Opis przesyłania strumieniowego ze strukturą platformy Spark
Przesyłanie strumieniowe ze strukturą platformy Spark to popularna platforma do przetwarzania w pamięci. Ma ujednolicony paradygmat dla partii i przesyłania strumieniowego. Wszystko, czego uczysz się i używasz do przetwarzania wsadowego, możesz użyć do przesyłania strumieniowego, dzięki czemu można łatwo zwiększać możliwości przetwarzania wsadowego danych do przesyłania strumieniowego. Przesyłanie strumieniowe platformy Spark to po prostu aparat działający na platformie Apache Spark.

Przesyłanie strumieniowe ze strukturą tworzy długotrwałe zapytanie, podczas którego stosujesz operacje do danych wejściowych, takich jak wybór, projekcja, agregacja, okno i łączenie przesyłania strumieniowego ramki danych z ramkami danych referencyjnych. Następnie wyprowadź wyniki do magazynu plików (obiektów blob usługi Azure Storage lub usługi Data Lake Storage) lub do dowolnego magazynu danych przy użyciu kodu niestandardowego (takiego jak usługa SQL Database lub Power BI). Przesyłanie strumieniowe ze strukturą udostępnia również dane wyjściowe do konsoli do debugowania lokalnie oraz do tabeli w pamięci, dzięki czemu można wyświetlić dane wygenerowane do debugowania w usłudze HDInsight.
Strumienie jako tabele
Przesyłanie strumieniowe ze strukturą platformy Spark reprezentuje strumień danych jako tabelę, która jest w głębi systemu, czyli tabela nadal rośnie wraz z nadejściem nowych danych. Ta tabela wejściowa jest stale przetwarzana przez długotrwałe zapytanie, a wyniki wysyłane do tabeli wyjściowej:

W przypadku przesyłania strumieniowego ze strukturą dane docierają do systemu i są natychmiast pozyskiwane do tabeli wejściowej. Zapytania są zapisywane (przy użyciu interfejsów API ramek danych i zestawu danych), które wykonują operacje względem tej tabeli wejściowej. Dane wyjściowe zapytania dają kolejną tabelę, tabelę wyników. Tabela wyników zawiera wyniki zapytania, z którego są rysowane dane dla zewnętrznego magazynu danych, takiego jak relacyjna baza danych. Czas przetwarzania danych z tabeli wejściowej jest kontrolowany przez interwał wyzwalacza. Domyślnie interwał wyzwalacza wynosi zero, więc przesyłanie strumieniowe ze strukturą próbuje przetworzyć dane natychmiast po ich nadejściu. W praktyce oznacza to, że gdy tylko przesyłanie strumieniowe ze strukturą zostanie wykonane przetwarzanie przebiegu poprzedniego zapytania, uruchamia kolejne uruchomienie przetwarzania względem wszystkich nowo odebranych danych. Wyzwalacz można skonfigurować tak, aby był uruchamiany w odstępach czasu, tak aby dane przesyłane strumieniowo są przetwarzane w partiach opartych na czasie.
Dane w tabelach wyników mogą zawierać tylko dane, które są nowe od czasu ostatniego przetworzenia zapytania (tryb dołączania) lub tabela może być odświeżona za każdym razem, gdy istnieją nowe dane, więc tabela zawiera wszystkie dane wyjściowe od rozpoczęcia zapytania przesyłania strumieniowego (tryb pełny).
Tryb dołączania
W trybie dołączania tylko wiersze dodane do tabeli wyników od ostatniego uruchomienia zapytania są obecne w tabeli wyników i zapisywane w magazynie zewnętrznym. Na przykład najprostsze zapytanie po prostu kopiuje wszystkie dane z tabeli wejściowej do tabeli wyników niezrealizowanych. Za każdym razem, gdy interwał wyzwalacza upłynie, nowe dane są przetwarzane, a wiersze reprezentujące te nowe dane są wyświetlane w tabeli wyników.
Rozważmy scenariusz, w którym przetwarzasz dane o cenach akcji. Załóżmy, że pierwszy wyzwalacz przetworzył jedno zdarzenie w czasie 00:01 dla akcji MSFT o wartości 95 dolarów. W pierwszym wyzwalaczu zapytania w tabeli wyników pojawia się tylko wiersz z czasem 00:01. W czasie 00:02 po nadejściu innego zdarzenia jedynym nowym wierszem jest wiersz o godzinie 00:02, więc tabela wyników będzie zawierać tylko ten jeden wiersz.
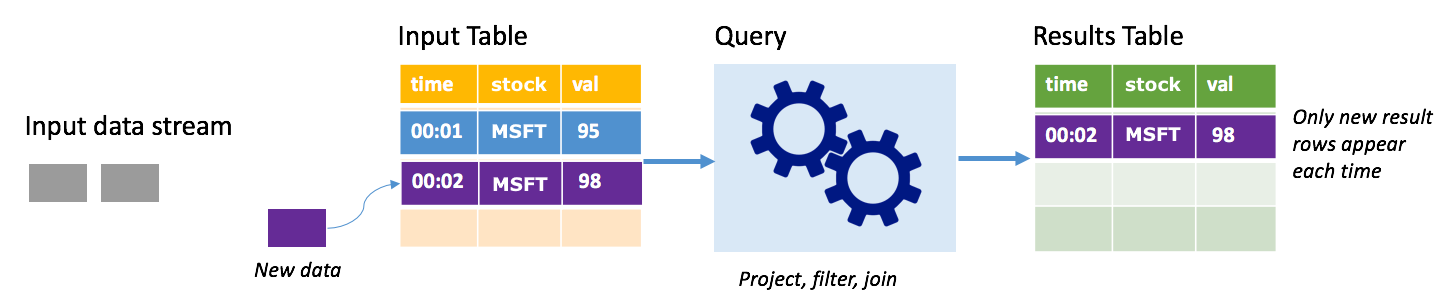
W przypadku korzystania z trybu dołączania zapytanie będzie stosować projekcje (wybierając kolumny, których dotyczy), filtrowanie (wybieranie tylko wierszy spełniających określone warunki) lub łączenie (rozszerzanie danych danymi z statycznej tabeli odnośników). Tryb dołączania ułatwia wypychanie tylko odpowiednich nowych danych do magazynu zewnętrznego.
Tryb ukończenia
Rozważmy ten sam scenariusz, tym razem przy użyciu trybu pełnego. W trybie pełnym cała tabela danych wyjściowych jest odświeżona na każdym wyzwalaczu, więc tabela zawiera dane nie tylko z ostatniego uruchomienia wyzwalacza, ale ze wszystkich przebiegów. Możesz użyć trybu pełnego, aby skopiować dane niezmodyfikowane z tabeli wejściowej do tabeli wyników. Na każdym wyzwolonym uruchomieniu nowe wiersze wyników są wyświetlane wraz ze wszystkimi poprzednimi wierszami. Tabela wyników wyjściowych będzie przechowywać wszystkie zebrane dane od rozpoczęcia zapytania i w końcu zabraknie pamięci. Tryb kompletny jest przeznaczony do użycia z zapytaniami agregowanymi, które podsumowują dane przychodzące w jakiś sposób, więc na każdym wyzwalaczu tabela wyników jest aktualizowana przy użyciu nowego podsumowania.
Załóżmy, że do tej pory są już przetwarzane dane o wartości pięciu sekund i nadszedł czas, aby przetworzyć dane na szóstą sekundę. Tabela wejściowa zawiera zdarzenia dotyczące czasu 00:01 i godziny 00:03. Celem tego przykładowego zapytania jest podanie średniej ceny akcji co pięć sekund. Implementacja tego zapytania stosuje agregację, która przyjmuje wszystkie wartości, które należą do każdego 5-sekundowego okna, średnia cena akcji i tworzy wiersz dla średniej ceny akcji w tym interwale. Na końcu pierwszego 5-sekundowego okna znajdują się dwie krotki: (00:01, 1, 95) i (00:03, 1, 98). Więc dla okna 00:00-00:05 agregacja generuje krotkę ze średnią ceną akcji w wysokości 96,50 USD. W następnym 5-sekundowym oknie istnieje tylko jeden punkt danych w czasie 00:06, więc wynikowa cena akcji wynosi 98 USD. W czasie 00:10 przy użyciu trybu pełnego tabela wyników zawiera wiersze dla obu okien 00:00-00:05 i 00:05-00:10, ponieważ zapytanie zwraca wszystkie zagregowane wiersze, a nie tylko nowe. W związku z tym tabela wyników nadal rośnie w miarę dodawania nowych okien.
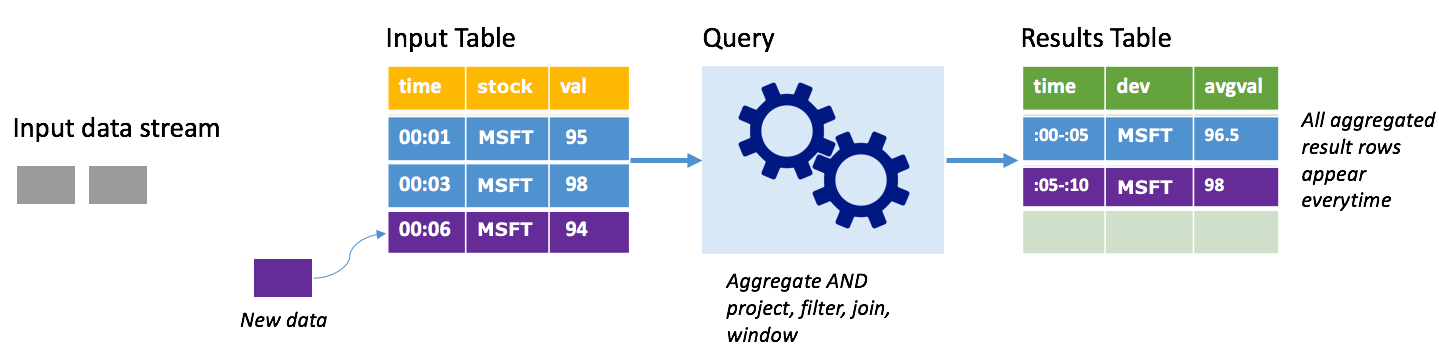
Nie wszystkie zapytania korzystające z trybu pełnego powodują wzrost tabeli bez ograniczeń. Rozważmy w poprzednim przykładzie, że zamiast średniej ceny akcji za przedział, średnia jest zamiast akcji. Tabela wyników zawiera stałą liczbę wierszy (jedną na czas) ze średnią ceną akcji dla zapasów we wszystkich punktach danych otrzymanych z tego urządzenia. W miarę odbierania nowych cen akcji tabela wyników jest aktualizowana tak, aby średnie w tabeli były zawsze aktualne.
Jakie są zalety przesyłania strumieniowego ze strukturą platformy Spark?
Będąc w sektorze finansowym, czas transakcji jest bardzo ważny. Na przykład w obrocie akcjami różnica między tym, kiedy handel akcjami odbywa się na giełdzie, lub gdy otrzymasz transakcję, lub gdy dane są odczytywane wszystkie sprawy. W przypadku instytucji finansowych są one zależne od tych krytycznych danych i czasu związanego z nim.
Czas zdarzenia, późne dane i znak wodny
Przesyłanie strumieniowe ze strukturą platformy Spark zna różnicę między czasem zdarzenia a czasem przetwarzania zdarzenia przez system. Każde zdarzenie jest wierszem w tabeli, a czas zdarzenia jest wartością kolumny w wierszu. Dzięki temu agregacje oparte na oknach (na przykład liczba zdarzeń co minutę) mogą być tylko grupowaniem i agregacją w kolumnie czas zdarzenia — za każdym razem okno jest grupą, a każdy wiersz może należeć do wielu okien/grup. W związku z tym takie zapytania agregacji oparte na oknach czasowych zdarzeń można spójnie definiować zarówno na statycznym zestawie danych, jak i strumieniu danych, co znacznie ułatwia życie inżyniera danych.
Ponadto ten model naturalnie obsługuje dane, które dotarły później niż oczekiwano na podstawie czasu zdarzenia. Platforma Spark ma pełną kontrolę nad aktualizowaniem starych agregacji w przypadku późnych danych, a także czyszczenie starych agregacji w celu ograniczenia rozmiaru danych stanu pośredniego. Ponadto, ponieważ platforma Spark 2.1 obsługuje znak wodny, co umożliwia określenie progu opóźnionych danych i umożliwia aparatowi odpowiednie czyszczenie starego stanu.
Elastyczność przekazywania ostatnich danych lub wszystkich danych
Zgodnie z opisem w poprzedniej lekcji możesz użyć trybu dołączania lub trybu ukończenia podczas pracy z przesyłaniem strumieniowym ze strukturą platformy Spark, aby tabela wyników zawierała tylko najnowsze dane lub wszystkie dane.
Obsługuje przechodzenie z mikrosadów do ciągłego przetwarzania
Zmieniając typ wyzwalacza zapytania Platformy Spark, można przejść z mikrosadów przetwarzania do ciągłego przetwarzania bez innych zmian w strukturze. Oto różne rodzaje wyzwalaczy, które obsługuje platforma Spark.
- Nieokreślone, jest to ustawienie domyślne. Jeśli żaden wyzwalacz nie jest jawnie ustawiony, zapytanie jest wykonywane w mikrosadach i będzie przetwarzane w sposób ciągły.
- Stały interwał mikrosadowy. Zapytanie jest uruchamiane w cyklicznych odstępach czasu ustawionych przez użytkownika. Jeśli nie odebrano żadnych nowych danych, nie zostanie uruchomiony żaden proces mikrosadowy.
- Jednorazowa mikrosadowa partia. Zapytanie uruchamia pojedynczą mikrosadę, a następnie zatrzymuje się. Jest to przydatne, jeśli chcesz przetworzyć wszystkie dane od poprzedniej mikrosady i może zapewnić oszczędności kosztów dla zadań, które nie muszą być uruchamiane w sposób ciągły.
- Ciągły z stałym interwałem punktu kontrolnego. Zapytanie jest uruchamiane w nowym trybie niskiego opóźnienia, w trybie ciągłego przetwarzania, który umożliwia małe (~1 ms) kompleksowe opóźnienie z co najmniej jednokrotną gwarancją odporności na uszkodzenia. Jest to podobne do wartości domyślnej, która może osiągnąć dokładnie jednokrotne gwarancje, ale osiąga tylko opóźnienia ok. 100 ms.
Łączenie zadań wsadowych i przesyłania strumieniowego
Oprócz uproszczenia przenoszenia z partii do zadań przesyłania strumieniowego można również łączyć zadania wsadowe i przesyłane strumieniowo. Jest to szczególnie przydatne, gdy chcesz używać długoterminowych danych historycznych do przewidywania przyszłych trendów podczas przetwarzania informacji w czasie rzeczywistym. W przypadku akcji warto przyjrzeć się cenie akcji w ciągu ostatnich 5 lat oprócz bieżącej ceny, aby przewidzieć zmiany wprowadzone w ogłoszeniach o przychodach rocznych lub kwartalnych.
Okna czasu zdarzenia
Możesz przechwycić dane w oknach, takie jak wysoka cena akcji i niska cena akcji w ciągu jednego dnia lub jednominutowe okno — niezależnie od interwału, który decydujesz, a przesyłanie strumieniowe ze strukturą platformy Spark obsługuje to również. Obsługiwane są również nakładające się okna.
Punktowanie kontrolne na potrzeby odzyskiwania po awarii
W przypadku awarii lub zamierzonego zamknięcia można odzyskać poprzedni postęp i stan poprzedniego zapytania i kontynuować, gdzie została przerwana. Odbywa się to przy użyciu dzienników punktów kontrolnych i zapisywania z wyprzedzeniem. Zapytanie można skonfigurować z lokalizacją punktu kontrolnego, a zapytanie zapisze wszystkie informacje o postępie (tj. zakres przesunięć przetworzonych w każdym wyzwalaczu) oraz uruchomione agregacje do lokalizacji punktu kontrolnego. Ta lokalizacja punktu kontrolnego musi być ścieżką w zgodnym systemie plików HDFS i można ustawić jako opcję w narzędziu DataStreamWriter podczas uruchamiania zapytania.