Alta disponibilidade em Servidor único do Banco de Dados do Azure para PostgreSQL
APLICA-SE A: Banco de Dados do Azure para PostgreSQL – Servidor Único
Banco de Dados do Azure para PostgreSQL – Servidor Único
Importante
O Banco de Dados do Azure para PostgreSQL – Servidor Único está prestes a ser desativado. É altamente recomendável atualizar para o Banco de Dados do Azure para PostgreSQL – Servidor Flexível. Para obter mais informações sobre a migração para o Banco de Dados do Azure para PostgreSQL - Servidor Flexível, confira O que está acontecendo com o Banco de Dados do Azure para PostgreSQL Servidor Único?.
O serviço de Servidor único do Banco de Dados do Azure para PostgreSQL fornece um alto nível de disponibilidade garantido com o SLA (contrato de nível de serviço) com suporte financeiro para tempo de atividade. O Banco de Dados do Azure para PostgreSQL fornece alta disponibilidade durante eventos planejados, como a operação de computação dimensionada iniciada pelo usuário, e também quando ocorrem eventos não planejados, como falhas de rede, hardware ou software subjacentes. O Banco de Dados do Azure para PostgreSQL pode se recuperar rapidamente das circunstâncias mais críticas, garantindo praticamente nenhum tempo de inatividade do aplicativo ao usar esse serviço.
O BD do Azure para PostgreSQL é adequado para a execução de dados de missão crítica que exigem alto tempo de atividade. Baseado na arquitetura do Azure, o serviço tem recursos inerentes de alta disponibilidade, redundância e resiliência para reduzir o tempo de inatividade do banco de dados de interrupções planejadas e não planejadas, sem a necessidade de configurar outro componente adicional.
Componentes no Servidor único do Banco de Dados do Azure para PostgreSQL
| Componente | Descrição |
|---|---|
| Servidor de Banco de Dados PostgreSQL | O Banco de Dados do Azure para PostgreSQL fornece segurança, isolamento, proteções de recursos e capacidade de reinicialização rápida para servidores de banco de dados. Esses recursos facilitam operações como o dimensionamento e a operação de recuperação do servidor de banco de dados após ocorrer uma interrupção em segundos. Normalmente, as modificações nos servidores de dados ocorrem durante uma transação de um banco de dados. Todas as alterações de banco de dados são gravadas de forma síncrona na maneira de WAL (logs write-ahead) no Armazenamento do Microsoft Azure – que é anexado ao servidor de banco de dados. Durante o processo de ponto de verificação do banco de dados, as páginas de dados da memória do servidor de banco de dados também são liberadas para o armazenamento. |
| Armazenamento Remoto | Todos os arquivos de dados físicos do PostgreSQL e os arquivos WAL são armazenados no Armazenamento do Microsoft Azure, que é arquitetado para armazenar três cópias de dados em uma região para garantir a redundância, a disponibilidade e a confiabilidade dos dados. A camada de armazenamento também é independente do servidor de banco de dados. Ela pode ser desanexada de um servidor de banco de dados com falha e reanexada a um novo servidor de banco de dados em questão de segundos. Além disso, o Armazenamento do Microsoft Azure monitora continuamente as falhas de armazenamento. Se uma corrupção de bloco for detectada, ela será automaticamente corrigida instanciando uma nova cópia de armazenamento. |
| Gateway | O gateway atua como um proxy de banco de dados roteando todas as conexões de cliente para o servidor de banco de dados. |
Mitigação de tempo de inatividade planejada
O Banco de Dados do Azure para PostgreSQL é projetado para fornecer alta disponibilidade durante operações de tempo de inatividade planejadas.
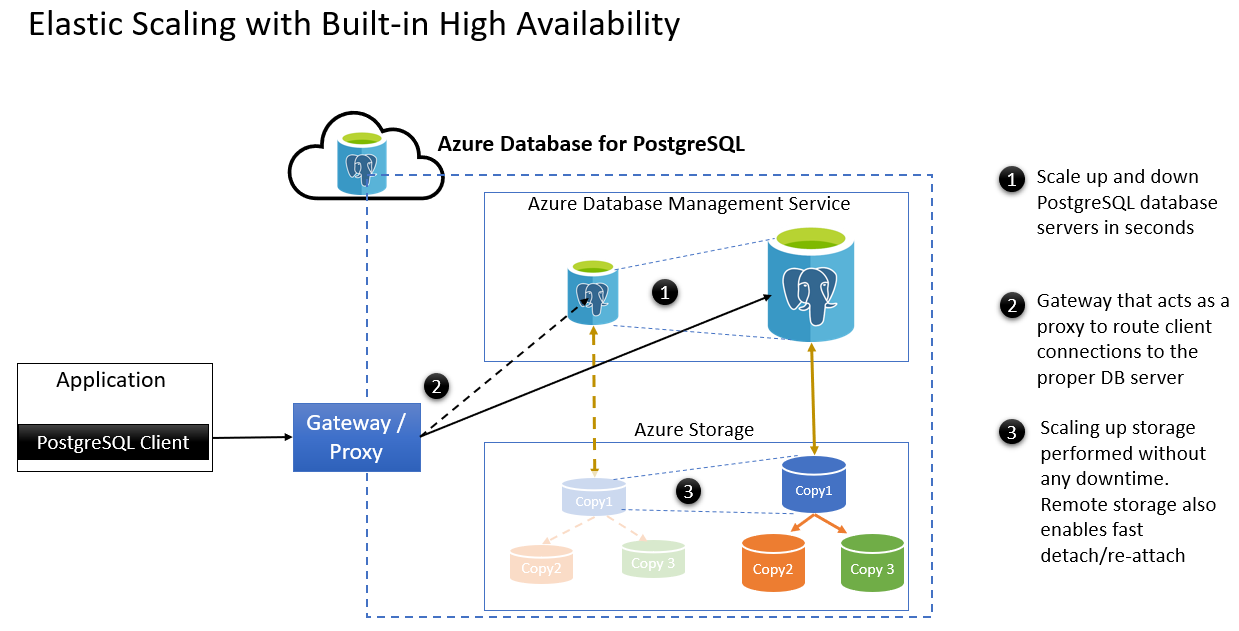
- Aumentar e reduzir os servidores de banco de dados do PostgreSQL em segundos.
- O gateway que atua como um proxy para rotear o cliente se conecta ao servidor de banco de dados apropriado.
- O aumento do armazenamento pode ser realizado sem nenhum tempo de inatividade. O armazenamento remoto permite desanexar/reanexar rapidamente após o failover. Estes são alguns cenários de manutenção planejada:
| Cenário | Descrição |
|---|---|
| Dimensionar/reduzir verticalmente a computação | Quando o usuário executa a operação de dimensionar/reduzir verticalmente, um novo servidor de banco de dados é provisionado usando a configuração de computação dimensionada. No servidor de banco de dados antigo, os pontos de verificação ativos têm permissão para serem concluídos, as conexões de cliente são descarregadas, todas as transações não confirmadas são canceladas e desligadas. Então, o armazenamento é desanexado do servidor de banco de dados antigo e anexado ao servidor de banco de dados novo. Quando o aplicativo cliente tenta se reconectar ou tenta fazer uma nova conexão, o gateway direciona a solicitação de conexão para o servidor de banco de dados novo. |
| Dimensionamento do armazenamento | Dimensionar o armazenamento é uma operação online e não interrompe o servidor de banco de dados. |
| Implantação de software novo (Azure) | Novos recursos de distribuição ou correções de bugs ocorrem automaticamente como parte da manutenção planejada do serviço. Para saber mais, confira a documentação e também verifique o portal. |
| Atualizações secundárias de versão | O Banco de Dados do Azure para PostgreSQL corrige automaticamente os servidores de banco de dados para a versão secundária determinada pelo Azure. Isso acontece como parte da manutenção planejada do serviço. Isso causará em alguns segundos de tempo de inatividade e o servidor de banco de dados será reiniciado automaticamente com a nova versão secundária. Para saber mais, confira a documentação e também verifique o portal. |
Mitigação de tempo de inatividade não planejada
O tempo de inatividade não planejado pode ocorrer como resultado de falhas imprevistas, incluindo falhas de hardware subjacentes, problemas de rede e bugs de software. Se o servidor de banco de dados ficar inativo inesperadamente, um novo servidor de banco de dados será provisionado automaticamente em segundos. O armazenamento remoto é anexado automaticamente ao novo servidor de banco de dados. O mecanismo do PostgreSQL executa a operação de recuperação usando WAL e arquivos de banco de dados abrindo o servidor de banco de dados para permitir que os clientes se conectem. As transações não confirmadas são perdidas e precisam ser repetidas pelo aplicativo. Embora não seja possível evitar um tempo de inatividade não planejado, o Banco de Dados do Azure para PostgreSQL reduz o tempo de inatividade realizando automaticamente operações de recuperação no servidor de banco de dados e nas camadas de armazenamento sem a necessidade de intervenção humana.
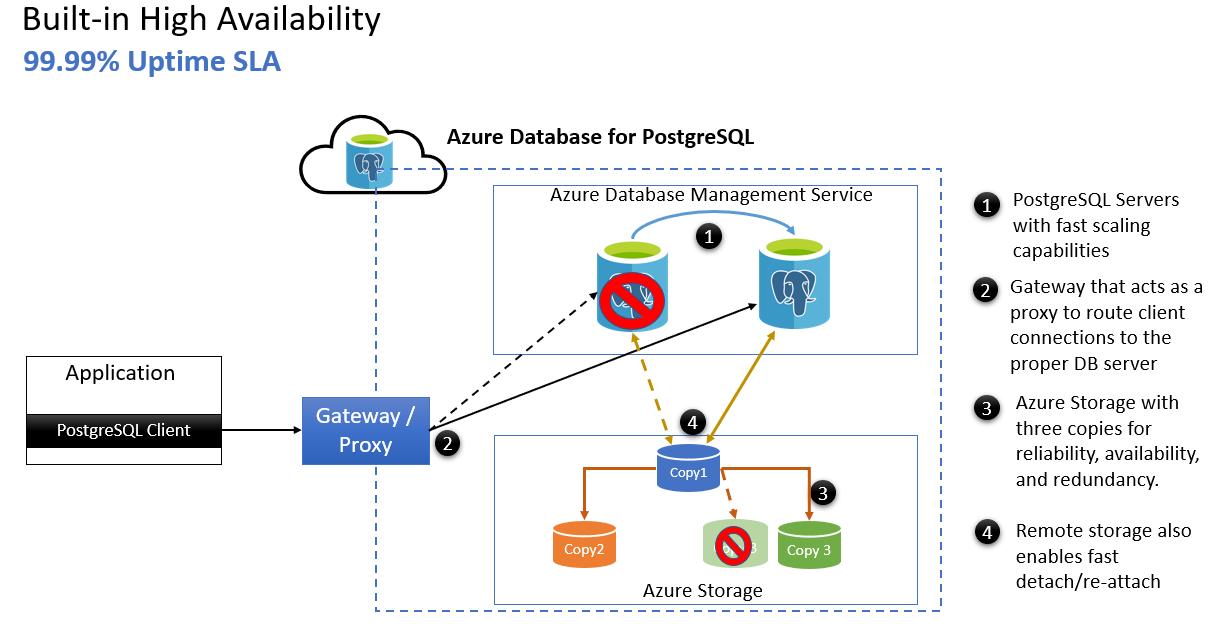
- Servidores PostgreSQL do Azure com recursos de dimensionamento rápido.
- O gateway que atua como um proxy para rotear as conexões do cliente para o servidor de banco de dados apropriado.
- Armazenamento do Azure com três cópias para confiabilidade, disponibilidade e redundância.
- O armazenamento remoto permite desanexar/reanexar rapidamente após o failover do servidor.
Tempo de inatividade não planejado: Cenários de falha e recuperação de serviço
Aqui estão alguns cenários de falha e como o Banco de Dados do Azure para PostgreSQL se recupera automaticamente:
| Cenário | Recuperação automática |
|---|---|
| Falha no servidor de banco de dados | Se o servidor de banco de dados estiver inoperante devido a alguma falha de hardware subjacente, as conexões ativas serão removidas e todas as transações em andamento serão anuladas. Um novo servidor de banco de dados é implantado automaticamente, e o armazenamento remoto é anexado ao novo servidor de banco de dado. Depois que a recuperação do banco de dados for concluída, os clientes podem se conectar ao novo servidor de banco de dados por meio do gateway. O RTO (tempo de recuperação) depende de vários fatores, incluindo a atividade no momento da falha, como transação grande e a quantidade de recuperação a ser executada durante o processo de inicialização do servidor de banco de dados. Os aplicativos que usam os bancos de dados do PostgreSQL precisam ser criados para detectar e repetir as conexões e transações que falharam. Quando o aplicativo repete a operação, o gateway redireciona a conexão de forma transparente para o servidor de banco de dados recém-criado. |
| Falha de armazenamento | Os aplicativos não detectam o impacto de problemas relacionados ao armazenamento, como uma falha de disco ou um dano a bloco físico. À medida que os dados são armazenados em três cópias, a cópia dos dados é atendida pelo armazenamento sobrevivente. As corrupções de bloco são corrigidas automaticamente. Se uma cópia dos dados for perdida, uma nova cópia dos dados será criada automaticamente. |
| Falha de computação | Falhas de computação são um evento raro. No caso de falha na computação, um novo contêiner de computação é provisionado e o armazenamento com arquivos de dados é mapeado para ele. O mecanismo de banco de dados PostgreSQL é então colocado online no novo contêiner e o serviço de gateway garante um failover transparente sem a necessidade de alterações no aplicativo. Observe também que a camada de computação tem resiliência interna da Zona de Disponibilidade e uma nova computação é criada em diferentes zonas de disponibilidade em caso de falha de computação do AZ. |
Aqui estão alguns cenários de falha que necessitam da ação do usuário para serem recuperados:
| Cenário | Plano de recuperação |
|---|---|
| Falha de região | A falha de uma região é um evento raro. No entanto, se precisar de proteção contra uma falha de região, você poderá configurar uma ou mais réplicas de leitura em outras regiões para DR (recuperação de desastre). (Para mais detalhes, confira este artigo, sobre como criar e gerenciar réplicas de leitura). No caso de uma falha em nível de região, você pode promover manualmente a réplica de leitura configurada na outra região para ser seu servidor de banco de dados de produção. |
| Falha na zona de disponibilidade | A falha de uma Zona de disponibilidade também é um evento raro. No entanto, se você precisar de proteção contra uma falha de Zona de disponibilidade, poderá configurar uma ou mais réplicas de leitura ou considerar usar nossa oferta de Servidor Flexível, que fornece alta disponibilidade com redundância de zona. |
| Erros de usuário/lógicos | A recuperação de erros do usuário, como tabelas removidas por acidente ou dados atualizados incorretamente, envolve a execução de uma PITR (recuperação pontual), que restaura e recupera os dados até o momento anterior da ocorrência do erro. Se você quiser restaurar apenas um subconjunto de bancos de dados ou tabelas específicas, em vez de todos os bancos de dados no servidor de banco de dados, poderá restaurar o servidor de banco de dados em uma nova instância, exportar as tabelas por meio de pg_dump e usar pg_restore para restaurar essas tabelas em seu banco de dados. |
Resumo
O Banco de Dados do Azure para PostgreSQL fornece recursos para reiniciar rapidamente servidores de banco de dados, armazenamento redundante e roteamento eficiente do gateway. Para proteção de dados adicional, você pode configurar os backups para serem replicados geograficamente e também implantar uma ou mais réplicas de leitura em outras regiões. Com os recursos inerentes de alta disponibilidade, o Banco de Dados do Azure para PostgreSQL protege seus bancos de dados contra as interrupções mais comuns e oferece um SLA de tempo de atividade, com suporte financeiro potencial do setor, de 99,99%. Todos esses recursos de disponibilidade e confiabilidade permitem que o Azure seja a plataforma ideal para executar aplicativos críticos.
Próximas etapas
- Saiba mais sobre Regiões do Azure
- Saiba mais sobre tratamento de erros de conectividade transitórios
- Saiba como replicar seus dados com réplicas de leitura