Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym samouczku nauczysz się utrwalać dane w aplikacji kontenera. Po uruchomieniu lub zaktualizowaniu programu dane są nadal dostępne. Istnieją dwa główne typy woluminów używanych do utrwalania danych. Ten samouczek skupia się na woluminach nazwanych .
Dowiesz się również o montowaniach powiązanych, które kontrolują dokładny punkt montowania na hoście. Możesz użyć punktów montowania, aby utrwalać dane, ale mogą one również dodawać więcej danych do kontenerów. Podczas pracy nad aplikacją możesz użyć instalacji powiązanej, aby zainstalować kod źródłowy w kontenerze, aby umożliwić mu wyświetlanie zmian kodu, reagowanie i wyświetlanie zmian od razu.
W tym samouczku przedstawiono również warstwy obrazów, buforowanie warstw i kompilacje wieloetapowe.
Z tego samouczka dowiesz się, jak wykonywać następujące działania:
- Zrozumienie danych w różnych kontenerach.
- Przechowywanie danych przy użyciu nazwanych woluminów.
- Użyj punktów montowania.
- Wyświetl warstwę obrazu.
- Zależności pamięci podręcznej.
- Zrozum kompilacje wieloetapowe.
Warunki wstępne
W tym samouczku kontynuowano poprzedni samouczek: Tworzenie i udostępnianie aplikacji kontenera w programie Visual Studio Code. Zacznij od tego, który zawiera wymagania wstępne.
Zrozumienie danych w różnych kontenerach
W tej sekcji uruchomisz dwa kontenery i utworzysz plik w każdym z nich. Pliki utworzone w jednym kontenerze nie są dostępne w innym.
Uruchom kontener
ubuntuprzy użyciu następującego polecenia:docker run -d ubuntu bash -c "shuf -i 1-10000 -n 1 -o /data.txt && tail -f /dev/null"To polecenie uruchamia wywołanie dwóch poleceń przy użyciu
&&. Pierwsza część wybiera pojedynczą losową liczbę i zapisuje ją do/data.txt. Drugie polecenie obserwuje plik, aby zachować działanie kontenera.W programie VS Code w Eksploratorze kontenerów kliknij prawym przyciskiem myszy kontener ubuntu i wybierz pozycję Dołącz powłokę.
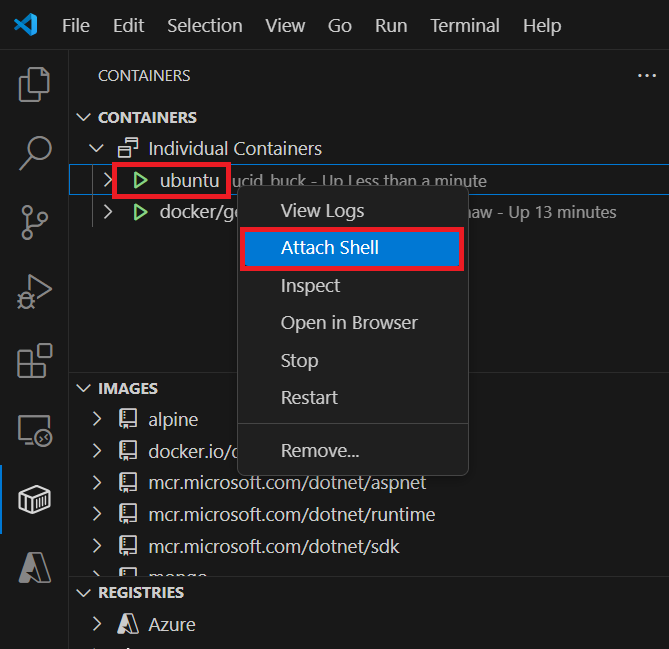
Otwiera się terminal, który uruchamia powłokę w kontenerze Ubuntu.
Uruchom następujące polecenie, aby wyświetlić zawartość pliku
/data.txt.cat /data.txtW terminalu jest wyświetlana liczba z zakresu od 1 do 10000.
Aby użyć wiersza polecenia, aby wyświetlić ten wynik, pobierz identyfikator kontenera przy użyciu polecenia
docker psi uruchom następujące polecenie.docker exec <container-id> cat /data.txtUruchom kolejny kontener
ubuntu.docker run -d ubuntu bash -c "shuf -i 1-10000 -n 1 -o /data.txt && tail -f /dev/null"Użyj tego polecenia, aby przyjrzeć się zawartości folderu.
docker run -it ubuntu ls /Nie powinno być pliku
data.txt, ponieważ został zapisany na dysku tymczasowym tylko dla pierwszego kontenera.Wybierz te dwa kontenery systemu Ubuntu. Kliknij prawym przyciskiem myszy i wybierz pozycję Usuń. W wierszu polecenia można je usunąć przy użyciu polecenia
docker rm -f.
Utrwalanie danych zadań do wykonania przy użyciu nazwanych woluminów
Domyślnie aplikacja do zadań przechowuje swoje dane w SQLite Database w /etc/todos/todo.db.
SQLite Database to relacyjna baza danych, która przechowuje dane w jednym pliku.
Takie podejście działa w przypadku małych projektów.
Pojedynczy plik można utrwalać na hoście. Gdy udostępnisz go następnemu kontenerowi, aplikacja może kontynuować od miejsca, w którym została przerwana. Tworząc wolumin i dołączając lub zamontowaniado folderu, w którym są przechowywane dane, można utrwalać dane. Kontener zapisuje w pliku todo.db, a dane są utrwalane na hoście w woluminie.
W tej sekcji użyj woluminu o nazwie. Platforma Docker utrzymuje lokalizację fizyczną woluminu na dysku. Odwołaj się do nazwy woluminu, i Docker udostępnia odpowiednie dane.
Utwórz wolumin przy użyciu polecenia
docker volume create.docker volume create todo-dbW obszarze CONTAINERSwybierz getting-started i kliknij prawym przyciskiem myszy. Wybierz Zatrzymaj, aby zatrzymać kontener aplikacji.
Aby zatrzymać kontener z wiersza polecenia, użyj polecenia
docker stop.Uruchom kontener getting-started, używając następującego polecenia.
docker run -dp 3000:3000 -v todo-db:/etc/todos getting-startedParametr woluminu określa wolumin do zainstalowania i lokalizacji,
/etc/todos.Odśwież przeglądarkę, aby ponownie załadować aplikację. Jeśli okno przeglądarki zostało zamknięte, przejdź do
http://localhost:3000/. Dodaj niektóre elementy do listy zadań do wykonania.
Usuń kontener rozpoczęcie dla aplikacji do zadań. Kliknij prawym przyciskiem myszy kontener w Eksploratorze kontenerów i wybierz polecenie Usuń lub użyj poleceń
docker stopidocker rm.Uruchom nowy kontener przy użyciu tego samego polecenia:
docker run -dp 3000:3000 -v todo-db:/etc/todos getting-startedTo polecenie instaluje ten sam dysk co poprzednio. Odśwież przeglądarkę. Dodane elementy są nadal na liście.
Usuń ponownie kontener getting-started.
Nazwane woluminy i powiązania montowania, omówione poniżej, są głównymi typami woluminów obsługiwanymi domyślnie przez instalację silnika Docker.
| Własność | Nazwane wolumeny | Wiązania montażowe |
|---|---|---|
| Lokalizacja hosta | Docker wybiera | Kontrolujesz |
Przykład mocowania (przy użyciu -v) |
my-volume:/usr/local/data | /path/to/data:/usr/local/data |
| Wypełnia nowy wolumin zawartością kontenera | Tak | Nie |
| Obsługuje sterowniki woluminów | Tak | Nie |
Dostępnych jest wiele wtyczek sterowników woluminów do obsługi NFS, SFTP, NetApp i innych technologii. Te wtyczki są szczególnie ważne, aby uruchamiać kontenery na wielu hostach w środowisku klastra, takim jak Swarm lub Kubernetes.
Jeśli zastanawiasz się, gdzie Docker rzeczywiście przechowuje twoje dane, uruchom następujące polecenie.
docker volume inspect todo-db
Przyjrzyj się wynikowi podobnemu do tego.
[
{
"CreatedAt": "2019-09-26T02:18:36Z",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/todo-db/_data",
"Name": "todo-db",
"Options": {},
"Scope": "local"
}
]
Mountpoint to rzeczywista lokalizacja, w której są przechowywane dane.
Na większości komputerów potrzebny jest dostęp do katalogu głównego, aby uzyskać dostęp do tego katalogu z hosta.
Korzystanie z montowania w trybie bind
W przypadku powiązanych punktów montowania , można kontrolować dokładny punkt montowania na hoście. Takie podejście utrwala dane, ale jest często używane do dostarczania większej ilości danych do kontenerów. Możesz użyć instalacji powiązania, aby zainstalować kod źródłowy w kontenerze, aby umożliwić mu wyświetlanie zmian kodu, reagowanie i wyświetlanie zmian od razu.
Aby uruchomić kontener w celu obsługi przepływu pracy programowania, wykonaj następujące kroki:
Usuń wszystkie kontenery
getting-started.W folderze
appuruchom następujące polecenie.docker run -dp 3000:3000 -w /app -v ${PWD}:/app node:lts-alpine sh -c "yarn install && yarn run dev"To polecenie zawiera następujące parametry.
-
-dp 3000:3000tak samo jak poprzednio. Uruchom w trybie odłączonym i utwórz mapowanie portu. -
-w /appKatalog roboczy wewnątrz kontenera. -
-v ${PWD}:/app"Zamontuj bieżący katalog z hosta w kontenerze do katalogu/app. -
node:lts-alpineObraz do użycia. Ten obraz jest obrazem podstawowym aplikacji z Dockerfile. -
sh -c "yarn install && yarn run dev"polecenie. Uruchamia powłokę przy użyciushi uruchamiayarn install, aby zainstalować wszystkie zależności. Następnie jest uruchamianyyarn run dev. Jeśli spojrzysz napackage.json, skryptdevrozpoczynanodemon.
-
Dzienniki można obserwować za pomocą
docker logs.docker logs -f <container-id>$ nodemon src/index.js [nodemon] 2.0.20 [nodemon] to restart at any time, enter `rs` [nodemon] watching path(s): *.* [nodemon] watching extensions: js,mjs,json [nodemon] starting `node src/index.js` Using sqlite database at /etc/todos/todo.db Listening on port 3000Po wyświetleniu końcowego wpisu na tej liście aplikacja jest uruchomiona.
Po zakończeniu oglądania dzienników naciśnij dowolny klawisz w oknie terminala lub wybierz Ctrl+C w oknie zewnętrznym.
W programie VS Code otwórz plik src/static/js/app.js. Zmień tekst przycisku Dodaj element w wierszu 109.
- {submitting ? 'Adding...' : 'Add Item'} + {submitting ? 'Adding...' : 'Add'}Zapisz zmianę.
Odśwież przeglądarkę. Powinieneś dostrzec tę zmianę.

node:lts-alpineUsuń kontener.W folderze
appuruchom następujące polecenie, aby usunąćnode_modulesfolder utworzony w poprzednich krokach.rm -r node_modules
Wyświetlanie warstw obrazów
Możesz przyjrzeć się warstwom tworzącym obraz.
Uruchom polecenie docker image history, aby wyświetlić polecenie użyte do utworzenia każdej warstwy na obrazie.
Użyj
docker image history, aby wyświetlić warstwy w obrazie rozpoczynającym, który utworzyłeś wcześniej w tym samouczku.docker image history getting-startedWynik powinien przypominać te dane wyjściowe.
IMAGE CREATED CREATED BY SIZE COMMENT a78a40cbf866 18 seconds ago /bin/sh -c #(nop) CMD ["node" "/app/src/ind… 0B f1d1808565d6 19 seconds ago /bin/sh -c yarn install --production 85.4MB a2c054d14948 36 seconds ago /bin/sh -c #(nop) COPY dir:5dc710ad87c789593… 198kB 9577ae713121 37 seconds ago /bin/sh -c #(nop) WORKDIR /app 0B b95baba1cfdb 13 days ago /bin/sh -c #(nop) CMD ["node"] 0B <missing> 13 days ago /bin/sh -c #(nop) ENTRYPOINT ["docker-entry… 0B <missing> 13 days ago /bin/sh -c #(nop) COPY file:238737301d473041… 116B <missing> 13 days ago /bin/sh -c apk add --no-cache --virtual .bui… 5.35MB <missing> 13 days ago /bin/sh -c #(nop) ENV YARN_VERSION=1.21.1 0B <missing> 13 days ago /bin/sh -c addgroup -g 1000 node && addu… 74.3MB <missing> 13 days ago /bin/sh -c #(nop) ENV NODE_VERSION=12.14.1 0B <missing> 13 days ago /bin/sh -c #(nop) CMD ["/bin/sh"] 0B <missing> 13 days ago /bin/sh -c #(nop) ADD file:e69d441d729412d24… 5.59MBKażdy z wierszy reprezentuje warstwę na obrazie. Dane wyjściowe pokazują podstawę u dołu z najnowszą warstwą u góry. Korzystając z tych informacji, można zobaczyć rozmiar każdej warstwy, pomagając zdiagnozować duże obrazy.
Kilka wierszy jest obcinanych. Jeśli dodasz parametr
--no-trunc, uzyskasz pełne dane wyjściowe.docker image history --no-trunc getting-started
Zależności pamięci podręcznej
Po zmianie warstwy należy ponownie utworzyć wszystkie warstwy podrzędne. Oto ponownie Dockerfile:
FROM node:lts-alpine
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "/app/src/index.js"]
Każde polecenie w Dockerfile staje się nową warstwą w obrazie.
Aby zminimalizować liczbę warstw, można przeprowadzić restrukturyzację Dockerfile, aby umożliwić buforowanie zależności.
W przypadku aplikacji opartych na Node.js te zależności są zdefiniowane w pliku package.json.
Podejście polega na skopiowaniu najpierw tylko tego pliku, zainstalowaniu zależności i następnie skopiowaniu reszty.
Proces odtwarza tylko zależności przędzy, jeśli nastąpiła zmiana package.json.
Zaktualizuj Dockerfile, aby najpierw skopiować
package.json, zainstalować zależności, a następnie skopiować wszystkie inne elementy. Oto nowy plik:FROM node:lts-alpine WORKDIR /app COPY package.json yarn.lock ./ RUN yarn install --production COPY . . CMD ["node", "/app/src/index.js"]Skompiluj nowy obraz przy użyciu
docker build.docker build -t getting-started .Powinny zostać wyświetlone dane wyjściowe podobne do następujących:
Sending build context to Docker daemon 219.1kB Step 1/6 : FROM node:lts-alpine ---> b0dc3a5e5e9e Step 2/6 : WORKDIR /app ---> Using cache ---> 9577ae713121 Step 3/6 : COPY package* yarn.lock ./ ---> bd5306f49fc8 Step 4/6 : RUN yarn install --production ---> Running in d53a06c9e4c2 yarn install v1.17.3 [1/4] Resolving packages... [2/4] Fetching packages... info fsevents@1.2.9: The platform "linux" is incompatible with this module. info "fsevents@1.2.9" is an optional dependency and failed compatibility check. Excluding it from installation. [3/4] Linking dependencies... [4/4] Building fresh packages... Done in 10.89s. Removing intermediate container d53a06c9e4c2 ---> 4e68fbc2d704 Step 5/6 : COPY . . ---> a239a11f68d8 Step 6/6 : CMD ["node", "/app/src/index.js"] ---> Running in 49999f68df8f Removing intermediate container 49999f68df8f ---> e709c03bc597 Successfully built e709c03bc597 Successfully tagged getting-started:latestWszystkie warstwy zostały przebudowane. Ten wynik jest oczekiwany, ponieważ zmieniono Dockerfile.
Wprowadź zmianę w src/static/index.html. Na przykład zmień tytuł, aby powiedzieć "The Awesome Todo App".
Zbuduj teraz obraz Docker ponownie, używając
docker build. Tym razem dane wyjściowe powinny wyglądać nieco inaczej.Sending build context to Docker daemon 219.1kB Step 1/6 : FROM node:lts-alpine ---> b0dc3a5e5e9e Step 2/6 : WORKDIR /app ---> Using cache ---> 9577ae713121 Step 3/6 : COPY package* yarn.lock ./ ---> Using cache ---> bd5306f49fc8 Step 4/6 : RUN yarn install --production ---> Using cache ---> 4e68fbc2d704 Step 5/6 : COPY . . ---> cccde25a3d9a Step 6/6 : CMD ["node", "/app/src/index.js"] ---> Running in 2be75662c150 Removing intermediate container 2be75662c150 ---> 458e5c6f080c Successfully built 458e5c6f080c Successfully tagged getting-started:latestPonieważ używasz pamięci podręcznej kompilacji, powinno to pójść znacznie szybciej.
Budowy wieloetapowe
Kompilacje wieloetapowe to niezwykle zaawansowane narzędzie ułatwiające tworzenie obrazu przy użyciu wielu etapów. Istnieje kilka zalet:
- Oddzielanie zależności czasu kompilacji od zależności środowiska uruchomieniowego
- Zmniejsz ogólny rozmiar obrazu, wysyłając tylko to, czego aplikacja musi uruchomić
Ta sekcja zawiera krótkie przykłady.
Przykład maven/Tomcat
Podczas kompilowania aplikacji opartych na języku Java potrzebny jest zestaw JDK do skompilowania kodu źródłowego do kodu bajtowego języka Java. Ten zestaw JDK nie jest potrzebny w środowisku produkcyjnym. Możesz używać narzędzi, takich jak Maven lub Gradle, aby ułatwić tworzenie aplikacji. Te narzędzia nie są również potrzebne na końcowym obrazie.
FROM maven AS build
WORKDIR /app
COPY . .
RUN mvn package
FROM tomcat
COPY --from=build /app/target/file.war /usr/local/tomcat/webapps
W tym przykładzie użyto jednego etapu, build, aby wykonać rzeczywistą kompilację języka Java przy użyciu narzędzia Maven.
Drugi etap, zaczynający się od "FROM tomcat", kopiuje pliki z etapu build.
Końcowy obraz jest tylko ostatnim tworzonym etapem, który można zastąpić przy użyciu parametru --target.
Przykład platformy React
Podczas budowania aplikacji React potrzebne jest środowisko Node, aby skompilować kod JavaScript, arkusze stylów Sass i inne źródła w statycznym kodzie HTML, JavaScript i CSS. Jeśli nie wykonujesz renderowania po stronie serwera, nie potrzebujesz nawet środowiska Node dla kompilacji produkcyjnej.
FROM node:lts-alpine AS build
WORKDIR /app
COPY package* yarn.lock ./
RUN yarn install
COPY public ./public
COPY src ./src
RUN yarn run build
FROM nginx:alpine
COPY --from=build /app/build /usr/share/nginx/html
W tym przykładzie użyto obrazu node:lts-alpine do wykonania kompilacji, która maksymalizuje buforowanie warstw, a następnie kopiuje dane wyjściowe do kontenera nginx.
Czyszczenie zasobów
Zachowaj wszystko, co zrobiłeś do tej pory, aby kontynuować tę serię poradników.
Następne kroki
Znasz już opcje utrwalania danych dla aplikacji kontenera.
Co chcesz zrobić dalej?
Praca z wieloma kontenerami przy użyciu narzędzia Docker Compose:
Tworzenie aplikacji wielokontenerowych za pomocą programów MySQL i Docker Compose
Wdrażanie do usługi Azure Container Apps:
Wdrażanie w usłudze Azure App Service