Modelos personalizados de Informação de Documentos
Importante
- As versões preliminares públicas da Informação de Documentos oferecem acesso antecipado a recursos que estão em desenvolvimento ativo.
- Recursos, abordagens e processos podem ser alterados, antes da Disponibilidade Geral (GA), com base nos comentários do usuário.
- A versão prévia pública das bibliotecas de clientes da Informação de Documentos usa como padrão a versão da API REST 2024-02-29-preview.
- Atualmente, a versão prévia pública 2024-02-29-preview só está disponível nas seguintes regiões do Azure:
- Leste dos EUA
- Oeste dos EUA 2
- Oeste da Europa
Este conteúdo se aplica a:![]() v4.0 (versão prévia) | Versões anteriores:
v4.0 (versão prévia) | Versões anteriores:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
Este conteúdo se aplica a:![]() v3.1 (GA) | Versão mais recente:
v3.1 (GA) | Versão mais recente:![]() v4.0 (versão prévia) | Versões anteriores:
v4.0 (versão prévia) | Versões anteriores:![]() v3.0
v3.0![]() v2.1
v2.1
Este conteúdo se aplica a:![]() v3.0 (GA) | Últimas versões:
v3.0 (GA) | Últimas versões:![]() v4.0 (versão prévia)
v4.0 (versão prévia)![]() v3.1 | Versão anterior:
v3.1 | Versão anterior:![]() v2.1
v2.1
Este conteúdo se aplica a:![]() v2.1 | Versão mais recente:
v2.1 | Versão mais recente:![]() v4.0 (versão prévia)
v4.0 (versão prévia)
A Informação de Documentos usa tecnologia avançada de aprendizado de máquina para identificar documentos, detectar e extrair informações de formulários e documentos e retornar os dados extraídos em uma saída JSON estruturada. Com a Informação de Documentos, você pode usar os modelos de análise de documentos pré-compilados/pré- treinados, ou seus modelos personalizados independentes treinados.
Os modelos personalizados agora incluem modelos de classificação personalizados para cenários em que você precisa identificar o tipo de documento antes de invocar o modelo de extração. Os modelos de classificação estão disponíveis a partir da API 2023-07-31 (GA). Um modelo de classificação pode ser emparelhado com um modelo de extração personalizado para analisar e extrair campos de formulários e documentos específicos para sua empresa para criar uma solução de processamento de documentos. Os modelos de extração personalizados autônomos podem ser combinados para criar modelos compostos.
Tipos de modelo de documento personalizado
Modelos de documento personalizados podem ser de dois tipos, modelo personalizado ou formulário personalizado e modelos de documentos personalizados ou neurais personalizados. O processo de rotulagem e treinamento para os dois modelos é idêntico, mas os modelos diferem da seguinte maneira:
Modelos de extração personalizados
Para criar um modelo de extração personalizado, rotule um conjunto de dados de documentos com os valores que deseja extrair e treine o modelo no conjunto de dados rotulado. É necessário somente cinco exemplos do mesmo tipo de formulário ou documento para começar.
Modelo neural personalizado
Importante
A partir da versão 4.0 — API de visualização de 2024-02-29, os modelos neurais personalizados agora oferecem suporte a campos sobrepostos e confiança em nível de tabela, linha e célula.
O modelo neural personalizado (documento personalizado) usa modelos de aprendizado profundo e modelo base treinado em uma grande coleção de documentos. Esse modelo é ajustado ou adaptado aos seus dados quando você treina o modelo com um conjunto de dados rotulado. Os modelos neurais personalizados dão suporte a documentos estruturados, semiestruturados e não estruturados para extrair campos. No momento, modelos neurais personalizados dão suporte a documentos em inglês. Quando você estiver escolhendo entre os dois tipos de modelo, comece com um modelo neural para determinar se ele atender às suas necessidades funcionais. Confira modelos neurais para saber mais sobre modelos de documento personalizados.
Modelo de template personalizado
O template personalizado ou modelo de formulário personalizado depende de um template visual consistente para extrair os dados rotulados. As variações na estrutura de seus documentos afetam a precisão do seu modelo. Formulários estruturados, como questionários ou aplicativos, são exemplos de templates visuais consistentes.
Seu conjunto de treinamento consiste de documentos estruturados em que a formatação e o layout são estáticos e constantes de uma instância de documento para a próxima. Os modelos personalizados dão suporte a pares chave-valor, marcas de seleção, tabelas, campos de assinatura e regiões. Modelos de template e podem ser treinados em documentos em todos os idiomas compatíveis. Para obter mais informações, confiramodelos de template personalizado.
Se o idioma dos seus documentos e os cenários de extração dão suporte a modelos neurais personalizados, recomendamos usar modelos neurais personalizados em vez de modelos predefinidos para obter maior precisão.
Dica
Para confirmar que seus documentos de treinamento apresentam um template visual consistente, remova todos os dados inseridos pelo usuário de cada formulário no conjunto. Se os formulários em branco forem idênticos na aparência, eles representarão um template visual consistente.
Para obter mais informações, confiraInterpretar e melhorar a precisão e a confiança para modelos personalizados.
Requisitos de entrada
Para ter melhores resultados, forneça uma foto clara ou uma digitalização de alta qualidade por documento.
Formatos de arquivo com suporte:
Modelar PDF Imagem:
jpeg/jpg, png, bmp, tiff, heifMicrosoft Office:
Word (docx), Excel (xlsx), PowerPoint (pptx)Ler ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-02-29-preview, 2023-10-31-preview e posterior) Documento geral ✔ ✔ Predefinida ✔ ✔ Extração personalizada ✔ ✔ Classificação personalizada ✔ ✔ ✔ ✱ Atualmente, não há suporte para arquivos do Microsoft Office para outros modelos ou versões.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de camada gratuita, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para análise de documentos é 500 MB para a camada paga (S0) e 4 MB para a camada gratuita (F0).
As dimensões da imagem devem estar entre 50 x 50 pixels e 10.000 px x 10.000 pixels.
Se os PDFs estiverem com bloqueio de senha, você deverá remover o bloqueio antes do envio.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1.024 x 768 pixels. Essa dimensão corresponde a cerca de
8-texto de ponto a 150 pontos por polegada.Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para treinamento de modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo e 1G-MB para o modelo neural.
Para treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é
1GBcom no máximo 10.000 páginas.
Modo de criação
A operação de criação de modelo personalizado adicionou suporte para modelos personalizados predefinidos e neurais. As versões anteriores da API REST e das bibliotecas de cliente só dão suporte a um único modo de build que agora é conhecido como o modo de modelo.
Modelos de template aceitam apenas documentos que tenham a mesma estrutura de página básica – uma aparência visual uniforme – ou o mesmo posicionamento relativo de elementos dentro do documento.
Os modelos neurais dão suporte a documentos que têm as mesmas informações, mas estruturas de página diferentes. Exemplos desses documentos incluem formulários W2 dos Estados Unidos, que compartilham as mesmas informações, mas variam na aparência entre as empresas. Atualmente, os modelos neurais dão suporte apenas a texto em inglês.
Esta tabela fornece links para as referências do SDK da linguagem de programação do modo de compilação e exemplos de código no GitHub:
| Linguagem de programação | Referência do SDK | Exemplo de código |
|---|---|---|
| C# / .NET | DocumentBuildMode Struct | Sample_BuildCustomModelAsync.cs |
| Java | DocumentBuildMode Class | BuildModel.java |
| JavaScript | DocumentBuildMode type | buildModel.js |
| Python | DocumentBuildMode Enum | sample_build_model.py |
Comparar recursos de modelo
A tabela a seguir compara o modelo personalizado e os recursos neurais personalizados:
| Recurso | Modelo personalizado (formulário) | Neural personalizado (documento) |
|---|---|---|
| Estrutura do documento | Modelo, formulário e estruturado | Estruturado, semiestruturado e não estruturado |
| Tempo de treinamento | De 1 a 5 minutos | De 20 minutos a 1 hora |
| Extração de dados | Pares chave-valor, tabelas, marcas de seleção, coordenadas e assinaturas | Pares chave-valor, marcas de seleção e tabelas |
| Campos sobrepostos | Sem suporte | Com suporte |
| Variações de documento | Requer um modelo por variação | Usa um único modelo para todas as variações |
| Suporte ao idioma | Suporte a vários idiomas | Inglês, com suporte de versão prévia para suporte a idiomas para espanhol, francês, alemão, italiano e holandês |
Modelo de classificação personalizada
A classificação de documentos é um novo cenário com suporte pela Informação de Documentos com a API 2023-07-31 (v3.1 de disponibilidade geral). A API do classificador de documentos dá suporte a cenários de classificação e divisão. Treine um modelo de classificação para identificar os diferentes tipos de documentos aos quais seu aplicativo dá suporte. O arquivo de entrada para o modelo de classificação pode conter vários documentos e classifica cada documento dentro de um intervalo de páginas associado. Para saber mais, vejamodelos de classificação personalizada.
Observação
A partir da classificação do documento de versão da API 2024-02-29-preview agora dá suporte a tipos de documento do Office para classificação. Essa versão da API também apresenta o treinamento incremental para o modelo de classificação.
Ferramentas de modelo personalizado
Os modelos de Informação de Documentos v3.1 e posteriores dão suporte às seguintes ferramentas, aplicativos e bibliotecas, programas e bibliotecas:
| Recurso | Recursos | ID do Modelo |
|---|---|---|
| Modelo personalizado | • Estúdio da Informação de Documentos • API REST • SDK do C# • SDK do Python |
custom-model-id |
A Informação de Documentos v2.1 dá suporte às seguintes ferramentas, aplicativos e bibliotecas:
Observação
Os tipos de modelo de personalização neural e modelo personalizado estão disponíveis com as APIs de Informação de Documentos versão v3.1 e v3.0.
| Recurso | Recursos |
|---|---|
| Modelo personalizado | ● Ferramenta de rotulagem do recurso Informação de Documentos • API REST • SDK da biblioteca de clientes • Contêiner do Docker da Informação de Documentos |
Criar um modelo personalizado
Extraia dados de documentos específicos ou exclusivos usando modelos personalizados. Você precisa dos seguintes recursos:
Uma assinatura do Azure. É possível criar uma gratuitamente.
Uma instância da Informação de Documentos no portal do Azure. Você pode usar o tipo de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter a chave e o ponto de extremidade.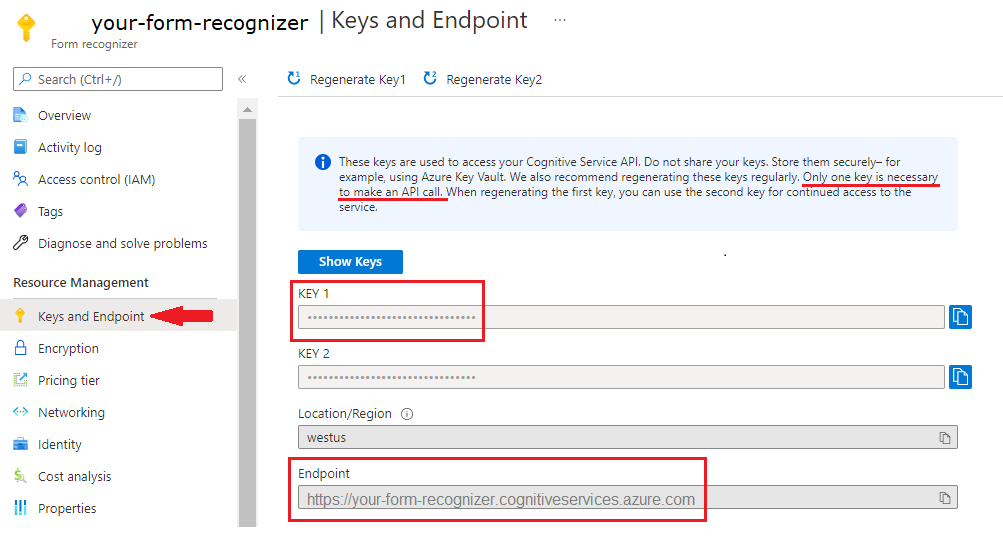
Ferramenta de rotulagem de exemplos
Dica
- Para obter uma experiência aprimorada e modelos de qualidade avançada, experimente o Estúdio de Informação de Documentos v3.0.
- O Studio v3.0 dá suporte a qualquer modelo treinado usando os dados rotulados da v2.1.
- Você pode consultar o guia de migração de API para obter informações detalhadas sobre como migrar da v2.1 para a v3.0.
- Confira nossos inícios rápidos da API REST ou do C#, Java, JavaScript ou do SDK para Python para começar a usar a versão v3.0.
A ferramenta de Rotulagem de Amostra de Informação de Documentos é uma ferramenta de código aberto que permite testar os recursos mais recentes da Informação de Documentos e os recursos de Reconhecimento Óptico de Caracteres (OCR).
Acesse o início rápido da ferramenta Rotulagem de Exemplo para começar a criar e usar um modelo personalizado.
Estúdio de Informação de Documentos
Observação
O Estúdio de Informação de Documentos está disponível com as APIs v3.1 e v3.0.
Na página inicial do Estúdio de Informação de Documentos, selecione Modelos de extração personalizados.
Em Meus projetos, selecione Criar um projeto.
Preencha os campos de detalhes do projeto.
Configure o recurso de serviço adicionando sua conta de armazenamento e seu contêiner de blob para Conectar sua fonte de dados de treinamento.
Revise e crie seu projeto.
Adicione seus documentos de exemplo para rotular, compilar e testar seu modelo personalizado.
Para obter um passo a passo detalhado para criar seu primeiro modelo de extração personalizado, consulteComo criar um modelo de extração personalizado.
Resumo da extração de modelo personalizado
Esta tabela compara as áreas de extração de dados com suporte:
| Modelar | Campos de formulário | Marcas de seleção | Campos estruturados (tabelas) | Assinatura | Rotulagem de região | Campos sobrepostos |
|---|---|---|---|---|---|---|
| Template personalizado | ✔ | ✔ | ✔ | ✔ | ✔ | n/a |
| Neural personalizado | ✔ | ✔ | ✔ | n/a | * | ✔ (2024-02-29-preview) |
Símbolos de tabela:
✔ — Com suporte
**n/a— atualmente indisponível;
*-Comporta-se de forma diferente dependendo do modelo. Com modelos, os dados sintéticos são gerados no momento do treinamento. Com modelos neurais, o texto de saída reconhecido na região é selecionado.
Dica
Ao escolher entre os dois tipos de modelo, comece com um modelo neural personalizado se ele atender às suas necessidades funcionais. Confira neural personalizada para saber mais sobre modelos neurais personalizados.
Opções de desenvolvimento de modelo personalizado
A tabela a seguir descreve os recursos disponíveis com as ferramentas e bibliotecas de cliente associadas. Como melhor prática, não deixe de usar as ferramentas compatíveis listadas aqui.
| Tipo de documento | API REST | . | Modelos de rótulo e teste |
|---|---|---|---|
| Modelo personalizado v 4.0, v3.1 e v3.0 | Informação de Documentos 3.1 | SDK da Informação de Documentos | Estúdio da Informação de Documentos |
| Neural personalizado v4.0, v3.1 e v3.0 | Informação de Documentos 3.1 | SDK da Informação de Documentos | Estúdio da Informação de Documentos |
| Formulário personalizado v2.1 | API de disponibilidade geral da Informação de Documentos 2.1 | SDK da Informação de Documentos | Ferramenta de rotulagem de exemplo |
Observação
Modelos de template personalizados treinados com a API 3.0 terão algumas melhorias em relação à API 2.1 que derivam de melhorias no mecanismo de OCR. Os conjuntos de dados usados para treinar um modelo de template personalizado usando a API 2.1 ainda podem ser usados para treinar um novo modelo usando a API 3.0.
Para ter melhores resultados, forneça uma foto clara ou uma digitalização de alta qualidade por documento.
Os formatos de arquivo com suporte são JPEG/JPG, PNG, BMP, TIFF e PDF (texto inserido ou digitalizado). PDFs com texto inserido são melhores porque eliminam a possibilidade de erro na extração e na localização de caracteres.
Para arquivos PDF e TIFF, até 2.000 páginas podem ser processadas. Para assinantes de camada gratuita, somente as duas primeiras páginas são processadas.
O tamanho do arquivo deve ter menos de 500 MB para a camada paga (S0) e 4 MB para a camada gratuita (F0).
As dimensões das imagens devem estar entre 50 x 50 pixels e 10.000 x 10.000 pixels.
As dimensões PDF têm até 17 x 17 polegadas, correspondentes ao tamanho de papel Legal ou A3 ou menor.
O tamanho total do conjunto de dados de treinamento é de 500 páginas ou menos.
Se os PDFs estiverem com bloqueio de senha, você deverá remover o bloqueio antes do envio.
Dica
Dados de treinamento:
- Se possível, use documentos PDF de texto em vez de documentos baseados em imagem. Os PDFs digitalizados são tratados como imagens.
- Forneça uma única instância do formulário por documento.
- Para formulários preenchidos, use exemplos com todos os campos preenchidos.
- Use os formulários com diferentes valores em cada campo.
- Se suas imagens de formulário forem de qualidade inferior, use um conjunto de dados maior. Por exemplo, use de 10 a 15 imagens.
Idiomas e localidades com suporte
Confira nosso página Suporte a Idiomas – modelos personalizados, para obter uma lista completa dos idiomas com suporte.
Próximas etapas
Tente processar seus próprios formulários e documentos com a ferramenta Rotulagem de Amostra da Informação de Documentos.
Execute um início rápido do serviço Informação de Documentos e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.
Experimente processar seus próprios formulários e documentos com o Estúdio da Informação de Documentos.
Execute um início rápido do serviço Informação de Documentos e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.