Poznaj platformę Spark
Aby lepiej zrozumieć, jak przetwarzać i analizować dane za pomocą platformy Apache Spark w usłudze Azure Databricks, ważne jest, aby zrozumieć podstawową architekturę.
Ogólne omówienie
Na wysokim poziomie usługa Azure Databricks uruchamia klastry Apache Spark i zarządza nimi w ramach subskrypcji platformy Azure. Klastry Apache Spark to grupy komputerów, które są traktowane jako pojedynczy komputer i obsługują wykonywanie poleceń wydanych z notesów. Klastry umożliwiają równoległe przetwarzanie danych na wielu komputerach w celu zwiększenia skali i wydajności. Składają się one z węzłów sterownika platformy Spark i procesu roboczego. Węzeł sterownika wysyła pracę do węzłów procesu roboczego i nakazuje im ściąganie danych z określonego źródła danych.
W usłudze Databricks interfejs notesu jest zazwyczaj programem sterowników. Ten program sterowników zawiera pętlę główną programu i tworzy rozproszone zestawy danych w klastrze, a następnie stosuje operacje do tych zestawów danych. Programy sterowników uzyskują dostęp do platformy Apache Spark za pośrednictwem obiektu SparkSession niezależnie od lokalizacji wdrożenia.
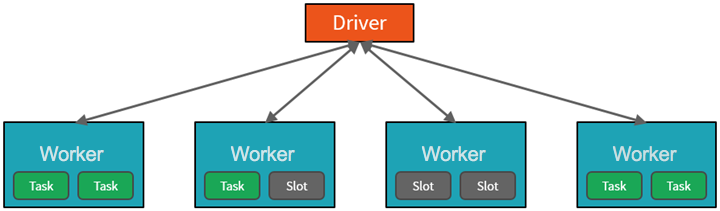
Platforma Microsoft Azure zarządza klastrem i automatycznie skaluje go zgodnie z potrzebami na podstawie użycia i ustawienia używanego podczas konfigurowania klastra. Automatyczne kończenie można również włączyć, co umożliwia platformie Azure zakończenie działania klastra po określonej liczbie minut braku aktywności.
Zadania platformy Spark szczegółowo
Praca przesłana do klastra jest podzielona na tyle niezależnych zadań, ile jest potrzebnych. W ten sposób praca jest dystrybuowana między węzłami klastra. Zadania są dalej podzielone na zadania. Dane wejściowe zadania są podzielone na co najmniej jedną partycję. Te partycje są jednostką pracy dla każdego miejsca. W przypadku zadań między partycjami może być konieczna reorganizacja i współdzielona za pośrednictwem sieci.
Kluczem do wysokiej wydajności platformy Spark jest równoległość. Skalowanie w pionie (przez dodanie zasobów do pojedynczego komputera) jest ograniczone do ograniczonej ilości pamięci RAM, wątków i szybkości procesora CPU, ale klastry są skalowane w poziomie, dodając nowe węzły do klastra zgodnie z potrzebami.
Spark parallelizuje zadania na dwóch poziomach:
- Pierwszym poziomem równoległości jest funkcja wykonawcza — maszyna wirtualna Java (JVM) uruchomiona w węźle roboczym, zazwyczaj jedno wystąpienie na węzeł.
- Drugi poziom równoległości to miejsce — liczba z nich jest określana przez liczbę rdzeni i procesorów CPU każdego węzła.
- Każda funkcja wykonawcza ma wiele miejsc, do których można przypisać zadania równoległe.
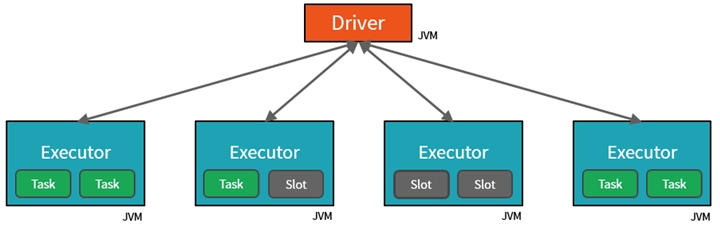
JVM jest naturalnie wielowątkowy, ale pojedynczy JVM, taki jak jeden koordynujący pracę nad sterownikiem, ma skończony górny limit. Dzięki podzieleniu pracy na zadania sterownik może przypisać jednostki pracy do *miejsc w funkcjach wykonawczych w węzłach roboczych na potrzeby wykonywania równoległego. Ponadto sterownik określa sposób partycjonowania danych, aby można je było dystrybuować na potrzeby przetwarzania równoległego. W związku z tym sterownik przypisuje partycję danych do każdego zadania, aby każde zadanie wiedziało, który element danych ma zostać przetworzyny. Po uruchomieniu każde zadanie pobierze przypisaną do niego partycję danych.
Zadania i etapy
W zależności od wykonywanej pracy może być wymaganych wiele zadań równoległych. Każde zadanie jest podzielone na etapy. Przydatną analogią jest wyobrazić sobie, że zadaniem jest zbudowanie domu:
- Pierwszym etapem byłoby ustanowienie fundamentu.
- Drugim etapem byłoby wzniesienie ścian.
- Trzecim etapem byłoby dodanie dachu.
Próba wykonania któregokolwiek z tych kroków poza kolejnością po prostu nie ma sensu i może być w rzeczywistości niemożliwe. Podobnie platforma Spark dzieli każde zadanie na etapy, aby upewnić się, że wszystko jest wykonywane w odpowiedniej kolejności.