Essa arquitetura de referência mostra uma arquitetura sem servidor controlada por evento que ingere um fluxo de dados, processa os dados e grava os resultados em um banco de dados back-end.
Arquitetura
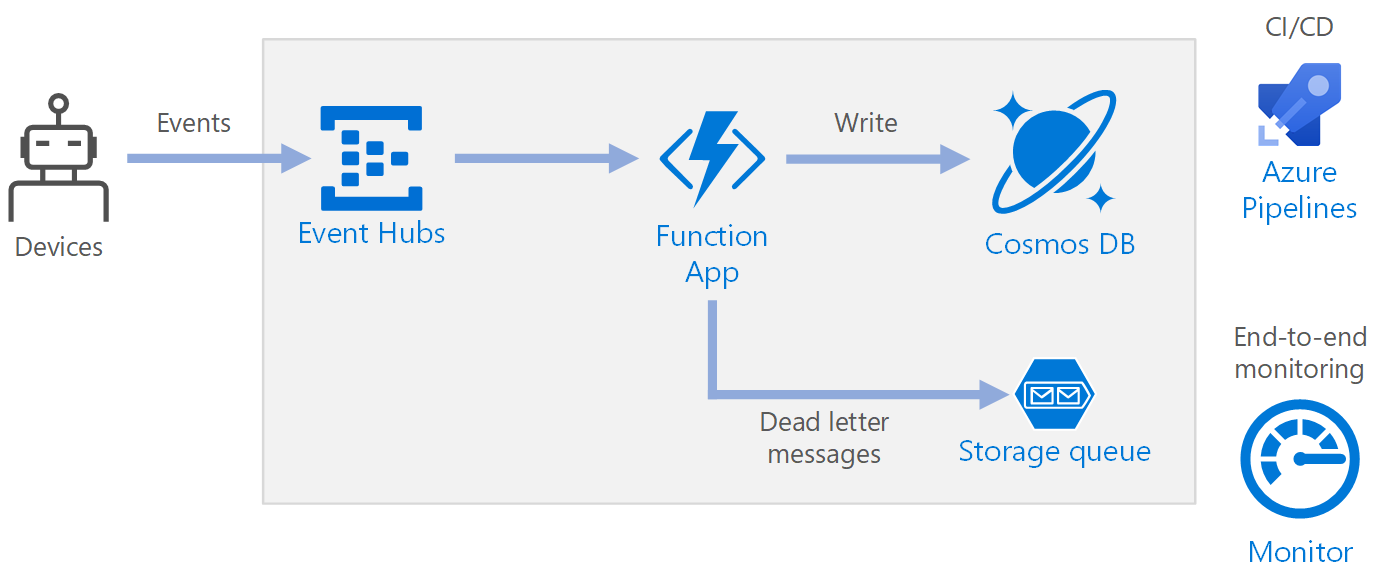
Fluxo de trabalho
- Os eventos chegam aos Hubs de Eventos do Azure.
- Um Aplicativo de Funções é disparado para manipular o evento.
- O evento é armazenado em um banco de dados do Azure Cosmos DB.
- Se o Aplicativo de Funções falhar ao armazenar o evento com êxito, o evento será salvo em uma fila de Armazenamento a ser processada posteriormente.
Componentes
Os Hubs de Eventos ingerem o fluxo de dados. Os Hubs de Eventos foram projetados para cenários de streaming de dados com alta taxa de transferência.
Observação
Para cenários de IoT (Internet das Coisas), recomendamos o Hub IoT do Azure. O Hub IoT tem um ponto de extremidade interno compatível com a API de Hubs de Eventos do Azure, para que você possa usar um dos serviços nessa arquitetura sem grandes mudanças no processamento de back-end. Para saber mais, confira Conectar dispositivos IoT ao Azure: Hub IoT e Hubs de Eventos.
Aplicativo de funções. O Azure Functions é uma opção de computação sem servidor. Ele usa um modelo controlado por eventos, em que um trecho de código (uma função) é invocado por um gatilho. Nessa arquitetura, quando os eventos chegam aos Hubs de Eventos, eles disparam uma função que processa os eventos e grava os resultados no armazenamento.
Os Aplicativos de Funções são adequados para processar registros individuais dos Hubs de Eventos. Para cenários de processamento de fluxo mais complexos, considere o Apache Spark com o Azure Databricks, ou o Azure Stream Analytics.
Azure Cosmos DB. O Azure Cosmos DB é um serviço de banco de dados de vários modelos que está disponível em um modo baseado em consumo sem servidor. Para esse cenário, a função de processamento de eventos armazena registros JSON usando o Azure Cosmos DB for NoSQL.
Armazenamento de filas. O Armazenamento de filas é usado para mensagens mortas. Se ocorrer um erro ao processar um evento, a função armazenará os dados do evento em uma fila de mensagens mortas para processamento posterior. Para obter mais informações, confira a seção Resiliência neste artigo.
Azure Monitor. O Monitor coleta métricas de desempenho sobre os serviços do Azure implantados na solução. Ao visualizá-las em um painel, você obtém informações sobre a integridade da solução.
Azure Pipelines. O Pipelines é um serviço de CI (integração contínua) e CD (entrega contínua) que compila, testa e implanta o aplicativo.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios de orientação que podem ser usados para aprimorar a qualidade de uma carga de trabalho. Para obter mais informações, confira Microsoft Azure Well-Architected Framework.
Disponibilidade
A implantação exibida aqui reside em uma única região do Azure. Para uma abordagem mais resiliente à recuperação de desastres, aproveite os recursos de distribuição geográfica de vários serviços:
- Hubs de Eventos. Crie dois namespaces de Hubs de Eventos, um namespace primário (ativo) e um namespace secundário (passivo). As mensagens são roteadas automaticamente para o namespace ativo, a menos que você faça o failover para o namespace secundário. Para saber mais, confira Recuperação de desastre geográfico dos Hubs de Eventos do Azure.
- Aplicativo de Funções. Implante um segundo aplicativo de função que está aguardando leitura do namespace secundário de Hubs de Eventos. Essa função grava em uma conta de armazenamento secundário para a fila de mensagens mortas.
- Azure Cosmos DB. O Azure Cosmos DB dá suporte a várias regiões de gravação, o que permite gravações em qualquer região que você adicionar à sua conta do Azure Cosmos DB. Se você não habilitar várias gravações, ainda poderá fazer o failover da região de gravação primária. Os SDKs de cliente do Azure Cosmos DB e as associações do Azure Functions lidam automaticamente com o failover, para que você não precise atualizar nenhuma definição de configuração de aplicativo.
- Armazenamento do Microsoft Azure. Use o armazenamento RA-GRS para a fila de mensagens mortas. Isso cria uma réplica somente leitura em outra região. Se a região primária ficar indisponível, você poderá ler os itens atualmente na fila. Além disso, provisione outra conta de armazenamento na região secundária para gravação da função após um failover.
Escalabilidade
Hubs de Eventos
A capacidade da taxa de transferência dos Hubs de Eventos é medida em unidades de produtividade. É possível fazer o dimensionamento automático de um hub de eventos ao permitir a inflação automática, o que dimensiona automaticamente as unidades de produtividade com base no tráfego até um número máximo configurado.
O gatilho dos Hubs de Eventos no aplicativo de funções é dimensionado de acordo com o número de partições no hub de eventos. Cada partição recebe uma instância de função por vez. Para maximizar a taxa de transferência, receba os eventos em lote, em vez de um de cada vez.
Azure Cosmos DB
O Azure Cosmos DB está disponível em dois modos de capacidade diferentes:
- Sem servidor, para cargas de trabalho com tráfego intermitente ou imprevisível e baixa taxa de tráfego média para pico.
- Taxa de transferência provisionada, para cargas de trabalho com tráfego sustentado que exigem desempenho previsível.
Para garantir que sua carga de trabalho seja escalonável, é importante escolher uma chave de partição apropriada ao criar seus contêineres do Azure Cosmos DB. Estas são algumas características de uma boa chave de partição:
- O espaço para o valor de chave é grande.
- Haverá uma distribuição uniforme de leituras/gravações por valor de chave, evitando teclas de atalho.
- O máximo de dados armazenado para qualquer valor de chave única não excederá o tamanho máximo da partição física (20 GB).
- A chave de partição de um documento não será alterada. Não é possível atualizar a chave de partição em um documento existente.
No cenário dessa arquitetura de referência, a função armazena exatamente um documento por dispositivo que está enviando dados. A função atualiza continuamente os documentos com o status mais recente do dispositivo, usando uma operação upsert. A ID do dispositivo é uma boa chave de partição para esse cenário, pois as gravações serão distribuídas uniformemente entre as chaves e o tamanho de cada partição será estritamente limitado, pois há um único documento para cada valor de chave. Para saber mais sobre chaves de particionamento, confira Particionar e dimensionar no Azure Cosmos DB.
Resiliência
Ao usar o gatilho dos Hubs de Eventos com o Functions, capture exceções dentro de seu loop de processamento. Se ocorrer uma exceção sem tratamento, o runtime do Functions não tentará novamente as mensagens. Se não for possível processar uma mensagem, coloque-a em uma fila de mensagens mortas. Use um processo fora de banda para examinar as mensagens e determinar a ação corretiva.
O código a seguir mostra como a função de ingestão captura exceções e coloca as mensagens não processadas em uma fila de mensagens mortas.
[FunctionName("RawTelemetryFunction")]
[StorageAccount("DeadLetterStorage")]
public static async Task RunAsync(
[EventHubTrigger("%EventHubName%", Connection = "EventHubConnection", ConsumerGroup ="%EventHubConsumerGroup%")]EventData[] messages,
[Queue("deadletterqueue")] IAsyncCollector<DeadLetterMessage> deadLetterMessages,
ILogger logger)
{
foreach (var message in messages)
{
DeviceState deviceState = null;
try
{
deviceState = telemetryProcessor.Deserialize(message.Body.Array, logger);
}
catch (Exception ex)
{
logger.LogError(ex, "Error deserializing message", message.SystemProperties.PartitionKey, message.SystemProperties.SequenceNumber);
await deadLetterMessages.AddAsync(new DeadLetterMessage { Issue = ex.Message, EventData = message });
}
try
{
await stateChangeProcessor.UpdateState(deviceState, logger);
}
catch (Exception ex)
{
logger.LogError(ex, "Error updating status document", deviceState);
await deadLetterMessages.AddAsync(new DeadLetterMessage { Issue = ex.Message, EventData = message, DeviceState = deviceState });
}
}
}
Observe que a função usa a associação de saída do armazenamento de filas para colocar itens na fila.
O código exibido acima também registra exceções em log para o Application Insights. Use o número de sequência e a chave de partição para correlacionar mensagens mortas com as exceções nos logs.
As mensagens na fila de mensagens mortas devem ter informações suficientes para você entender o contexto do erro. Neste exemplo, a classe DeadLetterMessage contém a mensagem de exceção, os dados do evento original e a mensagem de evento desserializada (se estiver disponível).
public class DeadLetterMessage
{
public string Issue { get; set; }
public EventData EventData { get; set; }
public DeviceState DeviceState { get; set; }
}
Use o Azure Monitor para monitorar o hub de eventos. Se você vir que há entrada, mas nenhuma saída, as mensagens não estarão sendo processadas. Nesse caso, acesse o Log Analytics e procure exceções ou outros erros.
DevOps
Use a IaC (infraestrutura como código) quando possível. A IaC gerencia a infraestrutura, o aplicativo e os recursos de armazenamento com uma abordagem declarativa como o Azure Resource Manager. Isso ajudará a automatizar a implantação usando o DevOps como uma solução de CI/CD (integração contínua e entrega contínua). Os modelos devem ter controle de versão e ser incluídos como parte do pipeline de lançamento.
Ao criar modelos, agrupe os recursos como uma forma de organizá-los e isolá-los por carga de trabalho. Uma maneira comum de pensar na carga de trabalho é um único aplicativo sem servidor ou uma rede virtual. A meta do isolamento de carga de trabalho é associar os recursos a uma equipe, para que a equipe de DevOps possa gerenciar de forma independente todos os aspectos desses recursos e realizar CI/CD.
Essa arquitetura inclui etapas para configurar o Aplicativo de Funções de Status do Drone usando o Azure Pipelines com YAML e slots Azure Functions.
Ao implantar seus serviços, você precisará monitorá-los. Use o Application Insights para permitir que os desenvolvedores monitorem o desempenho e detectem problemas.
Para obter mais informações, consulte a lista de verificação de DevOps.
Recuperação de desastre
A implantação exibida aqui reside em uma única região do Azure. Para uma abordagem mais resiliente à recuperação de desastres, aproveite os recursos de distribuição geográfica de vários serviços:
Hubs de Evento. Crie dois namespaces de Hubs de Eventos, um namespace primário (ativo) e um namespace secundário (passivo). As mensagens são roteadas automaticamente para o namespace ativo, a menos que você faça o failover para o namespace secundário. Para saber mais, confira Recuperação de desastre geográfico dos Hubs de Eventos do Azure.
Aplicativo de funções. Implante um segundo aplicativo de função que está aguardando leitura do namespace secundário de Hubs de Eventos. Essa função grava em uma conta de armazenamento secundário para a fila de mensagens mortas.
Azure Cosmos DB. O Azure Cosmos DB dá suporte a várias regiões de gravação, o que permite gravações em qualquer região que você adicionar à sua conta do Azure Cosmos DB. Se você não habilitar várias gravações, ainda poderá fazer o failover da região de gravação primária. Os SDKs do cliente do Azure Cosmos DB e as associações do Azure Function lidam automaticamente com o failover, portanto, você não precisa atualizar nenhuma configuração de aplicativo.
Armazenamento do Azure. Use o armazenamento RA-GRS para a fila de mensagens mortas. Isso cria uma réplica somente leitura em outra região. Se a região primária ficar indisponível, você poderá ler os itens atualmente na fila. Além disso, provisione outra conta de armazenamento na região secundária para gravação da função após um failover.
Otimização de custo
A otimização de custos é a análise de maneiras de reduzir as despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, confira Visão geral do pilar de otimização de custo.
Use a Calculadora de Preços do Azure para estimar os custos. Aqui estão algumas outras considerações sobre Azure Functions e o Azure Cosmos DB.
Funções do Azure
O Azure Functions dá suporte a dois modelos de hospedagem:
- Plano de consumo. O poder de computação é alocado automaticamente quando o código está em execução.
- Plano do Serviço de Aplicativo. Um conjunto de VMs (máquinas virtuais) é alocado para seu código. O plano de Serviço de Aplicativo define o número de VMs e o tamanho da VM.
Nessa arquitetura, cada evento que chega aos Hubs de Eventos dispara uma função que processa esse evento. De uma perspectiva de custo, a recomendação é usar o plano de consumo porque você paga apenas pelos recursos de computação que usa.
Azure Cosmos DB
Com o Azure Cosmos DB, você paga pelas operações executadas no banco de dados e pelo armazenamento consumido pelos dados.
- Operações de banco de dados. A maneira como você é cobrado pelas operações de banco de dados depende do tipo de conta do Azure Cosmos DB que você está usando.
- No modo sem servidor, você não precisa provisionar nenhuma taxa de transferência ao criar recursos em sua conta do Azure Cosmos DB. No final do período de cobrança, você será cobrado pela quantidade de Unidades de Solicitação consumidas pelas operações de banco de dados.
- No modo de taxa de transferência provisionada, você especifica a taxa de transferência necessária em Unidades de Solicitação por segundo (RU/s) e é cobrado por hora pela taxa de transferência máxima provisionada por uma determinada hora. Observação: como o modelo de taxa de transferência provisionada dedica recursos para seu contêiner ou banco de dados, você será cobrado pela taxa de transferência que provisionou mesmo se não executar cargas de trabalho.
- Armazenamento. Você será cobrado uma taxa fixa para a quantidade total de armazenamento (em GBs) consumida por seus dados e índices por determinada hora.
Nesta arquitetura de referência, a função armazena exatamente um documento por dispositivo que está enviando os dados. A função atualiza continuamente os documentos com o status mais recente do dispositivo, usando uma operação upsert, que é econômica em termos de armazenamento consumido. Para obter mais informações, consulte Modelo de preços do Azure Cosmos DB.
Use a calculadora de capacidade do Azure Cosmos DB para obter uma estimativa rápida do custo da carga de trabalho.
Implantar este cenário
 Uma implementação de referência para esta arquitetura está disponível no GitHub.
Uma implementação de referência para esta arquitetura está disponível no GitHub.
Próximas etapas
- Introdução ao Azure Functions
- Bem-vindo(a) ao Azure Cosmos DB
- O que é o Armazenamento de Filas do Azure?
- Visão geral do Azure Monitor
- Documentação do Azure Pipelines
Recursos relacionados
- Passo a passo do código: aplicativo sem servidor com o Azure Functions
- Monitoramento do processamento de eventos sem servidor
- Remoção de lotes e filtragem no processamento de eventos sem servidor com os Hubs de Eventos
- Cenário de link privado no processamento de fluxos de eventos
- Kubernetes do Azure no processamento de fluxos de eventos