Apache Phoenix no Azure HDInsight
O Apache Phoenix é um banco de dados relacional de software livre altamente paralelo criado no Apache HBase. Phoenix permite que você use consultas SQL em HBase. O Phoenix usa drivers JDBC abaixo para permitir aos usuários criar, excluir, alterar tabelas SQL, índices, exibições e as sequências e linhas upsert individualmente e em massa. O Phoenix usa compilação nativa noSQL, em vez de usar o MapReduce para compilar consultas, permitindo a criação de aplicativos de baixa latência sobre HBase. O Phoenix adiciona coprocessadores para oferecer suporte à execução de código fornecido pelo cliente no espaço de endereço do servidor, executando o código colocalizado junto com os dados. Essa abordagem minimiza a transferência de dados do cliente/servidor.
O Apache Phoenix abre consultas de Big Data para não desenvolvedores que podem usar uma sintaxe semelhante ao SQL em vez de programação. O Phoenix é altamente otimizado para o HBase, diferentemente de outras ferramentas, como o Apache Hive e o Apache Spark SQL. Os benefícios para os desenvolvedores está gravando altamente consultas de alto desempenho com muito menos código.
Quando você envia uma consulta SQL, Phoenix compila a consulta a chamadas nativas HBase e executa a verificação (ou plano) em paralelo para otimização. Com essa camada de abstração, o desenvolvedor não precisa gravar os trabalhos do MapReduce e pode se concentrar na lógica de negócios e no fluxo de trabalho do aplicativo de armazenamento de Big Data do Phoenix.
Otimização de desempenho de consulta e outros recursos
O Apache Phoenix adiciona vários recursos e aprimoramentos de desempenho para consultas do HBase.
Índices secundários
HBase tem um único índice que é lexicograficamente classificado na chave da linha primária. Esses registros só podem ser acessados pela chave da linha. Acessar registros por meio de qualquer coluna que não seja a chave da linha requer a verificação de todos os dados ao aplicar o filtro obrigatório. Em um índice secundário, as colunas ou expressões que são indexadas formam uma chave de linha alternada, permitindo pesquisas e verificações de intervalo nesse índice.
Criar um índice secundário com o comando CREATE INDEX:
CREATE INDEX ix_purchasetype on SALTEDWEBLOGS (purchasetype, transactiondate) INCLUDE (bookname, quantity);
Essa abordagem pode produzir um aumento significativo de desempenho executando consultas únicas indexadas. Esse tipo de índice secundário é um índice de cobertura, que contém todas as colunas incluídas na consulta. Portanto, a pesquisa da tabela não é obrigatórioa e o índice satisfaz a consulta inteira.
Exibições
As exibições do Phoenix oferecem uma forma de resolver uma limitação do HBase, em que o desempenho começa a ser prejudicado quando você cria mais que cerca de 100 tabelas físicas. Exibições de Phoenix habilitam várias tabelas virtuais para compartilhar uma tabela do HBase física subjacente.
A criação de uma exibição do Phoenix é semelhante ao uso da sintaxe de exibição padrão do SQL. Uma diferença é que você pode definir colunas de exibição, além de colunas herdadas de sua tabela base. Você também pode adicionar novas colunas KeyValue.
Por exemplo, aqui está uma tabela física chamada product_metrics com a seguinte definição:
CREATE TABLE product_metrics (
metric_type CHAR(1) NOT NULL,
created_by VARCHAR,
created_date DATE NOT NULL,
metric_id INTEGER NOT NULL
CONSTRAINT pk PRIMARY KEY (metric_type, created_by, created_date, metric_id));
Defina uma exibição sobre essa tabela, com colunas adicionais:
CREATE VIEW mobile_product_metrics (carrier VARCHAR, dropped_calls BIGINT) AS
SELECT * FROM product_metrics
WHERE metric_type = 'm';
Para adicionar mais colunas depois, use a instrução ALTER VIEW.
Verificação de ignorar
Verificação de ignorar usa uma ou mais colunas de um índice composto para localizar valores distintos. Ao contrário de uma verificação de intervalo, verificação de ignorar implementa verificação intralinha, produzindo melhor desempenho. Durante a verificação, o primeiro valor correspondente será ignorado junto com o índice até o próximo valor ser encontrado.
Uma verificação de ignorar usa a enumeração SEEK_NEXT_USING_HINT do filtro HBase. Usando SEEK_NEXT_USING_HINT, a verificação de ignorar mantém o controle do conjunto de chaves ou intervalos de chaves, que estão sendo pesquisados para cada coluna. A verificação de ignorar usa a chave que foi passada durante a avaliação de filtro e determina se ela é uma das combinações. Caso contrário, a verificação de ignorar avalia a próxima chave mais alta a ser avaliada.
Transactions
Enquanto HBase fornece transações de nível de linha, Phoenix integra Tephra para adicionar suporte a transações entre linhas e de tabela cruzada com semântica ACID completa.
Da mesma forma que transações SQL tradicionais, as transações fornecidas por meio do gerenciador de transações Phoenix permitem que você certifique-se de que uma unidade atômica de dados é introduzida com êxito, revertendo a transação se a operação de inserção falhar em qualquer tabela de transações habilitadas.
Para habilitar transações Phoenix, consulte a documentação de transação do Apache Phoenix.
Para criar uma nova tabela com transações habilitadas, defina a TRANSACTIONAL propriedade true em uma CREATE instrução:
CREATE TABLE my_table (k BIGINT PRIMARY KEY, v VARCHAR) TRANSACTIONAL=true;
Para alterar uma tabela existente para ser transacional, use a mesma propriedade em uma ALTER instrução:
ALTER TABLE my_other_table SET TRANSACTIONAL=true;
Observação
Você não pode reverter uma tabela transacional novamente em uma não-transacional.
Tabelas Distribuídas
O ponto de acesso do servidor de região pode ocorrer durante a gravação de registros com chaves sequenciais no HBase. Embora você tenha vários servidores de região no seu cluster, suas gravações estão ocorrendo em apenas um. Essa concentração cria o problema de hotspotting onde, em vez de sua carga de trabalho de gravação ser distribuída em todos os servidores de região disponíveis, apenas um deles está controlando a carga. Como cada região tem um tamanho máximo predefinido, quando uma região atinge esse limite de tamanho, ela é dividida em duas regiões pequenas. Quando isso acontece, uma nova região tem todos os novos registros, tornando-se o novo ponto de acesso.
Para atenuar esse problema e aumentar o desempenho, divida as tabelas antecipadamente de modo que todos os servidores de região sejam usados por igual. O Phoenix fornece tabelas distribuídas, de modo transparente adicionando o byte de distribuição à chave de linha de uma tabela específica. A tabela é previamente dividida em limites salt byte para garantir a distribuição de carga entre os servidores de região durante a fase inicial da tabela. Essa abordagem distribui a carga de trabalho de gravação em todos os servidores de região disponíveis, melhorando a gravação e o desempenho de leitura. Para distribuir uma tabela, especifique a propriedade de tabela SALT_BUCKETS quando a tabela for criada:
CREATE TABLE Saltedweblogs (
transactionid varchar(500) Primary Key,
transactiondate Date NULL,
customerid varchar(50) NULL,
bookid varchar(50) NULL,
purchasetype varchar(50) NULL,
orderid varchar(50) NULL,
bookname varchar(50) NULL,
categoryname varchar(50) NULL,
invoicenumber varchar(50) NULL,
invoicestatus varchar(50) NULL,
city varchar(50) NULL,
state varchar(50) NULL,
paymentamount DOUBLE NULL,
quantity INTEGER NULL,
shippingamount DOUBLE NULL) SALT_BUCKETS=4;
Habilitar e ajustar o Phoenix com o Apache Ambari
Um cluster HDInsight HBase inclui a interface de usuário do Ambari para fazer alterações de configuração.
Para habilitar ou desabilitar Phoenix e controlar as configurações de tempo limite de consulta do Phoenix, faça logon na interface do usuário do Ambari Web (
https://YOUR_CLUSTER_NAME.azurehdinsight.net) usando suas credenciais de usuário do Hadoop.Selecione HBase na lista de serviços no menu esquerdo, em seguida selecione a guia Configurações.
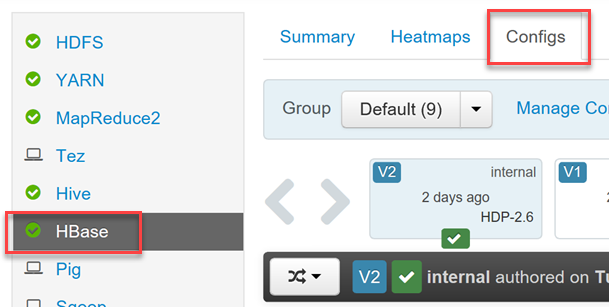
Localize a seção de configuração Phoenix SQL para habilitar ou desabilitar phoenix e definir o tempo limite da consulta.