O que é o Apache Hadoop no Azure HDInsight?
O Apache Hadoop era a estrutura de código aberto original para processamento distribuído e análise de conjuntos de Big Data em clusters. O ecossistema do Hadoop inclui software e utilitários relacionados, inclusive o Apache Hive, o Apache HBase, o Spark, o Kafka e muitos outros.
O HDInsight do Azure é um serviço de análise totalmente gerenciado, completo e de fonte aberta na nuvem para empresas. O tipo de cluster do Apache Hadoop no Azure HDInsight permite usar o HDFS (Sistema de Arquivos Distribuído do Apache Hadoop), YARN do Apache Hadoop e gerenciamento de recursos, bem como um modelo de programação MapReduce simples, para processar e analisar dados em lote em paralelo. Os clusters Hadoop no HDInsight são compatíveis com o Armazenamento de blobs do Azure, Azure Data Lake Storage Gen1 ou Azure Data Lake Storage Gen2.
Para ver os componentes disponíveis da pilha de tecnologia do Hadoop no HDInsight, confira Componentes e versões disponíveis com o HDInsight. Para ler mais sobre o Hadoop no HDInsight, consulte a Página de recursos do Azure para HDInsight.
O que é o MapReduce
O Apache Hadoop MapReduce é uma estrutura de software para gravar trabalhos que processam grandes quantidades de dados. Dados de entrada são divididos em partes independentes. Cada bloco é processado em paralelo em todos os nós no cluster. Um trabalho do MapReduce consiste em duas funções:
Mapeador: consome dados de entrada, analisa-os (normalmente com operações de classificação e filtro) e emite tuplas (pares chave-valor)
Redutor: consome tuplas emitidas pelo Mapeador e executa uma operação de resumo que cria um resultado menor e combinado dos dados do Mapeador
Um exemplo básico de trabalho de contagem de palavras do MapReduce está ilustrado no diagrama abaixo:
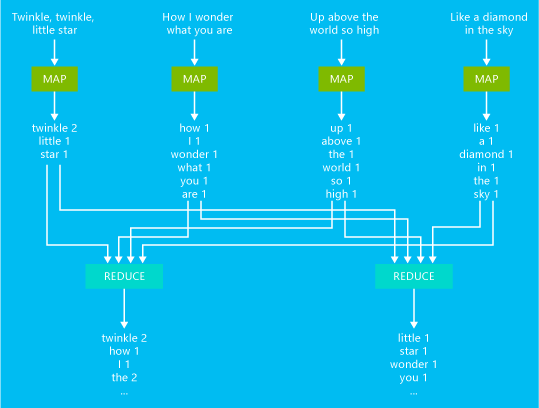
A saída deste trabalho é uma contagem de quantas vezes cada palavra ocorreu no texto.
- O mapeador utiliza cada linha do texto de entrada como uma entrada e a divide em palavras. Ele emite um par de chave/valor cada vez que ocorre uma palavra seguida de um 1. A saída será classificada antes de ser enviada ao redutor.
- Em seguida, o redutor soma essas contagens individuais para cada palavra e emite um par de chave/valor único que contém a palavra seguido pela soma de suas ocorrências.
O MapReduce pode ser implementado em várias linguagens. Java é a implementação mais comum e é usado para fins de demonstração neste documento.
Linguagens de desenvolvimento
As linguagens ou estruturas baseadas em Java e a Máquina Virtual Java podem ser executadas diretamente como um trabalho do MapReduce. O exemplo usado neste documento é um aplicativo MapReduce em Java. Linguagens não Java, como C#, Python ou executáveis autônomos devem usar o streaming do Hadoop.
O streaming do Hadoop se comunica com o mapeador e redutor por STDIN e STDOUT. O mapeador e redutor leem os dados uma linha por vez do STDIN e gravam a saída em STDOUT. Cada linha lida ou emitida pelo mapeador e redutor deve estar no formato de um par de chave/valor, delimitado por um caractere de tabulação:
[key]\t[value]
Para saber mais, confira Streaming do Hadoop.
Para ver exemplos do uso de streaming do Hadoop com o HDInsight, confira os seguintes documentos:
Por onde começar
- Início Rápido: Criar cluster do Apache Hadoop no Azure HDInsight usando o portal do Azure
- Tutorial: Enviar trabalhos do Apache Hadoop no HDInsight
- Desenvolver programas Java MapReduce para o Apache Hadoop no HDInsight
- Usar o Apache Hive como uma ferramenta ETL (extração, transformação e carregamento)
- ETL (extração, transformação e carregamento) em escala
- Operacionalize um pipeline de análise de dados