Tworzenie architektury platformy Kafka i platformy Spark
Aby używać platformy Kafka i platformy Spark razem w usłudze Azure HDInsight, należy umieścić je w tej samej sieci wirtualnej lub równorzędnej sieciach wirtualnych, aby klastry działały z rozpoznawaniem nazw DNS.
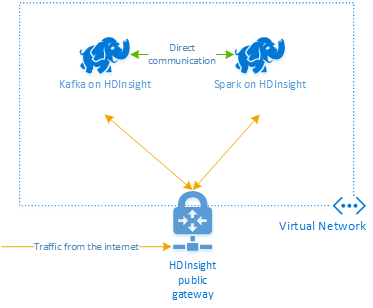
Aby utworzyć klastry w tej samej sieci wirtualnej, procedura to:
- Tworzenie grupy zasobów
- Dodawanie sieci wirtualnej do grupy zasobów
- Dodaj klaster platformy Kafka i klaster Spark do tej samej sieci wirtualnej lub alternatywnie za pomocą komunikacji równorzędnej sieci wirtualnych, w których te usługi działają z rozpoznawaniem nazw DNS.
Zalecanym sposobem łączenia klastra platformy Kafka z platformą Spark w usłudze HDInsight jest natywny łącznik Spark-Kafka, który umożliwia klastrowi Spark dostęp do poszczególnych partycji danych w klastrze kafka, co zwiększa równoległość zadań przetwarzania w czasie rzeczywistym i zapewnia bardzo wysoką przepływność.
Gdy oba klastry znajdują się w tej samej sieci wirtualnej, można również użyć nazw FQDN brokera platformy Kafka w kodzie przesyłania strumieniowego platformy Spark i utworzyć reguły sieciowej grupy zabezpieczeń w sieci wirtualnej na potrzeby zabezpieczeń przedsiębiorstwa.
Architektura rozwiązania
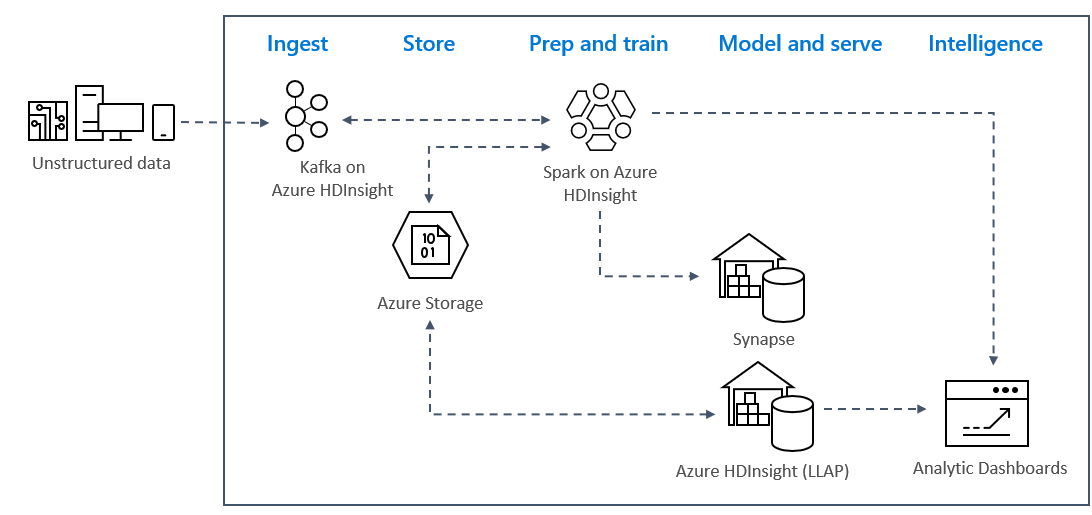
Wzorce analizy przesyłania strumieniowego w czasie rzeczywistym na platformie Azure zwykle używają następującej architektury rozwiązania.
- Pozyskiwanie: dane nieustrukturyzowane lub ustrukturyzowane są pozyskiwane do klastra platformy Kafka w usłudze Azure HDInsight.
- Przygotowywanie i trenowanie: dane są wstępnie mapowane i trenowane za pomocą platformy Spark w usłudze HDInsight.
- Model i obsługa: dane są umieszczane w magazynie danych, takim jak usługa Azure Synapse lub interakcyjne zapytanie usługi HDInsight.
- Analiza: dane są udostępniane do pulpitu nawigacyjnego analizy, takiego jak power BI lub Tableau.
- Magazyn: dane są umieszczane w zimnym rozwiązaniu magazynu, takim jak Usługa Azure Storage, i są obsługiwane później.
Przykładowa architektura scenariusza
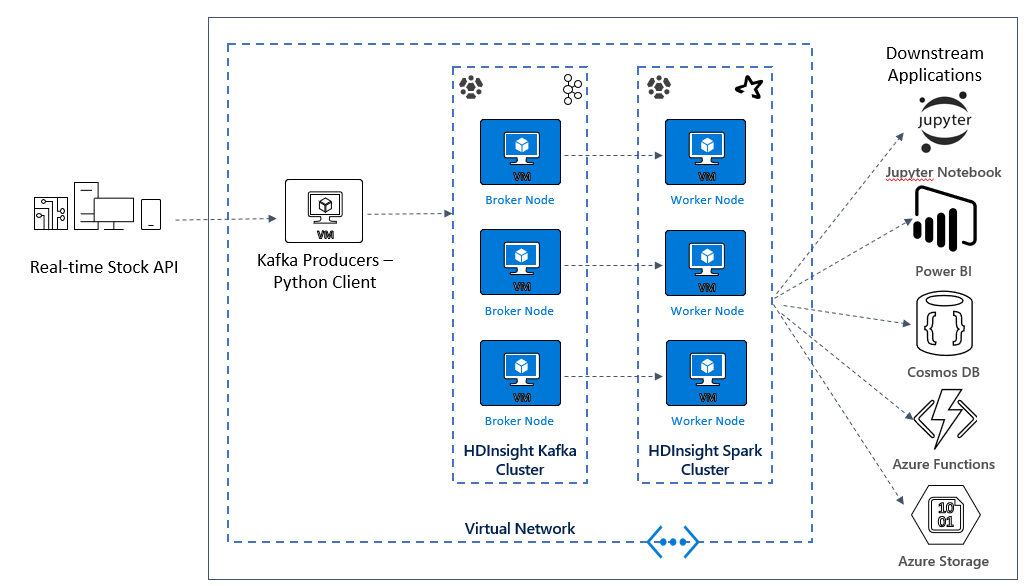
W następnej lekcji zaczniesz tworzyć architekturę rozwiązania dla przykładowej aplikacji. W tym przykładzie użyto pliku szablonu usługi Azure Resource Manager do utworzenia grupy zasobów, sieci wirtualnej, klastra Spark i klastra platformy Kafka.
Po wdrożeniu klastrów utworzysz protokół ssh w jednym z brokerów platformy Kafka i skopiujesz plik producenta języka Python do węzła głównego. Ten plik producenta zapewnia sztuczne ceny akcji co 10 sekund, zapisuje również numer partycji i przesunięcie komunikatu do konsoli.
Po uruchomieniu producenta możesz przekazać notes Jupyter do klastra Spark. W notesie połączysz klastry Spark i Kafka i uruchomisz kilka przykładowych zapytań dotyczących danych, w tym znalezienie wysokich i niskich wartości zapasów w oknie zdarzeń.