę A przed tabelą B, zależności cykliczne nie mogą się tworzyć. Standaryzacja wzorców dostępu za pomocą procedur składowanych.
- Zachowaj krótkie transakcje: Krótsze transakcje utrzymują blokady przez krótszy czas, co zmniejsza okno dla zależności cyklicznych.
- Użyj poziomów izolacji wersjonowania wierszy: RCSI eliminuje wspólne blokady dla operacji odczytu, co powoduje usunięcie jednego wspólnego źródła cykli zablokowań międzyprocesowych. Zoptymalizowane blokowanie w usłudze Azure SQL Database dodatkowo zmniejsza prawdopodobieństwo zakleszczenia.
- Dodaj odpowiednie indeksy: gdy zapytania skanują wiele wierszy, uzyskują blokady w szerokim zakresie danych. Dodanie indeksów, które zawężają skanowanie do mniejszej liczby wierszy, zmniejsza konflikty blokady.
- Użyj wymuszania planu w Magazynie Zapytań: jeśli zmiana planu spowodowała przeskanowanie większej liczby wierszy i uzyskanie większej liczby blokad, wymuszanie poprzedniego planu może zmniejszyć zakleszczenia podczas analizy.
Obsługiwanie zakleszczeń w kodzie aplikacji
Aplikacje powinny zawsze uwzględniać mechanizm ponawiania prób w przypadku błędów związanych z zakleszczeniem. Gdy transakcja zostanie wybrana jako ofiara zakleszczenia, silnik bazy danych wycofa ją i zwróci błąd 1205. Aplikacja powinna przechwycić ten błąd, wstrzymać krótko i ponownie przesłać transakcję.
BEGIN TRY
BEGIN TRANSACTION;
-- Your data modification statements
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
IF ERROR_NUMBER() = 1205
BEGIN
ROLLBACK TRANSACTION;
WAITFOR DELAY '00:00:01'; -- Brief pause before retry
-- Retry logic here
END
ELSE
BEGIN
ROLLBACK TRANSACTION;
THROW;
END
END CATCH;
Wskazówka
Randomizuj opóźnienie przed ponowieniem próby, aby zapobiec natychmiastowemu zakleszczeniu tych samych dwóch transakcji. Typowym wzorcem jest odczekanie od jednej do trzech sekund z losowym składnikiem.
Kluczowe wnioski
Blokowanie jest normalne, ale przedłużone blokowanie wpływa na użytkowników, więc używasz sys.dm_exec_requests aby znaleźć głównego blokera i zrozumieć, co robi. Typowe scenariusze obejmują długotrwałe zapytania, uśpione sesje z niezatwierdzonymi transakcjami i osierocone połączenia, które są rozwiązywane przez utrzymywanie krótkich transakcji przy użyciu poleceń SET XACT_ABORT ON i zapewnienie prawidłowego zarządzania połączeniami i zestawami wyników przez aplikacje. Zakleszczenia występują, gdy transakcje tworzą cykliczne zależności blokad, a silnik bazy danych rozwiązuje je automatycznie, kończąc najmniej kosztowną transakcję i zwracając błąd 1205. Zmniejszenie częstotliwości występowania blokad poprzez uzyskiwanie dostępu do obiektów w spójnej kolejności, utrzymywanie krótkich transakcji, stosowanie poziomów izolacji wersji wierszy i dodawanie odpowiednich indeksów. Kod aplikacji powinien zawsze zawierać logikę ponawiania próby dla błędu 1205, aby można było ją odzyskać automatycznie po wybraniu jako ofiara zakleszczenia.