Obter posição facial com viseme
Observação
Para explorar as localidades com suporte para ID de visema e mesclar formas, confira a lista de todas as localidades com suporte. O SVG (Gráficos Vetoriais Escalonáveis) só dá suporte para a localidade en-US.
Um visema é a descrição visual de um fonema na linguagem falada. Ele define a posição do rosto e da boca enquanto uma pessoa está falando. Cada visema representa as principais poses faciais de um conjunto específico de fonemas.
Você pode usar visemas para controlar a movimentação de modelos de avatar 2D e 3D, para que as posições faciais fiquem melhor alinhadas com a fala sintética. Por exemplo, você pode:
- Criar um assistente de voz virtual animado para quiosques inteligentes, criando serviços integrados de vários modos para seus clientes.
- Criar transmissões de notícias imersivas e aprimorar as experiências do público-alvo com movimentos de rosto e bocas naturais.
- Gerar avatares de jogos mais interativos e personagens de desenho que podem falar com conteúdo dinâmico.
- Criar vídeos de ensino de idioma mais eficazes que ajudam os alunos de idiomas a entender o comportamento da boca em cada palavra e fonema.
- As pessoas com deficiência auditiva também podem captar sons visualmente e fazer a “leitura labial” de um conteúdo de fala que mostra visemas em um rosto animado.
Para obter mais informações sobre visemas, assista a este vídeo introdutório.
Fluxo de trabalho geral de produção de viseme com fala
A TTS neural (conversão de texto em fala neural) transforma um texto de entrada ou uma SSML (Speech Synthesis Markup Language) em uma voz sintetizada realista. A saída de áudio de fala pode ser acompanhada pela ID do viseme, SVG (Gráficos vetoriais escalonáveis) ou formas de combinação. Usando um mecanismo de renderização 2D ou 3D, você pode usar esses eventos de visema para animar o seu avatar.
O fluxo de trabalho geral do visema é descrito no seguinte fluxograma:
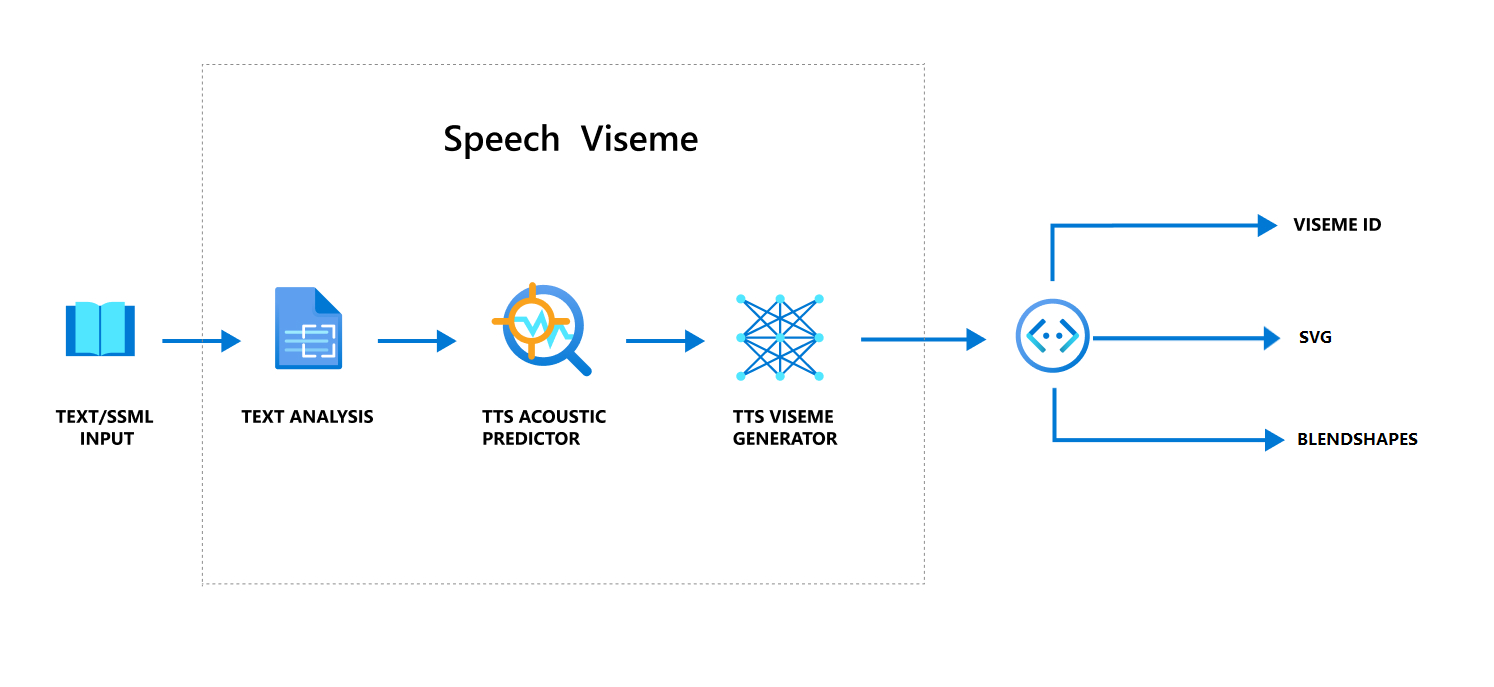
ID do visema
A ID do viseme refere-se a um número inteiro que especifica um viseme. Oferecemos 22 visemes diferentes, cada um ilustrando a posição da boca de um conjunto específico de fonemas. Não existe uma correspondência individual entre visemas e fonemas. Muitas vezes, vários fonemas correspondem a um único visema, porque eles pareciam iguais no rosto do falante quando são produzidos, como s e z. Para obter informações mais específicas, confira a tabela de mapeamento de fonemas para IDs de visema.
A saída de áudio de fala pode ser acompanhada pelas IDs de visema e Audio offset. O Audio offset indica o carimbo de data/hora de deslocamento que representa a hora de início de cada viseme, em tiques (100 nanossegundos).
Mapear fonemas a visemas
Os visemas mudam de acordo com o idioma e a localidade. Cada localidade tem um conjunto de visemas que corresponde aos fonemas específicos dela. A documentação de alfabetos fonéticos SSML mapeia as IDs de visema para os fonemas do IPA (Alfabeto Fonético Internacional) correspondentes. A tabela nesta seção mostra uma relação de mapeamento entre as IDs de visema e as posições da boca, listando fonemas IPA típicos para cada ID de visema.
| ID do visema | IPA | Posição da boca |
|---|---|---|
| 0 | Silêncio |  |
| 1 | æ, ə, ʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 4 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, i, ɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, tʃ, dʒ, ʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, t, n, θ |
 |
| 20 | k, g, ŋ |
 |
| 21 | p, b, m |
 |
Animação 2D SVG
Para personagens 2D, você pode criar um personagem que se adapte ao seu cenário e usar SVGs (Elementos Gráficos Vetoriais Escaláveis) para cada ID de visema a fim de obter uma posição facial baseada em tempo.
Com marcas temporais fornecidas em um evento de visema, esses SVGs bem projetados são processados com modificações de suavização e fornecem animação robusta aos usuários. Por exemplo, a ilustração a seguir mostra uma personagem com lábios vermelhos projetada para aprendizado de idioma.

Animação de formas de combinação 3D
Use formas de combinação para conduzir os movimentos faciais de um caractere 3D que você projetou.
A cadeia de caracteres JSON de formas de combinação é representada como uma matriz bidimensional. Cada linha representa um quadro. Cada quadro (em 60 FPS) contém uma matriz de 55 posições faciais.
Obter eventos de visema com o SDK de Fala
Para obter o visema com a voz sintetizada, assine o evento VisemeReceived no SDK de Fala.
Observação
Para solicitar a saída de formas SVG ou blend, você deve usar o elemento mstts:viseme no SSML. Para obter detalhes, confira como usar o elemento viseme no SSML.
Os seguintes snippets de código mostram como assinar o evento de visema:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Aqui está um exemplo da saída do visema.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
Depois de obter a saída do visema, use esses eventos para fazer a animação de personagens. Você pode criar seus personagens e animá-los automaticamente.
Próximas etapas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de