Criar, exportar e pontuar modelos de machine learning do Spark nos Clusters de Big Data do SQL Server
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
O exemplo a seguir mostra como criar um modelo com ML do Spark, exportar o modelo para MLeap e pontuar o modelo no SQL Server com sua Extensão de Linguagem Java. Isso é feito no contexto de um cluster de Big Data do SQL Server.
O diagrama a seguir ilustra o trabalho executado neste exemplo:
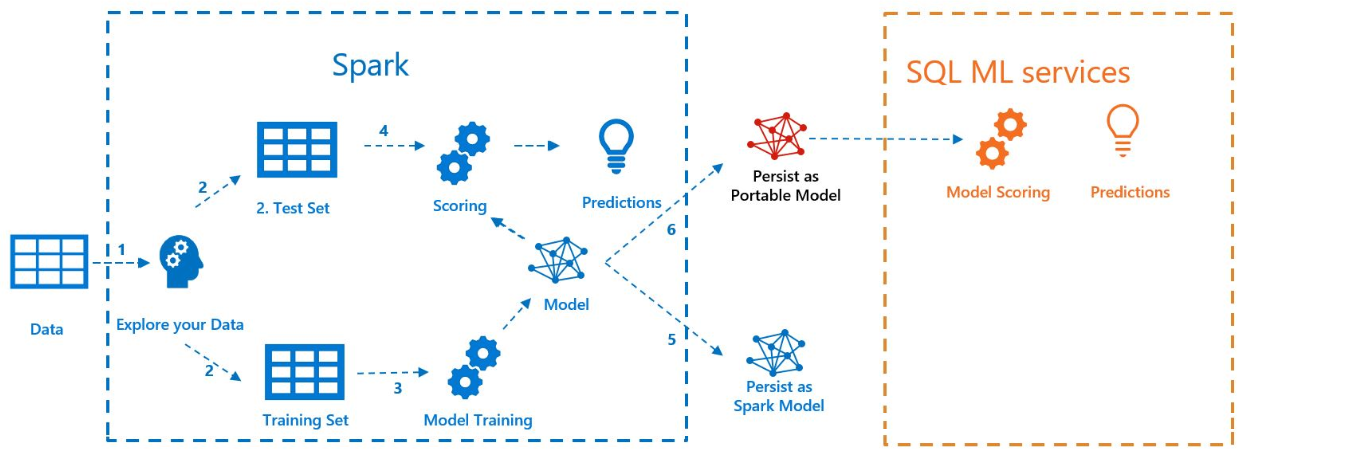
Pré-requisitos
Todos os arquivos deste exemplo ficam localizados em https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
Para executar o exemplo, você também precisa ter os seguintes pré-requisitos:
-
- kubectl
- curl
- Azure Data Studio
Treinamento de modelo com ML do Spark
Para este exemplo, dados de censo (AdultCensusIncome.csv) são usados para criar um modelo de pipeline de ML do Spark.
Use o arquivo mleap_sql_test/setup.sh para baixar o conjunto de dados da Internet e colocá-lo no HDFS em seu cluster de Big Data do SQL Server. Isso permite que ele seja acessado pelo Spark.
Em seguida, baixe o notebook de exemplo train_score_export_ml_models_with_spark. ipynb. Em uma linha de comando do PowerShell ou Bash, execute o seguinte comando para baixar o notebook de exemplo:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"Este notebook contém células com os comandos necessários para esta seção do exemplo.
Abra o notebook no Azure Data Studio e execute cada bloco de código. Para saber mais sobre como trabalhar com notebooks, confira Como usar notebooks com o SQL Server.
Os dados são lidos primeiro no Spark e são divididos em conjuntos de dados de treinamento e teste. Em seguida, o código treina um modelo de pipeline com os dados de treinamento. Por fim, ele exporta o modelo para um pacote MLeap.
Dica
Você também pode revisar ou executar o código Python associado a essas etapas fora do notebook no arquivo mleap_sql_test/mleap_pyspark. py.
Pontuação de modelo com o SQL Server
Agora que o modelo de pipeline de ML do Spark está em um formato de pacote MLeap de serialização comum, você pode pontuar o modelo no Java sem a presença do Spark.
Este exemplo usa a Extensão de Linguagem Java no SQL Server. Para pontuar o modelo no SQL Server, primeiro você precisa criar um aplicativo Java que possa carregar o modelo em Java e pontuá-lo. Você pode encontrar o código de exemplo para este aplicativo Java na pasta MSSQL-mleap-app.
Depois de criar o exemplo, você pode usar o Transact-SQL para chamar o aplicativo Java e pontuar o modelo com uma tabela de banco de dados. Isso pode ser visto no arquivo de origem mleap_sql_test/mleap_sql_tests.py.
Próximas etapas
Para obter mais informações sobre clusters de Big Data, confira Como implantar Clusters de Big Data do SQL Server no Kubernetes
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários