Depurar trabalhos do Apache Spark em execução no Azure HDInsight
Neste artigo, você aprenderá a controlar e depurar trabalhos do Apache Spark em execução em clusters do HDInsight. Depure usando a interface do usuário do YARN do Apache Hadoop, a interface do usuário do Spark e o servidor de histórico do Spark. Você começará um trabalho do Spark usando um notebook disponível com o cluster Spark, Aprendizado de máquina: análise preditiva nos dados de inspeção de alimentos usando MLLib. Use as etapas a seguir para rastrear um aplicativo que foi enviado usando qualquer outra abordagem, por exemplo, spark-submit.
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Para obter instruções, consulte o artigo sobre como Criar clusters do Apache Spark no Azure HDInsight.
Você deve ter começado a executar o notebook Machine Learning: análise preditiva nos dados de inspeção de alimentos usando MLLib. Para obter instruções sobre como executar este notebook, siga o link.
Rastrear um aplicativo na interface do usuário do YARN
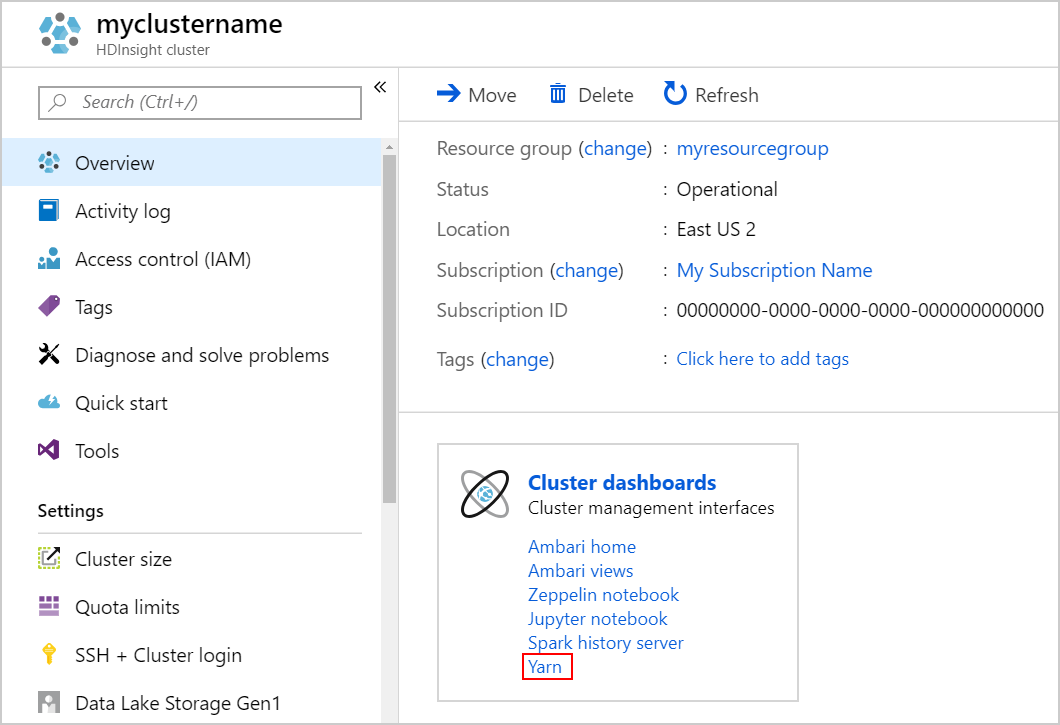
Inicie a interface do usuário do YARN. Selecione Yarn em Painéis do cluster.
Dica
Alternativamente, também é possível iniciar a interface do usuário do YARN na interface do usuário do Ambari. Para iniciar a IU do Ambari, selecione Página Inicial do Ambari em Painéis do cluster. Na IU do Ambari, navegue para YARN>Links Rápidos> o gerenciador de recursos ativo >Interface do usuário do gerenciador de recursos.
Como você iniciou o trabalho do Spark usando Jupyter Notebooks, o aplicativo tem o nome remotesparkmagics (o nome de todos os aplicativos que são iniciados dos notebooks). Selecione a ID de aplicativo com o nome do aplicativo para obter mais informações sobre o trabalho. Essa ação inicia o modo de exibição do aplicativo.
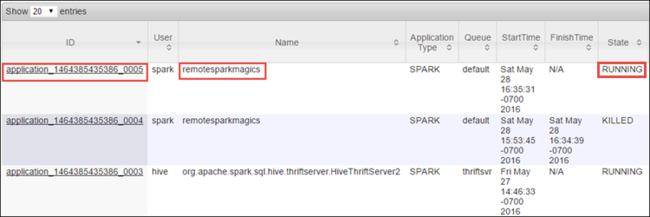
Para aplicativos que são iniciados do Jupyter Notebooks, o status é sempre EM EXECUÇÃO até que você saia do notebook.
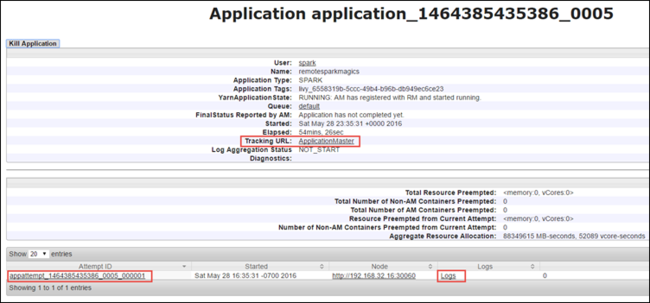
Na exibição de aplicativo, você pode fazer drill down para descobrir os contêineres associados ao aplicativo e os logs (stdout/stderr). Você também pode iniciar a interface do usuário do Spark clicando no link correspondente para a URL de Rastreamento, conforme mostrado abaixo.
Rastrear um aplicativo na interface do usuário do Spark
Na interface do usuário do Spark, é possível fazer drill down em trabalhos do Spark que são gerados pelo aplicativo iniciado anteriormente.
Para iniciar a interface do usuário do Spark, da exibição do aplicativo, selecione o link em URL de Rastreamento, conforme mostrado na captura de tela acima. Você pode ver todos os trabalhos do Spark que são iniciados pelo aplicativo em execução no Jupyter Notebook.
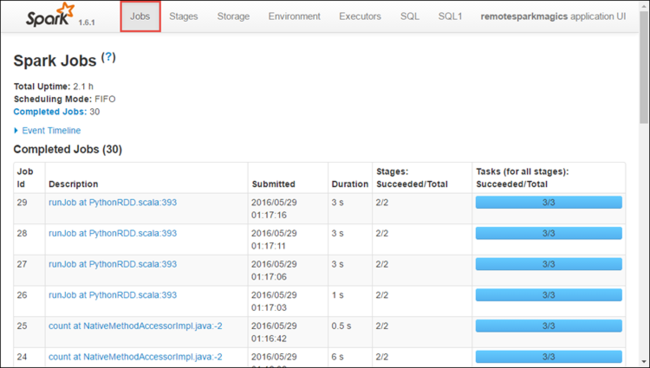
Selecione a guia Executores para ver informações de processamento e armazenamento de cada executor. Você também pode recuperar a pilha de chamadas selecionando o link Thread Dump (Despejo de Thread).
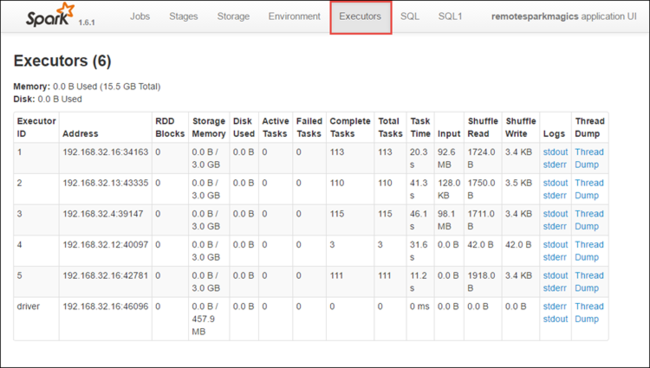
Selecione a guia Estágios para ver os estágios associados ao aplicativo.
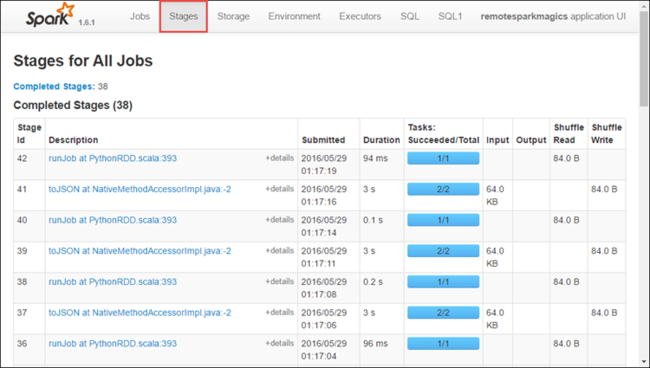
Cada estágio pode ter várias tarefas para as quais você pode exibir estatísticas de execução, como mostrado abaixo.
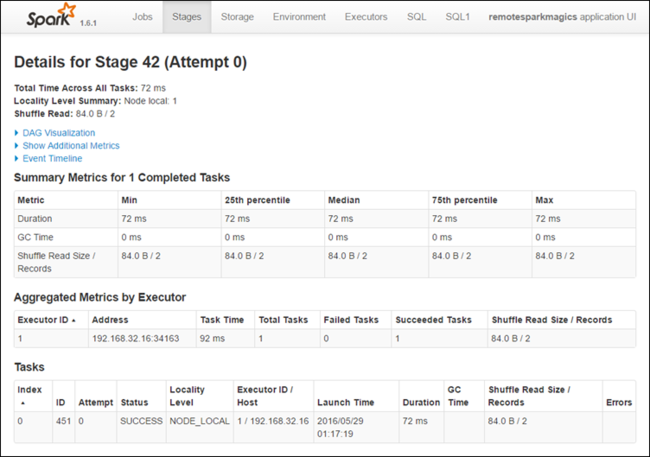
Na página de detalhes do estágio, você pode iniciar Visualização de DAG. Expanda o link DAG Visualization (Visualização de DAG) na parte superior da página, como mostrado abaixo.
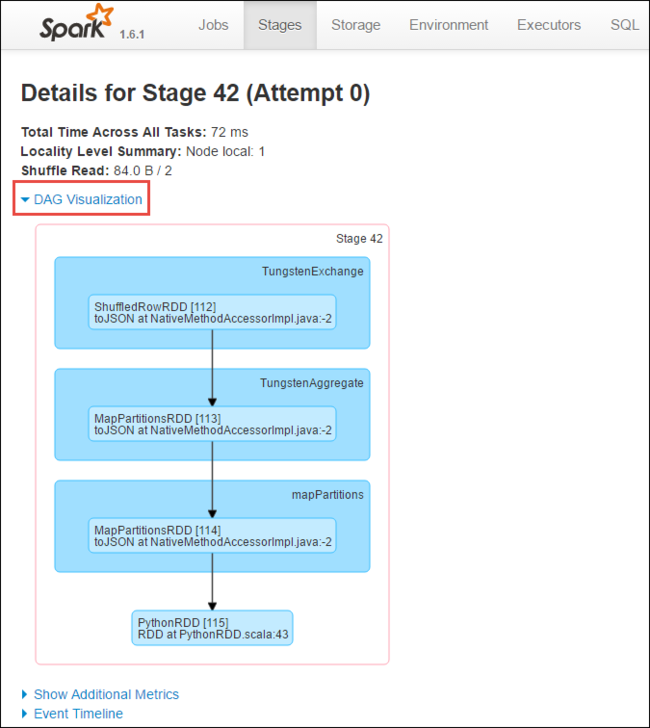
O DAG ou Grafo Acíclico Direto representa os diferentes estágios no aplicativo. Cada caixa azul no grafo representa uma operação do Spark iniciada do aplicativo.
Na página de detalhes do estágio, você também pode iniciar o modo de exibição de linha do tempo do aplicativo. Expanda o link Event Timeline (Linha do Tempo do Evento) na parte superior da página, como mostrado abaixo.
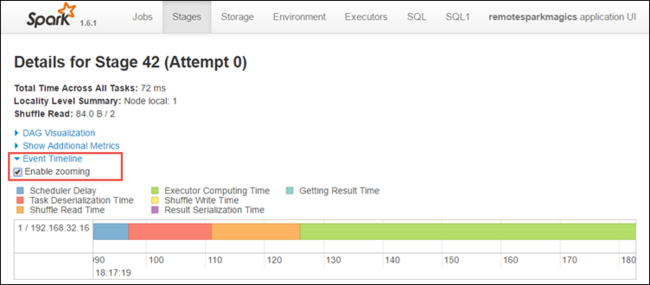
Essa imagem exibe os eventos do Spark na forma de uma linha do tempo. O modo de exibição de tempo está disponível em três níveis, entre trabalhos, dentro de um trabalho e dentro de um estágio. A imagem acima captura o modo de exibição de linha do tempo de um determinado estágio.
Dica
Se você selecionar a caixa de seleção Enable zooming (Habilitar zoom), poderá rolar para a esquerda e para a direita no modo de exibição de linha do tempo.
Outras guias na interface do usuário do Spark fornecem informações úteis sobre a instância do Spark.
- Guia Armazenamento: se seu aplicativo criar RDDs, você encontrará informações na guia Armazenamento.
- Guia Ambiente: esta guia contém informações úteis sobre a instância do Spark, como:
- Versão da escala
- Diretório de log de eventos associado ao cluster
- Número de núcleos de executor do aplicativo
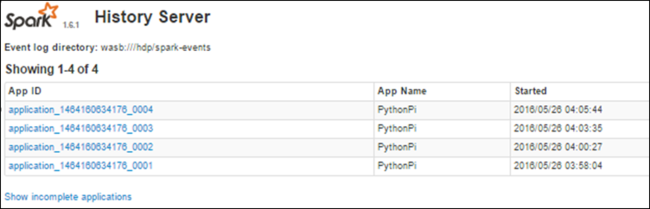
Encontrar informações sobre trabalhos concluídos usando o Servidor de Histórico do Spark
Quando um trabalho é concluído, as informações sobre ele são mantidas no Servidor de Histórico do Spark.
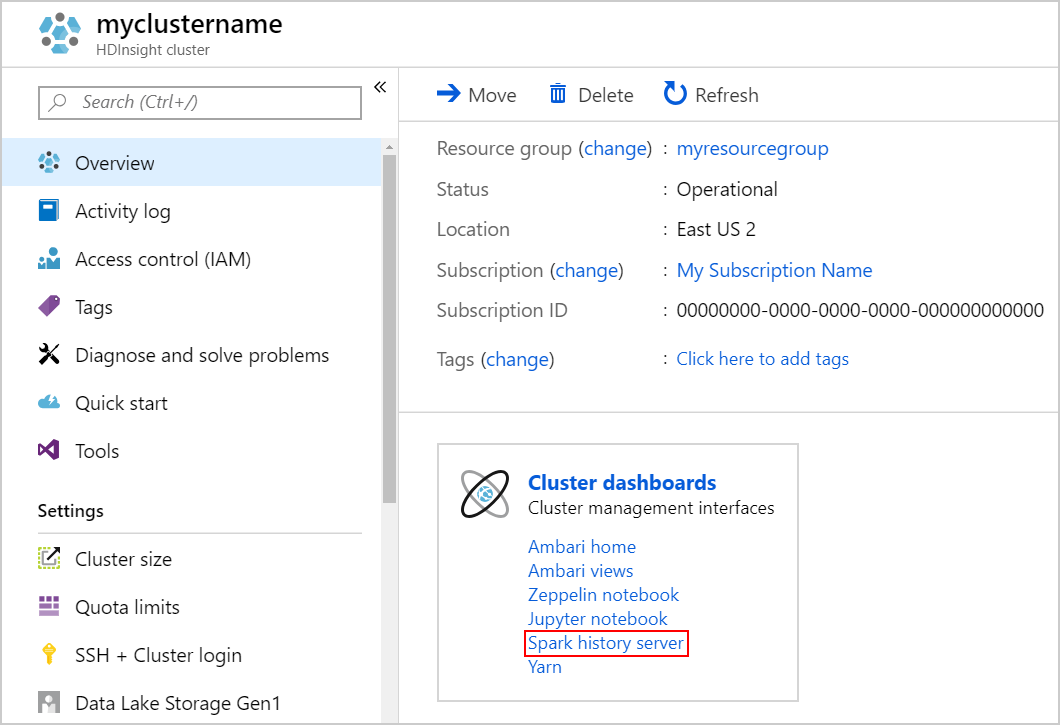
Para iniciar o servidor de histórico do Spark, na página Visão Geral, selecione Servidor de histórico do Spark em Painéis do cluster.
Dica
Alternativamente, também é possível iniciar a interface do usuário do Servidor de Histórico do Spark na interface do usuário do Ambari. Para iniciar a IU do Ambari, na folha de visão geral, selecione Página Inicial do Ambari em Painéis do cluster. Na IU do Ambari, navegue para Spark2>Links Rápidos>IU do Servidor de Histórico do Spark2.
Você verá todos os aplicativos concluídos listados. Selecione uma ID de aplicativo para fazer drill down em um aplicativo para obter mais informações.