Normalizacja i standaryzacja
Skalowanie funkcji to technika, która zmienia zakres wartości, które ma funkcja. Dzięki temu modele uczą się szybciej i bardziej niezawodnie.
Normalizacja a standaryzacja
Normalizacja oznacza skalowanie wartości tak, aby wszystkie mieściły się w określonym zakresie, zazwyczaj 0–1. Jeśli na przykład masz listę osób w wieku 0, 50 i 100 lat, możesz znormalizować, dzieląc wiek o 100 lat, aby wartości były 0, 0,5 i 1.
Standaryzacja jest podobna, ale zamiast tego odejmujemy średnią (znaną również jako średnia) wartości i dzielimy przez odchylenie standardowe. Jeśli nie znasz odchylenia standardowego, nie martw się, oznacza to, że po standaryzacji średnia wartość wynosi zero, a około 95% wartości spadnie z zakresu od -2 do 2.
Istnieją inne sposoby skalowania danych, ale niuanse tych elementów wykraczają poza to, co musimy wiedzieć teraz. Przyjrzyjmy się, dlaczego stosujemy normalizację lub standaryzację.
Dlaczego musimy skalować?
Istnieje wiele powodów, dla których znormalizowamy lub ustandaryzujemy dane przed trenowaniem. Możesz je łatwiej zrozumieć za pomocą przykładu. Załóżmy, że chcemy wytrenować model, aby przewidzieć, czy pies uda się pracować w śniegu. Nasze dane są wyświetlane na poniższym wykresie jako kropki, a linia trendu, którą próbujemy znaleźć, jest wyświetlana jako linia ciągła:
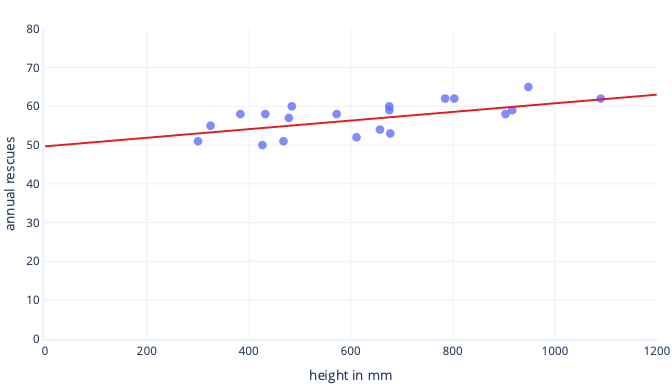
Skalowanie zapewnia lepszy punkt wyjścia
Optymalna linia na poprzednim wykresie ma dwa parametry: przechwycenie, czyli 50, linia na x=0 i nachylenie, czyli 0,01; każdy 1000 milimetrów zwiększa ratunki o 10. Załóżmy, że rozpoczniemy trenowanie przy użyciu początkowych szacunków 0 dla obu tych parametrów.
Jeśli nasze iteracji trenowania zmieniają parametry o około 0,01 na iterację średnio, potrzeba co najmniej 5000 iteracji przed odnalezieniem przechwycenia: 50 / 0,01 = 5000 iteracji. Standaryzacja może przynieść ten optymalny przechwyt jest bliżej zera, co oznacza, że możemy go znaleźć znacznie szybciej. Jeśli na przykład odejmiemy średnią od etykiety — roczne ratunki — i naszą funkcję — wysokość — przechwycenie wynosi -0,5, a nie 50, co możemy znaleźć około 100 razy szybciej.
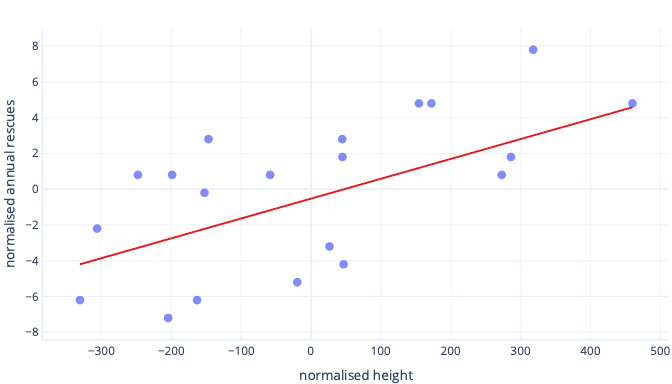
Istnieją inne powody, dla których złożone modele mogą być bardzo powolne do trenowania, gdy początkowe odgadnięcie jest dalekie od znaku, ale rozwiązanie jest nadal takie samo: funkcje przesunięcia do czegoś bliżej początkowego odgadnięcia.
Standaryzacja umożliwia trenowanie parametrów z taką samą prędkością
W naszych nowo przesunięć danych mamy idealne przesunięcie -0,5 i idealną nachylenie 0,01. Chociaż denerwowanie pomaga przyspieszyć, nadal jest znacznie wolniejsze trenowanie przesunięcia niż trenowanie nachylenia stoku. Może to spowolnić i sprawić, że trenowanie będzie niestabilne.
Na przykład nasze początkowe odgadnięcia przesunięcia i nachylenia to zero. Jeśli zmieniamy nasze parametry o około 0,1 w każdej iteracji, szybko znajdziemy przesunięcie, ale bardzo trudno będzie znaleźć prawidłową nachylenie, ponieważ wzrost nachylenia będzie zbyt duży (0 + 0,1 > 0,01) i może zastąpić idealną wartość. Możemy zmniejszyć korekty, ale spowolni to, jak długo trwa znalezienie przechwycenia.
Co się stanie, jeśli przeskalujemy naszą funkcję wysokości?
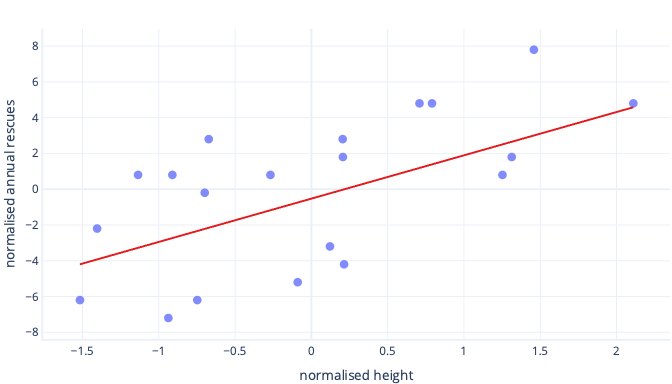
Nachylenie linii wynosi teraz 0,5. Zwróć uwagę na oś x. Nasze optymalne przecięcie -0,5 i nachylenie 0,5 to taka sama skala! Teraz można łatwo wybrać rozsądny rozmiar kroku, co oznacza szybkość aktualizacji parametrów spadku gradientu.
Skalowanie pomaga w wielu funkcjach
Gdy pracujemy z wieloma funkcjami, posiadanie tych elementów na innej skali może powodować problemy z dopasowaniem, podobnie jak w przypadku przykładów przechwytywania i nachyleń. Jeśli na przykład trenujemy model, który akceptuje zarówno wysokość w mm, jak i wagę w tonach metrycznych, wiele rodzajów modeli będzie musiało docenić znaczenie funkcji wagi, po prostu dlatego, że jest tak mała w stosunku do cech wysokości.
Czy zawsze muszę skalować?
Nie zawsze musimy skalować. Niektóre rodzaje modeli, w tym poprzednie modele z liniami prostymi, mogą być dopasowane bez procedury iteracyjnej, takiej jak spadek gradientu, więc nie mają nic przeciwko cechom, które są niewłaściwym rozmiarem. Inne modele wymagają skalowania, aby dobrze trenować, ale ich biblioteki często wykonują skalowanie funkcji automatycznie.
Ogólnie rzecz biorąc, jedynymi prawdziwymi wadami normalizacji lub standaryzacji są to, że może utrudnić interpretowanie naszych modeli i że musimy napisać nieco więcej kodu. Z tego powodu skalowanie funkcji jest standardową częścią tworzenia modeli uczenia maszynowego.