Splotowe sieci neuronowe
Modele uczenia głębokiego można używać w przypadku dowolnego rodzaju uczenia maszynowego, ale są szczególnie przydatne do obsługi danych składających się z dużych tablic wartości liczbowych , takich jak obrazy. Modele uczenia maszynowego, które współpracują z obrazami, stanowią podstawę dla obszaru sztucznej inteligencji nazywanej przetwarzaniem obrazów, a techniki uczenia głębokiego są odpowiedzialne za prowadzenie niesamowitych postępów w tym obszarze w ostatnich latach.
W centrum sukcesu uczenia głębokiego w tym obszarze jest rodzaj modelu nazywanego splotową siecią neuronową lub siecią CNN. Sieć CNN zwykle działa przez wyodrębnianie funkcji z obrazów, a następnie przekazywanie tych funkcji do w pełni połączonej sieci neuronowej w celu wygenerowania przewidywania. Warstwy wyodrębniania cech w sieci mają wpływ na zmniejszenie liczby funkcji z potencjalnie ogromnej tablicy pojedynczych wartości pikseli do mniejszego zestawu funkcji obsługującego przewidywanie etykiet.
Warstwy w sieci CNN
Nazwy CNN składają się z wielu warstw, z których każda wykonuje określone zadanie w wyodrębnieniu funkcji lub przewidywaniu etykiet.
Warstwy splotu
Jednym z głównych typów warstw jest splotowa warstwa, która wyodrębnia ważne cechy na obrazach. Warstwa splotowa działa przez zastosowanie filtru do obrazów. Filtr jest definiowany przez jądro , które składa się z macierzy wartości wagowych.
Na przykład filtr 3x3 może być zdefiniowany w następujący sposób:
1 -1 1
-1 0 -1
1 -1 1
Obraz jest również tylko macierzą wartości pikseli. Aby zastosować filtr, "nakładasz" go na obraz i obliczasz ważoną sumę odpowiadających wartości pikseli obrazu w jądrze filtru. Wynik jest następnie przypisywany do komórki środkowej równoważnej poprawki 3x3 w nowej macierzy wartości o tym samym rozmiarze co obraz. Załóżmy na przykład, że obraz 6 x 6 ma następujące wartości pikseli:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
Zastosowanie filtru do lewej górnej 3x3 poprawki obrazu będzie działać następująco:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
Wynik jest przypisywany do odpowiedniej wartości pikseli w nowej macierzy w następujący sposób:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Teraz filtr jest przenoszony wzdłuż (convolved), zazwyczaj przy użyciu kroku o rozmiarze 1 (tak przesuwając się wzdłuż jednego piksela po prawej stronie), a wartość następnego piksela jest obliczana
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Teraz możemy wypełnić następną wartość nowej macierzy.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Proces powtarza się do momentu zastosowania filtru we wszystkich 3x3 poprawek obrazu w celu utworzenia nowej macierzy wartości w następujący sposób:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
Ze względu na rozmiar jądra filtru nie możemy obliczyć wartości dla pikseli na krawędzi; dlatego zwykle stosujemy tylko wartość dopełnienia (często 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
Dane wyjściowe konwoju są zwykle przekazywane do funkcji aktywacji, która jest często funkcją ReLU (Rectified Linear Unit ), która zapewnia, że wartości ujemne są ustawione na 0:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
Wynikowa macierz jest mapą cech wartości funkcji, które mogą służyć do trenowania modelu uczenia maszynowego.
Uwaga: Wartości na mapie funkcji mogą być większe niż maksymalna wartość pikseli (255), więc jeśli chcesz zwizualizować mapę funkcji jako obraz, musisz znormalizować wartości funkcji z zakresu od 0 do 255.
Proces splotu jest wyświetlany w poniższej animacji.

- Obraz jest przekazywany do warstwy splotowej. W tym przypadku obraz jest prostym kształtem geometrycznym.
- Obraz składa się z tablicy pikseli z wartościami z zakresu od 0 do 255 (w przypadku obrazów kolorów jest to zwykle tablica 3-wymiarowa z wartościami dla czerwonych, zielonych i niebieskich kanałów).
- Jądro filtru jest zwykle inicjowane przy użyciu losowych wag (w tym przykładzie wybraliśmy wartości, aby podkreślić efekt, jaki filtr może mieć na wartości pikseli; ale w rzeczywistej sieci CNN początkowe wagi będą zwykle generowane na podstawie losowego rozkładu Gaussańskiego). Ten filtr będzie używany do wyodrębniania mapy funkcji z danych obrazu.
- Filtr jest rozdzielany na obrazie, obliczając wartości funkcji, stosując sumę wag pomnożonych przez odpowiadające im wartości pikseli w każdej pozycji. Funkcja aktywacji reLU (Rectified Linear Unit) jest stosowana w celu zapewnienia, że wartości ujemne są ustawione na 0.
- Po konolucji mapa funkcji zawiera wyodrębnione wartości funkcji, które często podkreślają kluczowe atrybuty wizualne obrazu. W tym przypadku mapa funkcji wyróżnia krawędzie i rogi trójkąta na obrazie.
Zazwyczaj warstwa konwolucyjna stosuje wiele jąder filtrów. Każdy filtr tworzy inną mapę funkcji, a wszystkie mapy funkcji są przekazywane do następnej warstwy sieci.
Warstwy buforowania
Po wyodrębnieniu wartości funkcji z obrazów warstwy buforowania (lub próbkowania w dół) są używane do zmniejszenia liczby wartości funkcji przy zachowaniu kluczowych funkcji wyróżniających, które zostały wyodrębnione.
Jednym z najczęstszych rodzajów buforowania jest maksymalna pula, w której filtr jest stosowany do obrazu, a tylko maksymalna wartość pikseli w obszarze filtru jest zachowywana. Na przykład zastosowanie jądra puli 2x2 do następującej poprawki obrazu spowoduje wygenerowanie wyniku 155.
0 0
0 155
Należy pamiętać, że efektem filtru puli 2x2 jest zmniejszenie liczby wartości z 4 do 1.
Podobnie jak w przypadku warstw splotowych warstwy puli działają przez zastosowanie filtru na całej mapie funkcji. Poniższa animacja przedstawia przykład maksymalnej puli dla mapy obrazu.

- Mapa funkcji wyodrębniona przez filtr w warstwie splotowej zawiera tablicę wartości funkcji.
- Jądro buforowania służy do zmniejszenia liczby wartości funkcji. W tym przypadku rozmiar jądra wynosi 2x2, więc będzie generować tablicę z ćwiartkami liczby wartości funkcji.
- Jądro buforowania jest połączone na mapie funkcji, zachowując tylko najwyższą wartość pikseli w każdej pozycji.
Upuszczanie warstw
Jednym z najtrudniejszych wyzwań w sieci CNN jest unikanie nadmiernego dopasowania, gdzie wynikowy model działa dobrze z danymi treningowymi, ale nie uogólnia nowych danych, na których nie został wytrenowany. Jedną z technik, których można użyć do ograniczenia nadmiernego dopasowania, jest uwzględnienie warstw, w których proces trenowania losowo eliminuje (lub "krople") mapy funkcji. Może to wydawać się sprzeczne, ale jest to skuteczny sposób zapewnienia, że model nie uczy się być nadmiernie zależny od obrazów szkoleniowych.
Inne techniki, których można użyć do ograniczenia nadmiernego dopasowania, obejmują losowe przerzucanie, dublowanie lub niesymetryczność obrazów treningowych w celu generowania danych, które różnią się między epokami trenowania.
Spłaszczanie warstw
Po korzystaniu z warstw splotowych i buforowania w celu wyodrębnienia ważnych funkcji na obrazach wynikowe mapy funkcji są wielowymiarowymi tablicami wartości pikseli. Warstwa spłaszczania służy do spłaszczania map funkcji w wektor wartości, które mogą być używane jako dane wejściowe do w pełni połączonej warstwy.
W pełni połączone warstwy
Zazwyczaj sieć CNN kończy się w pełni połączoną siecią, w której wartości funkcji są przekazywane do warstwy wejściowej, przez co najmniej jedną ukrytą warstwę i generują przewidywane wartości w warstwie wyjściowej.
Podstawowa architektura CNN może wyglądać mniej więcej tak:
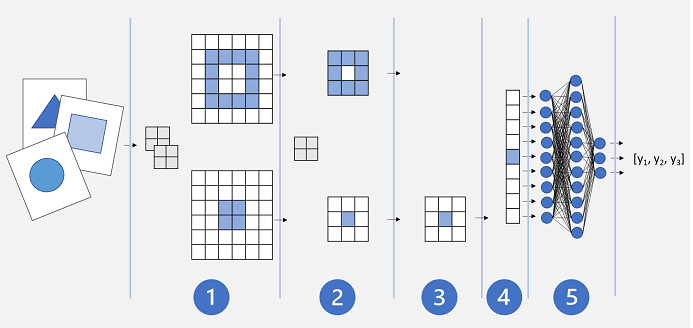
- Obrazy są przekazywane do warstwy konwolucyjnej. W tym przypadku istnieją dwa filtry, więc każdy obraz tworzy dwie mapy funkcji.
- Mapy funkcji są przekazywane do warstwy buforowania, gdzie jądro puli 2x2 zmniejsza rozmiar map funkcji.
- Porzucanie warstwy losowo spada niektóre mapy funkcji, aby zapobiec nadmiernemu dopasowaniu.
- Warstwa spłaszczania pobiera pozostałe tablice map funkcji i spłaszcza je w wektor.
- Elementy wektorów są przekazywane do w pełni połączonej sieci, która generuje przewidywania. W tym przypadku sieć jest modelem klasyfikacji, który przewiduje prawdopodobieństwo trzech możliwych klas obrazów (trójkąt, kwadrat i okrąg).
Trenowanie modelu CNN
Podobnie jak w przypadku każdej głębokiej sieci neuronowej, sieć CNN jest trenowana przez przekazywanie partii danych treningowych przez wiele epok, dostosowywanie wag i wartości stronniczości na podstawie straty obliczonej dla każdej epoki. W przypadku sieci CNN, backpropagation dostosowanych wag obejmuje wagi jądra filtru używane w warstwach splotowych, a także wagi używane w w pełni połączonych warstwach.