Clonagem de blocos em ReFS
A clonagem de blocos instrui o sistema de arquivos a copiar um intervalo de bytes do arquivo em nome de um aplicativo, onde o arquivo de destino pode ser igual ao ou diferente do arquivo de origem. As operações de cópia tradicionais, infelizmente, são caras, pois acionam leituras e gravações caras nos dados físicos subjacentes.
No entanto, a clonagem de blocos no ReFS executa cópias como uma operação de metadados de baixo custo, em vez de ler e gravar dados do arquivo. Como o ReFS permite que vários arquivos compartilhem os mesmo clusters lógicos (locais físicos em um volume), as operações de cópia só precisam remapear uma região de um arquivo para um local físico à parte, convertendo uma operação física cara em uma operação rápida e lógica. Isso permite que as cópias terminem mais rapidamente e gerem menos E/S para o armazenamento subjacente. Esse aprimoramento também beneficia as cargas de trabalho de virtualização, já que as operações de mesclagem de pontos de verificação do .vhdx são muito aceleradas quando são usadas operações de clonagem de blocos. Além disso, como vários arquivos podem compartilhar os mesmo clusters lógicos, os dados idênticos não são armazenados fisicamente várias vezes, melhorando a capacidade de armazenamento.
Como ele funciona
A clonagem de blocos do ReFS converte uma operação de dados de arquivo em uma operação de metadados. Para fazer essa otimização, o ReFS introduz contagens de referências em seus metadados para regiões copiadas. Essa contagem de referência registra o número de regiões distintas de arquivos referenciam as mesmas regiões físicas. Isso permite que vários arquivos compartilhem os mesmos dados físicos:
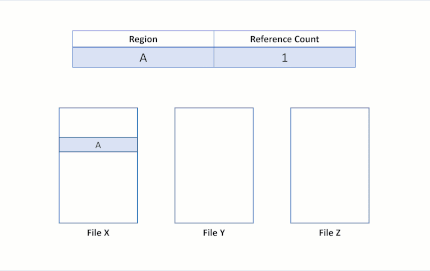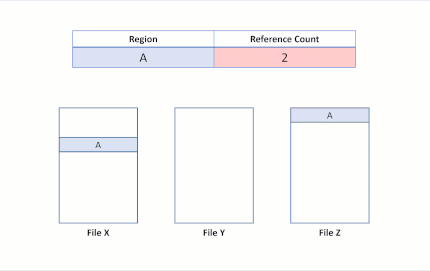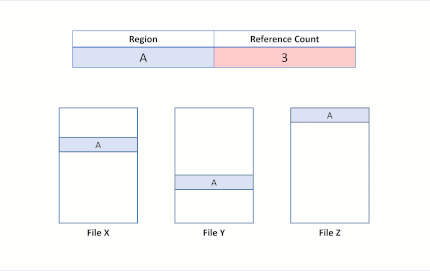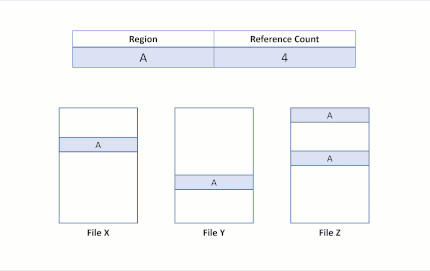
Ao manter uma contagem de referência para cada cluster lógico, o ReFS não interrompe o isolamento entre arquivos: as gravações em regiões compartilhadas disparam um mecanismo de alocação mediante gravação, onde o ReFS aloca uma nova região para a gravação de entrada. Esse mecanismo preserva a integridade dos clusters lógicos compartilhados.
Exemplo
Suponhamos que haja dois arquivos, X e Y, onde cada arquivo é composto por três regiões, e cada região é mapeada para clusters lógicos separados.
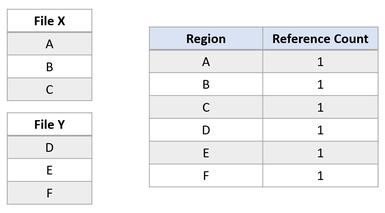
Agora, vamos supor que um aplicativo emita uma operação de clonagem de blocos do Arquivo X para o Arquivo Y, para as regiões A e B serem copiadas no deslocamento da região E. O estado do sistema de arquivo a seguir resultaria em:
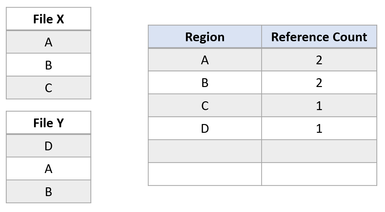
Esse estado do sistema de arquivo revela uma duplicação bem-sucedida da região do clone do bloco. Como o ReFS executa essa operação de cópia atualizando apenas os mapeamentos de VCN para LCN, nenhum dado físico foi lido, nem os dados físicos no Arquivo Y foram substituídos. Agora os arquivos X e Y compartilham clusters lógicos, refletidos pelas contagens de referência na tabela. Como nenhum dado foi copiado fisicamente, o ReFS reduz o consumo de capacidade no volume.
Agora, suponha que o aplicativo tente sobrescrever a região A no arquivo X. O ReFS duplica a região compartilhada, atualiza as contagens de referência corretamente e executa a gravação de entrada na região recém-duplicada. Isso garante que o isolamento entre os arquivos seja preservado.
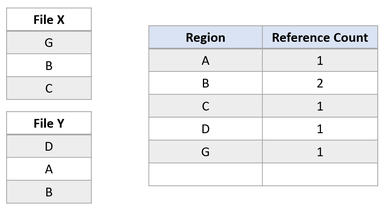
Após a gravação de modificação, a região B ainda é compartilhada pelos dois arquivos. Se a região A fosse maior que um cluster, somente o cluster modificado teria sido duplicado, e a parte restante continuaria compartilhada.
Restrições e comentários sobre a funcionalidade
- As regiões de origem e de destino devem começar e terminar em um limite de cluster.
- A região clonada deve ter menos de 4 GB.
- O número máximo de regiões de arquivo que podem ser mapeadas para a mesma região física é 8175.
- A região de destino não deve ultrapassar o final do arquivo. Se o aplicativo quiser estender o destino com dados clonados, ele deverá chamar SetEndOfFile primeiro.
- Se as regiões de origem e de destino estiverem no mesmo arquivo, elas não deverão se sobrepor. (O aplicativo poderá continuar dividindo a operação de clonagem de blocos em vários clones de blocos que não se sobrepõem mais.)
- Os arquivos de origem e de destino devem estar no mesmo volume do ReFS.
- Os arquivos de origem e de destino devem ter a mesma configuração de Fluxos de Integridade.
- Se o arquivo de origem for esparso, o arquivo de destino também deverá ser esparso.
- A operação de clonagem de blocos quebra os Shared Opportunistic Locks (também conhecidos como Level 2 Opportunistic Locks).
- O volume ReFS deve ter sido formatado com o Windows Server 2016 e, se o Clustering de failover estiver em uso, o nível funcional do clustering deverá ser o Windows Server 2016 ou posterior no momento da formatação.
- A partir das versões do Windows 11 24H2 e do Windows Server 2025, a clonagem de blocos ocorre de forma nativa nas operações de cópia compatíveis com o Windows.