Rozwiązywanie problemów z wydajnością AKTUALIZACJI z wąskimi i szerokimi planami w SQL Server
Dotyczy: SQL Server
W niektórych przypadkach instrukcja UPDATE może być szybsza, a w innych wolniejsza. Istnieje wiele czynników, które mogą prowadzić do takiej wariancji, w tym liczba zaktualizowanych wierszy i użycie zasobów w systemie (blokowanie, procesor CPU, pamięć lub we/wy). W tym artykule opisano jedną konkretną przyczynę wariancji: wybór planu zapytania dokonanego przez SQL Server.
Co to są wąskie i szerokie plany?
Podczas wykonywania UPDATE instrukcji względem kolumny indeksu klastrowanego SQL Server aktualizuje nie tylko sam indeks klastrowany, ale także wszystkie indeksy nieklasterowane, ponieważ indeksy nieklasterowane zawierają klucz indeksu klastra.
SQL Server ma dwie opcje wykonania aktualizacji:
Wąski plan: wykonaj aktualizację indeksu nieklasterowanego wraz z aktualizacją klucza indeksu klastrowanego. To proste podejście jest łatwe do zrozumienia; zaktualizuj indeks klastrowany, a następnie zaktualizuj jednocześnie wszystkie indeksy nieklasterowane. SQL Server zaktualizuje jeden wiersz i przejdzie do następnego do momentu ukończenia wszystkich. Takie podejście jest nazywane wąską aktualizacją planu lub aktualizacją Per-Row. Jednak ta operacja jest stosunkowo kosztowna, ponieważ kolejność nieklasterowanych danych indeksu, które zostaną zaktualizowane, może nie być w kolejności danych indeksu klastrowanego. Jeśli w aktualizację bierze udział wiele stron indeksu, gdy dane znajdują się na dysku, może wystąpić duża liczba losowych żądań we/wy.
Szeroki plan: aby zoptymalizować wydajność i zmniejszyć liczbę losowych operacji we/wy, SQL Server może wybrać szeroki plan. Nie powoduje aktualizacji indeksów nieklasterowanych wraz z aktualizacją indeksu klastrowanego razem. Zamiast tego najpierw sortuje wszystkie nieklasterowane dane indeksu w pamięci, a następnie aktualizuje wszystkie indeksy w tej kolejności. Takie podejście jest nazywane szerokim planem (nazywanym również aktualizacją Per-Index).
Oto zrzut ekranu przedstawiający wąskie i szerokie plany:

Kiedy SQL Server wybrać szeroki plan?
Aby SQL Server wybrać szeroki plan, muszą zostać spełnione dwa kryteria:
- Liczba wierszy, których dotyczy problem, jest większa niż 250.
- Rozmiar poziomu liści indeksów nieklasterowanych (liczba stron indeksu * 8 KB) wynosi co najmniej 1/1000 maksymalnego ustawienia pamięci serwera.
Jak działają wąskie i szerokie plany?
Aby zrozumieć, jak działają wąskie i szerokie plany, wykonaj następujące kroki w następującym środowisku:
- SQL Server 2019 CU11
- Maksymalna ilość pamięci serwera = 1500 MB
Uruchom następujący skrypt, aby utworzyć tabelę
mytable1zawierającą odpowiednio 41 501 wierszy, jeden indeks klastrowany w kolumniec1i pięć indeksów nieklasterowanych w pozostałych kolumnach.CREATE TABLE mytable1(c1 INT,c2 CHAR(30),c3 CHAR(20),c4 CHAR(30),c5 CHAR(30)) GO WITH cte AS ( SELECT ROW_NUMBER() OVER(ORDER BY c1.object_id) id FROM sys.columns CROSS JOIN sys.columns c1 ) INSERT mytable1 SELECT TOP 41000 id,REPLICATE('a',30),REPLICATE('a',20),REPLICATE('a',30),REPLICATE('a',30) FROM cte GO INSERT mytable1 SELECT TOP 250 50000,c2,c3,c4,c5 FROM mytable1 GO INSERT mytable1 SELECT TOP 251 50001,c2,c3,c4,c5 FROM mytable1 GO CREATE CLUSTERED INDEX ic1 ON mytable1(c1) CREATE INDEX ic2 ON mytable1(c2) CREATE INDEX ic3 ON mytable1(c3) CREATE INDEX ic4 ON mytable1(c4) CREATE INDEX ic5 ON mytable1(c5)Uruchom następujące trzy instrukcje języka T-SQL
UPDATEi porównaj plany zapytań:UPDATE mytable1 SET c1=c1 WHERE c1=1 OPTION(RECOMPILE)— jeden wiersz jest aktualizowanyUPDATE mytable1 SET c1=c1 WHERE c1=50000 OPTION(RECOMPILE)— Zaktualizowano 250 wierszy.UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE)— Zaktualizowano 251 wierszy.
Sprawdź wyniki na podstawie pierwszego kryterium (próg liczby wierszy, których dotyczy problem, wynosi 250).
Na poniższym zrzucie ekranu przedstawiono wyniki na podstawie pierwszego kryterium:

Zgodnie z oczekiwaniami optymalizator zapytań wybiera wąski plan dla pierwszych dwóch zapytań, ponieważ liczba wierszy, których dotyczy problem, jest mniejsza niż 250. Dla trzeciego zapytania jest używany szeroki plan, ponieważ liczba wierszy, których dotyczy problem, wynosi 251, czyli więcej niż 250.
Sprawdź wyniki na podstawie drugiego kryterium (pamięć rozmiaru indeksu liścia wynosi co najmniej 1/1000 maksymalnego ustawienia pamięci serwera).
Na poniższym zrzucie ekranu przedstawiono wyniki na podstawie drugiego kryterium:

Dla trzeciego
UPDATEzapytania wybrano szeroki plan. Ale indeksic3(w kolumniec3) nie jest widoczny w planie. Problem występuje, ponieważ drugie kryterium nie jest spełnione — rozmiar indeksu stron liścia w porównaniu z ustawieniem maksymalnej pamięci serwera.Typ danych kolumny , i to
char(30), podczas gdy typ danych kolumnyc3tochar(20).c4c4c2Rozmiar każdego wiersza indeksuic3jest mniejszy niż w przypadku innych, więc liczba stron liści jest mniejsza niż w innych.Za pomocą funkcji zarządzania dynamicznego (DMF)
sys.dm_db_database_page_allocationsmożna obliczyć liczbę stron dla każdego indeksu. W przypadku indeksówic2,ic4iic5, każdy indeks ma 214 stron, a 209 z nich to strony liści (wyniki mogą się nieznacznie różnić). Pamięć używana przez strony liści wynosi 209 x 8 = 1672 KB. W związku z tym współczynnik wynosi 1672/(1500 x 1024) = 0,00108854101, który jest większy niż 1/1000. Jednak jedynaic3strona ma 161 stron; 159 z nich to strony liści. Współczynnik wynosi 159 x 8/(1500 x 1024) = 0,000828125, czyli mniej niż 1/1000 (0,001).Jeśli wstawisz więcej wierszy lub zmniejszysz maksymalną ilość pamięci serwera , aby spełnić kryterium, plan ulegnie zmianie. Aby rozmiar na poziomie liści indeksu był większy niż 1/1000, możesz nieco obniżyć maksymalne ustawienie pamięci serwera do 1200, uruchamiając następujące polecenia:
sp_configure 'show advanced options', 1; GO RECONFIGURE; GO sp_configure 'max server memory', 1200; GO RECONFIGURE GO UPDATE mytable1 SET c1=c1 WHERE c1=50001 OPTION(RECOMPILE) --251 rows are updated.W tym przypadku 159 x 8/(1200 x 1024) = 0,00103515625 > 1/1000. Po tej zmianie element zostanie
ic3wyświetlony w planie.Aby uzyskać więcej informacji na temat
show advanced optionsprogramu , zobacz Korzystanie z języka Transact-SQL.Poniższy zrzut ekranu pokazuje, że szeroki plan używa wszystkich indeksów po osiągnięciu progu pamięci:




Czy szeroki plan jest szybszy niż wąski plan?
Odpowiedź jest taka, że zależy to od tego, czy dane i strony indeksu są buforowane w puli buforów, czy nie.
Dane są buforowane w puli buforów
Jeśli dane znajdują się już w puli buforów, zapytanie z szerokim planem nie musi zapewniać dodatkowych korzyści wydajności w porównaniu z wąskimi planami, ponieważ szeroki plan ma na celu zwiększenie wydajności operacji we/wy (odczyty fizyczne, a nie odczyty logiczne).
Aby sprawdzić, czy szeroki plan jest szybszy niż wąski plan, gdy dane znajdują się w puli buforów, wykonaj następujące kroki w następującym środowisku:
SQL Server 2019 CU11
Maksymalna ilość pamięci serwera: 30 000 MB
Rozmiar danych wynosi 64 MB, a rozmiar indeksu wynosi około 127 MB.
Pliki bazy danych znajdują się na dwóch różnych dyskach fizycznych:
- I:\sql19\dbWideplan.mdf
- H:\sql19\dbWideplan.ldf
Utwórz inną tabelę ,
mytable2uruchamiając następujące polecenia:CREATE TABLE mytable2(C1 INT,C2 INT,C3 INT,C4 INT,C5 INT) GO CREATE CLUSTERED INDEX IC1 ON mytable2(C1) CREATE INDEX IC2 ON mytable2(C2) CREATE INDEX IC3 ON mytable2(C3) CREATE INDEX IC4 ON mytable2(C4) CREATE INDEX IC5 ON mytable2(C5) GO DECLARE @N INT=1 WHILE @N<1000000 BEGIN DECLARE @N1 INT=RAND()*4500 DECLARE @N2 INT=RAND()*100000 DECLARE @N3 INT=RAND()*100000 DECLARE @N4 INT=RAND()*100000 DECLARE @N5 INT=RAND()*100000 INSERT mytable2 VALUES(@N1,@N2,@N3,@N4,@N5) SET @N+=1 END GO UPDATE STATISTICS mytable2 WITH FULLSCANWykonaj następujące dwa zapytania, aby porównać plany zapytań:
update mytable2 set c1=c1 where c2<260 option(querytraceon 8790) --trace flag 8790 will force Wide plan update mytable2 set c1=c1 where c2<260 option(querytraceon 2338) --trace flag 2338 will force Narrow planAby uzyskać więcej informacji, zobacz flaga śledzenia 8790 i flaga śledzenia 2338.
Zapytanie z szerokim planem trwa 0,136 sekundy, a zapytanie z planem wąskim zajmuje tylko 0,112 sekundy. Dwa czasy trwania są bardzo bliskie, a aktualizacja Per-Index (szeroki plan) jest mniej korzystna, ponieważ dane znajdują się już w buforze przed wykonaniem
UPDATEinstrukcji.Poniższy zrzut ekranu przedstawia szerokie i wąskie plany, gdy dane są buforowane w puli buforów:


Dane nie są buforowane w puli buforów
Aby sprawdzić, czy szeroki plan jest szybszy niż wąski plan, gdy dane nie znajdują się w puli buforów, uruchom następujące zapytania:
Uwaga
Podczas testowania upewnij się, że twoje jest jedynym obciążeniem w SQL Server, a dyski są przeznaczone do SQL Server.
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 seconds
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 8790) --force Wide plan
CHECKPOINT
GO
DBCC DROPCLEANBUFFERS
GO
WAITFOR DELAY '00:00:02' --wait for 1~2 SECONDS
UPDATE mytable2 SET c1=c1 WHERE c2 < 260 OPTION (QUERYTRACEON 2338) --force Narrow plan
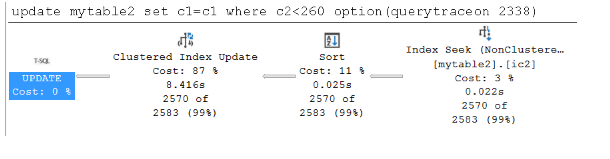
Zapytanie z szerokim planem trwa 3,554 sekundy, a zapytanie z wąskim planem trwa 6,701 sekundy. Tym razem zapytanie o szeroki plan jest uruchamiane szybciej.
Poniższy zrzut ekranu przedstawia szeroki plan, gdy dane nie są buforowane w puli buforów:

Poniższy zrzut ekranu przedstawia wąski plan, gdy dane nie są buforowane w puli buforów:
Czy zapytanie o szerokim planie jest zawsze szybsze niż wąski plan zapytań, gdy dane nie są w buforze?
Odpowiedź brzmi "nie zawsze". Aby sprawdzić, czy zapytanie szerokiego planu jest zawsze szybsze niż wąski plan zapytania, gdy dane nie są w buforze, wykonaj następujące kroki:
Utwórz inną tabelę ,
mytable2uruchamiając następujące polecenia:SELECT c1,c1 AS c2,c1 AS C3,c1 AS c4,c1 AS C5 INTO mytable3 FROM mytable2 GO CREATE CLUSTERED INDEX IC1 ON mytable3(C1) CREATE INDEX IC2 ON mytable3(C2) CREATE INDEX IC3 ON mytable3(C3) CREATE INDEX IC4 ON mytable3(C4) CREATE INDEX IC5 ON mytable3(C5) GOWartość
mytable3jest taka sama jakmytable2, z wyjątkiem danych.mytable3Ma wszystkie pięć kolumn o tej samej wartości, co sprawia, że kolejność indeksów nieklasterowanych jest zgodna z kolejnością indeksu klastrowanego. To sortowanie danych zminimalizuje zalety szerokiego planu.Wykonaj następujące polecenia, aby porównać plany zapytań:
CHECKPOINT GO DBCC DROPCLEANBUFFERS go UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 8790) --tf 8790 will force Wide plan CHECKPOINT GO DBCC DROPCLEANBUFFERS GO UPDATE mytable3 SET c1=c1 WHERE c2<12 OPTION(QUERYTRACEON 2338) --tf 2338 will force Narrow planCzas trwania obu zapytań jest znacznie krótszy. Szeroki plan trwa 0,304 sekundy, co jest nieco wolniejsze niż tym razem wąski plan.
Poniższy zrzut ekranu przedstawia porównanie wydajności, gdy są używane szerokie i wąskie:


Scenariusze, w których są stosowane szerokie plany
Poniżej przedstawiono inne scenariusze, w których stosowane są również szerokie plany:
Kolumna indeksu klastrowanego ma unikatowy lub podstawowy klucz, a wiele wierszy jest aktualizowanych
Oto przykład odtworzenia scenariusza:
CREATE TABLE mytable4(c1 INT primary key,c2 INT,c3 INT,c4 INT)
GO
CREATE INDEX ic2 ON mytable4(c2)
CREATE INDEX ic3 ON mytable4(c3)
CREATE INDEX ic4 ON mytable4(c4)
GO
INSERT mytable4 VALUES(0,0,0,0)
INSERT mytable4 VALUES(1,1,1,1)
Poniższy zrzut ekranu pokazuje, że szeroki plan jest używany, gdy indeks klastra ma unikatowy klucz:

Aby uzyskać więcej informacji, zapoznaj się z tematem Utrzymywanie unikatowych indeksów.
Kolumna indeksu klastra jest określona w schemacie partycji
Oto przykład odtworzenia scenariusza:
CREATE TABLE mytable5(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS1')
DROP PARTITION SCHEME PS1
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF1')
DROP PARTITION FUNCTION PF1
GO
CREATE PARTITION FUNCTION PF1(INT) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS1 AS
PARTITION PF1 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable5(c1) ON PS1(c1)
CREATE INDEX c2 ON mytable5(c2)
CREATE INDEX c3 ON mytable5(c3)
CREATE INDEX c4 ON mytable5(c4)
GO
UPDATE mytable5 SET c1=c1 WHERE c1=1
Poniższy zrzut ekranu pokazuje, że szeroki plan jest używany, gdy w schemacie partycji znajduje się kolumna klastrowana:

Kolumna indeksu klastrowanego nie jest częścią schematu partycji, a kolumna schematu partycji jest aktualizowana
Oto przykład odtworzenia scenariusza:
CREATE TABLE mytable6(c1 INT,c2 INT,c3 INT,c4 INT)
GO
IF EXISTS (SELECT * FROM sys.partition_schemes WHERE name='PS2')
DROP PARTITION SCHEME PS2
GO
IF EXISTS (SELECT * FROM sys.partition_functions WHERE name='PF2')
DROP PARTITION FUNCTION PF2
GO
CREATE PARTITION FUNCTION PF2(int) AS
RANGE right FOR VALUES
(2000)
GO
CREATE PARTITION SCHEME PS2 AS
PARTITION PF2 all TO
([PRIMARY])
GO
CREATE CLUSTERED INDEX c1 ON mytable6(c1) ON PS2(c2) --on c2 column
CREATE INDEX c3 ON mytable6(c3)
CREATE INDEX c4 ON mytable6(c4)
Poniższy zrzut ekranu pokazuje, że szeroki plan jest używany podczas aktualizacji kolumny schematu partycji:

Wniosku
SQL Server wybiera szeroką aktualizację planu, gdy w tym samym czasie zostaną spełnione następujące kryteria:
- Liczba wierszy, których dotyczy problem, jest większa niż 250.
- Pamięć indeksu liścia wynosi co najmniej 1/1000 maksymalnego ustawienia pamięci serwera.
Szerokie plany zwiększają wydajność kosztem zużywania dodatkowej pamięci.
Jeśli oczekiwany plan zapytania nie jest używany, może to być spowodowane nieaktualną statystyką (nie raportowaniem prawidłowego rozmiaru danych), ustawieniem maksymalnej ilości pamięci serwera lub innymi niepowiązanymi problemami, takimi jak plany wrażliwe na parametry.
Czas trwania instrukcji korzystających
UPDATEz szerokiego planu zależy od kilku czynników, a w niektórych przypadkach może to potrwać dłużej niż wąskie plany.Flaga śledzenia 8790 wymusi szeroki plan; flaga śledzenia 2338 wymusi wąski plan.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla