Wykonywanie eksploracji danych
Rozwiązanie Data Wrangler ułatwia eksplorowanie danych za pomocą łatwego w użyciu interfejsu siatki, który dynamicznie przedstawia podsumowanie statystyk danych.
Dzięki wizualnej eksploracji statystyk podsumowania analitycy danych mogą wybrać odpowiednie modele statystyczne lub uczenia maszynowego, które najlepiej pasują do danych. Na przykład niektóre modele zakładają, że dane są zwykle dystrybuowane i mogą nie działać prawidłowo, jeśli to założenie zostanie naruszone.
Wskazówka
Aby dowiedzieć się więcej o podstawach eksploracji danych przy użyciu notesów, zobacz Eksplorowanie danych dotyczących nauki o danych za pomocą notesów w usłudze Microsoft Fabric.
Wyświetl statystyki podsumowujące
W celach demonstracyjnych wygenerujmy kilka losowych danych, aby zasymulować hipotetyczny scenariusz obejmujący ceny domów w określonej okolicy.
import pandas as pd
import numpy as np
# Set the seed
np.random.seed(0)
# Define the size of the dataset
size = 500
# Generate random data
data = {
'Size': np.random.randint(1000, 4001, size, dtype=int) // 10 * 10, # any integer value between 1000 and 4000, with multiple of 10
'Bedrooms': np.random.choice([2, 4, 3, 2, 1], size),
'YearBuilt': np.random.randint(1980, 2021, size), # any integer value between 1980 and 2020
'Price': np.random.normal(loc=110000, scale=20000, size=size), # normally distributed prices
'Type': np.random.choice(['Single Family', 'Townhouse', 'Condo', 'Duplex'], size) # type of the house
}
# Create a DataFrame
df = pd.DataFrame(data)
Aby wyświetlić statystyki podsumowania dla ramki danych df, wybierz pozycję Dane na wstążce notesu, a następnie wybierz pozycję Uruchom narzędzie Data Wrangler dla ramki danych df.

W przypadku zmiennych liczbowych siatka wyświetla histogram, liczbę brakujących i unikatowych wartości, a także wartości minimalne i maksymalne. Jeśli chodzi o zmienne kategorii, siatka oferuje wgląd w proporcję każdej kategorii w zmiennej.
Panel Podsumowanie zawiera szczegółowe opisowe statystyki i dynamiczne aktualizacje podczas wybierania różnych kolumn w siatce.
Grupowanie i agregowanie danych
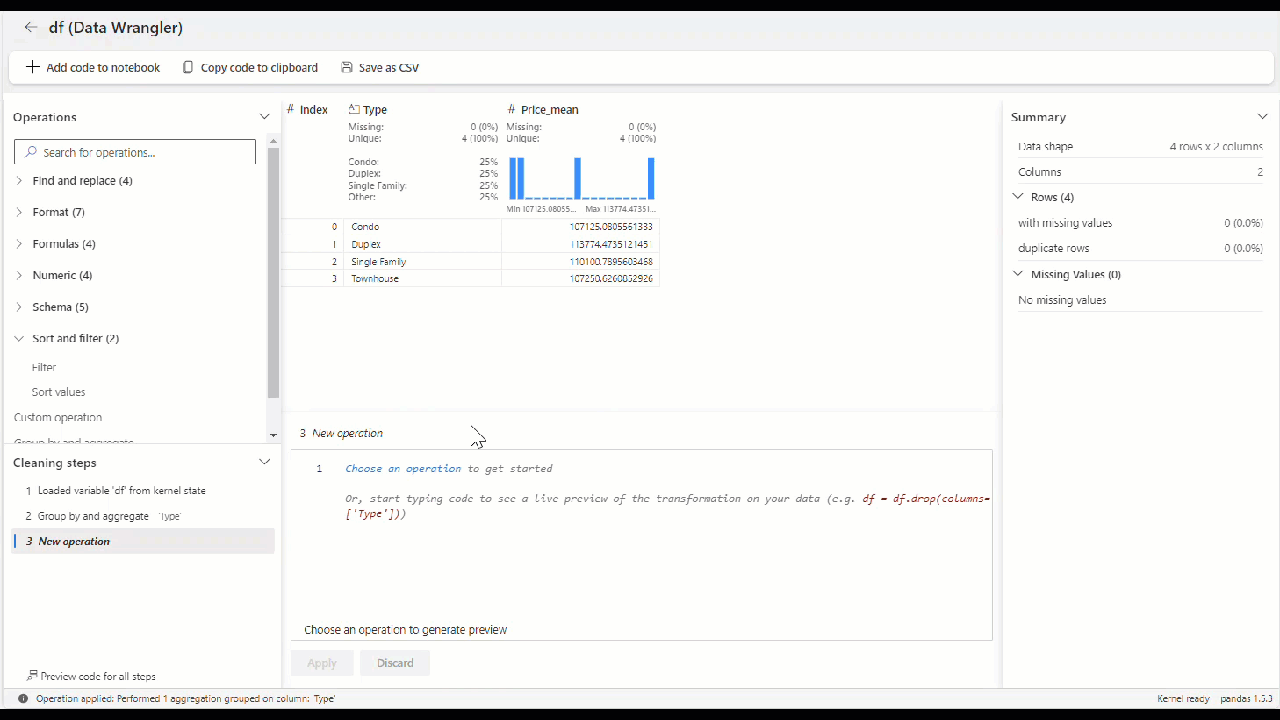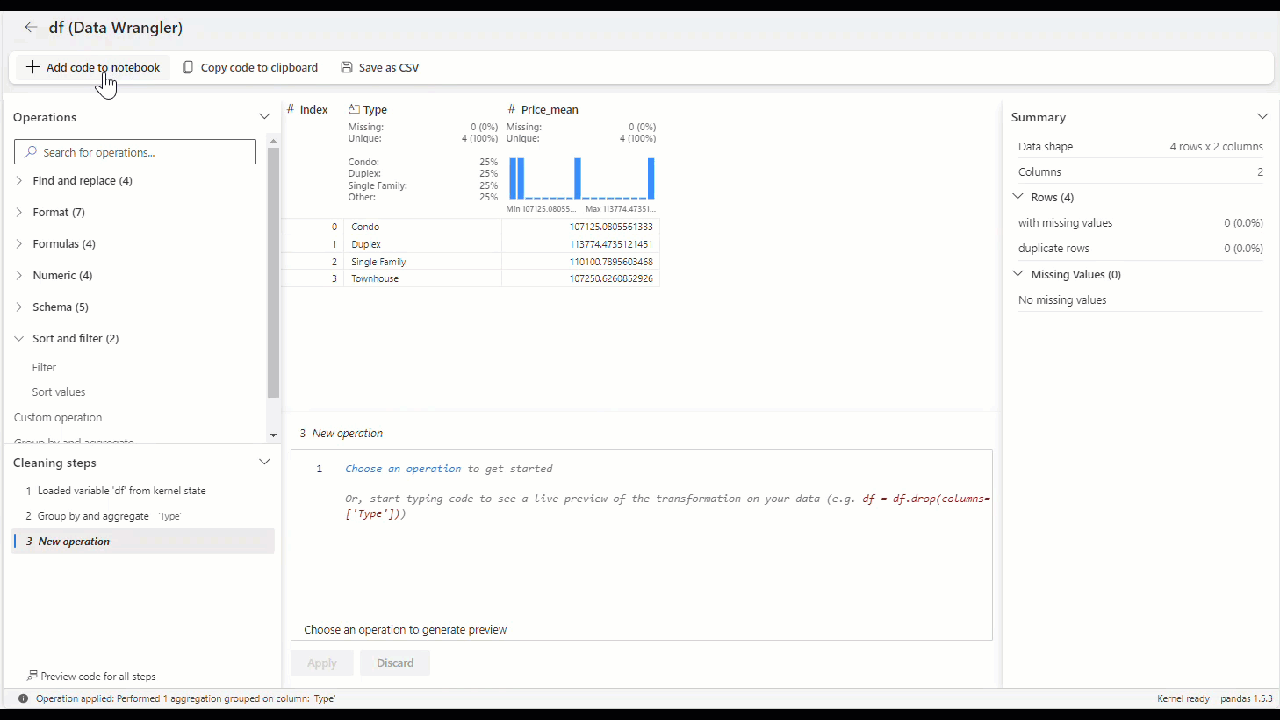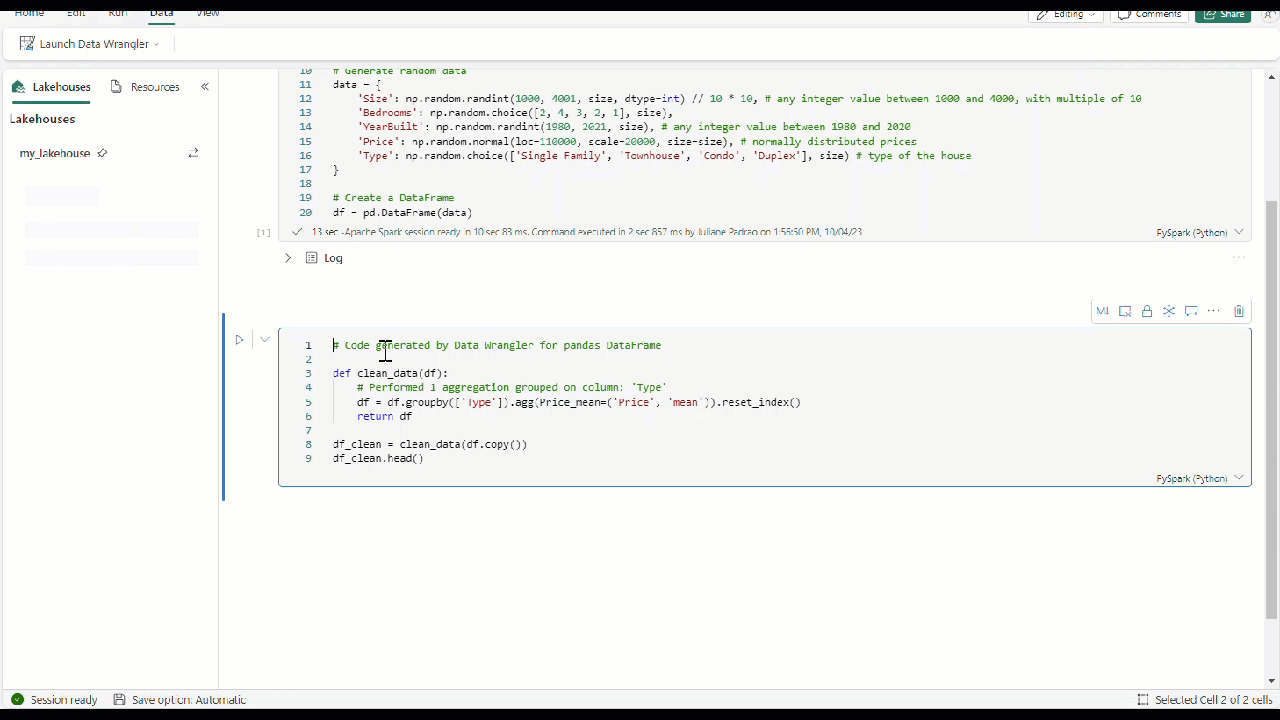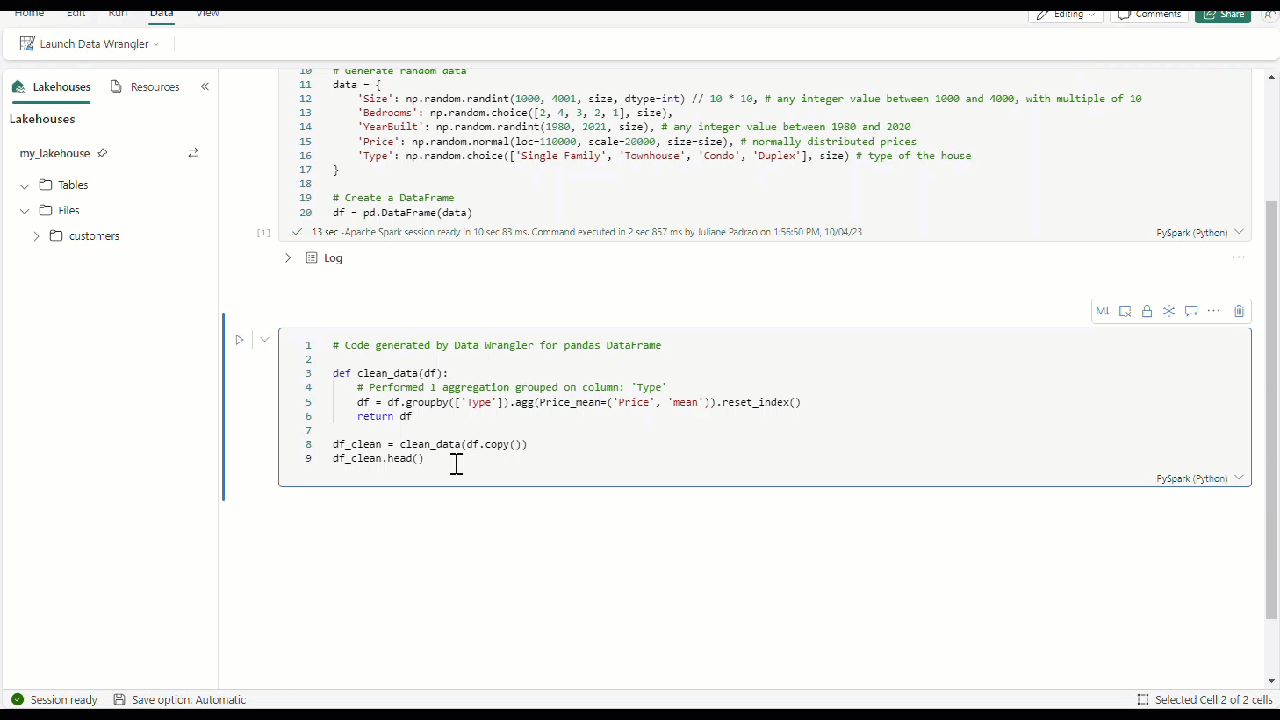
Alternatywnie, możesz zastosować agregację w danych przy użyciu operatora Grupuj według i agreguj w panelu operatora.
W naszym scenariuszu cen domów załóżmy, że potrzebujemy średniej ceny domu według typu.

W ciągu kilku sekund możemy skonfigurować operator grupowania według i agregacji, w którym kod jest generowany automatycznie. Ponadto siatka pokazuje nowe dane w kolorze zielonym i kolumny do usunięcia na czerwono.
Po zastosowaniu operatora jest to sposób wyświetlania ostatecznej siatki.

W tym momencie możesz zdecydować się na wygenerowanie kodu lub pobranie przekształconej ramki danych jako pliku wartości rozdzielanych przecinkami (CSV).
Generowanie kodu
W narzędziu Data Wrangler, gdy używasz dowolnych wbudowanych lub niestandardowych operatorów, ramka danych nie zostanie zmieniona do momentu dodania i wykonania wygenerowanego kodu w notesie.
Po zastosowaniu wszystkich operatorów w celu przekształcenia danych wybierz pozycję + Dodaj kod do notesu na pasku narzędzi powyżej siatki Data Wrangler. Spowoduje to wygenerowanie funkcji, którą można następnie wykonać w potoku danych.
Ta funkcja upraszcza eksplorację danych i wstępne przetwarzanie w twoim przepływie pracy naukowej z danymi.