Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga / Notatka
W celu zwiększenia funkcjonalności można również używać biblioteki PyTorch z językiem DirectML w systemie Windows.
W poprzednim etapie tego samouczka uzyskaliśmy zestaw danych, który będziemy używać do trenowania klasyfikatora obrazów za pomocą narzędzia PyTorch. Teraz nadszedł czas, aby wykorzystać te dane.
Aby wytrenować klasyfikator obrazu za pomocą narzędzia PyTorch, należy wykonać następujące czynności:
- Załaduj dane. Jeśli zrobiłeś poprzedni krok tego samouczka, już sobie z tym poradziłeś.
- Zdefiniuj splotową sieć neuronową.
- Zdefiniuj funkcję utraty.
- Wytrenuj model na danych treningowych.
- Przetestuj sieć na danych testowych.
Zdefiniuj splotową sieć neuronową.
Aby utworzyć sieć neuronową za pomocą narzędzia PyTorch, użyjesz torch.nn pakietu . Ten pakiet zawiera moduły, rozszerzalne klasy i wszystkie wymagane składniki do tworzenia sieci neuronowych.
Tutaj zbudujesz podstawową splotową sieć neuronową (CNN), aby sklasyfikować obrazy z zestawu danych CIFAR10.
Sieć CNN to klasa sieci neuronowych, zdefiniowana jako wielowarstwowe sieci neuronowe przeznaczone do wykrywania złożonych funkcji w danych. Są one najczęściej używane w aplikacjach przetwarzania obrazów.
Nasza sieć będzie mieć strukturę z następującymi 14 warstwami:
Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> MaxPool -> Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> Linear.
Warstwa splotowa
Warstwa konwolucyjna jest główną warstwą sieci CNN, która pomaga nam wykrywać cechy na obrazach. Każda z warstw ma wiele kanałów do wykrywania określonych funkcji na obrazach oraz wiele jąder w celu zdefiniowania rozmiaru wykrytej funkcji. W związku z tym warstwa konwolucyjna z 64 kanałami i rozmiarem jądra 3 x 3 wykrywa 64 odrębne cechy, każda o rozmiarze 3 x 3. Podczas definiowania warstwy konwolucyjnej należy podać liczbę kanałów wejściowych, liczbę kanałów wyjściowych i rozmiar filtra. Liczba wyjściowych kanałów w warstwie jest liczbą wejściowych kanałów dla następnej warstwy.
Na przykład: Warstwa konwolucyjna z in-channels=3, out-channels=10 i rozmiarem jądra wynoszącym 6x6 pobierze obraz RGB (3 kanały) jako dane wejściowe i zastosuje 10 detektorów cech do obrazu przy użyciu jądra o rozmiarze 6x6. Mniejsze rozmiary jądra zmniejszają czas obliczeniowy i podział wagi.
Inne warstwy
W naszej sieci są zaangażowane następujące inne warstwy:
- Warstwa
ReLUto funkcja aktywacji służąca do określania, czy wszystkie przychodzące cechy mają wartość 0 lub większą. Po zastosowaniu tej warstwy dowolna liczba mniejsza niż 0 jest zmieniana na zero, podczas gdy inne są zachowywane tak samo. -
BatchNorm2dwarstwa stosuje normalizację na danych wejściowych, aby uzyskać średnią zerową i wariancję jednostkową oraz zwiększyć dokładność sieci. - Warstwa
MaxPoolpomoże nam zapewnić, że lokalizacja obiektu na obrazie nie wpłynie na zdolność sieci neuronowej do wykrywania określonych funkcji. - Warstwa
Linearjest ostatnimi warstwami w naszej sieci, która oblicza wyniki poszczególnych klas. W zestawie danych CIFAR10 istnieją dziesięć klas etykiet. Etykieta o najwyższym wyniku będzie tą, którą przewiduje model. W warstwie liniowej należy określić liczbę funkcji wejściowych i liczbę funkcji wyjściowych, które powinny odpowiadać liczbie klas.
Jak działa sieć neuronowa?
Sieć CNN jest siecią jednokierunkową. Podczas procesu trenowania sieć przetworzy dane wejściowe we wszystkich warstwach, obliczy utratę, aby zrozumieć, jak daleko przewidywana etykieta obrazu spada z prawidłowego obrazu i propaguje gradienty z powrotem do sieci, aby zaktualizować wagi warstw. Iterując poprzez ogromny zbiór danych wejściowych, sieć będzie "uczyć się", aby ustawić swoje wagi w celu uzyskania najlepszych wyników.
Funkcja przesunięcia oblicza wartość funkcji straty, a funkcja odwrotna oblicza gradienty parametrów uczących się. Podczas tworzenia sieci neuronowej za pomocą biblioteki PyTorch wystarczy zdefiniować funkcję przesyłania dalej. Funkcja wsteczna zostanie automatycznie zdefiniowana.
- Skopiuj następujący kod do
PyTorchTraining.pypliku w programie Visual Studio, aby zdefiniować nazwę CCN.
import torch
import torch.nn as nn
import torchvision
import torch.nn.functional as F
# Define a convolution neural network
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*10*10, 10)
def forward(self, input):
output = F.relu(self.bn1(self.conv1(input)))
output = F.relu(self.bn2(self.conv2(output)))
output = self.pool(output)
output = F.relu(self.bn4(self.conv4(output)))
output = F.relu(self.bn5(self.conv5(output)))
output = output.view(-1, 24*10*10)
output = self.fc1(output)
return output
# Instantiate a neural network model
model = Network()
Uwaga / Notatka
Chcesz dowiedzieć się więcej o sieci neuronowej za pomocą rozwiązania PyTorch? Zapoznaj się z dokumentacją usługi PyTorch
Definiowanie funkcji utraty
Funkcja straty oblicza wartość, która szacuje, jak daleko dane wyjściowe pochodzą z obiektu docelowego. Głównym celem jest zmniejszenie wartości funkcji straty przez zmianę wartości wektora wagi poprzez propagację wsteczną w sieciach neuronowych.
Wartość straty różni się od dokładności modelu. Funkcja straty pozwala nam zrozumieć, jak dobrze działa model po każdej iteracji optymalizacji w zestawie treningowym. Dokładność modelu jest obliczana na danych testowych i przedstawia wartość procentową odpowiedniego przewidywania.
W rozwiązaniu PyTorch pakiet sieci neuronowej zawiera różne funkcje utraty, które tworzą bloki konstrukcyjne głębokich sieci neuronowych. W tym samouczku użyjesz funkcji straty klasyfikacji opartej na zdefiniowaniu funkcji straty z utratą klasyfikacji między entropiami i Optymalizatorem Adama. Szybkość nauki (lr) określa, w jakim stopniu dostosowujesz wagi twojej sieci w odniesieniu do gradientu strat. Ustawisz ją jako 0,001. Im niższa jest, tym wolniej będzie trenowanie.
- Skopiuj następujący kod do pliku
PyTorchTraining.pyw programie Visual Studio, aby zdefiniować funkcję straty i optymalizator.
from torch.optim import Adam
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Wytrenuj model na danych treningowych.
Aby wytrenować model, musisz iterować przez dane za pomocą iteratora, przesłać dane wejściowe do sieci i zoptymalizować. PyTorch nie ma dedykowanej biblioteki do użycia z procesorem GPU, ale można ręcznie zdefiniować urządzenie wykonawcze. Urządzenie będzie procesorem GPU firmy Nvidia, jeśli istnieje na twojej maszynie lub procesorem CPU, jeśli nie.
- Dodaj następujący kod do
PyTorchTraining.pypliku
from torch.autograd import Variable
# Function to save the model
def saveModel():
path = "./myFirstModel.pth"
torch.save(model.state_dict(), path)
# Function to test the model with the test dataset and print the accuracy for the test images
def testAccuracy():
model.eval()
accuracy = 0.0
total = 0.0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with torch.no_grad():
for data in test_loader:
images, labels = data
# run the model on the test set to predict labels
outputs = model(images.to(device))
# the label with the highest energy will be our prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
accuracy += (predicted == labels.to(device)).sum().item()
# compute the accuracy over all test images
accuracy = (100 * accuracy / total)
return(accuracy)
# Training function. We simply have to loop over our data iterator and feed the inputs to the network and optimize.
def train(num_epochs):
best_accuracy = 0.0
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device")
# Convert model parameters and buffers to CPU or Cuda
model.to(device)
for epoch in range(num_epochs): # loop over the dataset multiple times
running_loss = 0.0
running_acc = 0.0
for i, (images, labels) in enumerate(train_loader, 0):
# get the inputs
images = Variable(images.to(device))
labels = Variable(labels.to(device))
# zero the parameter gradients
optimizer.zero_grad()
# predict classes using images from the training set
outputs = model(images)
# compute the loss based on model output and real labels
loss = loss_fn(outputs, labels)
# backpropagate the loss
loss.backward()
# adjust parameters based on the calculated gradients
optimizer.step()
# Let's print statistics for every 1,000 images
running_loss += loss.item() # extract the loss value
if i % 1000 == 999:
# print every 1000 (twice per epoch)
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
# zero the loss
running_loss = 0.0
# Compute and print the average accuracy fo this epoch when tested over all 10000 test images
accuracy = testAccuracy()
print('For epoch', epoch+1,'the test accuracy over the whole test set is %d %%' % (accuracy))
# we want to save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
Przetestuj model na danych testowych.
Teraz możesz przetestować model przy użyciu partii obrazów z naszego zestawu testowego.
- Dodaj następujący kod do pliku
PyTorchTraining.py.
import matplotlib.pyplot as plt
import numpy as np
# Function to show the images
def imageshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Function to test the model with a batch of images and show the labels predictions
def testBatch():
# get batch of images from the test DataLoader
images, labels = next(iter(test_loader))
# show all images as one image grid
imageshow(torchvision.utils.make_grid(images))
# Show the real labels on the screen
print('Real labels: ', ' '.join('%5s' % classes[labels[j]]
for j in range(batch_size)))
# Let's see what if the model identifiers the labels of those example
outputs = model(images)
# We got the probability for every 10 labels. The highest (max) probability should be correct label
_, predicted = torch.max(outputs, 1)
# Let's show the predicted labels on the screen to compare with the real ones
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(batch_size)))
Na koniec dodajmy główny kod. Spowoduje to zainicjowanie trenowania modelu, zapisanie modelu i wyświetlenie wyników na ekranie. Uruchomimy tylko dwie iteracji [train(2)] w zestawie treningowym, więc proces trenowania nie potrwa zbyt długo.
- Dodaj następujący kod do pliku
PyTorchTraining.py.
if __name__ == "__main__":
# Let's build our model
train(5)
print('Finished Training')
# Test which classes performed well
testAccuracy()
# Let's load the model we just created and test the accuracy per label
model = Network()
path = "myFirstModel.pth"
model.load_state_dict(torch.load(path))
# Test with batch of images
testBatch()
Przeprowadźmy test! Upewnij się, że menu rozwijane na górnym pasku narzędzi są ustawione na Debug. Zmień platformę rozwiązania na x64, aby uruchomić projekt na komputerze lokalnym, jeśli urządzenie jest 64-bitowe lub x86, jeśli jest 32-bitowe.
Wybranie liczby epok (liczba ukończonych przejść przez dane treningowe) równej dwóm ([train(2)]) spowoduje dwukrotne przejście przez testowy zbiór danych zawierający 10 000 obrazów. Ukończenie trenowania na procesorze Intel 8 generacji potrwa około 20 minut, a model powinien osiągnąć mniej lub więcej 65% współczynnika powodzenia w klasyfikacji dziesięciu etykiet.
- Aby uruchomić projekt, kliknij przycisk Rozpocznij debugowanie na pasku narzędzi lub naciśnij F5.
Zostanie wyświetlone okno konsoli i będzie można zobaczyć proces trenowania.
Zgodnie z twoją definicją, wartość straty będzie wyświetlana co 1000 partii obrazów lub pięć razy w trakcie iteracji nad zestawem treningowym. Oczekujesz, że wartość straty spadnie wraz z każdą pętlą.
Zobaczysz również dokładność modelu po każdej iteracji. Dokładność modelu różni się od wartości straty. Funkcja straty pozwala nam zrozumieć, jak dobrze działa model po każdej iteracji optymalizacji w zestawie treningowym. Dokładność modelu jest obliczana na danych testowych i przedstawia wartość procentową odpowiedniego przewidywania. W naszym przypadku pokaże nam, ile obrazów z zestawu testowego 10 000 obrazów nasz model był w stanie poprawnie sklasyfikować po każdej iteracji trenowania.
Gdy szkolenie się zakończy, możesz spodziewać się wyniku podobnego do poniższego. Liczby nie będą dokładnie takie same — trening zależy od wielu czynników i nie zawsze zwraca identyczne wyniki — ale powinny być podobne.
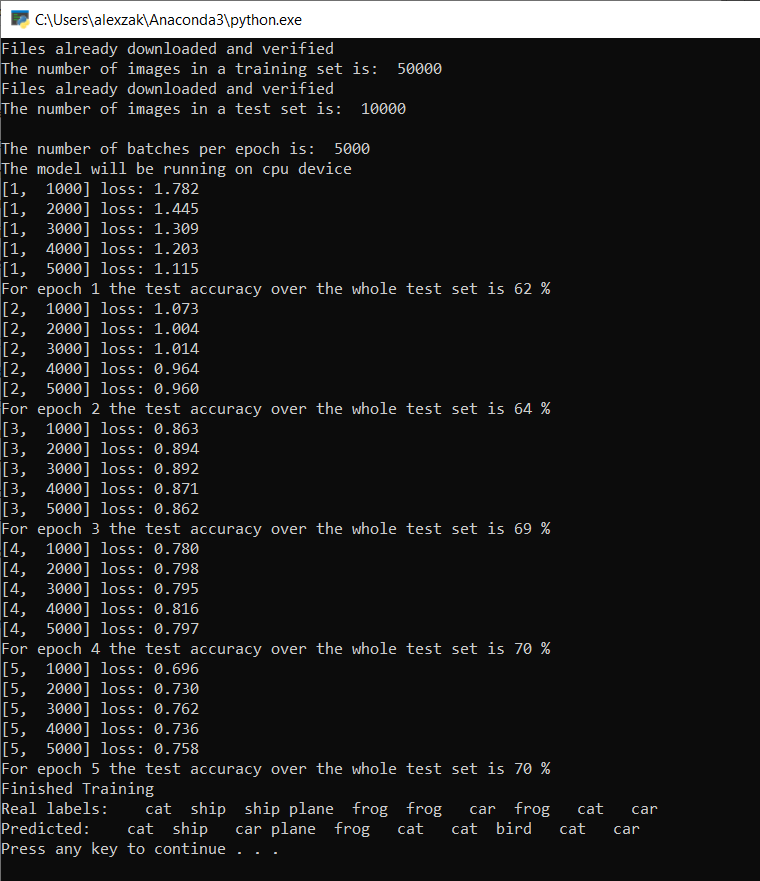
Po uruchomieniu zaledwie 5 iteracji współczynnik powodzenia modelu wynosi 70%. Jest to dobry wynik dla podstawowego modelu trenowanego przez krótki czas!
Testowanie przy użyciu partii obrazów, model poprawnie zidentyfikował 7 obrazów z partii liczącej 10. Nieźle w ogóle i zgodne z współczynnikiem powodzenia modelu.

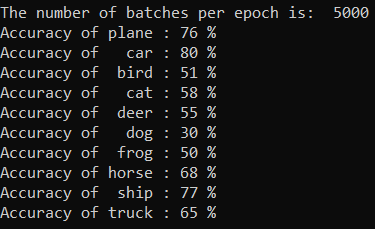
Możesz sprawdzić, które klasy nasz model może przewidzieć najlepiej. Po prostu dodaj i uruchom kod poniżej:
-
Opcjonalnie — dodaj następującą
testClassessfunkcję doPyTorchTraining.pypliku, dodaj wywołanie tej funkcji —testClassess()wewnątrz funkcji main —__name__ == "__main__".
# Function to test what classes performed well
def testClassess():
class_correct = list(0. for i in range(number_of_labels))
class_total = list(0. for i in range(number_of_labels))
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(batch_size):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(number_of_labels):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
Dane wyjściowe są następujące:
Dalsze kroki
Teraz, gdy mamy model klasyfikacji, następnym krokiem jest przekonwertowanie modelu na format ONNX