Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy: SQL Server
Ten artykuł zawiera procedury diagnozowania i rozwiązywania problemów spowodowanych wysokim użyciem procesora na komputerze z programem Microsoft SQL Server. Chociaż istnieje wiele możliwych przyczyn wysokiego użycia procesora CPU występujących w programie SQL Server, najczęstsze przyczyny są następujące:
- Wysokie odczyty logiczne spowodowane skanowaniem tabeli lub indeksu z powodu następujących warunków:
- nieaktualne statystyki,
- brakujące indeksy,
- Problemy z planem wrażliwym na parametry (PSP)
- źle zaprojektowane zapytania,
- Wzrost obciążenia
Poniższe kroki umożliwiają rozwiązywanie problemów z wysokim użyciem procesora w programie SQL Server.
Krok 1. Sprawdź, czy program SQL Server powoduje wysokie użycie procesora CPU
Użyj jednego z następujących narzędzi, aby sprawdzić, czy proces programu SQL Server faktycznie przyczynia się do wysokiego użycia procesora CPU:
Menedżer zadań: na karcie Proces sprawdź, czy wartość kolumny procesora CPU dla programu SQL Server Windows NT-64 Bit jest bliska 100 procent.
Monitor wydajności i zasobów (perfmon)
- Licznik:
Process/%User Time,% Privileged Time - Wystąpienie: sqlservr
- Licznik:
Aby zebrać dane licznika w ciągu 60 sekund, można użyć następującego skryptu programu PowerShell:
$serverName = $env:COMPUTERNAME $Counters = @( ("\\$serverName" + "\Process(sqlservr*)\% User Time"), ("\\$serverName" + "\Process(sqlservr*)\% Privileged Time") ) Get-Counter -Counter $Counters -MaxSamples 30 | ForEach { $_.CounterSamples | ForEach { [pscustomobject]@{ TimeStamp = $_.TimeStamp Path = $_.Path Value = ([Math]::Round($_.CookedValue, 3)) } Start-Sleep -s 2 } }Jeśli
% User Timewartość jest stale większa niż 90 procent (% czasu użytkownika jest sumą czasu procesora na każdym procesorze, jego maksymalna wartość wynosi 100% * (bez procesorów), proces programu SQL Server powoduje wysokie użycie procesora CPU. Jednak jeśli wartość% Privileged timestale przekracza 90 procent, oprogramowanie antywirusowe, inne sterowniki lub inny składnik systemu operacyjnego na komputerze przyczynia się do wysokiego użycia procesora CPU. Podejmij działania z administratorem systemu w celu przeanalizowania głównej przyczyny tego zachowania.Pulpit nawigacyjny wydajności: w programie SQL Server Management Studio kliknij prawym przyciskiem myszy pozycję< SQLServerInstance> i wybierz pozycję > wydajności.
Na pulpicie nawigacyjnym przedstawiono wykres zatytułowany Wykorzystanie procesora CPU systemu z wykresem słupkowym. Ciemniejszy kolor wskazuje wykorzystanie procesora PROCESORA aparatu programu SQL Server, natomiast jaśniejszy kolor reprezentuje ogólne wykorzystanie procesora CPU systemu operacyjnego (zobacz legendę na grafie, aby uzyskać odwołanie). Wybierz przycisk odświeżania cyklicznego lub F5 , aby wyświetlić zaktualizowane wykorzystanie.
Krok 2. Identyfikowanie zapytań przyczyniających się do użycia procesora CPU
Sqlservr.exe Jeśli proces powoduje wysokie użycie procesora, zdecydowanie najczęstszą przyczyną jest zapytanie programu SQL Server, które wykonuje skanowanie tabeli lub indeksu, a następnie operacje sortowania, funkcje skrótu i pętle (operator zagnieżdżonej pętli lub WHILE (T-SQL)). Aby dowiedzieć się, ile procesora CPU aktualnie używają zapytania (biorąc pod uwagę ogólną wydajność procesora), uruchom następującą instrukcję:
DECLARE @init_sum_cpu_time int,
@utilizedCpuCount int
--get CPU count used by SQL Server
SELECT @utilizedCpuCount = COUNT( * )
FROM sys.dm_os_schedulers
WHERE status = 'VISIBLE ONLINE'
--calculate the CPU usage by queries OVER a 5 sec interval
SELECT @init_sum_cpu_time = SUM(cpu_time) FROM sys.dm_exec_requests
WAITFOR DELAY '00:00:05'
SELECT CONVERT(DECIMAL(5,2), ((SUM(cpu_time) - @init_sum_cpu_time) / (@utilizedCpuCount * 5000.00)) * 100) AS [CPU from Queries as Percent of Total CPU Capacity]
FROM sys.dm_exec_requests
Aby zidentyfikować zapytania, które są obecnie odpowiedzialne za działanie wysokiego użycia procesora CPU, uruchom następującą instrukcję:
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Jeśli zapytania nie napędzają procesora CPU w tej chwili, możesz uruchomić następującą instrukcję, aby wyszukać historyczne zapytania związane z procesorem CPU:
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Krok 3. Aktualizowanie statystyk
Po zidentyfikowaniu zapytań o najwyższym zużyciu procesora CPU zaktualizuj statystyki tabel używanych przez te zapytania. Za pomocą systemowej procedury składowanej sp_updatestats można zaktualizować statystyki wszystkich tabel zdefiniowanych przez użytkownika i tabel wewnętrznych w bieżącej bazie danych. Na przykład:
exec sp_updatestats
Uwaga 16.
Systemowa procedura składowana sp_updatestats uruchamia UPDATE STATISTICS względem wszystkich tabel zdefiniowanych przez użytkownika i wewnętrznych w bieżącej bazie danych. W przypadku regularnej konserwacji upewnij się, że regularne planowanie konserwacji powoduje aktualizowanie statystyk. Rozwiązania takie jak Adaptive Index Defrag umożliwiają automatyczne zarządzanie defragmentacją indeksu i aktualizacjami statystyk dla co najmniej jednej bazy danych. Ta procedura automatycznie wybiera, czy należy ponownie skompilować lub zreorganizować indeks zgodnie z jego poziomem fragmentacji, między innymi parametrami oraz czy zaktualizować statystyki z progiem liniowym.
Aby uzyskać więcej informacji o sp_updatestats, zobacz sp_updatestats.
Jeśli program SQL Server nadal używa nadmiernej pojemności procesora CPU, przejdź do następnego kroku.
Krok 4. Dodawanie brakujących indeksów
Brak indeksów może prowadzić do wolniejszego uruchamiania zapytań i wysokiego użycia procesora CPU. Można zidentyfikować brakujące indeksy i utworzyć je, aby zwiększyć ten wpływ na wydajność.
Uruchom następujące zapytanie, aby zidentyfikować zapytania, które powodują wysokie użycie procesora CPU i zawierają co najmniej jeden brakujący indeks w planie zapytania:
-- Captures the Total CPU time spent by a query along with the query plan and total executions SELECT qs_cpu.total_worker_time / 1000 AS total_cpu_time_ms, q.[text], p.query_plan, qs_cpu.execution_count, q.dbid, q.objectid, q.encrypted AS text_encrypted FROM (SELECT TOP 500 qs.plan_handle, qs.total_worker_time, qs.execution_count FROM sys.dm_exec_query_stats qs ORDER BY qs.total_worker_time DESC) AS qs_cpu CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q CROSS APPLY sys.dm_exec_query_plan(plan_handle) p WHERE p.query_plan.exist('declare namespace qplan = "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; //qplan:MissingIndexes')=1Przejrzyj plany wykonywania zidentyfikowanych zapytań i dostosuj zapytanie, wprowadzając wymagane zmiany. Poniższy zrzut ekranu przedstawia przykład, w którym program SQL Server będzie wskazywać brakujący indeks zapytania. Kliknij prawym przyciskiem myszy część Brak indeksu planu zapytania, a następnie wybierz pozycję Brakujące szczegóły indeksu, aby utworzyć indeks w innym oknie w programie SQL Server Management Studio.
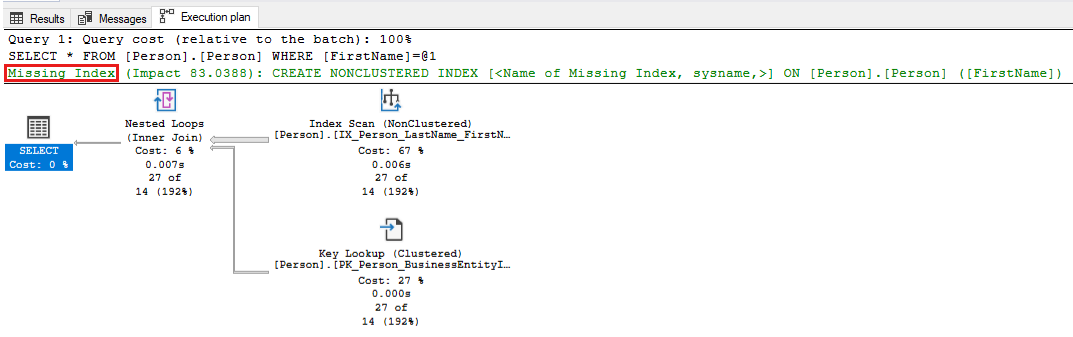
Użyj następującego zapytania, aby sprawdzić brakujące indeksy i zastosować wszystkie zalecane indeksy, które mają wartości miary wysokiej poprawy. Zacznij od 5 lub 10 pierwszych zaleceń z danych wyjściowych, które mają najwyższą wartość improvement_measure. Indeksy te mają najbardziej znaczący pozytywny wpływ na wydajność. Zdecyduj, czy chcesz zastosować te indeksy i upewnij się, że dla aplikacji wykonywane są testy wydajnościowe. Następnie kontynuuj stosowanie zaleceń dotyczących braku indeksu do momentu osiągnięcia żądanych wyników wydajności aplikacji. Aby uzyskać więcej informacji na ten temat, zobacz Dostrajanie indeksów nieklastrowanych z brakującymi sugestiami indeksu.
SELECT CONVERT(VARCHAR(30), GETDATE(), 126) AS runtime, mig.index_group_handle, mid.index_handle, CONVERT(DECIMAL(28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) AS improvement_measure, 'CREATE INDEX missing_index_' + CONVERT(VARCHAR, mig.index_group_handle) + '_' + CONVERT(VARCHAR, mid.index_handle) + ' ON ' + mid.statement + ' (' + ISNULL(mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement, migs.*, mid.database_id, mid.[object_id] FROM sys.dm_db_missing_index_groups mig INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle WHERE CONVERT (DECIMAL (28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) > 10 ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC

Krok 5. Badanie i rozwiązywanie problemów z wrażliwymi parametrami
Możesz użyć polecenia DBCC FREEPROCCACHE, aby zwolnić pamięć podręczną planu i sprawdzić, czy rozwiązuje to problem z wysokim użyciem procesora CPU. Jeśli problem zostanie rozwiązany, oznacza to, że wystąpił problem wrażliwy na parametry (PSP, znany również jako „problem z wykrywaniem parametrów”).
Uwaga 16.
Użycie DBCC FREEPROCCACHE bez parametrów powoduje usunięcie wszystkich skompilowanych planów z pamięci podręcznej planu. Spowoduje to ponowne skompilowanie nowych wykonań zapytań, co doprowadzi do jednorazowo dłuższego czasu trwania każdego nowego zapytania. Najlepszym rozwiązaniem jest użycie DBCC FREEPROCCACHE ( plan_handle | sql_handle ) do określenia, które zapytanie może być przyczyną problemu, a następnie rozwiązanie tego pojedynczego zapytania lub zapytań.
Aby rozwiązać problemy z parametrami, użyj następujących metod. Każda metoda ma skojarzone kompromisy i wady.
Użyj wskazówki dotyczącej zapytania RECOMPILE . Możesz dodać wskazówkę dotyczącą zapytania
RECOMPILEdo co najmniej jednego zapytania o wysokim wykorzystaniu procesora CPU, które zostały zidentyfikowane w kroku 2. Ta wskazówka pomaga zrównoważyć niewielki wzrost użycia procesora CPU kompilacji z bardziej optymalną wydajnością dla każdego wykonywania zapytania. Aby uzyskać więcej informacji, zobacz Parametry i ponowne użycie planu wykonywania, informacje o poufności parametrów i wskazówki dotyczące zapytania RECOMPILE.Oto przykład zastosowania tej wskazówki do zapytania.
SELECT * FROM Person.Person WHERE LastName = 'Wood' OPTION (RECOMPILE)Użyj wskazówek zapytania OPTIMIZE FOR, aby zastąpić rzeczywistą wartość parametru bardziej typową wartością parametru, która obejmuje większość wartości w danych. Ta opcja wymaga pełnego zrozumienia optymalnych wartości parametrów i skojarzonych cech planu. Oto przykład użycia tej wskazówki w zapytaniu.
DECLARE @LastName Name = 'Frintu' SELECT FirstName, LastName FROM Person.Person WHERE LastName = @LastName OPTION (OPTIMIZE FOR (@LastName = 'Wood'))Użyj wskazówek zapytania OPTIMIZE FOR UNKNOWN, aby zastąpić rzeczywistą wartość parametru średnią wektora gęstości. Można to również zrobić, przechwytując przychodzące wartości parametrów w zmiennych lokalnych, a następnie używając zmiennych lokalnych w predykatach, zamiast używać samych parametrów. W przypadku tej poprawki do zapewnienia akceptowalnej wydajności może być wystarczająca średnia gęstość.
Użyj wskazówki zapytania DISABLE_PARAMETER_SNIFFING, aby całkowicie wyłączyć wykrywanie parametrów. Oto przykład użycia go w zapytaniu:
SELECT * FROM Person.Address WHERE City = 'SEATTLE' AND PostalCode = 98104 OPTION (USE HINT ('DISABLE_PARAMETER_SNIFFING'))Użyj wskazówki zapytania KEEPFIXED PLAN, aby zapobiec ponownej kompilacji w pamięci podręcznej. W tym obejściu założono, że „wystarczająco dobrym” wspólnym planem jest ten, który znajduje się już w pamięci podręcznej. Możesz również wyłączyć automatyczne aktualizacje statystyk, aby zmniejszyć prawdopodobieństwo wykluczenia dobrego planu i skompilowania nowego złego planu.
Użyj polecenia DBCC FREEPROCCACHE jako rozwiązania tymczasowego, dopóki kod aplikacji nie zostanie naprawiony. Możesz użyć polecenia
DBCC FREEPROCCACHE (plan_handle), aby usunąć tylko plan, który powoduje problem. Aby na przykład znaleźć plany zapytań odwołujące się do tabeliPerson.Personw rozwiązaniu AdventureWorks, możesz użyć tego zapytania do znalezienia dojścia zapytania. Następnie można zwolnić określony plan zapytania z pamięci podręcznej przy użyciu elementuDBCC FREEPROCCACHE (plan_handle)utworzonego w drugiej kolumnie wyników zapytania.SELECT text, 'DBCC FREEPROCCACHE (0x' + CONVERT(VARCHAR (512), plan_handle, 2) + ')' AS dbcc_freeproc_command FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY sys.dm_exec_sql_text(plan_handle) WHERE text LIKE '%person.person%'
Krok 6. Badanie i rozwiązywanie problemów z parametrem SARGability
Predykat w zapytaniu jest uważany jako warunek SARGable (Search ARGument ABLE), gdy aparat systemu SQL Server może użyć wyszukiwania indeksu w celu przyspieszenia wykonania zapytania. Wiele projektów zapytań zapobiega warunkowi SARGability i prowadzi do skanowania tabel lub indeksów oraz wysokiego użycia procesora. Rozważ następujące zapytanie względem bazy danych AdventureWorks, w której należy pobrać wszystkie elementy ProductNumber i zastosować do nich funkcję SUBSTRING(), zanim zostanie porównana z wartością literału ciągu. Jak widać, musisz najpierw pobrać wszystkie wiersze tabeli, a następnie zastosować funkcję przed dokonaniem porównania. Pobranie wszystkich wierszy z tabeli oznacza skanowanie tabeli lub indeksu, co prowadzi do wyższego użycia procesora.
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE SUBSTRING(ProductNumber, 0, 4) = 'HN-'
Zastosowanie dowolnej funkcji lub obliczeń w kolumnach w predykacie wyszukiwania zwykle sprawia, że zapytanie nie ma warunku SARGable i prowadzi do wyższego zużycia procesora. Rozwiązania zwykle obejmują ponowne zapisywanie zapytań w kreatywny sposób, aby spełnić warunek SARGable. Możliwym rozwiązaniem tego przykładu jest ponowne zapisywanie, w którym funkcja jest usuwana z predykatu zapytania, przeszukiwana jest inna kolumna i osiągane są te same wyniki:
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE Name LIKE 'Hex%'
Oto kolejny przykład, w którym kierownik sprzedaży może chcieć przekazać 10% prowizji od sprzedaży w przypadku dużych zamówień i chce sprawdzić, które zamówienia będą miały prowizję większą niż 300 USD. Oto logiczny, inny niż „sargable” sposób, aby to zrobić.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice * 0.10 > 300
Oto możliwe, mniej intuicyjne, ale z możliwością ponownego zapisania zapytania, w którym obliczenia są przenoszone na drugą stronę predykatu.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice > 300/0.10
SARGability ma zastosowanie nie tylko do klauzul WHERE, ale także do klauzul JOINs, HAVING, GROUP BY i ORDER BY. Częste wystąpienia zapobiegania SARGability w zapytaniach obejmują funkcje CONVERT(), CAST(), ISNULL(), COALESCE() używane w klauzulach WHERE lub JOIN, które prowadzą do skanowania kolumn. W przypadkach konwersji typu danych (CONVERT lub CAST), rozwiązaniem może być upewnienie się, że porównuje się te same typy danych. Oto przykład, w którym kolumna T1.ProdID jest jawnie konwertowana na typ danych INT w pliku JOIN. Konwersja pokonuje użycie indeksu w kolumnie sprzężenia. Ten sam problem występuje w przypadku niejawnej konwersji, w której typy danych są różne, a program SQL Server konwertuje jeden z nich w celu wykonania sprzężenia.
SELECT T1.ProdID, T1.ProdDesc
FROM T1 JOIN T2
ON CONVERT(int, T1.ProdID) = T2.ProductID
WHERE t2.ProductID BETWEEN 200 AND 300
Aby uniknąć skanowania tabeli T1, można zmienić podstawowy typ danych kolumny ProdID po odpowiednim planowaniu i projektowaniu, a następnie połączyć dwie kolumny bez użycia funkcji konwertuj ON T1.ProdID = T2.ProductID.
Innym rozwiązaniem jest utworzenie obliczonej kolumny w T1, która korzysta z tej samej funkcji CONVERT(), a następnie utworzenie na niej indeksu. Dzięki temu optymalizator zapytań będzie używać tego indeksu bez konieczności zmiany zapytania.
ALTER TABLE dbo.T1 ADD IntProdID AS CONVERT (INT, ProdID);
CREATE INDEX IndProdID_int ON dbo.T1 (IntProdID);
W niektórych przypadkach nie można łatwo przepisać zapytań, aby umożliwić SARGability. W takich przypadkach należy sprawdzić, czy kolumna obliczeniowa z indeksem może pomóc lub też zachować zapytanie w dotychczasowej postaci ze świadomością, że może to prowadzić do scenariuszy z wyższym wykorzystaniem procesora CPU.
Krok 7. Wyłączanie intensywnego śledzenia
Sprawdź, czy śledzenie SQL lub śledzenia XEvent, które ma wpływ na wydajność programu SQL Server i powoduje wysokie użycie procesora CPU. Na przykład użycie następujących zdarzeń może spowodować wysokie użycie procesora CPU w przypadku śledzenia dużej aktywności programu SQL Server:
- Zdarzenia XML planu zapytań (
query_plan_profile,query_post_compilation_showplan,query_post_execution_plan_profile,query_post_execution_showplan,query_pre_execution_showplan) - Zdarzenia na poziomie instrukcji (
sql_statement_completed,sql_statement_starting,sp_statement_starting,sp_statement_completed) - Zdarzenia logowania i wylogowywania (
login,process_login_finish,login_event,logout) - Zdarzenia blokady (
lock_acquired,lock_cancel,lock_released) - Zdarzenia oczekiwania (
wait_info,wait_info_external) - Inspekcja zdarzeń SQL (w zależności od inspekcji grupy i aktywności programu SQL Server w tej grupie)
Uruchom następujące zapytania, aby zidentyfikować aktywne śledzenie XEvent lub Server:
PRINT '--Profiler trace summary--'
SELECT traceid, property, CONVERT(VARCHAR(1024), value) AS value FROM::fn_trace_getinfo(
default)
GO
PRINT '--Trace event details--'
SELECT trace_id,
status,
CASE WHEN row_number = 1 THEN path ELSE NULL end AS path,
CASE WHEN row_number = 1 THEN max_size ELSE NULL end AS max_size,
CASE WHEN row_number = 1 THEN start_time ELSE NULL end AS start_time,
CASE WHEN row_number = 1 THEN stop_time ELSE NULL end AS stop_time,
max_files,
is_rowset,
is_rollover,
is_shutdown,
is_default,
buffer_count,
buffer_size,
last_event_time,
event_count,
trace_event_id,
trace_event_name,
trace_column_id,
trace_column_name,
expensive_event
FROM
(SELECT t.id AS trace_id,
row_number() over(PARTITION BY t.id order by te.trace_event_id, tc.trace_column_id) AS row_number,
t.status,
t.path,
t.max_size,
t.start_time,
t.stop_time,
t.max_files,
t.is_rowset,
t.is_rollover,
t.is_shutdown,
t.is_default,
t.buffer_count,
t.buffer_size,
t.last_event_time,
t.event_count,
te.trace_event_id,
te.name AS trace_event_name,
tc.trace_column_id,
tc.name AS trace_column_name,
CASE WHEN te.trace_event_id in (23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180) THEN CAST(1 as bit) ELSE CAST(0 AS BIT) END AS expensive_event FROM sys.traces t CROSS APPLY::fn_trace_geteventinfo(t.id) AS e JOIN sys.trace_events te ON te.trace_event_id = e.eventid JOIN sys.trace_columns tc ON e.columnid = trace_column_id) AS x
GO
PRINT '--XEvent Session Details--'
SELECT sess.NAME 'session_name', event_name, xe_event_name, trace_event_id,
CASE WHEN xemap.trace_event_id IN(23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180)
THEN Cast(1 AS BIT)
ELSE Cast(0 AS BIT)
END AS expensive_event
FROM sys.dm_xe_sessions sess
JOIN sys.dm_xe_session_events evt
ON sess.address = evt.event_session_address
INNER JOIN sys.trace_xe_event_map xemap
ON evt.event_name = xemap.xe_event_name
GO
Krok 8. Naprawienie wysokiego użycia procesora CPU spowodowane rywalizacją spinlock
Aby rozwiązać typowe wysokie użycie procesora CPU spowodowane rywalizacją spinlock, zobacz poniższe sekcje.
rywalizacja SOS_CACHESTORE spinlock
Jeśli wystąpienie programu SQL Server napotyka dużą SOS_CACHESTORE rywalizację o spinlock lub zauważasz, że plany zapytań są często usuwane w nieplanowanych obciążeniach zapytań, zobacz następujący artykuł i włącz flagę T174 śledzenia przy użyciu DBCC TRACEON (174, -1) polecenia :
Jeśli warunek wysokiego użycia procesora CPU zostanie rozwiązany przy użyciu polecenia T174, włącz go jako parametr uruchamiania przy użyciu menedżera konfiguracji programu SQL Server.
Losowe wysokie użycie procesora CPU z powodu rywalizacji o SOS_BLOCKALLOCPARTIALLIST spinlock na maszynach z dużą ilością pamięci
Jeśli wystąpienie programu SQL Server doświadcza losowego wysokiego użycia procesora CPU z powodu SOS_BLOCKALLOCPARTIALLIST rywalizacji spinlock, zalecamy zastosowanie aktualizacji zbiorczej Update 21 dla programu SQL Server 2019. Aby uzyskać więcej informacji na temat rozwiązywania problemu, zobacz informacje o błędach 2410400 i DBCC DROPCLEANBUFFERS , które zapewniają tymczasowe środki zaradcze.
Wysokie użycie procesora CPU ze względu na rywalizację spinlock na XVB_list na maszynach wysokiej klasy
Jeśli wystąpienie programu SQL Server ma duży scenariusz procesora CPU spowodowany rywalizacją spinlock na XVB_LIST spinlock na maszynach o wysokiej konfiguracji (systemy wysokiej klasy z dużą liczbą procesorów nowej generacji (PROCESORy)), włącz flagę śledzenia TF8102 wraz z TF8101.
Uwaga 16.
Wysokie użycie procesora CPU może wynikać z rywalizacji spinlock na wielu innych typach spinlock. Aby uzyskać więcej informacji na temat spinlocks, zobacz Diagnozowanie i rozwiązywanie rywalizacji spinlock w programie SQL Server.
Krok 9. Sprawdzanie ustawień planu zasilania na poziomie systemu operacyjnego
Obciążenia programu SQL Server mogą mieć obniżoną wydajność i powodować wysokie użycie procesora CPU w systemie, gdy system Windows jest skonfigurowany przy użyciu domyślnego planu zasilania z równoważeniem obciążenia. Ustawienie Zrównoważonego planu zasilania może obniżyć szybkość zegara procesora CPU, aby zaoszczędzić energię. Na przykład procesor o częstotliwości 3,00 GHz może zmniejszać częstotliwość do 1,2 GHz. W związku z tym obciążenia, które zwykle zużywają około 30% CPU, mogą osiągnąć 100% obciążenie ze względu na zmniejszoną szybkość zegara. Aby zachować spójną i optymalną wydajność obciążeń programu SQL Server intensywnie korzystających z obliczeń, zalecamy skonfigurowanie systemu pod kątem korzystania z planu zasilania o wysokiej wydajności . To ustawienie zapewnia, że procesor działa z pełną nominalną prędkością, co pomaga uniknąć problemów z wydajnością. Aby uzyskać więcej informacji, zobacz Niska wydajność w systemie Windows Server podczas korzystania z planu zrównoważonej zasilania.
Krok 10. Konfigurowanie maszyny wirtualnej
Jeśli używasz maszyny wirtualnej, upewnij się, że procesory CPU nie są nadmiernie aprowizowane i że są one prawidłowo skonfigurowane. Aby uzyskać więcej informacji, zobacz Rozwiązywanie problemów z wydajnością maszyn wirtualnych ESX/ESXi (2001003).
Krok 11: Skalowanie systemu na większą skalę w celu użycia większej liczby procesorów
Jeśli pojedyncze wystąpienia zapytań używają niewielkiej pojemności procesora CPU, ale ogólne obciążenie wszystkich zapytań powoduje wysokie użycie procesora CPU, rozważ skalowanie w górę komputera przez dodanie większej liczby procesorów CPU. Użyj następującego zapytania, aby znaleźć liczbę zapytań, które przekroczyły określony próg średniego i maksymalnego użycia procesora CPU na wykonanie i zostały uruchomione wiele razy w systemie (upewnij się, że zostały zmodyfikowane wartości dwóch zmiennych w celu dopasowania ich do środowiska):
-- Shows queries where Max and average CPU time exceeds 200 ms and executed more than 1000 times
DECLARE @cputime_threshold_microsec INT = 200*1000
DECLARE @execution_count INT = 1000
SELECT qs.total_worker_time/1000 total_cpu_time_ms,
qs.max_worker_time/1000 max_cpu_time_ms,
(qs.total_worker_time/1000)/execution_count average_cpu_time_ms,
qs.execution_count,
q.[text]
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
WHERE (qs.total_worker_time/execution_count > @cputime_threshold_microsec
OR qs.max_worker_time > @cputime_threshold_microsec )
AND execution_count > @execution_count
ORDER BY qs.total_worker_time DESC
Zobacz też
- Wysokie przydziały procesora CPU lub pamięci mogą wystąpić w przypadku zapytań korzystających z zoptymalizowanej pętli zagnieżdżonej lub sortowania wsadowego
- Zalecane aktualizacje i opcje konfiguracji dla programu SQL Server z obciążeniami o wysokiej wydajności
- Zalecane aktualizacje i opcje konfiguracji dla programu SQL Server 2017 i 2016 z obciążeniami o wysokiej wydajności