Wizualizowanie danych za pomocą platformy Spark
Jednym z najbardziej intuicyjnych sposobów analizowania wyników zapytań dotyczących danych jest wizualizowanie ich jako wykresów. Notesy w usłudze Azure Synapse Analytics udostępniają pewne podstawowe funkcje tworzenia wykresów w interfejsie użytkownika, a gdy ta funkcja nie zapewnia potrzebnych elementów, możesz użyć jednej z wielu bibliotek graficznych języka Python do tworzenia i wyświetlania wizualizacji danych w notesie.
Korzystanie z wbudowanych wykresów notesów
Po wyświetleniu ramki danych lub uruchomieniu zapytania SQL w notesie platformy Spark w usłudze Azure Synapse Analytics wyniki są wyświetlane w komórce kodu. Domyślnie wyniki są renderowane jako tabela, ale można również zmienić widok wyników na wykres i użyć właściwości wykresu, aby dostosować sposób wizualizacji danych na wykresie, jak pokazano poniżej:
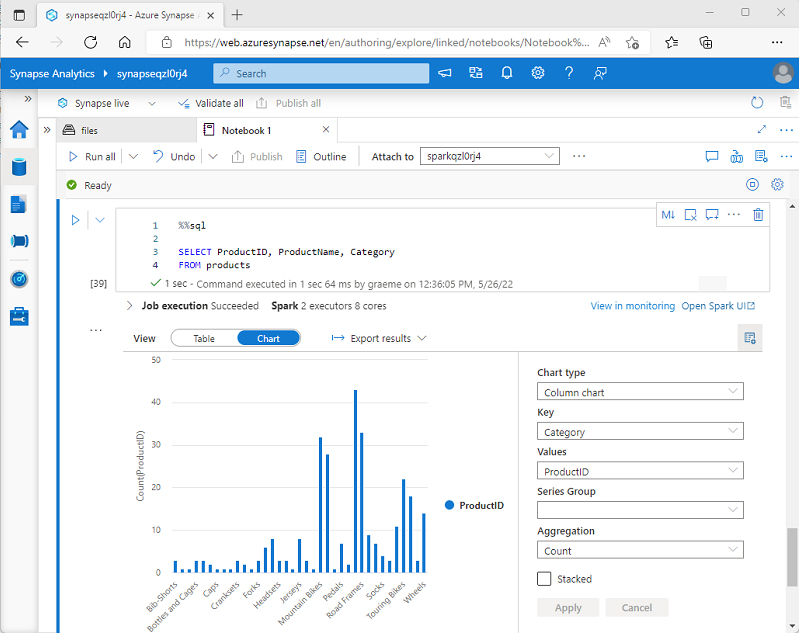
Wbudowana funkcja tworzenia wykresów w notesach jest przydatna podczas pracy z wynikami zapytania, które nie zawierają żadnych istniejących grup lub agregacji, i chcesz szybko podsumować dane wizualnie. Jeśli chcesz mieć większą kontrolę nad sposobem formatowania danych lub wyświetlić wartości, które zostały już zagregowane w zapytaniu, należy rozważyć użycie pakietu graficznego do utworzenia własnych wizualizacji.
Używanie pakietów graficznych w kodzie
Istnieje wiele pakietów graficznych, których można użyć do tworzenia wizualizacji danych w kodzie. W szczególności język Python obsługuje duży wybór pakietów; większość z nich oparta na podstawowej bibliotece Matplotlib . Dane wyjściowe z biblioteki grafiki można renderować w notesie, co ułatwia łączenie kodu w celu pozyskiwania i manipulowania danymi za pomocą wbudowanych wizualizacji danych i komórek markdown w celu udostępnienia komentarza.
Na przykład można użyć następującego kodu PySpark, aby agregować dane z hipotetycznych danych produktów eksplorowanych wcześniej w tym module i użyć biblioteki Matplotlib do utworzenia wykresu na podstawie zagregowanych danych.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Biblioteka Matplotlib wymaga, aby dane były w ramce danych biblioteki Pandas, a nie w ramce danych platformy Spark, więc metoda toPandas jest używana do jej konwersji. Następnie kod tworzy rysunek o określonym rozmiarze i wykreśli wykres słupkowy z konfiguracją właściwości niestandardowych przed wyświetleniem wynikowego wykresu.
Wykres utworzony przez kod będzie wyglądać podobnie do poniższego obrazu:
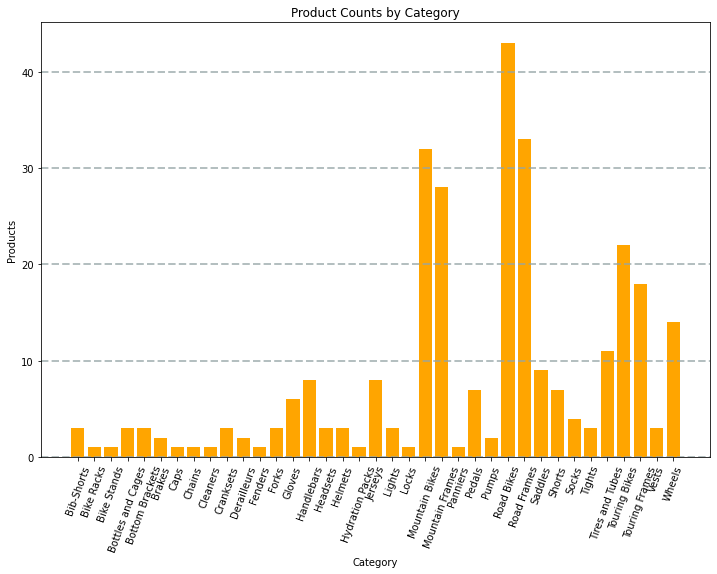
Możesz użyć biblioteki Matplotlib, aby utworzyć wiele rodzajów wykresu; lub jeśli jest to preferowane, możesz użyć innych bibliotek, takich jak Seaborn , aby utworzyć wysoce dostosowane wykresy.