Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga 16.
Aby zautomatyzować ręczną analizę opisaną w tym artykule, zobacz Diagnozowanie zdarzeń kondycji grupy dostępności za pomocą narzędzia AGDiag.
Ten artykuł zawiera kroki rozwiązywania problemów, które ułatwiają ustalenie, dlaczego grupa dostępności została przełączona w tryb failover.
Wpływ problemów z kondycją zawsze włączonej lub przejścia w tryb failover
Funkcja Always On implementuje niezawodne monitorowanie kondycji za pomocą różnych mechanizmów, aby zapewnić kondycję wystąpienia programu Microsoft SQL Server, które hostuje replikę podstawową, podstawowy klaster i kondycję systemu. Obciążenie produkcyjne jest chwilowo przerywane po zidentyfikowaniu problemu z kondycją zawsze włączonego klastra systemu Windows.
Po wykryciu stanu kondycji zwykle występuje następująca sekwencja zdarzeń. W tym narzędziu do rozwiązywania problemów zdarzenia kondycji są wymienione w odniesieniu do następujących zdarzeń:
Repliki grup dostępności i bazy danych przechodzą z roli podstawowej do rozpoznawania roli.
Bazy danych grup dostępności przechodzą do trybu offline i nie są już dostępne.
Klaster systemu Windows oznacza zasób klastrowany grupy dostępności jako niepowodzenie.
Klaster systemu Windows próbuje przywrócić rolę grupy dostępności w trybie online (w oryginalnej lub automatycznej replice partnera trybu failover).
Rola grupy dostępności zostanie pomyślnie włączona w trybie online, jeśli zostanie wykryta w dobrej kondycji przez monitorowanie kondycji zawsze włączonego i klastra systemu Windows.
W przypadku powodzenia repliki grup dostępności i bazy danych przechodzą do roli podstawowej, a bazy danych grupy dostępności są dostępne w trybie online i są dostępne dla aplikacji.
Aplikacje nie mogą uzyskać dostępu do baz danych grup dostępności
Po wykryciu stanu kondycji replika grupy dostępności i bazy danych przechodzą do roli Rozpoznawanie, a bazy danych grupy dostępności są przełączane w tryb offline. Po przejściu repliki do trybu online w roli podstawowej (na oryginalnym serwerze repliki repliki lub na serwerze repliki partnera trybu failover) replika i bazy danych ponownie przechodzą do trybu online. Podczas gdy replika i bazy danych są rozpoznawane i są w trybie offline, wszystkie aplikacje, które próbują uzyskać dostęp do tych baz danych grupy dostępności, kończą się niepowodzeniem i generują komunikat "Błąd 983": Unable to access availability database.... Ten błąd jest również rejestrowany w dzienniku błędów programu Microsoft SQL Server, jeśli program SQL Server jest skonfigurowany do rejestrowania nieudanych prób logowania:
Logon Error: 983, Severity: 14, State: 1.
Logon Unable to access availability database '<databasename>' because the database replica is not in the PRIMARY or SECONDARY role. Connections to an availability database is permitted only when the database replica is in the PRIMARY or SECONDARY role. Try the operation again later.
Okres, w którym grupa dostępności znajduje się w roli Rozpoznawanie, zanim wróci do trybu online w roli głównej, zazwyczaj trwa tylko kilka sekund, a nawet mniej niż sekundę.
Identyfikowanie i diagnozowanie zdarzeń kondycji zawsze włączonej grupy dostępności lub trybu failover
1. Identyfikowanie trendów kondycji zawsze włączonych
Możesz zbadać pojedyncze zdarzenie kondycji Zawsze włączone lub może wystąpić niedawny lub ciągły trend problemów zdrowotnych, które sporadycznie przerywają produkcję. Następujące pytania mogą ułatwić zawężenie i skorelowanie ostatnich zmian w środowisku produkcyjnym, które mogą być związane z tymi problemami zdrowotnymi:
- Kiedy rozpoczął się trend Zawsze włączone lub zdarzenia kondycji klastra?
- Czy zdarzenia dotyczące kondycji występują w określonym dniu?
- Czy zdarzenia kondycji występują o określonej porze dnia?
- Czy zdarzenia dotyczące kondycji występują w określonym dniu lub tygodniu miesiąca?
Jeśli wykryjesz trend, sprawdź zaplanowaną konserwację systemu (system hosta w środowisku wirtualnym), partie ETL i inne zadania, które mogą być skorelowane z tymi zdarzeniami kondycji. Jeśli system jest maszyną wirtualną, zbadaj system hosta pod kątem zmian, które mogły zostać wprowadzone w momencie awarii.
Rozważ zajęte obciążenia produkcyjne ad hoc, które mogą być skorelowane z czasem problemów z kondycją (na przykład gdy użytkownicy po raz pierwszy logują się do systemu lub po powrocie użytkowników z lunchu).
Uwaga 16.
Jest to dobry moment, aby rozważyć plan zbierania danych wydajności przez cały tydzień i miesiąc. Aby lepiej zrozumieć, kiedy system jest najbardziej ruchliwy, można zmierzyć liczniki monitora wydajności systemu Windows, takie jak Processor Information::% Processor Time, Memory::Available MBytesi MSSQLServer:SQL Statistics::Batch Requests/sec.
2. Przejrzyj dziennik klastra
Dziennik klastra systemu Windows jest najbardziej kompleksowym dziennikiem używanym do identyfikowania rodzaju zdarzenia Zawsze włączone lub kondycji klastra, a także wykrytego stanu kondycji, który spowodował zdarzenie. Aby wygenerować i otworzyć dziennik klastra, wykonaj następujące kroki:
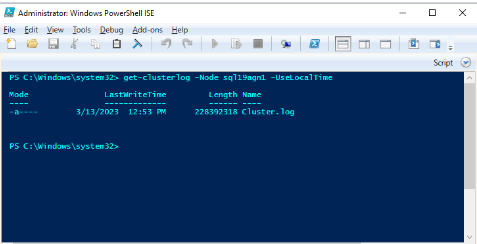
Użyj programu Windows PowerShell, aby wygenerować dziennik klastra systemu Windows w węźle klastra, który hostuje replikę podstawową w czasie zdarzenia kondycji. Na przykład uruchom następujące polecenie cmdlet w oknie programu PowerShell z podwyższonym poziomem uprawnień przy użyciu polecenia "sql19agn1" jako nazwy serwera opartego na programie SQL Server:
get-clusterlog -Node sql19agn1 -UseLocalTime
Uwaga 16.
Domyślnie plik dziennika jest tworzony w folderze %WINDIR%\cluster\reports.
3. Znajdź zdarzenie kondycji w dzienniku klastra
Funkcja Always On używa kilku mechanizmów monitorowania kondycji do monitorowania kondycji grupy dostępności. Oprócz zdarzenia kondycji klastra systemu Windows (w którym klaster systemu Windows wykrywa problem z kondycją między węzłami klastra), funkcja Always On ma cztery różne rodzaje kontroli kondycji:
- Usługa SQL Server nie jest uruchomiona
- Limit czasu dzierżawy programu SQL Server
- Limit czasu sprawdzania kondycji programu SQL Server
- Problem z kondycją wewnętrzną programu SQL Server
Możesz zlokalizować dowolne z tych zdarzeń kondycji zawsze włączone, wyszukując dziennik klastra dla ciągu . [hadrag] Resource Alive result 0 Ten ciąg jest zapisywany w dzienniku klastra po wykryciu dowolnego z tych zdarzeń. Na przykład:
00001334.00002ef4::2019/06/24-18:24:36.153 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
Możesz użyć narzędzia , aby znaleźć wszystkie zdarzenia kondycji w dzienniku klastra, aby wygenerować raport podsumowujący problemy z kondycją zawsze włączone. Może to być przydatne do identyfikowania trendów chronologicznych i określenia, czy określony stan kondycji Zawsze włączone jest cykliczny. Poniższy zrzut ekranu przedstawia sposób użycia edytora tekstów (NotePad++, w tym przypadku) w celu znalezienia wszystkich wierszy w dzienniku klastra [hadrag] Resource Alive result 0 , które zawierają ciąg:

Identyfikowanie i rozwiązywanie problemu z kondycją, który wyzwolił tryb failover
Aby zidentyfikować problemy z kondycją w dzienniku klastra repliki podstawowej, porównaj je z problemami opisanymi w poniższych sekcjach. Typowe przyczyny przejścia grupy dostępności w tryb failover obejmują:
- Zdarzenie kondycji klastra
- Usługa SQL Server nie działa (zdarzenie zawsze włączonej kondycji)
- Limit czasu dzierżawy (zdarzenie kondycji zawsze włączone)
- Limit czasu sprawdzania kondycji (zdarzenie zawsze włączonej kondycji)
- Kondycja programu SQL Server (zdarzenie zawsze włączonej kondycji)
Zdarzenia kondycji klastra
Klaster systemu Microsoft Windows monitoruje kondycję serwerów członkowskich w klastrze. Jeśli zostanie wykryty problem z kondycją, serwer członkowski klastra może zostać usunięty z klastra. Ponadto zasoby klastra (w tym rola grupy dostępności hostowana na usuniętym serwerze członkowskim klastra) zostaną przeniesione do repliki partnera trybu failover grupy dostępności, jeśli jest skonfigurowany do automatycznego trybu failover.
Symptomy
Oto przykład zdarzenia kondycji klastra w dzienniku klastra. Aby go znaleźć, możesz wyszukać Lost quorum lub Cluster service has terminated dlatego, że może być obecny podczas zmiany roli grupy dostępności lub przejścia w tryb failover.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: Lost quorum (1)
00000fe4.00001628::2022/12/15-14:26:02.654 WARN [QUORUM] Node 1: goingAway: 0, core.IsServiceShutdown: 0
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925)
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [NETFT] Cluster Service preterminate succeeded.
00000fe4.00001628::2022/12/15-14:26:02.654 WARN lost quorum (status = 5925), executing OnStop
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM]: Shutting down, so unloading the cluster database.
00000fe4.00001628::2022/12/15-14:26:02.654 INFO [DM] Shutting down, so unloading the cluster database (waitForLock: false).
000019cc.000019d0::2022/12/15-14:26:02.654 WARN [RHS] Cluster service has terminated. Cluster.Service.Running.Event got signaled.
Innym sposobem identyfikacji tego zdarzenia jest przeszukiwanie dziennika zdarzeń systemu Windows:
Critical SQL19AGN1.CSSSQL 1135 Microsoft-Windows-FailoverClusterin Node Mgr NT AUTHORITY\SYSTEM Cluster node 'SQL19AGN2' was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapters on this node. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Critical SQL19AGN1.CSSSQL 1177 Microsoft-Windows-FailoverClusterin Quorum Manager NT AUTHORITY\SYSTEM The Cluster service is shutting down because quorum was lost. This could be due to the loss of network connectivity between some or all nodes in the cluster, or a failover of the witness disk. Run the Validate a Configuration wizard to check your network configuration. If the condition persists, check for hardware or software errors related to the network adapter. Also check for failures in any other network components to which the node is connected such as hubs, switches, or bridges.
Diagnozowanie zdarzenia kondycji klastra
Błędy w dzienniku zdarzeń systemu Windows (zdarzenia 1135 i 1177) sugerują, że łączność sieciowa jest przyczyną zdarzenia. Jest to najczęstsza przyczyna wykrycia problemu z kondycją klastra. W poniższym przykładzie pokazano, że inne serwery członkowskie klastra nie mogły komunikować się z tym serwerem, który hostuje replikę podstawową grupy dostępności, i że ten problem wyzwolił usunięcie węzła klastra z klastra:
00000fe4.00001edc::2022/12/14-22:44:36.870 INFO [NODE] Node 1: New join with n3: stage: 'Attempt Initial Connection' status (10060) reason: 'Failed to connect to remote endpoint <endpoint address>'
00000fe4.00001620::2022/12/15-14:26:02.050 INFO [IM] got event: Remote endpoint <endpoint address> unreachable from <endpoint address>
00000fe4.00001620::2022/12/15-14:26:02.050 WARN [NDP] All routes for route (virtual) local <local address> to remote <remote address> are down
00000fe4.0000179c::2022/12/15-14:26:02.053 WARN [NODE] Node 1: Connection to Node 2 is broken. Reason GracefulClose(1226)' because of 'channel to remote endpoint <endpoint address> is closed'
Możesz wyszukać w dzienniku klastra dowody niepowodzenia połączenia z węzłem. Z lokalizacji w dzienniku klastra, w którym znaleziono Lost quorum, wyszukaj wstecz ciągi, takie jak Failed to connect to remote endpoint, unreachablei is broken.
Rozwiązanie
Upewnij się, że monitorowanie kondycji klastra jest odpowiednie dla środowiska hosta. Aby uzyskać więcej informacji na temat zawsze włączonych grup dostępności programu SQL Server hostowanych na platformie Microsoft Azure, zobacz Omówienie klastra trybu failover systemu Windows Server — SQL Server na maszynach wirtualnych platformy Azure.
Jeśli jest to konieczne, rozważ skontaktowanie się z pomocą techniczną dotyczącą wysokiej dostępności systemu Microsoft Windows, aby otworzyć zdarzenie pomocy technicznej.
Usługa SQL Server nie działa: zdarzenie zawsze włączonej kondycji
Zawsze włączone monitorowanie kondycji może wykryć, czy usługa PROGRAMU SQL Server, która hostuje replikę podstawową grupy dostępności, nie jest już uruchomiona.
Symptomy
Oto przykład raportu dziennika klastra dla roli grupy dostępności "ag", który wskazuje błąd, ponieważ QueryServiceStatusEx zwrócił identyfikator 0procesu:
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] QueryServiceStatusEx returned a process id 0
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] SQL server service is not alive
00001898.0000185c::2023/02/27-13:27:41.121 ERR [RES] SQL Server Availability Group <ag>: [hadrag] Resource Alive result 0.
00001898.0000185c::2023/02/27-13:27:41.121 WARN [RHS] Resource ag IsAlive has indicated failure.
Diagnozowanie zdarzeń zamykania usługi SQL
Sprawdź dziennik zdarzeń systemu Windows i dziennik błędów programu SQL Server pod kątem nieoczekiwanego zamknięcia programu SQL Server.
Jeśli program SQL Server został zamknięty przez zamknięcie systemu lub zamknięcie administracyjne, w dzienniku błędów programu SQL Server zostanie wyświetlony następujący wpis:
2023-03-10 09:38:46.73 spid9s SQL Server is terminating in response to a 'stop' request from Service Control Manager. This is an informational message only. No user action is required.
Dziennik zdarzeń systemu Windows zawiera następujący wpis błędu:
Information 3/10/2023 9:41:06 AM Service Control Manager 7036 None The SQL Server (MSSQLSERVER) service entered the stopped state.
Dziennik zdarzeń systemu Windows pokazuje następujący wpis błędu, jeśli program SQL Server zostanie nieoczekiwanie zamknięty:
Error 3/10/2023 8:37:46 AM Service Control Manager 7034 None The SQL Server (MSSQLSERVER) service terminated unexpectedly. It has done this 1 time(s).
Sprawdź koniec dziennika błędów programu SQL Server, aby uzyskać wskazówki. Jeśli dziennik błędów nagle zakończy się, oznacza to, że został zamknięty przez siłę. Jeśli na przykład program SQL Server został zakończony przy użyciu Menedżera zadań, raport o błędach programu SQL Server nie ujawni żadnych informacji o problemach wewnętrznych, które mogły spowodować zamknięcie procesu.
Rozwiązanie
Upewnij się, że autoryzowani administratorzy bazy danych i systemu mają dostęp do systemu, aby zminimalizować nieoczekiwane kończenie działania usługi PROGRAMU SQL Server. Po zbadaniu dzienników zdarzeń sprawdź, dlaczego usługa musiała zostać nieoczekiwanie zakończona.
Jeśli wewnętrzny problem z kondycją programu SQL Server spowodował nieoczekiwane zakończenie działania programu SQL Server, mogą wystąpić wskazówki dotyczące możliwego wyjątku krytycznego (w tym wygenerowanego pliku diagnostycznego zrzutu pamięci) na końcu dziennika błędów SQL. Przejrzyj wskazówki i podejmij niezbędne działania. Jeśli znajdziesz plik zrzutu, rozważ skontaktowanie się z pomocą techniczną programu Microsoft SQL Server i podaj dziennik błędów programu SQL Server i zawartość pliku zrzutu w celu dalszego zbadania.
Limit czasu dzierżawy: zdarzenie zawsze włączonej kondycji
Zawsze włączone używa mechanizmu "dzierżawy" do monitorowania kondycji komputera, na którym jest zainstalowany program SQL Server. Domyślny limit czasu dzierżawy wynosi 20 sekund.
Symptomy
Oto przykładowe dane wyjściowe zawsze włączonego limitu czasu dzierżawy z dziennika klastra. Możesz wyszukać te ciągi, aby zlokalizować limit czasu dzierżawy w dzienniku klastra.
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Availability Group lease is no longer valid
00001a0c.00001c5c::2023/01/04-15:36:54.762 ERR [RES] SQL Server Availability Group : [hadrag] Resource Alive result 0.
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:35:57.0, 98.068572, 509227008.000000, 0.000395, 0.000350 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:7.0, 12.314941, 451817472.000000, 0.000278, 0.000266 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:17.0, 17.270742, 416096256.000000, 0.000376, 0.000292 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:27.0, 38.399895, 416301056.000000, 0.000446, 0.000304 00001a0c.00001c5c::2023/01/04-15:36:54.762 WARN [RES] SQL Server Availability Group: [hadrag] 1/4/2023 15:36:37.0, 100.000000, 417517568.000000, 0.001292, 0.000666
Aby uzyskać więcej informacji na temat limitu czasu dzierżawy, zobacz sekcję Mechanizm dzierżawy w sekcji Mechanika i wskazówki dotyczące limitów czasu dzierżawy, klastra i kontroli kondycji dla zawsze włączonych grup dostępności.
Diagnozowanie i rozwiązywanie problemów z zawsze włączonymi zdarzeniami przekroczenia limitu czasu dzierżawy
Istnieją dwa główne problemy, które mogą wyzwalać limit czasu dzierżawy:
Zrzut pamięci programu SQL Server: gdy program SQL Server wykryje pewne zdarzenia dotyczące kondycji wewnętrznej, takie jak naruszenie dostępu, aseracja lub zakleszczenie harmonogramu, generuje plik zrzutu diagnostycznego (mdmp) w folderze \LOG programu SQL Server. Proces generowania zrzutu pamięci zawiesza wykonywanie programu SQL Server przez krótki okres. W tym okresie mechanizm dzierżawy może wykryć brak odpowiedzi na usługę i akcję wyzwalacza. Aby uzyskać więcej informacji, zobacz Wpływ generowania zrzutu.
Problem z wydajnością całego systemu: limit czasu dzierżawy nie musi wskazywać na problem z kondycją programu SQL Server. Zamiast tego może to wskazywać na problem z kondycją całego systemu, który również wpływa na kondycję serwera opartego na programie SQL Server.
- Wysokie użycie procesora CPU w systemie (blisko 100%).
- Warunki braku pamięci — mała ilość pamięci wirtualnej i/lub jeden z procesów jest odsyłany.
- WSFC przechodzi w tryb offline z powodu utraty kworum
- Ograniczanie przepustowości maszyny wirtualnej wpływa na wydajność i powoduje wygaśnięcie dzierżawy.
Rozwiązanie
Aby uzyskać szczegółowe instrukcje rozwiązywania problemów, zobacz MSSQLSERVER_19407. Poniżej przedstawiono dwa najczęstsze problemy:
Diagnostyka pliku zrzutu serwera 1. SQL
Program SQL Server może wykryć wewnętrzny problem z kondycją, taki jak naruszenie dostępu, potwierdzenie lub zakleszczenia harmonogramów. W takiej sytuacji program generuje plik mini zrzutu (mdmp) w folderze \LOG programu SQL Server na potrzeby diagnostyki. Proces programu SQL Server jest zamrożony przez kilka sekund, podczas gdy plik mini zrzutu jest zapisywany na dysku. W tym czasie wszystkie wątki w procesie programu SQL Server są w stanie zamrożonym, który obejmuje wątek dzierżawy monitorowany przez monitorowanie kondycji Zawsze włączone. W związku z tym funkcja Always On może wykryć przekroczenie limitu czasu dzierżawy.
**Dump thread - spid = 0, EC = 0x0000000000000000
***Stack Dump being sent to C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\LOG\SQLDump0001.txt
* *******************************************************************************
*
* BEGIN STACK DUMP:
* 11/02/14 21:21:10 spid 1920
*
* Deadlocked Schedulers
*
* *******************************************************************************
* -------------------------------------------------------------------------------
* Short Stack Dump
Stack Signature for the dump is 0x00000000000002BA
Error: 19407, Severity: 16, State: 1.
The lease between availability group 'ag' and the Windows Server Failover Cluster has expired. A connectivity issue occurred between the instance of SQL Server and the Windows Server Failover Cluster. To determine whether the availability group is failing over correctly, check the corresponding availability group resource in the Windows Server Failover Cluster.
Aby rozwiązać ten problem, należy zbadać diagnostykę pliku zrzutu pamięci dla głównej przyczyny. Rozważ skontaktowanie się z pomocą techniczną programu Microsoft SQL Server, aby zapewnić dziennik błędów programu SQL Server i zawartość pliku zrzutu w celu dalszego zbadania.
2. Wysokie użycie procesora CPU lub inny problem z wydajnością systemu
Limit czasu dzierżawy wskazuje na problem z wydajnością, który ma wpływ na cały system, w tym program SQL Server. Aby zdiagnozować problem z systemem, funkcja Zawsze włączonej diagnostyki kondycji raportuje dane monitora wydajności w dzienniku klastra i zawiera zdarzenie limitu czasu dzierżawy. Dane wydajności obejmują około 50 sekund poprzedzających zdarzenie przekroczenia limitu czasu dzierżawy, raportowanie wykorzystania procesora CPU, wolnej pamięci i opóźnienia dysku.
Oto przykład zgłoszonych danych wydajności, które pokazują limit czasu dzierżawy w dzienniku klastra. W tych przykładowych danych wyjściowych wysokie ogólne wykorzystanie procesora CPU, które może być związane z limitem czasu dzierżawy.
00000f90.000015c0::2020/08/07-14:16:41.378 WARN [RES] SQL Server Availability Group: [hadrag] Lease timeout detected, logging perf counter data collected so far
00000f90.000015c0::2020/08/07-14:16:41.382 WARN [RES] SQL Server Availability Group: [hadrag] Date/Time, Processor time(%), Available memory(bytes), Avg disk read(secs), Avg disk write(secs)
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:20.0, 83.266073, 31700828160.000000, 0.018094, 0.015752
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:30.0, 93.653224, 31697063936.000000, 0.038590, 0.026897
00000f90.000015c0::2020/08/07-14:16:41.431 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:40.0, 94.270691, 31696265216.000000, 0.166000, 0.038962
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:15:50.0, 90.272016, 31695409152.000000, 0.215141, 0.106084
00000f90.000015c0::2020/08/07-14:16:41.434 WARN [RES] SQL Server Availability Group: [hadrag] 8/7/2020 14:16:1.0, 99.991336, 31695892480.000000, 0.046983, 0.035440
Jeśli dane dotyczące wydajności pokazują wysokie wykorzystanie procesora CPU, niski stan pamięci lub duże opóźnienie dysku w momencie przekroczenia limitu czasu dzierżawy, rozpocznij zbieranie danych monitor wydajności przez cały dzień w repliki podstawowej w celu zbadania tych objawów. Przechwytując dane monitora wydajności w dłuższym okresie, można lepiej zidentyfikować wartości punktu odniesienia i wartości szczytowe dla tych zasobów oraz monitorować zmiany w tych zasobach po przekroczeniu limitu czasu dzierżawy. Podczas zbierania tych danych należy wziąć pod uwagę, czy w programie SQL Server istnieją pewne obciążenia zaplanowane lub ad hoc, które są skorelowane z czasem tych problemów z zasobami i zdarzeniami kondycji.
Należy również przechwytywać liczniki, które zgłaszają to samo użycie zasobów systemowych, w tym następujące:
Processor Information::% Processor TimeMemory::Available MBytesLogical Disk::Avg. Disk sec/ReadLogical Disk::Avg. Disk sec/WriteLogical Disk::Avg. Disk Read Queue LengthLogical Disk::Avg. Disk Write Queue LengthMSSQLServer:SQL Statistics::Batch Requests/sec
Limit czasu sprawdzania kondycji: zdarzenie zawsze włączonej kondycji
Funkcja Always On używa mechanizmu sprawdzania kondycji do monitorowania kondycji programu SQL Server i możliwości nawiązywania połączeń przez aplikacje klienckie.
Symptomy
Gdy replika grupy dostępności przechodzi do roli podstawowej, monitorowanie kondycji Always On ustanawia lokalne połączenie ODBC z wystąpieniem programu SQL Server. Gdy funkcja Always On jest połączona i monitoruje, jeśli program SQL Server nie reaguje na połączenie ODBC w okresie ustawionym dla limitu czasu sprawdzania kondycji grupy dostępności (wartość domyślna to 30 sekund), zostanie wyzwolone zdarzenie przekroczenia limitu czasu sprawdzania kondycji. W takiej sytuacji grupa dostępności przechodzi z roli podstawowej do roli Rozpoznawanie i inicjuje tryb failover, jeśli została skonfigurowana do tego celu.
Aby uzyskać więcej informacji na temat limitów czasu sprawdzania kondycji, zobacz sekcję "Operacja limitu czasu sprawdzania kondycji" w sekcji Mechanika i wskazówki dotyczące limitów czasu dzierżawy, klastra i sprawdzania kondycji dla zawsze włączonych grup dostępności.
Oto limit czasu zawsze włączonej kontroli kondycji zgodnie z raportem w dzienniku klastra:
0000211c.00002d70::2021/02/24-02:50:01.890 WARN [RES] SQL Server Availability Group: [hadrag] Failed to retrieve data column. Return code -1
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <AG>: [hadrag] Resource Alive result 0.
0000211c.00002594::2021/02/24-02:50:02.453 WARN [RHS] Resource AG IsAlive has indicated failure.
00001278.00002ed8::2021/02/24-02:50:02.453 INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'AG', gen(0) result 1/0.
Diagnozowanie i rozwiązywanie problemów z zdarzeniem przekroczenia limitu czasu sprawdzania kondycji zawsze włączone
Poniższa sekcja ułatwia przejrzenie dzienników programu SQL Server pod kątem zdarzeń "okruchu chleba", które można znaleźć i które są skorelowane z limitami czasu sprawdzania kondycji zawsze włączone, które są wykrywane i zgłaszane. Dzienniki, które są przeglądane w tym miejscu, obejmują dziennik klastra (gdzie jest potwierdzany limit czasu sprawdzania kondycji), system_health rozszerzone dzienniki zdarzeń i dzienniki błędów programu SQL Server (zarówno znalezione w folderze \LOG programu SQL Server), jak i dziennik zdarzeń systemu Windows. Użyj tych i innych dzienników, aby wyszukać korelujące zdarzenia, które mogą pomóc w zakresie przyczyny przekroczenia limitu czasu sprawdzania kondycji.
1. Sprawdź, czy nie są zwracane zdarzenia harmonogramu
Limit czasu sprawdzania kondycji Always On jest często spowodowany przez zdarzenia "nieodpowidające" w programie SQL Server. Gdy program SQL Server wykryje, że wątek nie został zwrócony zgodnie z harmonogramem, zgłosi, że wystąpiło zdarzenie harmonogramu, które nie daje. Jeśli widzisz inne zadania w tym samym harmonogramie, który nie otrzymuje czasu procesora CPU, jest to podstawowy znak harmonogramu nieodpowiadającego. To zachowanie może spowodować opóźnione wykonywanie tych zadań i "głodne" obciążenia przypisane do określonego harmonogramu czasu procesora CPU.
Aby sprawdzić, czy nie są zwracane zdarzenia harmonogramu, wykonaj następujące kroki:
Sprawdź rozszerzone dzienniki zdarzeń programu SQL Server
system_health, aby ustalić, czy zdarzenie harmonogramu nieodpowidające zostało zgłoszone w czasie zdarzenia zawsze włączonego sprawdzania kondycji. Zdarzenia, które mogą nie zwracać, obejmują następujące elementy:scheduler_monitor_non_yielding_ring_buffer_recordedscheduler_monitor_non_yielding_iocp_ring_buffer_recordedscheduler_monitor_stalled_dispatcher_ring_buffer_recordedscheduler_monitor_non_yielding_rm_ring_buffer_recorded
Otwórz dzienniki zdarzeń rozszerzonej kondycji systemu programu SQL Server w repliki podstawowej do czasu przekroczenia limitu czasu podejrzanego sprawdzania kondycji.
W programie SQL Server Management Studio (SSMS) przejdź do pozycji Plik > otwórz i wybierz pozycję Scal pliki zdarzeń rozszerzonych.
Kliknij przycisk Dodaj.
W oknie dialogowym Otwieranie pliku przejdź do plików w katalogu \LOG programu SQL Server.
Naciśnij i przytrzymaj kontrolkę, a następnie wybierz pliki, których nazwy zaczynają się od
system_health_xxx.xel.Wybierz pozycję Otwórz>ok.
Przefiltruj wyniki. Kliknij prawym przyciskiem myszy zdarzenie w kolumnie name i wybierz pozycję Filtruj według tej wartości.
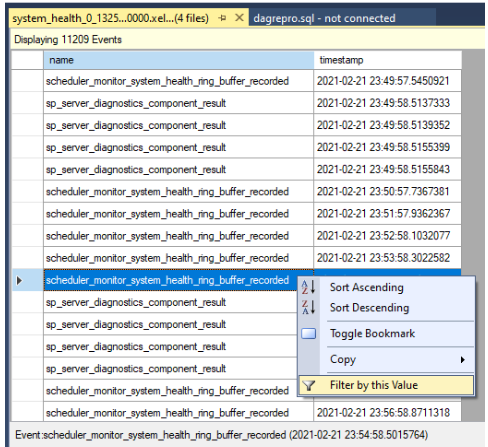
Zdefiniuj filtr do sortowania wierszy, w których wartości w kolumnie name zawierają
yieldwartość , jak pokazano na poniższym zrzucie ekranu. Spowoduje to zwrócenie wszystkich rodzajów zdarzeń, które mogły zostać zarejestrowane w dziennikachsystem_health.
Porównaj znaczniki czasu, aby sprawdzić, czy w momencie przekroczenia limitu czasu sprawdzania kondycji wystąpiły zdarzenia inne niż wydajność. Oto limit czasu sprawdzania kondycji zgłoszony w dzienniku klastra:
0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel 0000211c.00002594::2021/02/24-21:50:02.452 ERR [RES] SQL Server Availability Group < SQL19AGN1: [hadrag] Resource Alive result 0.Widać, że w momencie przekroczenia limitu czasu sprawdzania kondycji wystąpiły zdarzenia, które nie przyniosły żadnych zysków.
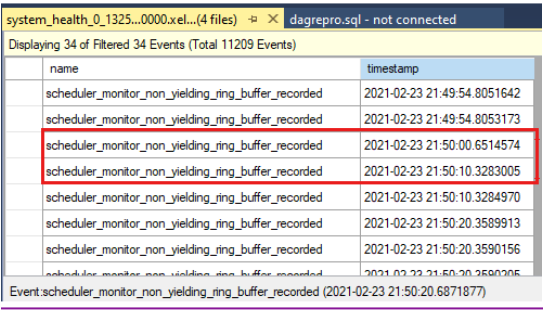
Jeśli nie zwracane są zdarzenia, sprawdź przyczynę zdarzenia nieodpowiedniającego. Rozważ skontaktowanie się z zespołem pomocy technicznej programu SQL Server w celu zbadania zdarzeń, które nie dają.
2. Sprawdź dziennik błędów programu SQL Server
Sprawdź dziennik błędów programu SQL Server pod kątem korelowania zdarzeń w momencie przekroczenia limitu czasu sprawdzania kondycji. Te zdarzenia mogą zawierać "okruchy stron nadrzędnych", które sugerują dalsze kroki w celu określenia zakresu głównej przyczyny przekroczenia limitu czasu sprawdzania kondycji.
Na przykład następujący wpis dziennika pokazuje, że w dzienniku klastra wystąpił limit czasu sprawdzania kondycji:
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, diagnostics heartbeat is lost
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
0000211c.00002594::2021/02/24-02:50:02.452 ERR [RES] SQL Server Availability Group <SQL19AGN1>: [hadrag] Resource Alive result 0.
W dzienniku błędów programu SQL Server w ciągu kilku sekund od przekroczenia limitu czasu sprawdzania kondycji program SQL Server zgłasza, że wykrył poważne opóźnienie we/wy:
2021-02-23 20:49:54.64 spid12s SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [C:\Program Files\Microsoft SQL Server\MSSQL15.MSSQLSERVER\MSSQL\DATA\agdb_log.ldf] in database id 12. The OS file handle is 0x0000000000001594. The offset of the latest long I/O is: 0x000030435b0000. The duration of the long I/O is: 26728 ms.
Przejrzyj dziennik zdarzeń systemu pod kątem możliwych wskazówek systemowych, które mogą być związane ze zdarzeniem przekroczenia limitu czasu sprawdzania kondycji. Podczas przeglądania dziennika zdarzeń systemu Windows może wystąpić problem z we/wy zgłoszony w tym samym czasie dla tego samego limitu czasu sprawdzania kondycji:
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"Reset to device, \Device\<device ID>, was issued."
02/23/2021,08:50:16 PM,Warning,SQL19AGN1.CSSSQL.local.local,<...>,"The IO operation at logical block address <block address> for Disk 6 (PDO name: \Device\<device ID>) was retried."
Kondycja programu SQL Server: zdarzenie zawsze włączonej kondycji
Zawsze włączone monitoruje różne rodzaje zdarzeń kondycji programu SQL Server. Chociaż hostuje replikę podstawową grupy dostępności, program SQL Server stale działa sp_server_diagnostics , które zgłaszają kondycję programu SQL Server przy użyciu różnych składników. Po wykryciu sp_server_diagnostics problemów z kondycją zgłasza błąd dla tego konkretnego składnika, a następnie wysyła wyniki z powrotem do procesu wykrywania kondycji Zawsze włączone. Po zgłoszeniu błędu rola grupy dostępności pokazuje stan niepowodzenia i możliwe przejście w tryb failover, jeśli grupa dostępności jest skonfigurowana do tego celu.
Symptomy
Oto przykład problemu z kondycją programu SQL Server zgłoszonego w sp_server_diagnostics dzienniku klastra. Program SQL Server zgłasza stan "błąd" w składniku systemu do monitorowania kondycji Zawsze włączone, a grupa dostępności "contoso-ag" jest przeniesiona do stanu niepowodzenia.
Uwaga 16.
Problem z kondycją programu SQL Server generuje podobny raport do limitu czasu sprawdzania kondycji. Oba zdarzenia kondycji raportu Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel. Rozróżnienie dla zdarzenia kondycji programu SQL Server polega na tym, że zgłasza, że składnik programu SQL Server zmienił się z "ostrzeżenie" na "błąd".
INFO [RES] SQL Server Availability Group: [hadrag] SQL Server component 'system' health state has been changed from 'warning' to 'error' at 2019-06-20 15:05:52.330
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Availability Group is not healthy with given HealthCheckTimeout and FailureConditionLevel
ERR [RES] SQL Server Availability Group <contoso-ag>: [hadrag] Resource Alive result 0.
ERR [RES] SQL Server Availability Group: [hadrag] Failure detected, the state of system component is error
WARN [RHS] Resource contoso-ag IsAlive has indicated failure.
INFO [RCM] HandleMonitorReply: FAILURENOTIFICATION for 'contoso-ag', gen(0) result 1/0.
Diagnozowanie zdarzeń kondycji programu SQL Server
Rodzaj problemu z kondycją zgłaszaną przez kondycję programu SQL Server powinna określać kierunek analizy głównej przyczyny.
Domyślnie podczas wdrażania grupy FAILURE_CONDITION_LEVEL dostępności parametr jest ustawiany jako trzy. Spowoduje to aktywowanie monitorowania niektórych, ale nie wszystkich profilów kondycji programu SQL Server. Na poziomie domyślnym funkcja Always On wyzwala zdarzenie kondycji, gdy program SQL Server generuje zbyt wiele plików zrzutu, naruszenie dostępu do zapisu lub oddzielony spinlock. Ustawienie grupy dostępności do poziomu czterech lub pięciu spowoduje rozszerzenie typów monitorowanych problemów z kondycją programu SQL Server. Aby uzyskać więcej informacji na temat monitorów zawsze włączonej kondycji programu SQL Server, zobacz Konfigurowanie elastycznych zasad automatycznego trybu failover dla grupy dostępności — zawsze włączone programu SQL Server.
Aby zidentyfikować problem z kondycją zawsze włączone, wykonaj następujące kroki:
Otwórz dzienniki zdarzeń rozszerzonych diagnostyki klastra programu SQL Server w repliki podstawowej do czasu wystąpienia podejrzanego zdarzenia kondycji programu SQL Server.
W programie SSMS przejdź do pozycji Plik>otwórz, a następnie wybierz pozycję Scal pliki rozszerzonych zdarzeń.
Wybierz Dodaj.
W oknie dialogowym Otwieranie pliku przejdź do plików w katalogu \LOG programu SQL Server.
Naciśnij Control, wybierz pliki, których nazwy pasują do
<servername>_<instance>_SQLDIAG_xxx.xel, a następnie wybierz pozycję Otwórz>OK.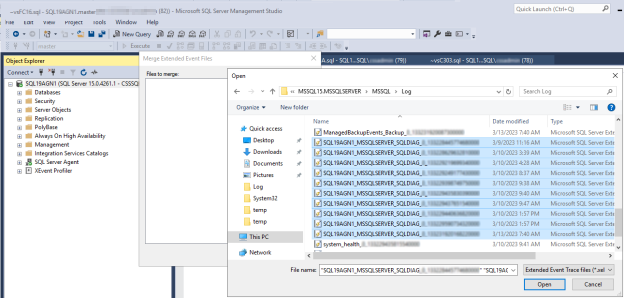
W programie SSMS zostanie wyświetlone nowe okno z kartami, które zawiera zdarzenia rozszerzone, jak pokazano na poniższym zrzucie ekranu.
Aby zbadać problem z kondycją programu SQL Server, znajdź
component_health_resultwartość , którejstate_descwartość toerror. Oto przykład zdarzenia składnika systemu, które zgłosiło błąd z powrotem do monitorowania kondycji Always On: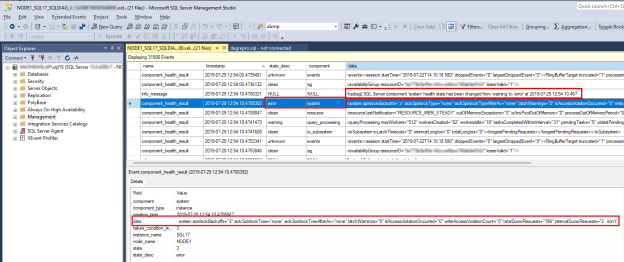
Kliknij dwukrotnie kolumnę danych w dolnym okienku. Spowoduje to otwarcie szczegółowych danych składników w nowym okienku okna programu SSMS w celu przejrzenia. Oto jak wyglądają dane składników systemu:

Zwróć uwagę, że dane "totalDumprequests=186" wskazują, że w tym programie SQL Server wygenerowano zbyt wiele zdarzeń diagnostycznych pliku zrzutu. Jest to powód, dla którego składnik systemowy zgłosił stan błędu. Gdy monitorowanie kondycji Zawsze włączone odbiera ten stan błędu, wyzwala zdarzenie kondycji grupy dostępności. Możesz również sprawdzić, czy nie wykryto żadnych naruszeń dostępu do zapisu ani oddzielonych spinlocks z danych podanych w danych składnika systemu.



Rozwiązanie
W zależności od typu wykrytego problemu należy odpowiednio rozwiązać ten problem. W artykule Konfigurowanie elastycznego automatycznego trybu failover dla grupy dostępności — zawsze włączone programu SQL Server omówiono różne problemy, które prowadzą do tego problemu. Przykłady:
- Usługa SQL Server nie działa.
- Limit czasu dzierżawy.
- Replika dostępności jest w stanie niepowodzenia.
- Zrzuty pamięci generowane przez oddzielone spinlocks, naruszenia dostępu lub zbyt wiele zrzutów pamięci generowanych w krótkim czasie.
- Trwały stan braku pamięci w wewnętrznej puli zasobów programu SQL Server.
- Wykrywanie zakleszczenia harmonogramu.
- Wykrywanie nierozwiązanego zakleszczenia.
Jeśli jest to konieczne, skontaktuj się z pomocą techniczną programu SQL Server, aby otworzyć zdarzenie pomocy technicznej, aby uzyskać dalszą pomoc w znalezieniu głównej przyczyny tych wewnętrznych problemów z kondycją programu SQL Server