Co to jest klasyfikacja?
Klasyfikacja binarna to klasyfikacja z dwiema kategoriami. Na przykład możemy oznaczyć pacjentów jako chorych na cukrzycę lub cukrzycę.
Przewidywanie klasy jest wykonywane przez określenie prawdopodobieństwa dla każdej możliwej klasy jako wartości z zakresu od 0 (niemożliwe) do 1 (niektóre). Całkowite prawdopodobieństwo dla wszystkich klas wynosi zawsze 1, ponieważ pacjent jest zdecydowanie z cukrzycą lub bez cukrzycy. Jeśli więc przewidywane prawdopodobieństwo cukrzycy pacjenta wynosi 0,3, wówczas istnieje odpowiednie prawdopodobieństwo 0,7, że pacjent jest bez cukrzycy.
Wartość progowa, często 0,5, służy do określania przewidywanej klasy. Jeśli klasa dodatnia (w tym przypadku cukrzyca) ma przewidywane prawdopodobieństwo większe niż próg, przewidywana jest klasyfikacja cukrzycy.
Trenowanie i ocenianie modelu klasyfikacji
Klasyfikacja jest przykładem nadzorowanejtechniki uczenia maszynowego, co oznacza, że opiera się na danych, które zawierają znane wartości funkcji i znane wartości etykiet. W tym przykładzie wartości funkcji są pomiarami diagnostycznymi dla pacjentów, a wartości etykiet są klasyfikacją osób bez cukrzycy lub cukrzycy. Algorytm klasyfikacji służy do dopasowania podzestawu danych do funkcji, która może obliczyć prawdopodobieństwo dla każdej etykiety klasy z wartości funkcji. Pozostałe dane są używane do oceny modelu przez porównanie przewidywań generowanych z funkcji do znanych etykiet klas.
Prosty przykład
Przyjrzyjmy się przykładowi, aby wyjaśnić kluczowe zasady. Załóżmy, że mamy następujące dane pacjentów, które składają się z jednej funkcji (poziomu glukozy we krwi) i etykiety klasy 0 dla cukrzycy, 1 dla cukrzycy.
| Stężenie glukozy we krwi | Cukrzycowej |
|---|---|
| 82 | 0 |
| 92 | 0 |
| 112 | 1 |
| 102 | 0 |
| 210 | 1 |
| 107 | 1 |
| 87 | 0 |
| 120 | 1 |
| 83 | 0 |
| 119 | 1 |
| 104 | 1 |
| 105 | 0 |
| 86 | 0 |
| 109 | 1 |
Używamy pierwszych ośmiu obserwacji do trenowania modelu klasyfikacji i zaczynamy od wykreślenia funkcji glukozy we krwi (x) i przewidywanej etykiety cukrzycy (y).
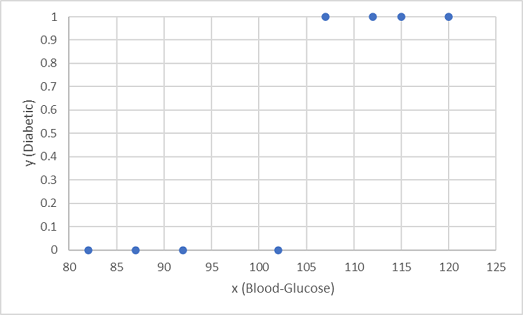
Potrzebujemy funkcji, która oblicza wartość prawdopodobieństwa dla y na podstawie wartości x (innymi słowy, potrzebujemy funkcji f(x) = y). Na wykresie widać, że pacjenci z niskim poziomem glukozy we krwi są wszyscy bez cukrzycy, podczas gdy pacjenci z wyższym poziomem glukozy we krwi są cukrzycowe. Wydaje się, że im wyższy poziom glukozy we krwi, tym bardziej prawdopodobne jest, że pacjent jest cukrzycowy, a punkt przegięcia jest gdzieś między 100 a 110. Musimy dopasować funkcję, która oblicza wartość z zakresu od 0 do 1 dla wartości y.
Jedną z takich funkcji jest funkcja logistyczna , która tworzy krzywą sigmoidalną (w kształcie S).
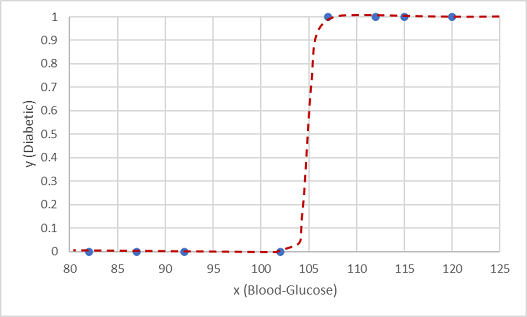
Teraz możemy użyć funkcji , aby obliczyć wartość prawdopodobieństwa, która jest dodatnia, co oznacza, że pacjent ma cukrzycę, z dowolnej wartości x, wyszukując punkt w wierszu funkcji x. Możemy ustawić wartość progową 0,5 jako punkt odcięty dla przewidywania etykiety klasy.
Przetestujmy ją przy użyciu dwóch wartości danych, które wstrzymaliśmy.
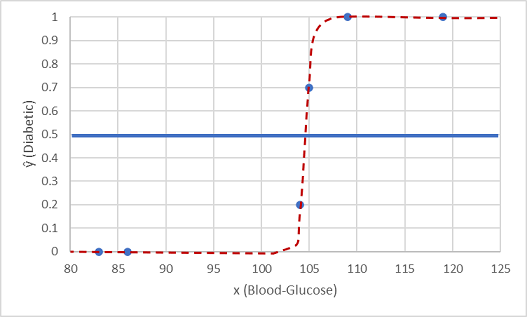
Punkty nakreślone poniżej linii progowej dają przewidywaną klasę 0 (bez cukrzycy) i punkty powyżej linii są przewidywane jako 1 (cukrzyca).
Teraz możemy porównać przewidywania etykiet (ŷ lub "y-hat"), na podstawie funkcji logistycznej hermetyzowanej w modelu do rzeczywistych etykiet klas (y).
| x | t | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |