Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Rozpoznawanie mowy umożliwia podawanie danych wejściowych, określanie akcji lub polecenia i wykonywanie zadań.
Ważne interfejsy API: Windows.Media.SpeechRecognition
Rozpoznawanie mowy składa się z runtime'u mowy, interfejsów API do programowania tego runtime'u, gotowych gramatyk do dyktowania i wyszukiwania w sieci oraz domyślnego interfejsu użytkownika, który ułatwia użytkownikom odkrywanie i korzystanie z funkcji rozpoznawania mowy.
Konfigurowanie rozpoznawania mowy
Aby obsługiwać rozpoznawanie mowy w aplikacji, użytkownik musi podłączyć i włączyć mikrofon na swoim urządzeniu oraz zaakceptować zasady ochrony prywatności firmy Microsoft, przyznając tym samym aplikacji pozwolenie na jego użycie.
Aby automatycznie wyświetlić użytkownikowi okno dialogowe z prośbą o uprawnienia do dostępu i korzystania z sygnału dźwiękowego mikrofonu (jak w przykładzie rozpoznawania i syntezy mowy pokazanym poniżej), wystarczy ustawić możliwość urządzenia Mikrofon w manifeście pakietu aplikacji. Aby uzyskać więcej informacji, zobacz Deklaracje możliwości aplikacji.

Jeśli użytkownik kliknie pozycję Tak, aby udzielić dostępu do mikrofonu, aplikacja zostanie dodana do listy zatwierdzonych aplikacji na stronie Ustawienia —> Prywatność —> Mikrofon. Jednak ponieważ użytkownik może w dowolnym momencie wyłączyć to ustawienie, przed podjęciem próby użycia tego ustawienia należy potwierdzić, że aplikacja ma dostęp do mikrofonu.
Jeśli chcesz również obsługiwać dyktowanie, Cortanę lub inne usługi rozpoznawania mowy (takie jak wstępnie zdefiniowana gramatyka zdefiniowana w ograniczeniu tematu), musisz również potwierdzić, że funkcja rozpoznawania mowy online (Ustawienia —> Prywatność —> mowa) jest włączona.
Ten fragment kodu pokazuje, jak aplikacja może sprawdzić, czy mikrofon jest obecny i czy ma uprawnienia do korzystania z niego.
public class AudioCapturePermissions
{
// If no microphone is present, an exception is thrown with the following HResult value.
private static int NoCaptureDevicesHResult = -1072845856;
/// <summary>
/// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle
/// the Cortana/Dictation privacy check.
///
/// You should perform this check every time the app gets focus, in case the user has changed
/// the setting while the app was suspended or not in focus.
/// </summary>
/// <returns>True, if the microphone is available.</returns>
public async static Task<bool> RequestMicrophonePermission()
{
try
{
// Request access to the audio capture device.
MediaCaptureInitializationSettings settings = new MediaCaptureInitializationSettings();
settings.StreamingCaptureMode = StreamingCaptureMode.Audio;
settings.MediaCategory = MediaCategory.Speech;
MediaCapture capture = new MediaCapture();
await capture.InitializeAsync(settings);
}
catch (TypeLoadException)
{
// Thrown when a media player is not available.
var messageDialog = new Windows.UI.Popups.MessageDialog("Media player components are unavailable.");
await messageDialog.ShowAsync();
return false;
}
catch (UnauthorizedAccessException)
{
// Thrown when permission to use the audio capture device is denied.
// If this occurs, show an error or disable recognition functionality.
return false;
}
catch (Exception exception)
{
// Thrown when an audio capture device is not present.
if (exception.HResult == NoCaptureDevicesHResult)
{
var messageDialog = new Windows.UI.Popups.MessageDialog("No Audio Capture devices are present on this system.");
await messageDialog.ShowAsync();
return false;
}
else
{
throw;
}
}
return true;
}
}
/// <summary>
/// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle
/// the Cortana/Dictation privacy check.
///
/// You should perform this check every time the app gets focus, in case the user has changed
/// the setting while the app was suspended or not in focus.
/// </summary>
/// <returns>True, if the microphone is available.</returns>
IAsyncOperation<bool>^ AudioCapturePermissions::RequestMicrophonePermissionAsync()
{
return create_async([]()
{
try
{
// Request access to the audio capture device.
MediaCaptureInitializationSettings^ settings = ref new MediaCaptureInitializationSettings();
settings->StreamingCaptureMode = StreamingCaptureMode::Audio;
settings->MediaCategory = MediaCategory::Speech;
MediaCapture^ capture = ref new MediaCapture();
return create_task(capture->InitializeAsync(settings))
.then([](task<void> previousTask) -> bool
{
try
{
previousTask.get();
}
catch (AccessDeniedException^)
{
// Thrown when permission to use the audio capture device is denied.
// If this occurs, show an error or disable recognition functionality.
return false;
}
catch (Exception^ exception)
{
// Thrown when an audio capture device is not present.
if (exception->HResult == AudioCapturePermissions::NoCaptureDevicesHResult)
{
auto messageDialog = ref new Windows::UI::Popups::MessageDialog("No Audio Capture devices are present on this system.");
create_task(messageDialog->ShowAsync());
return false;
}
throw;
}
return true;
});
}
catch (Platform::ClassNotRegisteredException^ ex)
{
// Thrown when a media player is not available.
auto messageDialog = ref new Windows::UI::Popups::MessageDialog("Media Player Components unavailable.");
create_task(messageDialog->ShowAsync());
return create_task([] {return false; });
}
});
}
var AudioCapturePermissions = WinJS.Class.define(
function () { }, {},
{
requestMicrophonePermission: function () {
/// <summary>
/// Note that this method only checks the Settings->Privacy->Microphone setting, it does not handle
/// the Cortana/Dictation privacy check.
///
/// You should perform this check every time the app gets focus, in case the user has changed
/// the setting while the app was suspended or not in focus.
/// </summary>
/// <returns>True, if the microphone is available.</returns>
return new WinJS.Promise(function (completed, error) {
try {
// Request access to the audio capture device.
var captureSettings = new Windows.Media.Capture.MediaCaptureInitializationSettings();
captureSettings.streamingCaptureMode = Windows.Media.Capture.StreamingCaptureMode.audio;
captureSettings.mediaCategory = Windows.Media.Capture.MediaCategory.speech;
var capture = new Windows.Media.Capture.MediaCapture();
capture.initializeAsync(captureSettings).then(function () {
completed(true);
},
function (error) {
// Audio Capture can fail to initialize if there's no audio devices on the system, or if
// the user has disabled permission to access the microphone in the Privacy settings.
if (error.number == -2147024891) { // Access denied (microphone disabled in settings)
completed(false);
} else if (error.number == -1072845856) { // No recording device present.
var messageDialog = new Windows.UI.Popups.MessageDialog("No Audio Capture devices are present on this system.");
messageDialog.showAsync();
completed(false);
} else {
error(error);
}
});
} catch (exception) {
if (exception.number == -2147221164) { // REGDB_E_CLASSNOTREG
var messageDialog = new Windows.UI.Popups.MessageDialog("Media Player components not available on this system.");
messageDialog.showAsync();
return false;
}
}
});
}
})
Rozpoznawanie danych wejściowych mowy
Ograniczenie definiuje słowa i frazy (słownictwo), które aplikacja rozpoznaje w danych wejściowych mowy. Ograniczenia są podstawą rozpoznawania mowy i zapewniają aplikacji większą kontrolę nad dokładnością rozpoznawania mowy.
Do rozpoznawania danych wejściowych mowy można użyć następujących typów ograniczeń.
Wstępnie zdefiniowane gramatyki
Predefiniowane dyktowanie i gramatyki wyszukiwania internetowego zapewniają rozpoznawanie mowy dla aplikacji bez konieczności tworzenia gramatyki. W przypadku korzystania z tych gramatyk rozpoznawanie mowy jest wykonywane przez zdalną usługę internetową, a wyniki są zwracane do urządzenia.
Domyślna gramatyka dyktowania tekstu może rozpoznawać większość wyrazów i fraz, które użytkownik może powiedzieć w określonym języku i jest zoptymalizowany pod kątem rozpoznawania krótkich fraz. Wstępnie zdefiniowana gramatyka dyktowania jest używana, jeśli nie określisz żadnych ograniczeń dla obiektu SpeechRecognizer . Dyktowanie bez tekstu jest przydatne, gdy nie chcesz ograniczać rodzajów rzeczy, które użytkownik może powiedzieć. Typowe zastosowania obejmują tworzenie notatek lub dyktowanie zawartości komunikatu.
Gramatyka wyszukiwania w Internecie, taka jak gramatyka dyktowania, zawiera dużą liczbę słów i fraz, które użytkownik może powiedzieć. Jest ona jednak zoptymalizowana pod kątem rozpoznawania terminów, których użytkownicy zazwyczaj używają podczas wyszukiwania w Internecie.
Uwaga / Notatka
Ponieważ wstępnie zdefiniowane gramatyki dyktowania i wyszukiwania w sieci mogą być duże i działają online (nie na urządzeniu), wydajność może być wolniejsza niż w przypadku niestandardowej gramatyki zainstalowanej na urządzeniu.
Te wstępnie zdefiniowane gramatyki mogą służyć do rozpoznawania do 10 sekund danych wejściowych mowy i nie wymagają nakładu pracy podczas tworzenia. Jednak wymagają one połączenia z siecią.
Aby korzystać z ograniczeń usługi internetowej, obsługa wprowadzania mowy i dyktowania musi być włączona w obszarze Ustawienia, włączając opcję "Uzyskaj informacje o mnie" w obszarze Ustawienia — prywatność —>> mowa, pisanie odręczne i wpisywanie.
W tym miejscu pokażemy, jak sprawdzić, czy wprowadzanie głosowe jest włączone, i otworzyć stronę Ustawienia — Prywatność — Mowa, Pismo ręczne, Pisanie, jeśli nie.
Najpierw zainicjujemy zmienną globalną (HResultPrivacyStatementDeclined) do wartości HResult 0x80045509. Zobacz Obsługa wyjątków dla języka C# lub Visual Basic.
private static uint HResultPrivacyStatementDeclined = 0x80045509;
Następnie przechwycimy wszelkie standardowe wyjątki podczas rozpoznawania i przetestujemy, czy wartość HResult jest równa wartości zmiennej HResultPrivacyStatementDeclined. Jeśli tak, wyświetlamy ostrzeżenie i wywołujemy await Windows.System.Launcher.LaunchUriAsync(new Uri("ms-settings:privacy-accounts"));, aby otworzyć stronę ustawień.
catch (Exception exception)
{
// Handle the speech privacy policy error.
if ((uint)exception.HResult == HResultPrivacyStatementDeclined)
{
resultTextBlock.Visibility = Visibility.Visible;
resultTextBlock.Text = "The privacy statement was declined." +
"Go to Settings -> Privacy -> Speech, inking and typing, and ensure you" +
"have viewed the privacy policy, and 'Get To Know You' is enabled.";
// Open the privacy/speech, inking, and typing settings page.
await Windows.System.Launcher.LaunchUriAsync(new Uri("ms-settings:privacy-accounts"));
}
else
{
var messageDialog = new Windows.UI.Popups.MessageDialog(exception.Message, "Exception");
await messageDialog.ShowAsync();
}
}
Zobacz SpeechRecognitionTopicConstraint.
Ograniczenia listy programowej
Ograniczenia listy programowej zapewniają lekkie podejście do tworzenia prostych gramatyk przy użyciu listy wyrazów lub fraz. Ograniczenie listy dobrze sprawdza się w przypadku rozpoznawania krótkich, odrębnych fraz. Jawne określanie wszystkich wyrazów w gramatyce zwiększa również dokładność rozpoznawania, ponieważ aparat rozpoznawania mowy musi przetwarzać mowę tylko w celu potwierdzenia dopasowania. Lista może być również aktualizowana programowo.
Ograniczenie listy składa się z tablicy ciągów znaków reprezentujących dane wejściowe mowy, które aplikacja będzie akceptować podczas operacji rozpoznawania. Możesz utworzyć ograniczenie dotyczące listy w swojej aplikacji, tworząc obiekt ograniczenia listy rozpoznawania mowy i przekazując tablicę ciągów znaków. Następnie dodaj ten obiekt do kolekcji ograniczeń rozpoznawania. Rozpoznawanie kończy się pomyślnie, gdy rozpoznawanie mowy rozpoznaje dowolny z ciągów w tablicy.
Zobacz SpeechRecognitionListConstraint.
Gramatyki SRGS
Specyfikacja gramatyki rozpoznawania mowy (SRGS) jest dokumentem statycznym, który w przeciwieństwie do programowego ograniczenia listy używa formatu XML definiowanego przez SRGS w wersji 1.0. Gramatyka SRGS zapewnia największą kontrolę nad środowiskiem rozpoznawania mowy, umożliwiając przechwytywanie wielu semantycznych znaczeń w jednym rozpoznawaniu.
Zobacz SpeechRecognitionGrammarFileConstraint.
Ograniczenia poleceń głosowych
Użyj pliku XML definicji poleceń głosowych (VCD), aby zdefiniować polecenia, które użytkownik może powiedzieć, aby zainicjować akcje podczas aktywowania aplikacji. Aby uzyskać więcej informacji, zobacz Aktywowanie aplikacji pierwszego planu za pomocą poleceń głosowych za pośrednictwem Cortany.
Zobacz SpeechRecognitionVoiceCommandDefinitionConstraint/
Nuta Typ używanego typu ograniczenia zależy od złożoności środowiska rozpoznawania, które chcesz utworzyć. Każda z opcji może być najlepszym wyborem dla określonego zadania rozpoznawania i można znaleźć użycie dla wszystkich typów ograniczeń w aplikacji. Aby rozpocząć pracę z ograniczeniami, zobacz Definiowanie ograniczeń rozpoznawania niestandardowego.
Wstępnie zdefiniowana gramatyka dyktowania aplikacji uniwersalnych systemu Windows rozpoznaje większość słów i krótkich fraz w języku. Domyślnie jest aktywowany, kiedy obiekt rozpoznawania mowy jest tworzony bez ograniczeń niestandardowych.
W tym przykładzie pokazano, jak:
- Utwórz rozpoznawanie mowy.
- Skompiluj domyślne ograniczenia aplikacji uniwersalnej systemu Windows (żadne gramatyki nie zostały dodane do zestawu gramatyki aparatu rozpoznawania mowy).
- Zacznij rozpoznawanie mowy, używając podstawowego interfejsu użytkownika i informacji zwrotnej TTS, dostarczonej przez metodę RecognizeWithUIAsync. Użyj metody RecognizeAsync , jeśli domyślny interfejs użytkownika nie jest wymagany.
private async void StartRecognizing_Click(object sender, RoutedEventArgs e)
{
// Create an instance of SpeechRecognizer.
var speechRecognizer = new Windows.Media.SpeechRecognition.SpeechRecognizer();
// Compile the dictation grammar by default.
await speechRecognizer.CompileConstraintsAsync();
// Start recognition.
Windows.Media.SpeechRecognition.SpeechRecognitionResult speechRecognitionResult = await speechRecognizer.RecognizeWithUIAsync();
// Do something with the recognition result.
var messageDialog = new Windows.UI.Popups.MessageDialog(speechRecognitionResult.Text, "Text spoken");
await messageDialog.ShowAsync();
}
Dostosuj interfejs użytkownika rozpoznawania
Gdy aplikacja próbuje rozpoznać mowę, wywołując metodę SpeechRecognizer.RecognizeWithUIAsync, kilka ekranów jest wyświetlanych w następującej kolejności.
Jeśli używasz ograniczenia opartego na wstępnie zdefiniowanej gramatyce (dyktowaniu lub wyszukiwaniu w Internecie):
- Ekran Nasłuchiwanie .
- Ekran Myślenie .
- Ekran "Słyszałem, co powiedziałeś" lub ekran błędu.
Jeśli używasz ograniczenia opartego na liście wyrazów lub fraz albo ograniczenia opartego na pliku gramatycznym SRGS:
- Ekran Nasłuchiwania.
- Ekran "Czy powiedziałeś", jeśli to, co użytkownik powiedział, może być interpretowane jako więcej niż jeden możliwy wynik.
- Ekran 'Słyszałem, co mówisz' lub ekran błędu.
Na poniższej ilustracji przedstawiono przykład przepływu między ekranami rozpoznawania mowy, który używa ograniczenia opartego na pliku gramatycznym SRGS. W tym przykładzie rozpoznawanie mowy zakończyło się pomyślnie.
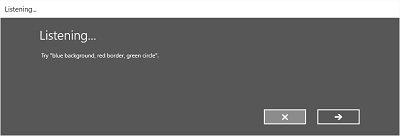
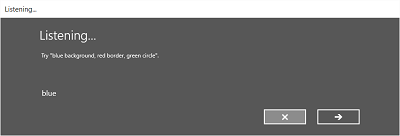
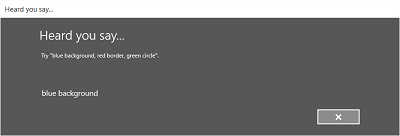
Ekran nasłuchiwania może zawierać przykłady słów lub fraz, które aplikacja może rozpoznać. W tym miejscu pokazano, jak używać właściwości klasy SpeechRecognizerUIOptions (uzyskanej przez wywołanie właściwości SpeechRecognizer.UIOptions ) w celu dostosowania zawartości na ekranie nasłuchiwania .
private async void WeatherSearch_Click(object sender, RoutedEventArgs e)
{
// Create an instance of SpeechRecognizer.
var speechRecognizer = new Windows.Media.SpeechRecognition.SpeechRecognizer();
// Listen for audio input issues.
speechRecognizer.RecognitionQualityDegrading += speechRecognizer_RecognitionQualityDegrading;
// Add a web search grammar to the recognizer.
var webSearchGrammar = new Windows.Media.SpeechRecognition.SpeechRecognitionTopicConstraint(Windows.Media.SpeechRecognition.SpeechRecognitionScenario.WebSearch, "webSearch");
speechRecognizer.UIOptions.AudiblePrompt = "Say what you want to search for...";
speechRecognizer.UIOptions.ExampleText = @"Ex. 'weather for London'";
speechRecognizer.Constraints.Add(webSearchGrammar);
// Compile the constraint.
await speechRecognizer.CompileConstraintsAsync();
// Start recognition.
Windows.Media.SpeechRecognition.SpeechRecognitionResult speechRecognitionResult = await speechRecognizer.RecognizeWithUIAsync();
//await speechRecognizer.RecognizeWithUIAsync();
// Do something with the recognition result.
var messageDialog = new Windows.UI.Popups.MessageDialog(speechRecognitionResult.Text, "Text spoken");
await messageDialog.ShowAsync();
}
Powiązane artykuły
Próbki
Współpracuj z nami na GitHub
Źródło tej treści można znaleźć na GitHubie, gdzie można także tworzyć i przeglądać problemy oraz pull requesty. Więcej informacji znajdziesz w naszym przewodniku dla współautorów.

Windows developer