Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano funkcje usługi Azure Monitor Application Insights, które są przydatne do rozwiązywania problemów związanych z aplikacjami.
Uwaga 16.
Ten artykuł dotyczy zarówno klasycznej usługi w chmurze, jak i rozszerzonej obsługi usługi w chmurze.
Konfigurowanie usługi Application Insights dla aplikacji usługi w chmurze
Aby monitorować aplikację za pomocą usługi Application Insights, wykonaj następujące kroki:
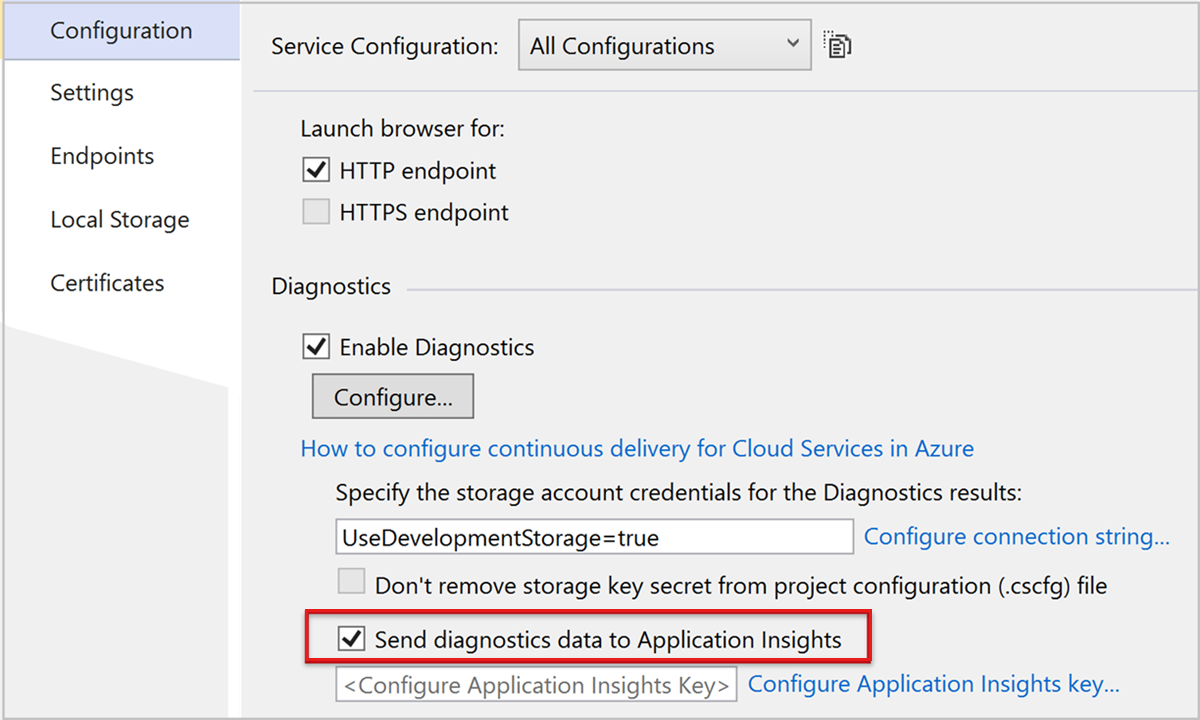
- W programie Visual Studio Eksplorator rozwiązań w obszarze Role usługi>w chmurze otwórz właściwości każdej roli.
- W obszarze Konfiguracja zaznacz pole wyboru Wyślij dane diagnostyczne do usługi Application Insights , a następnie wybierz utworzone wcześniej wystąpienie usługi Application Insights.
W przypadku ról internetowych ta opcja zapewnia monitorowanie wydajności, alerty, diagnostykę i analizę użycia. W przypadku innych ról można wyszukiwać i monitorować Diagnostyka Azure, takie jak liczniki ponownego uruchamiania i wydajności.
Diagnozowanie błędów w usłudze Application Insights
Usługa Application Insights oferuje wyselekcjonowane środowisko zarządzania wydajnością aplikacji, które ułatwia diagnozowanie błędów w monitorowanych aplikacjach. Aby wyświetlić błędy w witrynie Azure Portal, przejdź do wystąpienia usługi Application Insights, a następnie wybierz pozycję Błędy w obszarze Badanie.
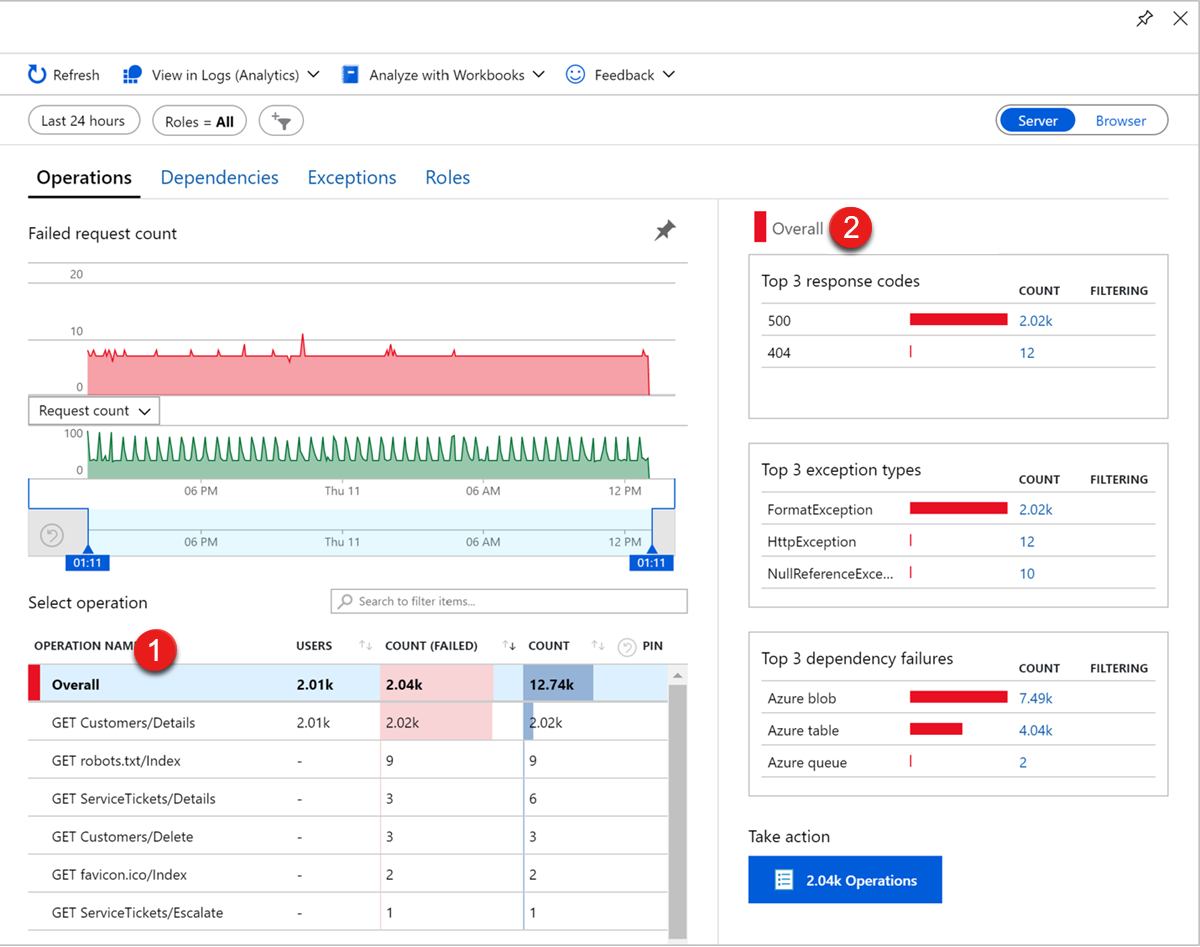
Zobaczysz trendy współczynnika niepowodzeń dla żądań, liczbę z nich kończy się niepowodzeniem i liczbę użytkowników, których dotyczy problem. Tabela operacji, którazakończyła się niepowodzeniem, zawiera żądania, które są pogrupowane według adresu URL żądania. W widokuOgólnym 2 zobaczysz trzy najważniejsze kody odpowiedzi, trzy najważniejsze typy wyjątków i trzy najważniejsze typy zależności zakończonych niepowodzeniem.
Aby przejrzeć reprezentatywne przykłady dla każdego z tych podzestawów operacji, wybierz odpowiedni link. Aby na przykład zdiagnozować wyjątki, możesz wybrać liczbę określonego wyjątku, który ma zostać wyświetlony na karcie Szczegóły transakcji kompleksowej.
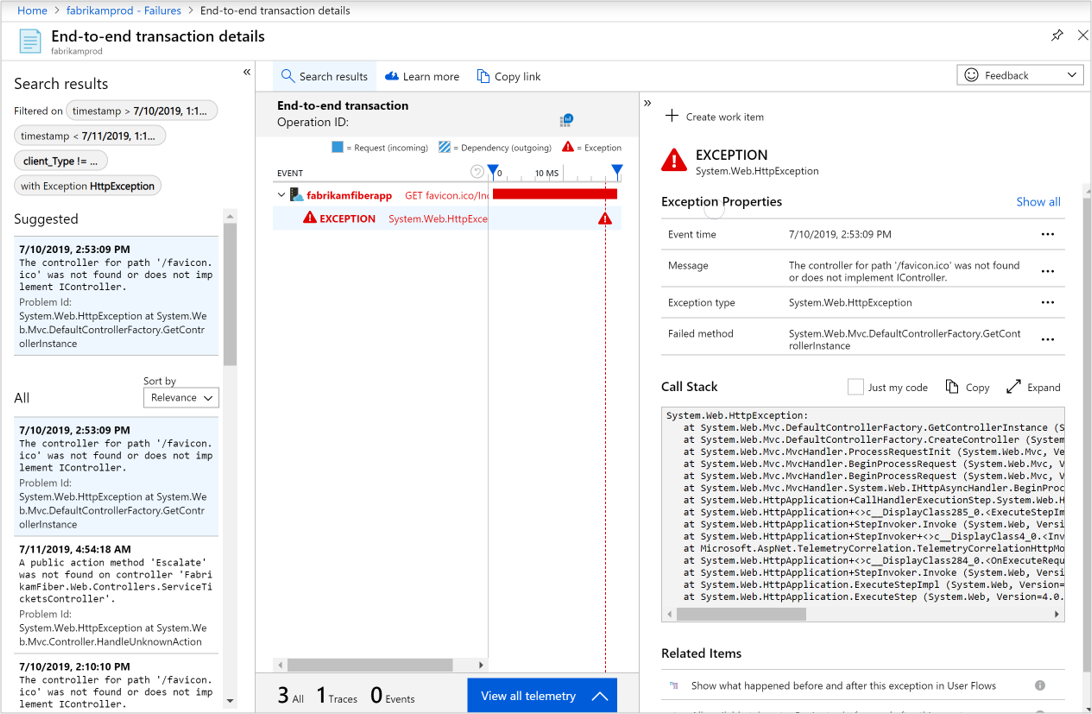
Poniższe informacje w szczegółach kompleksowej transakcji są przydatne do rozwiązywania problemów:
- Sygnatura czasowa żądania
- Kod odpowiedzi
- Czas odpowiedzi
- Komunikat o wyjątku
- Typ wyjątku
- Stos wywołań
Diagnozowanie problemów z wydajnością w usłudze Application Insights
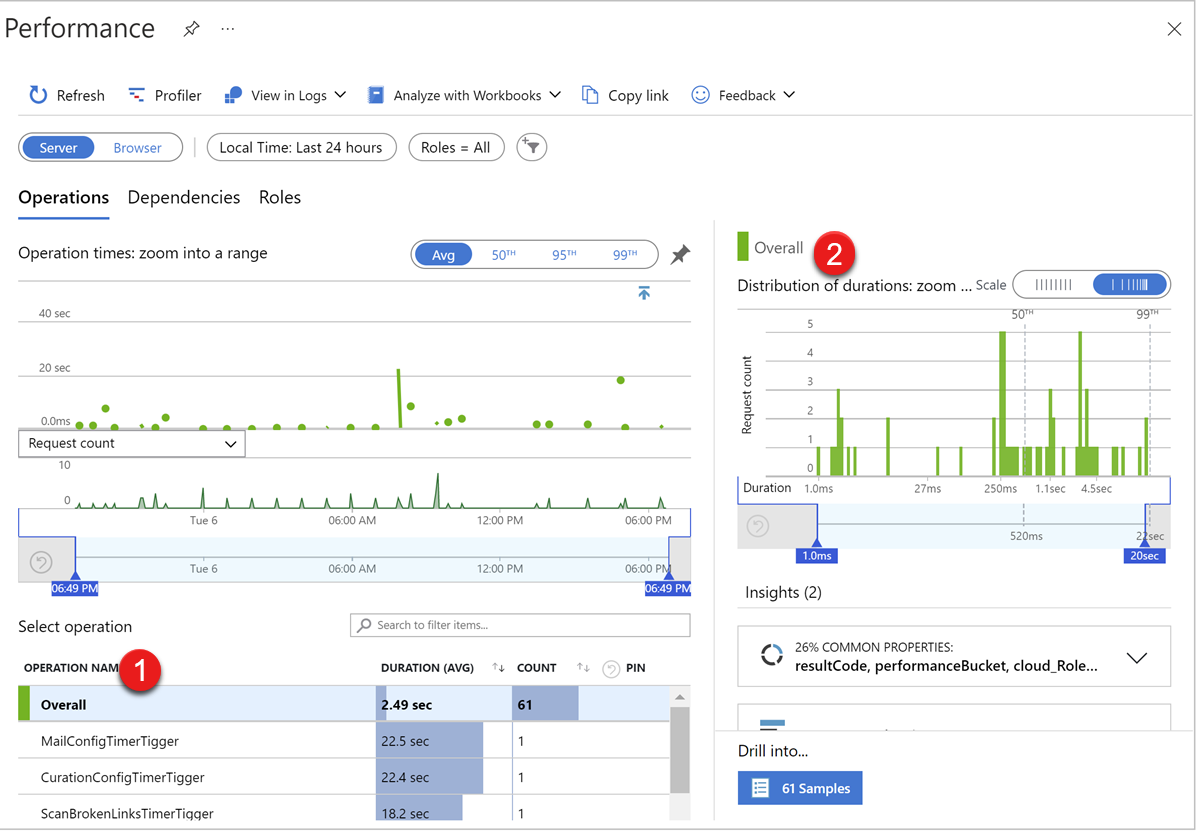
Aby zdiagnozować problemy z wydajnością roli internetowej, możemy sprawdzić następujące dane na stronie Wydajność wystąpienia usługi Application Insights:
- Czas odpowiedzi na żądania roli sieci Web
- Procesor CPU, pamięć, we/wy dysku, sieciowe we/wy wystąpienia roli sieci Web
Na karcie Operacje tabela operacji , którezakończyły się niepowodzeniem, tabela 1 zawiera nazwę operacji żądania, czas trwania, podsumowanie liczby żądań. Wybierz operację i odświeży wykresmetryk 2 , aby wyświetlić wykres metryk żądania i metryki czasu trwania.
Karta Role zawiera dane metryk bardziej powiązane z serwerem usługi w chmurze, takie jak procesor CPU, dostępna pamięć, żądania obsługiwane przez każde wystąpienie itd.
Alert w usłudze Application Insights
Alert umożliwia użytkownikom ustawianie reguł niestandardowych w celu monitorowania stanu wystąpienia roli usługi w chmurze. Po wystąpieniu monitorowanego zdarzenia użytkownicy mogą otrzymywać powiadomienia e-mail.
Reguły zawierają głównie dwie ważne części: warunki i akcje. Aby utworzyć alert, wykonaj następujące kroki:
W witrynie Azure Portal przejdź do wystąpienia usługi Application Insights i wybierz pozycję Alert w sekcji Monitorowanie . Na tej stronie są widoczne wszystkie wyzwolone alerty. Rozwiń węzeł + Utwórz, a następnie wybierz pozycję Reguła alertu.
Konfigurowanie warunków. Warunek składa się z trzech punktów: Sygnał, Wymiar i Logika alertu. Aby uzyskać więcej informacji, zobacz Typy alertów usługi Azure Monitor.
- Signal to typ danych metryk, które będzie monitorować reguła alertu. Można użyć typowych danych metryk, takich jak procesor CPU, dostępna pamięć, żądania, wyjątki i czas odpowiedzi.
- Wymiar określa zakres lub filtr, w którym zostanie zastosowana ta reguła alertu. W przypadku reguł alertów opartych na danych metryk usługi w chmurze zwykle zawierają one dwa możliwe opcje wymiarów: wystąpienie roli w chmurze i nazwę roli chmury. Oprócz tych dwóch wymiarów będzie również kilka innych wyborów w zależności od sygnału.
- Logika alertu to miejsce, w którym należy ustawić logikę warunku reguły alertu. Istnieje kilka ważnych pojęć:
- Próg oznacza, czy wynik oceny jest dynamiczny, czy statyczny. Jeśli jest statyczna, obliczone dane metryk (liczba żądań niepomyślnie w tym przykładzie) będą porównywane z wartością statyczną, taką jak 5 lub 10. Jeśli jest to dynamiczny, oceniane dane będą porównywane z tymi samymi danymi w ciągu ostatniego krótkiego okresu, na przykład z ostatnich pięciu minut.
- Operator, Typ agregacji, Wartość progowa i Jednostka są łatwe do zrozumienia; reprezentują główną treść logiki.
- Stopień szczegółowości agregacji, nazywany również "okresem", określa, jak długo będą oceniane dane metryk w historii. Jeśli jest to pięć minut, oznacza to, że dane metryk z ostatnich pięciu minut zostaną ocenione. Częstotliwość oceny oznacza, jak często zostanie wyzwolona ocena.
Ustaw akcję po wyzwoleniu reguły alertu. Możesz utworzyć nową grupę akcji i dodać ją do tej reguły alertu lub użyć istniejącej grupy akcji.
Aby utworzyć nową grupę akcji, wykonaj następujące kroki:
- Wybierz subskrypcję i grupę zasobów, w której zostanie utworzony zasób grupy akcji, i nadaj nazwę i nazwę wyświetlaną.
- Opcjonalnie) Wybierz sposób informowania użytkownika o wyzwoleniu reguły alertu, takiej jak wysyłanie wiadomości e-mail na określony adres e-mail.
- (Opcjonalnie) Wybierz akcję, która zostanie wykonana. W tej opcji możemy wyzwolić element Runbook usługi Automation, funkcję platformy Azure i pięć innych typów usług.
Po utworzeniu grupy akcji zostanie ona również dodana do reguły alertu.
Na stronie Szczegóły wybierz subskrypcję i grupę zasobów, w której chcesz zapisać regułę alertu i ustawić jej nazwę i poziom ważności.
Wykres metryk w usłudze Application Insights
Wykres metryk w usłudze Application Insights może służyć do wizualizacji zmian danych. Jest to dość przydatne do monitorowania stanu usługi w zakresie czasu, takim jak kilka dni lub tygodni.
Dane, które mają być monitorowane, można skonfigurować za pomocą następujących punktów:
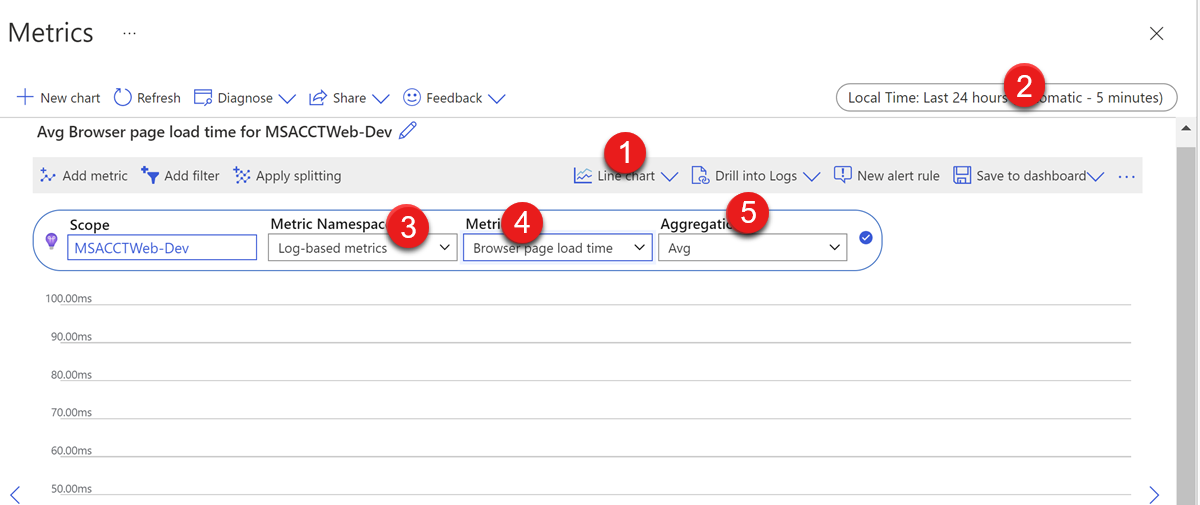
- Typ wykresu — typ wykresu, który chcesz zobaczyć. Możesz wybrać wykres liniowy, wykres warstwowy, wykres słupkowy, wykres punktowy i siatkę.
- Zakres czasu — zakres czasu danych metryk do wygenerowania wykresu (zwróć uwagę na różnicę między czasem lokalnym a UTC).
- Przestrzeń nazw metryk — grupa możliwych danych metryk. Zwykle wystarczy wybrać metryki standardowe oparte na dziennikach i usługi Application Insights. Wszystkie dane będą zbierane domyślnie, takie jak procesor CPU, pamięć, żądania, wyjątki itd. Niektóre bardziej szczegółowe dane zebrane przez dostosowane ustawienia, takie jak czas procesora procesu w3wp (który można skonfigurować w ustawieniu diagnostycznym usługi w chmurze), zostaną uwzględnione w metrykach opartych na dziennikach.
- Metryka — dane, dla których chcesz wygenerować wykres.
- Agregacja — typ statystyki obliczonej na podstawie wielu wartości metryk. Aby uzyskać więcej informacji, zapoznaj się z tym dokumentem. Zdecydowanie zaleca się zachowanie tej wartości jako wartości domyślnej. Należy je modyfikować tylko wtedy, gdy zrozumiesz, w jaki sposób ten typ danych metryk jest zbierany i różnice między wszystkimi typami agregacji.
Napiwek
Czasami na wykresie będą kropkowane linie. Oznacza to, że dane w tym zakresie czasu nie są wystarczająco dokładne lub nie są zbierane. Powodem jest to, że dane w tym okresie nie są kontynuowane. Załóżmy, że gdy dane metryk są zbierane co dwie minuty, ale różnica czasu między dwoma punktami na wykresie wynosi minutę, dane nie będą wystarczająco dokładne, aby wygenerować wykres, więc będzie to linia kropkowana.
Zebrane dzienniki w usłudze Application Insights
Prawie wszystkie przedstawione powyżej funkcje usługi Application Insights są oparte na danych zebranych jako dziennik. Użytkownicy mogą również sprawdzić te dzienniki bezpośrednio, aby uzyskać bardziej szczegółowe informacje, które nie są wyświetlane na stronach.
Aby wyświetlić dzienniki, wybierz pozycję Dzienniki w sekcji Monitorowanie .
Na stronie Dzienniki należy użyć język zapytań Kusto (KQL) do wykonywania zapytań lub filtrowania zebranych dzienników i uzyskiwania wymaganych informacji.
Istnieją tylko dwa punkty, na które należy zwrócić uwagę; zakres czasu i zapytanie.
Zakres czasu po górnej stronie może ustawić zakres czasu dzienników, które chcemy sprawdzić. Pamiętaj, aby zwrócić uwagę na różnicę między czasem lokalnym a czasem UTC.
Zapytanie zostanie skompilowane w dwóch częściach: nazwa tabeli w pierwszym wierszu i warunek używany do filtrowania wyników.
Oto często używane tabele:
| Tabela w wystąpieniu usługi Application Insights | Wyjaśnienie |
|---|---|
| żądania | Żądania wysłane do usługi w chmurze i zarejestrowane |
| wyjątki | Nieobsługiwane wyjątki i zarejestrowane wyjątki obsługiwane |
| Liczniki wydajności | dane wydajności |
Dane w poniższych tabelach są zbierane przez niestandardowe ustawienie diagnostyczne:
| Tabela w wystąpieniu usługi Application Insights | Nazwa w ustawieniu diagnostycznym |
|---|---|
| traces | Dzienniki aplikacji |
| traces | Dzienniki ETW |
| traces | Dzienniki infrastruktury |
| ślady/zdarzenia niestandardowe | Dzienniki zdarzeń systemu Windows |
| Metryki niestandardowe | liczniki wydajności |