Ocena modeli klasyfikacji
Dokładność trenowania modelu klasyfikacji jest znacznie mniej ważna niż to, jak dobrze ten model będzie działać, gdy dane nowych, niezauważonych danych. W końcu trenujemy modele, aby mogły być używane na nowych danych, które znajdują się w świecie rzeczywistym. Dlatego po wytrenowanym modelu klasyfikacji ocenimy, jak działa on na zestawie nowych, niezaświetczonych danych.
W poprzednich lekcjach utworzyliśmy model, który przewidywałby, czy pacjent miał cukrzycę, czy nie na podstawie poziomu glukozy we krwi. Teraz po zastosowaniu do niektórych danych, które nie były częścią zestawu treningowego, uzyskujemy następujące przewidywania.
| x | t | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |
Pamiętaj, że x odnosi się do poziomu glukozy we krwi, y odnosi się do tego, czy są one rzeczywiście cukrzycowe, a ŷ odnosi się do przewidywania modelu, czy są one cukrzycowe, czy nie.
Wystarczy obliczyć, ile przewidywań było poprawnych, jest czasami mylące lub zbyt uproszczone, aby zrozumieć rodzaje błędów, które będą popełniane w świecie rzeczywistym. Aby uzyskać bardziej szczegółowe informacje, możemy tabelarować wyniki w strukturze nazywanej macierzą pomyłek, w następujący sposób:
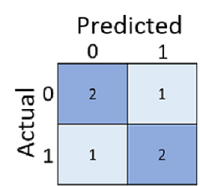
Macierz pomyłek przedstawia łączną liczbę przypadków, w których:
- Model przewidział 0, a rzeczywista etykieta to 0 (prawdziwie ujemne, w lewym górnym rogu)
- Model przewidział 1, a rzeczywista etykieta to 1 (prawdziwie dodatnie, prawe dolne)
- Model przewidział 0, a rzeczywista etykieta to 1 (fałszywie ujemne, w lewym dolnym rogu)
- Model przewidział 1, a rzeczywista etykieta to 0 (wyniki fałszywie dodatnie, prawy górny)
Komórki w macierzy pomyłek są często cieniowane, aby wyższe wartości miały głębszy cień. Ułatwia to wyświetlanie silnego trendu ukośnego od lewej górnej do prawej do dołu, podkreślając komórki, w których przewidywana wartość i rzeczywista wartość są takie same.
Na podstawie tych podstawowych wartości można obliczyć zakres innych metryk, które mogą pomóc w ocenie wydajności modelu. Na przykład:
- Dokładność: (TP+TN)/(TP+TN+FP+FN) - poza wszystkimi przewidywaniami, ile było poprawnych?
- Przypomnij sobie: TP/(TP+FN) — wszystkich przypadków, które są pozytywne, ile zidentyfikował model?
- Precyzja: TP/(TP+FP) — wszystkich przypadków przewidywanych przez model dodatnich, ile rzeczywiście jest dodatnich?