Desenvolver pacotes de regras de informações confidenciais no Exchange 2013
Aplica-se a: Exchange Server 2013
O esquema XML e as diretrizes neste tópico ajudarão você a começar a criar seus próprios arquivos XML de DLP (prevenção de perda de dados) básicos que definem seus próprios tipos de informações confidenciais em um pacote de regras de classificação. Depois de criar um arquivo XML bem formado, você pode importá-lo usando o centro de administração do Exchange ou o shell de gerenciamento do Exchange para ajudar a criar uma solução DLP Microsoft Exchange Server 2013. Um arquivo XML que é um modelo de política DLP personalizado pode conter o XML que é o pacote de regras de classificação. Para obter uma visão geral sobre como definir seus próprios modelos DLP como arquivos XML, consulte Definir seus próprios modelos DLP e tipos de informações.
Visão geral do processo de criação de regra
O processo de criação de regra é composto pelas seguintes etapas gerais.
Prepare um conjunto de documentos de teste representativos de seu ambiente de destino. As principais características a serem consideradas para o conjunto de documentos de teste incluem: um subconjunto dos documentos contém a entidade ou afinidade para a qual a regra está sendo criada, e um subconjunto dos documentos não contém a entidade ou afinidade para a qual a regra está sendo criada.
Identifique as regras que atendem aos requisitos de aceitação (precisão e recall) para identificar o conteúdo qualificado. Esse esforço de identificação pode exigir o desenvolvimento de várias condições dentro de uma regra, associadas à lógica booliana, que, juntas, atendem aos requisitos mínimos de correspondência para identificar documentos de destino.
Estabeleça o nível de confiança recomendado para as regras com base nos requisitos de aceitação (precisão e recall). O elemento de confiança recomendado pode ser considerado como o nível de confiança padrão para a regra.
Valide as regras instanciando uma política com elas e monitorando o conteúdo do teste de exemplo. Com base nos resultados, ajuste as regras ou o nível de confiança para maximizar o conteúdo detectado, minimizando falsos positivos e negativos. Continue o ciclo de validação e ajustes de regra até que um nível satisfatório de detecção de conteúdo seja atingido para amostras positivas e negativas.
Para obter informações sobre a definição de esquema XML para arquivos de modelo de política, consulte Desenvolvendo arquivos de modelo de política DLP.
Descrição da regra
Dois tipos de regra main podem ser criados para o mecanismo de detecção de informações confidenciais do DLP: Entidade e Afinidade. O tipo de regra escolhido baseia-se no tipo de lógica de processamento que deve ser aplicada ao processamento do conteúdo, conforme descrito nas seções anteriores. As definições de regra são configuradas em um documento XML no formato descrito pelo XSD de regras padronizadas. As regras descrevem o tipo de conteúdo a ser correspondido e o nível de confiança que a correspondência descrita representa o conteúdo de destino. O nível de confiança especifica a probabilidade de a Entidade estar presente se um Padrão for encontrado no conteúdo ou a probabilidade de a Affinity estar presente se a Evidência for encontrada no conteúdo.
Estrutura básica de regras
A definição regra é construída a partir de três componentes main:
Entidade define a lógica de correspondência e contagem para essa regra
A afinidade define a lógica correspondente para a regra
Localização de Cadeias de Caracteres localizadas para nomes de regras e suas descrições
Outros três elementos de suporte são usados que definem os detalhes do processamento e referenciados nos componentes main: Palavra-chave, Regex e Função. Usando referências, uma única definição dos elementos de suporte, como um número de segurança social, pode ser usada em várias regras de Entidade ou Afinidade. A estrutura de regra básica no formato XML pode ser vista da seguinte maneira.
<?xml version="1.0" encoding="utf-8"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id="DAD86A92-AB18-43BB-AB35-96F7C594ADAA">
<Version major="1" minor="0" build="0" revision="0"/>
<Publisher id="619DD8C3-7B80-4998-A312-4DF0402BAC04"/>
<Details defaultLangCode="en-us">
<LocalizedDetails langcode="en-us">
<PublisherName>DLP by EPG</PublisherName>
<Name>CSO Custom Rule Pack</Name>
<Description>This is a rule package for a EPG demo.</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
<!-- Employee ID -->
<Entity id="E1CC861E-3FE9-4A58-82DF-4BD259EAB378" patternsProximity="300" recommendedConfidence="75">
<Pattern confidenceLevel="75">
<IdMatch idRef="Regex_employee_id" />
<Match idRef="Keyword_employee" />
</Pattern>
</Entity>
<Regex id="Regex_employee_id">(\s)(\d{9})(\s)</Regex>
<Keyword id="Keyword_employee">
<Group matchStyle="word">
<Term>Identification</Term>
<Term>Contoso Employee</Term>
</Group>
</Keyword>
<LocalizedStrings>
<Resource idRef="E1CC861E-3FE9-4A58-82DF-4BD259EAB378">
<Name default="true" langcode="en-us">
Employee ID
</Name>
<Description default="true" langcode="en-us">
A custom classification for detecting Employee ID's
</Description>
</Resource>
</LocalizedStrings>
</Rules>
</RulePackage>
Regras de entidade
As Regras de Entidade são direcionadas para identificadores bem definidos, como Número de Segurança Social, e são representadas por uma coleção de padrões incontáveis. Regras de Entidade retorna uma contagem e o nível de confiança de uma correspondência, em que Contagem é o número total de instâncias da entidade encontrada e o Nível de Confiança é a probabilidade de que a entidade determinada exista no documento fornecido. A entidade contém o atributo "Id" como seu identificador exclusivo. O identificador é usado para localização, versão e consulta. A ID da Entidade deve ser um GUID. A ID da Entidade não deve ser duplicada em outras entidades ou afinidades. Ele é referenciado na seção cadeias de caracteres localizadas.
As regras de entidade contêm padrões opcionais Atributoproximity (padrão = 300) que é usado ao aplicar a lógica booliana para especificar a adjacência de vários padrões necessários para atender à condição de correspondência. O elemento entidade contém um ou mais elementos padrão filho, em que cada padrão é uma representação distinta da Entidade, como Entidade de Cartão de Crédito ou Entidade de Carteira de Motorista. O elemento Pattern tem um atributo obrigatório de confiançaLevel que representa a precisão do padrão com base no conjunto de dados de exemplo. O elemento Padrão pode ter três elementos filho:
IdMatch – Esse elemento é necessário.
Match
Qualquer
Se algum dos elementos Pattern retornar "true", o Padrão será satisfeito. A contagem para o elemento Entity é igual à soma de todas as contagens de padrões detectadas.

em que k é o número de elementos Pattern para a Entidade.
Um elemento Pattern deve ter exatamente um elemento IdMatch. O IdMatch representa o identificador que o Padrão deve corresponder, por exemplo, um número de cartão de crédito ou um número ITIN. A Contagem para um padrão é o número de IdMatches correspondentes ao elemento Pattern. O elemento IdMatch ancora a janela de proximidade dos elementos Match.
Outro subelemento opcional do elemento Pattern é o elemento Match que representa evidências corroborativas necessárias para serem correspondidas para dar suporte à localização do elemento IdMatch. Por exemplo, a regra de maior confiança pode exigir que, além de encontrar um número de cartão de crédito, existam artefatos extras no documento, dentro de uma janela de proximidade do cartão de crédito, como endereço e nome. Esses artefatos extras seriam representados por meio do elemento Match ou qualquer elemento (descrito em detalhes na seção Métodos e Técnicas Correspondentes). Vários elementos match podem ser incluídos em uma definição de Padrão, que pode ser incluída diretamente no elemento Pattern ou combinada usando o elemento Any para definir a semântica correspondente. Ele retornará true se uma correspondência for encontrada na janela de proximidade ancorada ao redor do conteúdo IdMatch.
Os elementos IdMatch e Match não definem os detalhes de qual conteúdo precisa ser correspondido, mas, em vez disso, referenciam-no por meio do atributo idRef. Essa referência promove a reutilização de definições em vários builds de padrão.
<Entity id="..." patternsProximity="300" >
<Pattern confidenceLevel="85">
<IdMatch idRef="FormattedSSN" />
<Any minMatches="1">
<Match idRef="SSNKeyword" />
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
<Pattern confidenceLevel="65">
<IdMatch idRef="UnformattedSSN" />
<Match idRef="SSNKeyword" />
<Any minMatches="1">
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
</Entity>
O elemento ID da Entidade, representado no XML anterior por "..." deve ser um GUID e é referenciado na seção Cadeias de Caracteres Localizadas.
Janela de proximidade do padrão de entidade
A entidade contém padrões opcionais Valor do atributoProximity (inteiro, padrão = 300) usado para localizar os Padrões. Para cada padrão, o valor do atributo define a distância (em caracteres Unicode) do local IdMatch para todas as outras Correspondências especificadas para esse Padrão. A janela de proximidade é ancorada pelo local IdMatch, com a janela se estendendo para a esquerda e para a direita do IdMatch.

O exemplo a seguir ilustra como a janela de proximidade afeta o algoritmo correspondente em que o elemento IdMatch do SSN requer pelo menos um endereço, nome ou data que corrobora correspondências. Apenas SSN1 e SSN4 correspondem porque para SSN2 e SSN3, nenhuma ou apenas evidência de corroboração parcial é encontrada dentro da janela de proximidade.

O corpo da mensagem e cada anexo são tratados como itens independentes. Essa condição significa que a janela de proximidade não se estende além do final de cada um desses itens. Para cada item (anexo ou corpo), a evidência idMatch e corroborativa precisa residir dentro de cada um deles.
Nível de confiança da entidade
O nível de confiança do elemento Entity é a combinação de todos os níveis de confiança do Padrão satisfeito. Eles são combinados usando a seguinte equação:

em que k é o número de elementos Pattern para a Entidade e um Padrão que não corresponde retorna um nível de confiança de 0.
Referindo-se ao exemplo de exemplo de código de estrutura de elemento de entidade, se ambos os padrões forem correspondidos, o nível de confiança da entidade será de 94,75% com base no seguinte cálculo:
Entidade CL = 1-[(1-CL Pattern1) x (1-CLPattern1)]
= 1-[(1-0,85) x (1-0,65)]
= 1-(0,15 x 0,35)
= 94,75%
Da mesma forma, se apenas o segundo padrão corresponder, o nível de confiança da Entidade será de 65% com base no seguinte cálculo:
Entidade CL = 1 - [(1 - CL Pattern1) X (1 -CL Pattern1)]
= 1 - [(1 - 0) X (1 - 0,65)]
= 1 – (1 X 0,35)
= 65%
Esses valores de confiança são atribuídos nas regras para padrões individuais com base no conjunto de documentos de teste validados como parte do processo de criação de regra.
Regras de afinidade
As regras de afinidade são direcionadas para conteúdo sem identificadores bem definidos, por exemplo, Sarbanes-Oxley ou conteúdo financeiro corporativo. Para esse conteúdo, nenhum identificador consistente pode ser encontrado e, em vez disso, a análise requer determinar se uma coleção de evidências está presente. As regras de afinidade não retornam uma contagem, em vez disso, retornam se encontradas e o nível de confiança associado. O conteúdo de afinidade é representado como uma coleção de evidências independentes. Evidência é uma agregação de correspondências necessárias dentro de uma certa proximidade. Para a regra Affinity, a proximidade é definida pelo atributo evidencesProximity (padrão é 600) e pelo nível mínimo de confiança pelo atributo thresholdConfidenceLevel.
As regras de afinidade contêm o atributo Id para seu identificador exclusivo que é usado para localização, versão e consulta. Ao contrário das regras de entidade, como as regras de afinidade não dependem de identificadores bem definidos, elas não contêm o elemento IdMatch.
Cada regra affinity contém um ou mais elementos de Evidência filho que definem as evidências que devem ser encontradas e o nível de confiança que contribui para a regra affinity. A afinidade não é considerada encontrada se o nível de confiança resultante estiver abaixo do nível de limite. Cada Evidência representa logicamente evidências corroborativas para esse "tipo" de documento e o atributo confidenceLevel é a precisão para essa Evidência no conjunto de dados de teste.
Os elementos de evidência têm um ou mais elementos Match ou Any child. Se todos os elementos Child Match e Any corresponderem, a Evidência será encontrada e o nível de confiança será contribuído para o cálculo do nível de confiança das regras. A mesma descrição se aplica às regras Match ou Any para Affinity como para regras de entidade.
<Affinity id="..."
evidencesProximity="1000"
thresholdConfidenceLevel="65">
<Evidence confidenceLevel="40">
<Any>
<Match idRef="AssetsTerms" />
<Match idRef="BalanceSheetTerms" />
<Match idRef="ProfitAndLossTerms" />
</Any>
</Evidence>
<Evidence confidenceLevel="40">
<Any minMatches="2">
<Match idRef="TaxTerms" />
<Match idRef="DollarAmountTerms" />
<Match idRef="SECTerms" />
<Match idRef="SECFilingFormTerms" />
<Match idRef="DollarTotalRegex" />
</Any>
</Evidence>
</Affinity>
Janela de proximidade de afinidade
A janela de proximidade da Affinity é calculada de forma diferente dos padrões de entidade. A proximidade de afinidade segue um modelo de janela deslizante. O algoritmo de proximidade de afinidade tenta encontrar o número máximo de evidências correspondentes na janela determinada. As evidências na janela de proximidade devem ter um nível de confiança maior do que o limite definido para que a regra Affinity seja encontrada.

Nível de confiança de afinidade
O nível de confiança da Affinity é igual à combinação de Evidências encontradas na janela de proximidade da regra Affinity. Embora semelhante ao nível de confiança da regra Entity, a principal diferença é a aplicação da janela de proximidade. Semelhante às regras de entidade, o nível de confiança do elemento Affinity é a combinação de todos os níveis de confiança de Evidência satisfeitos, mas para a regra Affinity, ele representa apenas a maior combinação de elementos Evidence encontrados na janela de proximidade. Os níveis de confiança de evidência são combinados usando a seguinte equação:

em que k é o número de elementos Evidence para a Afinidade correspondida dentro da janela de proximidade.
Referindo-se à estrutura de regras de Afinidade de Exemplo da Figura 4, se todas as três evidências forem correspondidas dentro da janela deslizante de proximidade, o nível de confiança de afinidade será de 85,6% com base no cálculo abaixo. Esse valor excede o limite de regra affinity de 65, o que resulta na correspondência da regra.
Cl Affinity = 1 - [(1 - Cl Evidence 1) X (1 -CL Evidence 2) X (1 -CL Evidence 2)]
= 1 - [(1 - 0,6) X (1 a 0,4) X (1 - 0,4)]
= 1 – (0,4 X 0,6 X 0,6)
= 85,6%
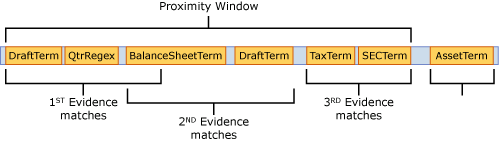
Usando a mesma definição de regra de exemplo, se apenas a primeira evidência corresponder porque a segunda Evidência está fora da janela de proximidade, o nível de confiança de afinidade mais alto é 60% com base no cálculo abaixo e a regra Affinity não corresponde, pois o limite de 65 não foi atendido.
Cl Affinity = 1 - [(1 - Cl Evidence 1) X (1 -CL Evidence 2) X (1 -CL Evidence 2)]
= 1 - [(1 - 0,6) X (1 a 0) X (1 - 0) ]
= 1 – (0,4 X 1 X 1)
= 60%

Ajustando níveis de confiança
Um dos principais aspectos do processo de criação de regra é o ajuste dos níveis de confiança para regras de entidade e afinidade. Depois de criar as definições de regra, execute a regra em relação ao conteúdo representativo e colete os dados de precisão. Compare os resultados retornados para cada padrão ou evidência com os resultados esperados para os documentos de teste.

Se as regras atenderem aos requisitos de aceitação, ou seja, o Padrão ou Evidência tiver uma taxa de confiança acima de um limite estabelecido (por exemplo, 75%), a expressão de correspondência será concluída e poderá ser movida para a próxima etapa.
Se o Padrão ou Evidência não atender ao nível de confiança, reautorize-o (por exemplo, adicione evidências mais corroborativas; remova ou adicione padrões/evidências extras; etc.) e repita esta etapa.
Em seguida, ajuste o nível de confiança para cada Padrão ou Evidência em suas regras com base nos resultados da etapa anterior. Para cada Padrão ou Evidência, adicione o número de True Positives (TP), subconjunto dos documentos que contêm a entidade ou afinidade para a qual a regra está sendo criada e que resultou em uma correspondência e o número de False Positives (FP), um subconjunto de documentos que não contêm a entidade ou afinidade para a qual a regra está sendo criada e que também retornou uma correspondência. Defina o nível de confiança para cada Padrão/Evidência usando o seguinte cálculo:
Nível de confiança = True Positives / (True Positives + False Positives)
| Padrão ou Evidência | Verdadeiros Positivos | False Positives | Nível de confiança |
|---|---|---|---|
| P1ou E1 | 4 | 1 | 80% |
| P2ou E2 | 2 | 2 | 50% |
| Pnou En | 9 | 10 | 47% |
Usando idiomas locais em seu arquivo XML
O esquema de regra dá suporte ao armazenamento de nome e descrição localizados para cada um dos elementos Entity e Affinity. Cada elemento Entity e Affinity deve conter um elemento correspondente na seção LocalizedStrings. Para localizar cada elemento, inclua um elemento Resource como filho do elemento LocalizedStrings para armazenar nome e descrições para várias localidades para cada elemento. O elemento Resource inclui um atributo idRef necessário que corresponde ao atributo idRef correspondente para cada elemento que está sendo localizado. Os elementos filho Locale do elemento Resource contêm o nome localizado e as descrições para cada localidade especificada.
<LocalizedStrings>
<Resource idRef="guid">
<Locale langcode="en-US" default="true">
<Name>affinity name en-us</Name>
<Description>
affinity description en-us
</Description>
</Locale>
<Locale langcode="de">
<Name>affinity name de</Name>
<Description>
affinity description de
</Description>
</Locale>
</Resource>
</LocalizedStrings>
Definição de esquema XML do pacote de regras de classificação
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:mce="http://schemas.microsoft.com/office/2011/mce"
targetNamespace="http://schemas.microsoft.com/office/2011/mce"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
attributeFormDefault="unqualified"
id="RulePackageSchema">
<xs:simpleType name="LangType">
<xs:union memberTypes="xs:language">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value=""/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="GuidType" final="#all">
<xs:restriction base="xs:token">
<xs:pattern value="[0-9a-fA-F]{8}\-([0-9a-fA-F]{4}\-){3}[0-9a-fA-F]{12}"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulePackageType">
<xs:sequence>
<xs:element name="RulePack" type="mce:RulePackType"/>
<xs:element name="Rules" type="mce:RulesType">
<xs:key name="UniqueRuleId">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueProcessorId">
<xs:selector xpath="mce:Regex|mce:Keyword"></xs:selector>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueResourceIdRef">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:key>
<xs:keyref name="ReferencedRuleMustExist" refer="mce:UniqueRuleId">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:keyref>
<xs:keyref name="RuleMustHaveResource" refer="mce:UniqueResourceIdRef">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:keyref>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RulePackType">
<xs:sequence>
<xs:element name="Version" type="mce:VersionType"/>
<xs:element name="Publisher" type="mce:PublisherType"/>
<xs:element name="Details" type="mce:DetailsType">
<xs:key name="UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="mce:LocalizedDetails"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:keyref name="DefaultLangCodeMustExist" refer="mce:UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="."/>
<xs:field xpath="@defaultLangCode"/>
</xs:keyref>
</xs:element>
<xs:element name="Encryption" type="mce:EncryptionType" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="VersionType">
<xs:attribute name="major" type="xs:unsignedShort" use="required"/>
<xs:attribute name="minor" type="xs:unsignedShort" use="required"/>
<xs:attribute name="build" type="xs:unsignedShort" use="required"/>
<xs:attribute name="revision" type="xs:unsignedShort" use="required"/>
</xs:complexType>
<xs:complexType name="PublisherType">
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="LocalizedDetailsType">
<xs:sequence>
<xs:element name="PublisherName" type="mce:NameType"/>
<xs:element name="Name" type="mce:RulePackNameType"/>
<xs:element name="Description" type="mce:OptionalNameType"/>
</xs:sequence>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="DetailsType">
<xs:sequence>
<xs:element name="LocalizedDetails" type="mce:LocalizedDetailsType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="defaultLangCode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="EncryptionType">
<xs:sequence>
<xs:element name="Key" type="xs:normalizedString"/>
<xs:element name="IV" type="xs:normalizedString"/>
</xs:sequence>
</xs:complexType>
<xs:simpleType name="RulePackNameType">
<xs:restriction base="xs:token">
<xs:minLength value="1"/>
<xs:maxLength value="64"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="1"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="OptionalNameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="0"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="RestrictedTermType">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="512"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulesType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
</xs:choice>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Regex" type="mce:RegexType"/>
<xs:element name="Keyword" type="mce:KeywordType"/>
</xs:choice>
<xs:element name="LocalizedStrings" type="mce:LocalizedStringsType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="EntityType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="patternsProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="recommendedConfidence" type="mce:ProbabilityType"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="PatternType">
<xs:sequence>
<xs:element name="IdMatch" type="mce:IdMatchType"/>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="AffinityType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="evidencesProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="thresholdConfidenceLevel" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="EvidenceType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="IdMatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="MatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="AnyType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="minMatches" type="xs:nonNegativeInteger" default="1"/>
<xs:attribute name="maxMatches" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>
<xs:simpleType name="ProximityType">
<xs:restriction base="xs:positiveInteger">
<xs:minInclusive value="1"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="ProbabilityType">
<xs:restriction base="xs:integer">
<xs:minInclusive value="1"/>
<xs:maxInclusive value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="WorkloadType">
<xs:restriction base="xs:string">
<xs:enumeration value="Exchange"/>
<xs:enumeration value="Outlook"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RegexType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="KeywordType">
<xs:sequence>
<xs:element name="Group" type="mce:GroupType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:complexType>
<xs:complexType name="GroupType">
<xs:sequence>
<xs:choice>
<xs:element name="Term" type="mce:TermType" maxOccurs="unbounded"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="matchStyle" default="word">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="word"/>
<xs:enumeration value="string"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="TermType">
<xs:simpleContent>
<xs:extension base="mce:RestrictedTermType">
<xs:attribute name="caseSensitive" type="xs:boolean" default="false"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="LocalizedStringsType">
<xs:sequence>
<xs:element name="Resource" type="mce:ResourceType" maxOccurs="unbounded">
<xs:key name="UniqueLangCodeUsedInNamePerResource">
<xs:selector xpath="mce:Name"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:key name="UniqueLangCodeUsedInDescriptionPerResource">
<xs:selector xpath="mce:Description"/>
<xs:field xpath="@langcode"/>
</xs:key>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="ResourceType">
<xs:sequence>
<xs:element name="Name" type="mce:ResourceNameType" maxOccurs="unbounded"/>
<xs:element name="Description" type="mce:DescriptionType" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="idRef" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="ResourceNameType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="DescriptionType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>