Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Adaptacja niskiej rangi (LoRA) może być wykorzystana do dostosowania modelu Phi Silica w celu zwiększenia jego wydajności dla konkretnego przypadku użycia. Korzystając z LoRA do optymalizowania Phi Silica w modelu językowym Microsoft Windows, można uzyskać dokładniejsze wyniki. Ten proces obejmuje trenowanie adaptera LoRA, a następnie stosowanie go podczas wnioskowania w celu zwiększenia dokładności modelu.
Uwaga / Notatka
Funkcje krzemionki Phi nie są dostępne w Chinach.
Wymagania wstępne
- Zidentyfikowałeś przypadek użycia do zwiększenia odpowiedzi Phi Silica.
- Wybrano kryteria oceny, aby zdecydować, jaka jest "dobra odpowiedź".
- Przetestowałeś interfejsy API Phi Silica i nie spełniają one twoich kryteriów oceny.
Przeszkol swój adapter
Aby wytrenować adapter LoRA do precyzyjnego dostrajania modelu Phi Silica przy użyciu Windows 11, należy najpierw wygenerować zestaw danych, który proces treningowy będzie wykorzystywał.
Generowanie zestawu danych do użycia z adapterem LoRA
Aby wygenerować zestaw danych, należy podzielić dane na dwa pliki:
train.json— jest używany do trenowania adaptera.test.json— służy do oceny wydajności adaptera podczas i po treningu.
Oba pliki muszą używać formatu JSON, gdzie każdy wiersz jest oddzielnym obiektem JSON reprezentującym pojedynczy przykład. Każdy przykład powinien zawierać listę komunikatów wymienianych między użytkownikiem a asystentem.
Każdy obiekt komunikatu wymaga dwóch pól:
content: tekst wiadomości.role"user": lub"assistant", wskazując nadawcę.
Zobacz następujące przykłady:
{"messages": [{"content": "Hello, how do I reset my password?", "role": "user"}, {"content": "To reset your password, go to the settings page and click 'Reset Password'.", "role": "assistant"}]}
{"messages": [{"content": "Can you help me find nearby restaurants?", "role": "user"}, {"content": "Sure! Here are some restaurants near your location: ...", "role": "assistant"}]}
{"messages": [{"content": "What is the weather like today?", "role": "user"}, {"content": "Today's forecast is sunny with a high of 25°C.", "role": "assistant"}]}
Porady dotyczące trenowania:
Na końcu każdego wiersza próbki nie jest potrzebny przecinek.
Uwzględnij jak najwięcej wysokiej jakości i różnorodnych przykładów. Aby uzyskać najlepsze wyniki, zbierz co najmniej kilka tysięcy przykładów treningowych w
train.jsonpliku.Plik
test.jsonmoże być mniejszy, ale powinien obejmować typy interakcji, które powinny być obsługiwane przez model.Utwórz pliki
train.jsonitest.json, z jednym obiektem JSON na wiersz, każdy zawierający krótką rozmowę pomiędzy użytkownikiem a asystentem. Jakość i ilość danych znacznie wpływają na skuteczność adaptera LoRA.
Trenowanie adaptera LoRA w zestawie narzędzi Foundry Toolkit
Aby wytrenować adapter LoRA przy użyciu zestawu narzędzi Foundry Toolkit for Visual Studio Code należy najpierw spełnić wymagane wymagania wstępne:
subskrypcja Azure z dostępnym limitem w Azure Container Apps.
- Zalecamy użycie GPU A100 lub lepszych, aby wydajnie wykonać zadanie fine-tuningu.
- Sprawdź, czy masz dostępny limit przydziału w Azure Portal. Jeśli chcesz uzyskać pomoc w znalezieniu limitu przydziału, zobacz Wyświetlanie limitów przydziału.
Jeśli jeszcze tego nie masz, musisz instalować Visual Studio Code.
Aby zainstalować zestaw narzędzi Foundry Toolkit for Visual Studio Code:
Pobierz rozszerzenie Zestawu narzędzi Foundry w Visual Studio Code
Po pobraniu rozszerzenia Foundry Toolkit będzie można uzyskać do niego dostęp z okienka lewego paska narzędzi w Visual Studio Code.
Przejdź do Narzędzia>Dostrajanie.
Wprowadź nazwę projektu i lokalizację projektu.
Wybierz pozycję "microsoft/phi-silica" z katalogu modeli.
Wybierz pozycję "Konfiguruj projekt".
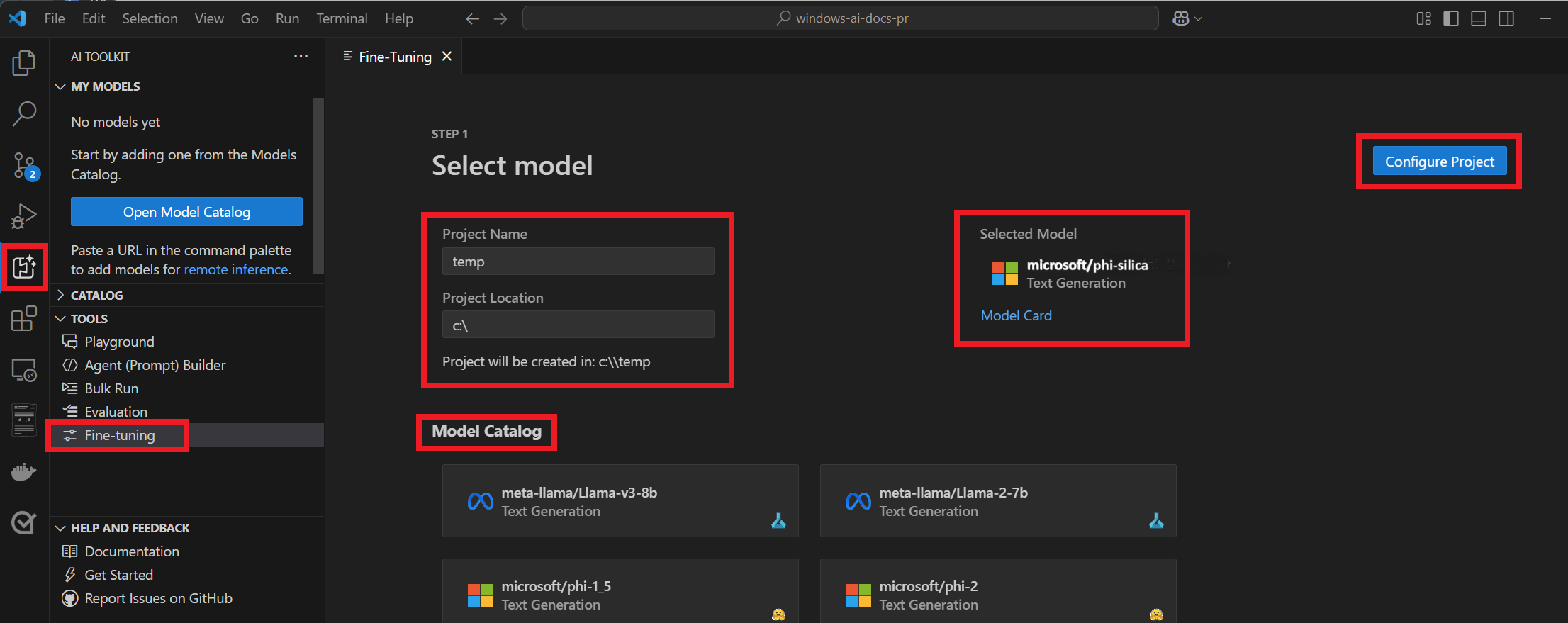
Wybierz najnowszą wersję Phi Silica.
Wybierz swoje pliki w obszarze danych>, nazwa zestawu danych trenowania i nazwa testowego zestawu danych
train.jsonitest.json.Wybierz pozycję "Generuj Project" — zostanie otwarte nowe okno programu VS Code.
Upewnij się, że w pliku bicep wybrano prawidłowy profil obciążenia, aby zadanie Azure zostało wdrożone i uruchomione poprawnie. Dodaj następujące elementy w obszarze
workloadProfiles:{ workloadProfileType: 'Consumption-GPU-NC24-A100' name: 'GPU' }Wybierz pozycję "Nowe zadanie dostrajania" i wprowadź nazwę zadania.
Zostanie wyświetlone okno dialogowe z prośbą o wybranie konto Microsoft, za pomocą którego będzie można uzyskać dostęp do subskrypcji Azure.
Po wybraniu konta musisz wybrać grupę zasobów z menu rozwijanego subskrypcji.
Teraz zobaczysz, że zadanie dostrajania zostało pomyślnie uruchomione wraz z informacją o stanie zadania. Po zakończeniu zadania będziesz mieć możliwość pobrania świeżo wyuczonego adaptera LoRA, klikając przycisk "Pobierz". Ukończenie zadania dostrajania zwykle trwa średnio 45– 60 minut.
Wnioskowanie
Trenowanie to faza początkowa, w której model sztucznej inteligencji uczy się na podstawie dużego zestawu danych, rozpoznawania wzorców i korelacji. Wnioskowanie to faza aplikacji, w której wytrenowany model (Silica Phi w naszym przypadku) używa nowych danych (nasz adapter LoRA) do dokonywania przewidywań lub podejmowania decyzji, aby wygenerować bardziej dostosowane dane wyjściowe.
Aby zastosować wyszkolony adapter LoRA:
Użyj aplikacji Galeria deweloperów sztucznej inteligencji. Galeria deweloperów sztucznej inteligencji to aplikacja, która umożliwia eksperymentowanie z lokalnymi modelami i interfejsem API sztucznej inteligencji, oprócz wyświetlania i eksportowania przykładowego kodu. Dowiedz się więcej o galerii deweloperów sztucznej inteligencji.
Po zainstalowaniu galerii deweloperów sztucznej inteligencji otwórz aplikację i wybierz kartę "Interfejsy API sztucznej inteligencji", a następnie wybierz pozycję "Phi Silica LoRA".
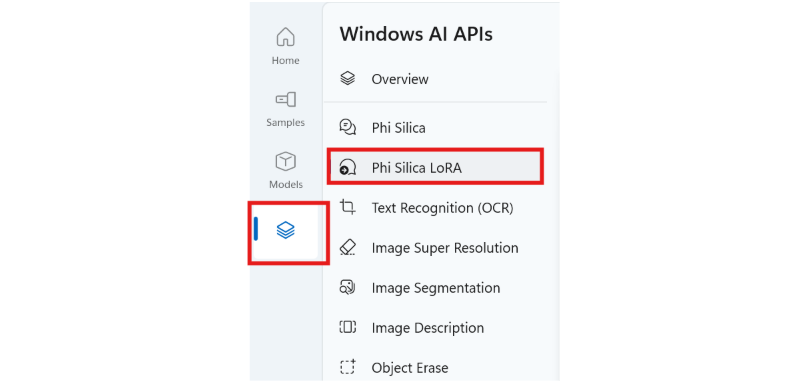
Wybierz plik adaptera. Domyślną lokalizacją tych, które mają być przechowywane, jest:
Desktop/lora_lab/trainedLora.Wypełnij pola "Monit systemowy" i "Monit". Następnie wybierz opcję "Generuj", aby zobaczyć różnicę między Phi Silica z oraz bez adaptera LoRA.
Poeksperymentuj z monitem i monitem systemowym, aby zobaczyć, jak to robi różnicę w danych wyjściowych.
Wybierz pozycję "Eksportuj przykład", aby pobrać autonomiczne rozwiązanie Visual Studio zawierające tylko ten przykładowy kod.
Generowanie odpowiedzi
Po przetestowaniu nowej karty LoRA przy użyciu galerii deweloperów AI możesz dodać kartę do aplikacji Windows, korzystając z poniższego przykładu kodu.
using Microsoft.Windows.AI.Text;
using Microsoft.Windows.AI.Text.Experimental;
// Path to the LoRA adapter file
string adapterFilePath = "C:/path/to/adapter/file.safetensors";
// Prompt to be sent to the LanguageModel
string prompt = "How do I add a new project to my Visual Studio solution?";
// Wait for LanguageModel to be ready
if (LanguageModel.GetReadyState() == AIFeatureReadyState.NotReady)
{
var languageModelDeploymentOperation = LanguageModel.EnsureReadyAsync();
await languageModelDeploymentOperation;
}
// Create the LanguageModel session
var session = LanguageModel.CreateAsync();
// Create the LanguageModelExperimental
var languageModelExperimental = new LanguageModelExperimental(session);
// Load the LoRA adapter
LowRankAdaptation loraAdapter = languageModelExperimental.LoadAdapter(adapterFilePath);
// Set the adapter in LanguageModelOptionsExperimental
LanguageModelOptionsExperimental options = new LanguageModelOptionsExperimental
{
LoraAdapter = loraAdapter
};
// Generate a response with the LoRA adapter provided in the options
var response = await languageModelExperimental.GenerateResponseAsync(prompt, options);
Odpowiedzialne używanie sztucznej inteligencji — czynniki ryzyka i ograniczenia dostosowywania
Gdy klienci dostosowują krzemionkę Phi, mogą poprawić wydajność i dokładność modelu w określonych zadaniach i obszarach, ale może to również wprowadzać nowe zagrożenia i ograniczenia, o których powinni być świadomi. Niektóre z tych czynników ryzyka i ograniczeń to:
Jakość i reprezentacja danych: jakość i reprezentatywność danych używanych do dostrajania mogą mieć wpływ na zachowanie i dane wyjściowe modelu. Jeśli dane są hałaśliwe, niekompletne, nieaktualne lub zawierają szkodliwe treści, takie jak stereotypy, model może dziedziczyć te problemy i generować niedokładne lub szkodliwe wyniki. Jeśli na przykład dane zawierają stereotypy dotyczące płci, model może je wzmocnić i wygenerować seksistowski język. Klienci powinni starannie wybierać i wstępnie przetwarzać swoje dane, aby upewnić się, że są one istotne, zróżnicowane i zrównoważone dla zamierzonego zadania i domeny.
Niezawodność i uogólnianie modelu: zdolność modelu do obsługi różnorodnych i złożonych danych wejściowych i scenariuszy może zmniejszyć się po dostrajaniu, zwłaszcza jeśli dane są zbyt wąskie lub specyficzne. Model może nadmiernie dopasować się do danych i utracić pewną ogólną wiedzę i możliwości. Jeśli na przykład dane dotyczą tylko sportu, model może mieć trudności z odpowiadaniem na pytania lub generowaniem tekstu na temat innych tematów. Klienci powinni ocenić wydajność i niezawodność modelu na różnych danych wejściowych i scenariuszach oraz unikać używania modelu dla zadań lub domen, które znajdują się poza jego zakresem.
Regurgitation: Podczas gdy dane szkoleniowe nie są dostępne dla Microsoft lub jakichkolwiek klientów innych firm, źle dostosowane modele mogą regurgitować lub bezpośrednio powtarzać dane treningowe. Klienci są odpowiedzialni za usunięcie wszelkich danych osobowych lub inaczej chronionych informacji z danych szkoleniowych i powinni ocenić swoje dopasowane modele pod kątem nadmiernego dopasowania lub niskiej jakości odpowiedzi. Aby uniknąć ponownego konfigurowania, klienci są zachęcani do udostępniania dużych i zróżnicowanych zestawów danych.
Przejrzystość i wyjaśnienie modelu: logika i rozumowanie modelu mogą stać się bardziej nieprzezroczyste i trudne do zrozumienia po dostrajaniu, zwłaszcza jeśli dane są złożone lub abstrakcyjne. Dostosowany model może generować dane wyjściowe, które są nieoczekiwane, niespójne lub sprzeczne, a klienci mogą nie być w stanie wyjaśnić, jak lub dlaczego model dotarł do tych danych wyjściowych. Jeśli na przykład dane dotyczą warunków prawnych lub medycznych, model może wygenerować dane wyjściowe, które są niedokładne lub mylące, a klienci mogą nie być w stanie ich zweryfikować lub uzasadnić. Klienci powinni monitorować i przeprowadzać inspekcję danych wyjściowych i zachowania modelu oraz dostarczać jasne i dokładne informacje oraz wskazówki dla użytkowników końcowych modelu.