Opções de armazenamento de dados (criando aplicativos de nuvem Real-World com o Azure)
por Rick Anderson, Tom Dykstra
Baixar o Projeto de Correção ou Baixar E-book
O livro eletrônico Criando Aplicativos de Nuvem do Mundo Real com o Azure é baseado em uma apresentação desenvolvida por Scott Guthrie. Ele explica 13 padrões e práticas que podem ajudá-lo a desenvolver aplicativos Web para a nuvem com êxito. Para obter informações sobre o livro eletrônico, consulte o primeiro capítulo.
A maioria das pessoas está acostumada com bancos de dados relacionais e tendem a ignorar outras opções de armazenamento de dados ao criar um aplicativo de nuvem. O resultado pode ser desempenho abaixo do ideal, despesas altas ou pior, pois os bancos de dados NoSQL (não relacionais) podem lidar com algumas tarefas com mais eficiência do que os bancos de dados relacionais. Quando os clientes nos pedem ajuda para resolver um problema crítico de armazenamento de dados, geralmente é porque eles têm um banco de dados relacional em que uma das opções noSQL teria funcionado melhor. Nessas situações, o cliente estaria melhor se tivesse implementado a solução NoSQL antes de implantar o aplicativo em produção.
Por outro lado, também seria um erro assumir que um banco de dados NoSQL pode fazer tudo bem ou bem o suficiente. Não há uma única melhor opção de gerenciamento de dados para todas as tarefas de armazenamento de dados; diferentes soluções de gerenciamento de dados são otimizadas para tarefas diferentes. A maioria dos aplicativos de nuvem do mundo real tem uma variedade de requisitos de armazenamento de dados e geralmente são atendidos melhor por uma combinação de várias soluções de armazenamento de dados.
A finalidade deste capítulo é fornecer uma noção mais ampla das opções de armazenamento de dados disponíveis para um aplicativo de nuvem e algumas diretrizes básicas sobre como escolher as que se encaixam em seu cenário. É melhor estar ciente das opções disponíveis para você e pensar em seus pontos fortes e fracos antes de desenvolver um aplicativo. Alterar as opções de armazenamento de dados em um aplicativo de produção pode ser extremamente difícil, como ter que alterar um motor a jato enquanto o avião está em voo.
Opções de armazenamento de dados no Azure
A nuvem torna relativamente fácil usar uma variedade de armazenamentos de dados relacionais e NoSQL. Aqui estão algumas das plataformas de armazenamento de dados que você pode usar no Azure.
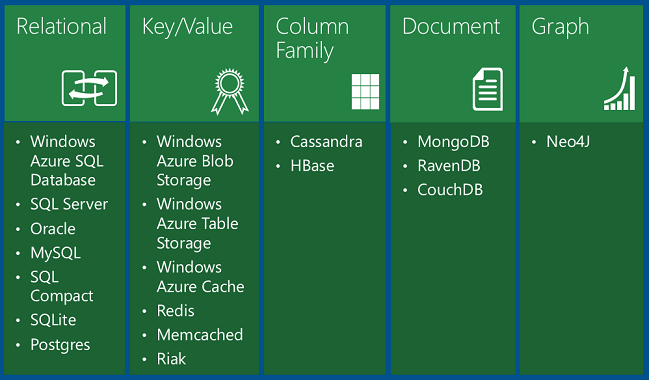
A tabela mostra quatro tipos de bancos de dados NoSQL:
Os bancos de dados chave/valor armazenam um único objeto serializado para cada valor de chave. Eles são bons para armazenar grandes volumes de dados, quando você deseja obter um item para determinado valor de chave e não precisa consultar com base em outras propriedades do item.
O Armazenamento de Blobs do Azure é um banco de dados de chave/valor que funciona como armazenamento de arquivos na nuvem, com valores de chave que correspondem a nomes de pasta e arquivo. Você recupera um arquivo por sua pasta e nome de arquivo, não pesquisando valores no conteúdo do arquivo.
O Armazenamento de Tabelas do Azure também é um banco de dados de chave/valor. Cada valor é chamado de entidade (semelhante a uma linha, identificada por uma chave de partição e chave de linha) e contém várias propriedades (semelhantes a colunas, mas nem todas as entidades em uma tabela precisam compartilhar as mesmas colunas). A consulta em colunas diferentes da chave é extremamente ineficiente e deve ser evitada. Por exemplo, você pode armazenar dados de perfil de usuário, com uma partição armazenando informações sobre um único usuário. Você pode armazenar dados como nome de usuário, hash de senha, data de nascimento e assim por diante, em propriedades separadas de uma entidade ou em entidades separadas na mesma partição. Mas você não deseja consultar todos os usuários com um determinado intervalo de datas de nascimento e não pode executar uma consulta de junção entre sua tabela de perfil e outra tabela. O armazenamento de tabelas é mais escalonável e menos caro do que um banco de dados relacional, mas não permite consultas ou junções complexas.
Documentdatabases são bancos de dados chave/valor nos quais os valores são documentos. "Documento" aqui não é usado no sentido de um documento Word ou do Excel, mas significa uma coleção de campos e valores nomeados, qualquer um dos quais poderia ser um documento filho. Por exemplo, em uma tabela de histórico de pedidos, um documento de pedido pode ter o número do pedido, a data do pedido e os campos do cliente; e o campo do cliente pode ter campos de nome e endereço. O banco de dados codifica dados de campo em um formato como XML, YAML, JSON ou BSON; ou pode usar texto sem formatação. Um recurso que define bancos de dados de documentos além dos bancos de dados de chave/valor é a capacidade de consultar em campos não chave e definir índices secundários para tornar a consulta mais eficiente. Essa capacidade torna um banco de dados de documento mais adequado para aplicativos que precisam recuperar dados com base em critérios mais complexos do que o valor da chave do documento. Por exemplo, em um banco de dados de documento de histórico de pedidos de vendas, você pode consultar em vários campos, como ID do produto, ID do cliente, nome do cliente e assim por diante. O MongoDB é um banco de dados de documento popular.
Os bancos de dados da família de colunas são armazenamentos de dados chave/valor que permitem estruturar o armazenamento de dados em coleções de colunas relacionadas chamadas famílias de colunas. Por exemplo, um banco de dados censitário pode ter um grupo de colunas para o nome de uma pessoa (primeiro, meio, último), um grupo para o endereço da pessoa e um grupo para as informações de perfil da pessoa (DOB, gênero etc.). Em seguida, o banco de dados pode armazenar cada família de colunas em uma partição separada, mantendo todos os dados de uma pessoa relacionada à mesma chave. Em seguida, você pode ler todas as informações de perfil sem precisar ler todas as informações de nome e endereço também. Cassandra é um banco de dados popular da família de colunas.
Os bancos de dados do Graph armazenam informações como uma coleção de objetos e relações. A finalidade de um banco de dados de grafo é habilitar um aplicativo para executar com eficiência consultas que atravessam a rede de objetos e as relações entre eles. Por exemplo, os objetos podem ser funcionários em um banco de dados de recursos humanos e talvez você queira facilitar consultas como "localizar todos os funcionários que trabalham direta ou indiretamente para Scott". Neo4j é um banco de dados de grafo popular.
Em comparação com bancos de dados relacionais, as opções noSQL oferecem escalabilidade e custo-benefício muito maiores para armazenamento e análise de dados não estruturados. A compensação é que eles não fornecem a consulta avançada e os recursos robustos de integridade de dados de bancos de dados relacionais. O NoSQL funcionaria bem para dados de log do IIS, o que envolve alto volume sem necessidade de consultas de junção. O NoSQL não funcionaria tão bem para transações bancárias, o que requer integridade absoluta de dados e envolve muitas relações com outros dados relacionados à conta.
Há também uma categoria mais recente de plataforma de banco de dados chamada NewSQL que combina a escalabilidade de um banco de dados NoSQL com a consulta e a integridade transacional de um banco de dados relacional. Os bancos de dados NewSQL são projetados para armazenamento distribuído e processamento de consultas, o que geralmente é difícil de implementar em bancos de dados "OldSQL". O NuoDB é um exemplo de um banco de dados NewSQL que pode ser usado no Azure.
Hadoop e MapReduce
Os grandes volumes de dados que você pode armazenar em bancos de dados NoSQL podem ser difíceis de analisar com eficiência em tempo hábil. Para fazer isso, você pode usar uma estrutura como o Hadoop , que implementa a funcionalidade MapReduce . Essencialmente, o que um processo MapReduce faz é o seguinte:
- Limite o tamanho dos dados que precisam ser processados selecionando fora do armazenamento de dados apenas os dados que você realmente precisa analisar. Por exemplo, você deseja saber a composição da sua base de usuários até o ano de nascimento, portanto, selecione apenas anos de nascimento fora do seu armazenamento de dados de perfil de usuário.
- Divida os dados em partes e envie-os para computadores diferentes para processamento. O computador A calcula o número de pessoas com datas de 1950-1959, o computador B faz 1960-1969 etc. Esse grupo de computadores é chamado de cluster Hadoop.
- Reúna os resultados de cada parte depois que o processamento nas partes for feito. Agora você tem uma lista relativamente curta de quantas pessoas para cada ano de nascimento e a tarefa de calcular percentuais nesta lista geral é gerenciável.
No Azure, o HDInsight permite processar, analisar e obter novos insights de Big Data usando o poder do Hadoop. Por exemplo, você pode usá-lo para analisar os logs do servidor Web:
Habilite o log do servidor Web em sua conta de armazenamento. Isso configura o Azure para gravar logs no Serviço blob para cada solicitação HTTP em seu aplicativo. O Serviço blob é basicamente armazenamento de arquivos na nuvem e integra-se bem ao HDInsight.
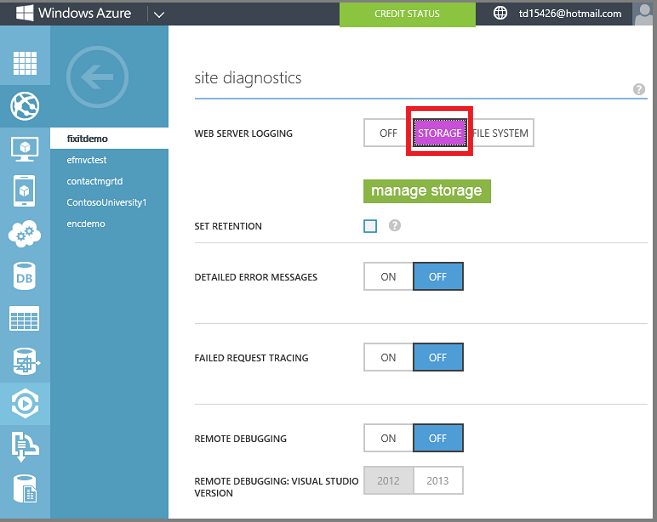
À medida que o aplicativo obtém tráfego, os logs do IIS do servidor Web são gravados no Armazenamento de Blobs.
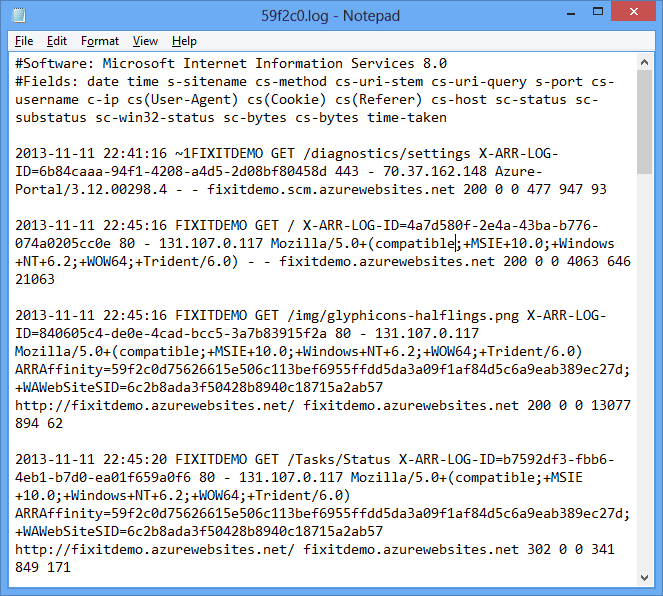
No portal, clique em Nova - Criação Rápida doHDInsight - dosServiços - de Dados e especifique um nome de cluster HDInsight, tamanho do cluster (número de nós de dados do cluster HDInsight) e um nome de usuário e senha para o cluster HDInsight.
Agora você pode configurar trabalhos do MapReduce para analisar seus logs e obter respostas para perguntas como:
- Quais horas do dia meu aplicativo obtém mais ou menos tráfego?
- De quais países meu tráfego vem?
- Qual é a renda média do bairro das áreas de onde meu tráfego vem. (Há um conjunto de dados público que fornece a você a renda do bairro por endereço IP e você pode fazer a correspondência com o endereço IP nos logs do servidor Web.)
- Como a renda do bairro se correlaciona com páginas ou produtos específicos no site?
Em seguida, você pode usar as respostas para perguntas como essas para direcionar anúncios com base na probabilidade de um cliente estar interessado ou provavelmente comprar um produto específico.
Conforme explicado no capítulo Automatizar Tudo, a maioria das funções que você pode fazer no portal pode ser automatizada e isso inclui configurar e executar trabalhos de análise do HDInsight. Um script HDInsight típico pode conter as seguintes etapas:
- Provisione um cluster HDInsight e vincule-o à sua conta de armazenamento para entrada de Armazenamento de Blobs.
- Carregue os executáveis do trabalho MapReduce (arquivos .jar ou .exe) no cluster HDInsight.
- Envie um MapReduce que armazena os dados de saída para o Armazenamento de Blobs.
- Aguarde a conclusão do trabalho.
- Excluir o cluster do HDInsight.
- Acesse a saída do Armazenamento de Blobs.
Ao executar um script que faz tudo isso, você minimiza a quantidade de tempo que o cluster HDInsight é provisionado, o que minimiza seus custos.
PaaS (plataforma como serviço) versus IaaS (infraestrutura como serviço)
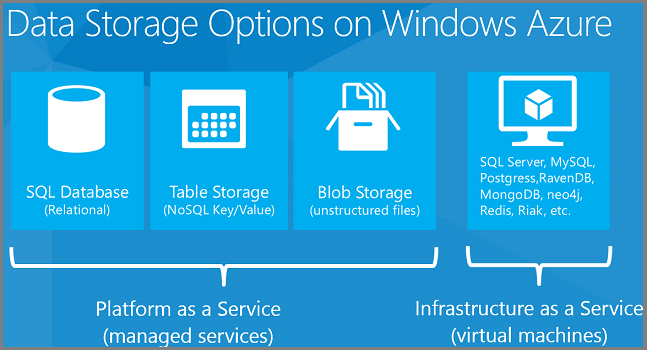
As opções de armazenamento de dados listadas anteriormente incluem soluções de PaaS (Plataforma como Serviço) e IaaS (Infraestrutura como Serviço). PaaS significa que gerenciamos a infraestrutura de hardware e software e você apenas usa o serviço. Banco de Dados SQL é um recurso de PaaS do Azure. Você solicita bancos de dados e, nos bastidores, o Azure configura e configura as VMs e configura os bancos de dados neles. Você não tem acesso direto às VMs e não precisa gerenciá-las. IaaS significa que você configura, configura e gerencia VMs que são executadas em nossa infraestrutura de data center e você coloca o que quiser nelas. Fornecemos uma galeria de imagens de VM pré-configuradas para configurações comuns de VM. Por exemplo, você pode instalar imagens de VM pré-configuradas para o Windows Server 2008, Windows Server 2012, BizTalk Server, Oracle WebLogic Server, Oracle Database etc.
As soluções de dados de PaaS que o Azure oferece incluem:
- banco de dados SQL do Azure (anteriormente conhecido como SQL Azure). Um banco de dados relacional de nuvem baseado em SQL Server.
- Armazenamento de Tabelas do Azure. Um banco de dados NoSQL de chave/valor.
- Armazenamento de Blobs do Azure. Armazenamento de arquivos na nuvem.
Para IaaS, você pode executar qualquer coisa que possa carregar em uma VM, por exemplo:
- Bancos de dados relacionais como SQL Server, Oracle, MySQL, SQL Compact, SQLite ou Postgres.
- Armazenamentos de dados de chave/valor, como Memcached, Redis, Cassandra e Riak.
- Armazenamentos de dados de coluna, como HBase.
- Documente bancos de dados como MongoDB, RavenDB e CouchDB.
- Bancos de dados do Graph, como Neo4j.
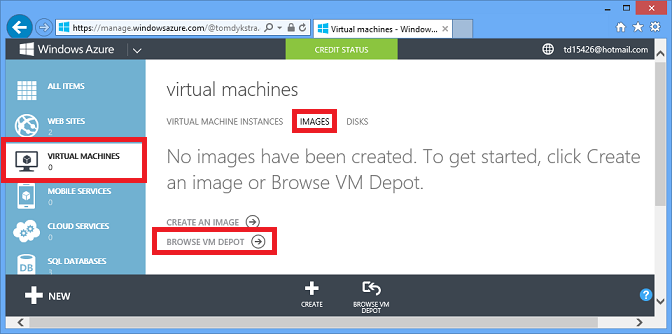
A opção IaaS oferece opções de armazenamento de dados quase ilimitadas, e muitas delas são especialmente fáceis de usar porque você pode criar VMs usando imagens pré-configuradas. Por exemplo, no portal de gerenciamento, vá para Máquinas Virtuais, clique na guia Imagens e clique em Procurar Depósito de VMs.
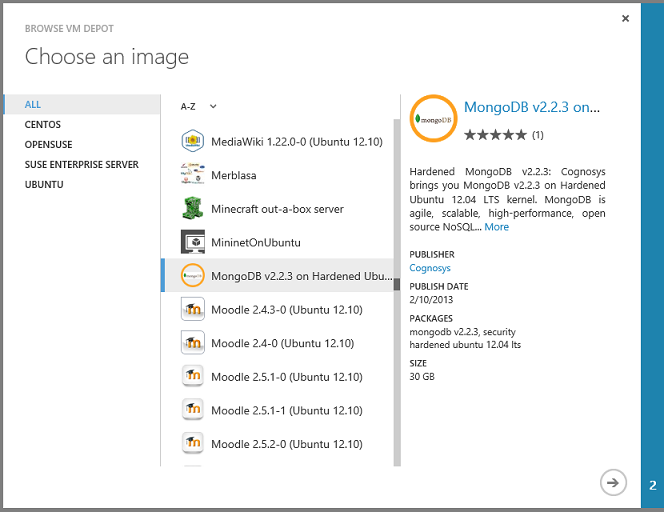
Em seguida, você vê uma lista de centenas de imagens de VM pré-configuradas e pode criar uma VM com base em uma imagem que tenha um sistema de gerenciamento de banco de dados pré-instalado, como MongoDB, Neo4J, Redis, Cassandra ou CouchDB:
O Azure torna as opções de armazenamento de dados de IaaS o mais fáceis de usar, mas as ofertas de PaaS têm muitas vantagens que as tornam mais econômicas e práticas para muitos cenários:
- Você não precisa criar VMs, basta usar o portal ou um script para configurar um armazenamento de dados. Se você quiser um armazenamento de dados de 200 terabyte, basta clicar em um botão ou executar um comando e, em segundos, ele estará pronto para uso.
- Você não precisa gerenciar ou corrigir as VMs usadas pelo serviço; A Microsoft faz isso para você automaticamente.- Você não precisa se preocupar em configurar a infraestrutura para dimensionamento ou alta disponibilidade; A Microsoft lida com tudo isso para você.
- Você não precisa comprar licenças; as taxas de licença são incluídas nas taxas de serviço.
- Você paga apenas pelo que usa.
As opções de armazenamento de dados de PaaS no Azure incluem ofertas de provedores de terceiros.
Escolhendo uma opção de armazenamento de dados
Nenhuma abordagem é certa para todos os cenários. Se alguém diz que essa tecnologia é a resposta, a primeira coisa a fazer é "Qual é a pergunta?", porque soluções diferentes são otimizadas para coisas diferentes. Há vantagens definitivas para o modelo relacional; É por isso que ele está por perto há tanto tempo. Mas também há lados inferiores ao SQL que podem ser abordados com uma solução NoSQL.
Muitas vezes, o que vemos melhor é uma abordagem de composição, em que você usa SQL e NoSQL em uma única solução. Mesmo quando as pessoas dizem que estão abraçando o NoSQL, se você detalhar o que elas estão fazendo, muitas vezes você descobre que elas estão usando várias estruturas diferentes do NoSQL: elas estão usando CouchDB, Redis e Riak para coisas diferentes. Até mesmo o Facebook, que usa o NoSQL extensivamente, usa diferentes estruturas NoSQL para diferentes partes do serviço. A flexibilidade para misturar e corresponder às abordagens de armazenamento de dados é uma das coisas que são boas na nuvem, pois é fácil usar várias soluções de dados e integrá-las em um único aplicativo.
Aqui estão algumas perguntas sobre as quais você está escolhendo uma abordagem:
| Semântica de dados | - O que é a semântica de armazenamento de dados e acesso a dados principais (você está armazenando dados relacionais ou não estruturados)? Dados não estruturados, como arquivos de mídia, se encaixam melhor no armazenamento de blobs; uma coleção de dados relacionados, como produtos, inventários, fornecedores, pedidos de clientes etc., se encaixa melhor em um banco de dados relacional. |
|---|---|
| Suporte à consulta | - Qual é a facilidade de consultar os dados? - Quais tipos de perguntas podem ser feitas com eficiência? Os armazenamentos de dados de chave/valor são muito bons em obter uma única linha com um valor de chave, mas não tão bons para consultas complexas. Para um armazenamento de dados de perfil de usuário em que você está sempre obtendo os dados de um usuário específico, um armazenamento de dados de chave/valor pode funcionar bem; para um catálogo de produtos em que você deseja obter agrupamentos diferentes com base em vários atributos de produto, um banco de dados relacional pode funcionar melhor. Os bancos de dados NoSQL podem armazenar grandes volumes de dados com eficiência, mas você precisa estruturar o banco de dados em torno de como o aplicativo consulta os dados e isso torna as consultas ad hoc mais difíceis de fazer. Com um banco de dados relacional, você pode criar quase qualquer tipo de consulta. |
| Projeção funcional | – Perguntas, agregações etc., podem ser executadas no lado do servidor? Se eu executar SELECT COUNT(*) em uma tabela no SQL, ele fará todo o trabalho no servidor com muita eficiência e retornará o número que estou procurando. Se eu quiser o mesmo cálculo de um armazenamento de dados NoSQL que não dá suporte à agregação, essa é uma "consulta não associado" ineficiente e provavelmente atingirá o tempo limite. Mesmo que a consulta seja bem-sucedida, tenho que recuperar todos os dados do servidor para o cliente e contar as linhas no cliente. - Quais idiomas ou tipos de expressões podem ser usados? Com um banco de dados relacional, posso usar o SQL. Com alguns bancos de dados NoSQL, como o Armazenamento de Tabelas do Azure, usarei o OData e tudo o que posso fazer é filtrar a chave primária e obter projeções (selecione um subconjunto dos campos disponíveis). |
| Facilidade de escalabilidade | - Com que frequência e quanto os dados precisarão dimensionar? - A plataforma implementa a expansão nativamente? - Qual é a facilidade de adicionar/remover capacidade (tamanho e taxa de transferência)? Bancos de dados relacionais e tabelas não são particionados automaticamente para torná-los escalonáveis, portanto, são difíceis de dimensionar além de determinadas limitações. Os armazenamentos de dados NoSQL, como o Armazenamento de Tabelas do Azure, particionam tudo inerentemente e quase não há limite para adicionar partições. Você pode dimensionar prontamente o Armazenamento de Tabelas até 200 terabytes, mas o tamanho máximo do banco de dados para SQL do Azure Banco de Dados é de 500 gigabytes. Você pode dimensionar dados relacionais particionando-os em vários bancos de dados, mas configurar um aplicativo para dar suporte a esse modelo envolve muito trabalho de programação. |
| Instrumentação e capacidade de gerenciamento | - Quão fácil é a plataforma de instrumentar, monitorar e gerenciar? Você precisará se manter informado sobre a integridade e o desempenho do seu armazenamento de dados, portanto, precisa saber antecipadamente quais métricas uma plataforma oferece gratuitamente e o que você tem para se desenvolver. |
| Operations | - Qual é a facilidade de implantar e executar a plataforma no Azure? Paas? Iaas? Linux? O Armazenamento de Tabelas e Banco de Dados SQL são fáceis de configurar no Azure. As plataformas que não são soluções internas de PaaS do Azure exigem mais esforço. |
| Suporte a API | - Há uma API disponível que facilita o trabalho com a plataforma? Para o Serviço de Tabela do Azure, há um SDK com uma API do .NET que dá suporte ao modelo de programação assíncrona do .NET 4.5. Se você estiver escrevendo um aplicativo .NET, será muito mais fácil escrever e testar código para o Serviço de Tabela do Azure em comparação com outra plataforma de armazenamento de dados de coluna de chave/valor que não tenha nenhuma API ou uma menos abrangente. |
| Integridade transacional e consistência de dados | – É fundamental que a plataforma dê suporte a transações para garantir a consistência dos dados? Para acompanhar emails em massa enviados, o desempenho e o baixo custo de armazenamento de dados podem ser mais importantes do que o suporte automático para transações ou integridade referencial na plataforma de dados, tornando o Serviço de Tabela do Azure uma boa opção. Para acompanhar saldos de contas bancárias ou ordens de compra, uma plataforma de banco de dados relacional que fornece garantias transacionais fortes seria uma opção melhor. |
| Continuidade de negócios | - Qual é a facilidade de backup, restauração e recuperação de desastres? Mais cedo ou mais tarde, os dados de produção serão corrompidos e você precisará de uma função desfazer. Os bancos de dados relacionais geralmente têm recursos de restauração mais refinados, como a capacidade de restaurar para um ponto no tempo. Entender quais recursos de restauração estão disponíveis em cada plataforma que você está considerando é um fator importante a ser considerado. |
| Cost | - Se mais de uma plataforma puder dar suporte à carga de trabalho de dados, como eles se comparam em custo? Por exemplo, se você usar ASP.NET Identity, poderá armazenar dados de perfil de usuário no Serviço de Tabela do Azure ou no Banco de Dados SQL do Azure. Se você não precisar das instalações de consulta avançadas de Banco de Dados SQL, poderá escolher Tabelas do Azure em parte porque custa muito menos para uma determinada quantidade de armazenamento. |
O que geralmente recomendamos é saber a resposta para as perguntas em cada uma dessas categorias antes de escolher suas soluções de armazenamento de dados.
Além disso, sua carga de trabalho pode ter requisitos específicos que algumas plataformas podem oferecer suporte melhor do que outras. Por exemplo:
- Seu aplicativo requer recursos de auditoria?
- Quais são seus requisitos de longevidade de dados: você precisa de recursos automatizados de arquivamento ou limpeza?
- Você tem necessidades de segurança especializadas? Por exemplo, os dados incluem PII (informações de identificação pessoal), mas você precisa ser capaz de garantir que a PII seja excluída dos resultados da consulta.
- Se você tiver alguns dados que não podem ser armazenados na nuvem por motivos regulatórios ou tecnológicos, talvez seja necessário uma plataforma de armazenamento de dados de nuvem que facilite a integração com seu armazenamento local.
Demonstração – usando Banco de Dados SQL no Azure
O aplicativo Fix It usa um banco de dados relacional para armazenar tarefas. A criação do ambiente Windows PowerShell script mostrado no capítulo Automatizar Tudo cria duas instâncias Banco de Dados SQL. Você pode vê-los no portal clicando na guia Bancos de Dados SQL .
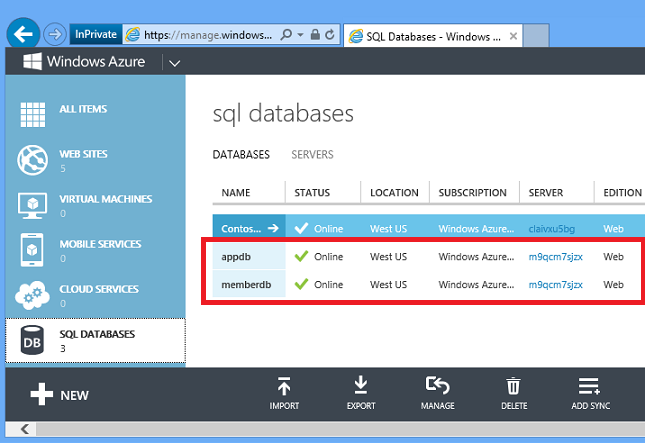
Também é fácil criar bancos de dados usando o portal.
Clique em Novo – Serviços -- de Dados Banco de Dados SQL -- Criação Rápida, insira um nome de banco de dados, escolha um servidor que você já tenha em sua conta ou crie um novo e clique em Criar Banco de Dados SQL.
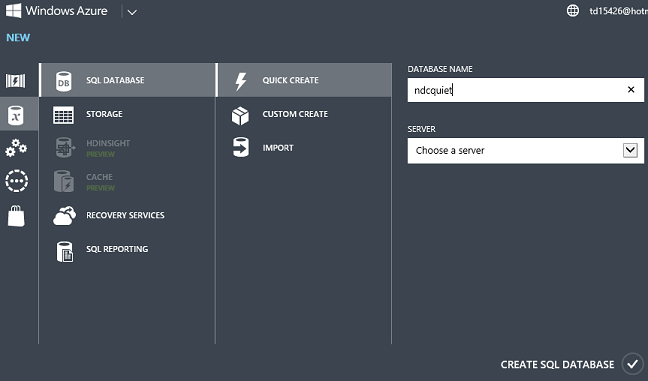
Aguarde vários segundos e você tem um banco de dados no Azure pronto para uso.
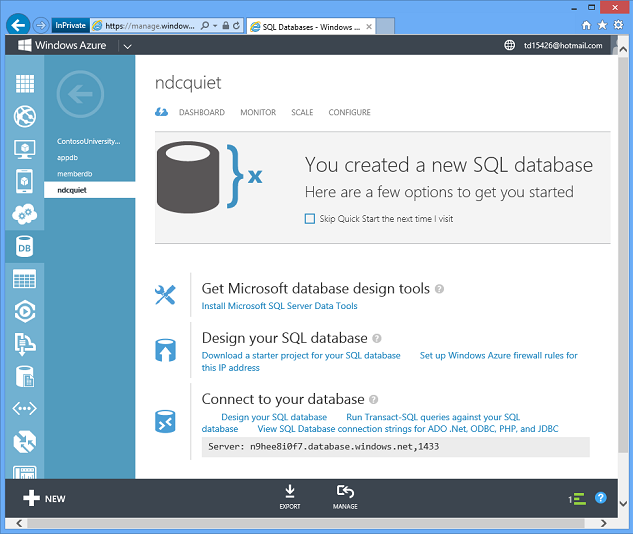
Portanto, o Azure faz em alguns segundos o que pode levar um dia ou uma semana ou mais para ser feito no ambiente local. E como você pode facilmente criar bancos de dados automaticamente em um script ou usando uma API de gerenciamento, você pode escalar horizontalmente dinamicamente espalhando seus dados em vários bancos de dados, desde que seu aplicativo tenha sido programado para isso.
Este é um exemplo de nosso modelo plataforma como serviço. Você não precisa gerenciar os servidores, nós fazemos isso. Você não precisa se preocupar com backups, nós fazemos isso. Ele está em execução em alta disponibilidade – os dados no banco de dados são replicados em três servidores automaticamente. Se um computador morrer, faremos failover automaticamente e você não perderá nenhum dado. O servidor é corrigido regularmente, você não precisa se preocupar com isso.
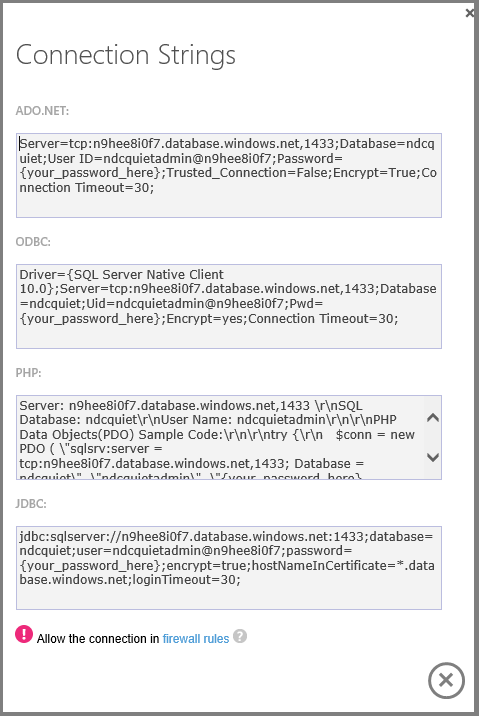
Clique em um botão e você obtém a cadeia de conexão exata necessária e pode começar imediatamente a usar o novo banco de dados.
O Painel mostra o histórico de conexões e a quantidade de armazenamento usada.
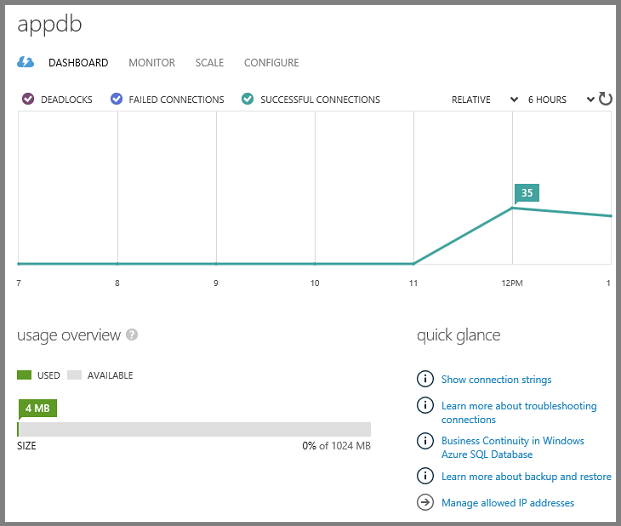
Você pode gerenciar bancos de dados no portal ou usando SQL Server ferramentas com as quais já está familiarizado, incluindo SQL Server Management Studio (SSMS) e as ferramentas do Visual Studio SQL Server Pesquisador de Objetos (SSOX) e o Explorer de Servidor.
Outra coisa boa é o modelo de preços. Você pode iniciar o desenvolvimento com um banco de dados gratuito de 20 MB e um banco de dados de produção começa em cerca de US$ 5 por mês. Você paga apenas pela quantidade de dados que realmente armazena no banco de dados, não pela capacidade máxima. Você não precisa comprar uma licença.
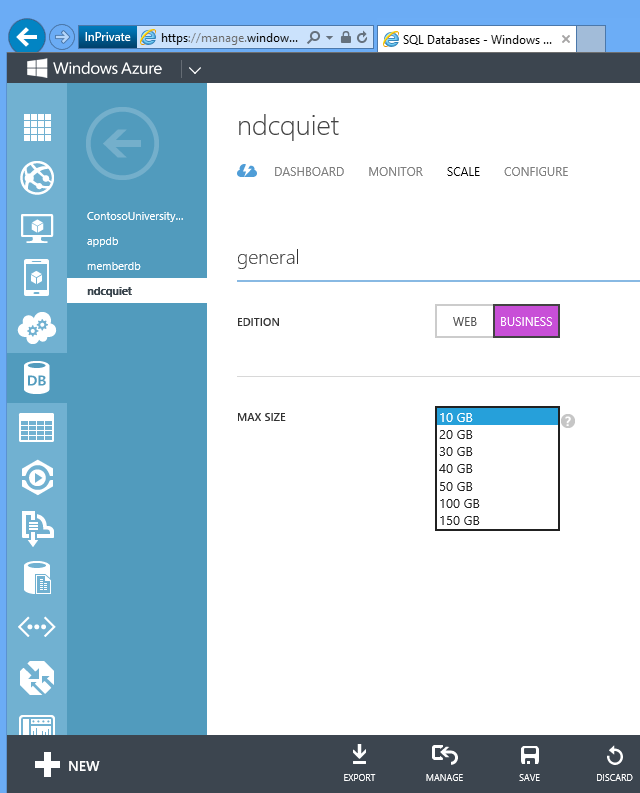
Banco de Dados SQL é fácil de dimensionar. Para o aplicativo Corrigir, o banco de dados que criamos em nosso script de automação é limitado a 1 gig. Se você quiser dimensioná-lo para até 150 gig, basta acessar o portal e alterar essa configuração ou executar um comando da API REST e, em segundos, você tem um banco de dados de 150 giges no qual pode implantar dados.
Esse é o poder da nuvem de manter a infraestrutura de forma rápida e fácil e começar a usá-la imediatamente.
O aplicativo Fix It usa dois bancos de dados SQL, um para associação (autenticação e autorização) e outro para dados, e isso é tudo o que você precisa fazer para provisioná-los e dimensioná-los. Você viu anteriormente como provisionar os bancos de dados por meio de scripts Windows PowerShell e agora também viu como é fácil fazer no portal.
Entity Framework versus acesso direto ao banco de dados usando ADO.NET
O aplicativo Fix It acessa esses bancos de dados usando o Entity Framework, o ORM (mapeador relacional de objeto) recomendado pela Microsoft para aplicativos .NET. Um ORM é uma ótima ferramenta que facilita a produtividade do desenvolvedor, mas a produtividade vem em detrimento do desempenho degradado em alguns cenários. Em um aplicativo de nuvem do mundo real, você não fará uma escolha entre usar o EF ou usar ADO.NET diretamente. Você usará ambos. Na maioria das vezes, quando você está escrevendo código que funciona com o banco de dados, obter o desempenho máximo não é crítico e você pode aproveitar a codificação simplificada e os testes obtidos com o Entity Framework. Em situações em que a sobrecarga de EF causaria um desempenho inaceitável, você pode escrever e executar suas próprias consultas usando ADO.NET, idealmente chamando procedimentos armazenados.
Seja qual for o método usado para acessar o banco de dados, você deseja minimizar a "conversação" o máximo possível. Em outras palavras, se você conseguir obter todos os dados necessários em um conjunto de resultados de consulta maior em vez de dezenas ou centenas de menores, isso geralmente é preferível. Por exemplo, se você precisar listar os alunos e os cursos nos quais eles estão inscritos, geralmente é melhor obter todos os dados em uma consulta de junção em vez de colocar os alunos em uma consulta e executar consultas separadas para os cursos de cada aluno.
Bancos de dados SQL e o Entity Framework no aplicativo Corrigir
No aplicativo Corrigir, a FixItContext classe , que deriva da classe Entity Framework DbContext , identifica o banco de dados e especifica as tabelas no banco de dados. O contexto especifica um conjunto de entidades (tabela) para tarefas e o código passa para o contexto o nome da cadeia de conexão. Esse nome refere-se a uma cadeia de conexão definida no arquivo Web.config.
public class MyFixItContext : DbContext
{
public MyFixItContext()
: base("name=appdb")
{
}
public DbSet<MyFixIt.Persistence.FixItTask> FixItTasks { get; set; }
}
A cadeia de conexão no arquivo Web.config é nomeada appdb (aqui apontando para o banco de dados de desenvolvimento local):
<connectionStrings>
<add name="DefaultConnection" connectionString="Data Source=(LocalDb)\v11.0;Initial Catalog=aspnet-MyFixIt-20130604091232_4;Integrated Security=True" providerName="System.Data.SqlClient" />
<add name="appdb" connectionString="Data Source=(localdb)\v11.0; Initial Catalog=MyFixItContext-20130604091609_11;Integrated Security=True; MultipleActiveResultSets=True" providerName="System.Data.SqlClient" />
</connectionStrings>
O Entity Framework cria uma tabela FixItTasks com base nas propriedades incluídas na FixItTask classe de entidade. Essa é uma classe POCO simples (Objeto CLR Antigo Simples), o que significa que ela não herda ou tem dependências no Entity Framework. Mas o Entity Framework sabe como criar uma tabela com base nela e executar operações CRUD (create-read-update-delete) com ela.
public class FixItTask
{
public int FixItTaskId { get; set; }
public string CreatedBy { get; set; }
[Required]
public string Owner { get; set; }
[Required]
public string Title { get; set; }
public string Notes { get; set; }
public string PhotoUrl { get; set; }
public bool IsDone { get; set; }
}
O aplicativo Corrigir inclui uma interface de repositório que ele usa para operações CRUD que trabalham com o armazenamento de dados.
public interface IFixItTaskRepository
{
Task<List<FixItTask>> FindOpenTasksByOwnerAsync(string userName);
Task<List<FixItTask>> FindTasksByCreatorAsync(string userName);
Task<MyFixIt.Persistence.FixItTask> FindTaskByIdAsync(int id);
Task CreateAsync(FixItTask taskToAdd);
Task UpdateAsync(FixItTask taskToSave);
Task DeleteAsync(int id);
}
Observe que os métodos do repositório são todos assíncronos, portanto, todo o acesso a dados pode ser feito de maneira completamente assíncrona.
A implementação do repositório chama métodos assíncronos do Entity Framework para trabalhar com os dados, incluindo consultas LINQ, bem como para operações de inserção, atualização e exclusão. Aqui está um exemplo do código para procurar uma tarefa Corrigir.
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
try
{
fixItTask = await db.FixItTasks.FindAsync(id);
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed, "id={0}", id);
}
catch(Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
Você observará que também há algum código de registro em log de erros e tempo aqui. Examinaremos isso mais tarde no capítulo Monitoramento e Telemetria.
Escolhendo Banco de Dados SQL (PaaS) versus SQL Server em uma VM (IaaS) no Azure
Uma coisa interessante sobre SQL Server e SQL do Azure Database é que o modelo de programação principal para ambos é idêntico. Você pode usar a maioria das mesmas habilidades em ambos os ambientes. Você pode até mesmo usar um banco de dados SQL Server em desenvolvimento e uma instância de Banco de Dados SQL na nuvem, que é como o aplicativo Fix It é configurado.
Como alternativa, você pode executar o mesmo SQL Server na nuvem que você executa localmente instalando-o em VMs IaaS. Para alguns aplicativos herdados, executar SQL Server em uma VM pode ser uma solução melhor. Como um banco de dados SQL Server é executado em uma VM dedicada, ele tem mais recursos disponíveis do que um banco de dados Banco de Dados SQL executado em um servidor compartilhado. Isso significa que um banco de dados SQL Server pode ser maior e ainda ter um bom desempenho. Em geral, quanto menor o tamanho do banco de dados e o tamanho da tabela, melhor o caso de uso funciona para Banco de Dados SQL (PaaS).
Aqui estão algumas diretrizes sobre como escolher entre os dois modelos.
| Banco de Dados SQL do Azure (PaaS) | SQL Server em uma Máquina Virtual (IaaS) |
|---|---|
| Prós – você não precisa criar ou gerenciar VMs, atualizar ou corrigir o sistema operacional ou SQL; O Azure faz isso por você. – Alta disponibilidade interna, com um SLA no nível do banco de dados. – TCO (baixo custo total de propriedade) porque você paga apenas pelo que usa (nenhuma licença necessária). – Bom para lidar com um grande número de bancos de dados menores (<=500 GB cada). – Fácil criar dinamicamente novos bancos de dados para habilitar a expansão. | Prós – compatível com recursos com SQL Server locais. – Pode implementar SQL Server alta disponibilidade por meio do AlwaysOn em mais de 2 VMs, com SLA no nível da VM. – Você tem controle total sobre como o SQL é gerenciado. – Pode reutilize as licenças do SQL que você já possui ou pague por hora por uma. – Bom para lidar com bancos de dados menores, mas maiores (1 TB+). |
| Contras – algumas lacunas de recursos em comparação com SQL Server locais (falta de integração CLR, TDE, suporte à compactação, SQL Server Reporting Services etc.) – limite de tamanho do banco de dados de 500 GB. | Contras – Atualizações/patches (SO e SQL) são de sua responsabilidade – A criação e o gerenciamento de bancos de dados são de sua responsabilidade – O IOPS de disco (operações de entrada/saída por segundo) é limitado a cerca de 8.000 (por meio de 16 unidades de dados). |
Se você quiser usar SQL Server em uma VM, poderá usar sua própria licença de SQL Server ou pagar por uma por hora. Por exemplo, no portal ou por meio da API REST, você pode criar uma nova VM usando uma imagem SQL Server.
Quando você cria uma VM com uma imagem SQL Server, avaliamos o custo da licença SQL Server por hora com base no uso da VM. Se você tem um projeto que só vai ser executado por alguns meses, é mais barato pagar por hora. Se você acha que seu projeto vai durar anos, é mais barato comprar a licença da maneira que você normalmente faz.
Resumo
A computação em nuvem torna prático misturar e combinar abordagens de armazenamento de dados para melhor atender às necessidades do seu aplicativo. Se você estiver criando um novo aplicativo, pense cuidadosamente sobre as perguntas listadas aqui para escolher abordagens que continuarão funcionando bem quando seu aplicativo crescer. O próximo capítulo explicará algumas estratégias de particionamento que você pode usar para combinar várias abordagens de armazenamento de dados.
Recursos
Para obter mais informações, consulte os recursos a seguir.
Escolhendo uma plataforma de banco de dados:
- Acesso a dados para soluções de Highly-Scalable: usando SQL, NoSQL e persistência poliglota. Livro eletrônico da Microsoft Patterns and Practices que se aprofunda nos diferentes tipos de armazenamentos de dados disponíveis para aplicativos de nuvem.
- Padrões e práticas da Microsoft – Diretrizes do Azure. Consulte Primer de Consistência de Dados, Diretrizes de Replicação de Dados e Sincronização, Padrão de Tabela de Índice, Padrão de Exibição Materializada.
- BASE: uma alternativa ácida. Artigo sobre compensações entre consistência de dados e escalabilidade.
- Sete bancos de dados em sete semanas: um guia para bancos de dados modernos e o movimento NoSQL. Livro de Eric Redmond e Jim R. Wilson. Altamente recomendado para se apresentar ao intervalo de plataformas de armazenamento de dados disponíveis hoje.
Escolhendo entre SQL Server e Banco de Dados SQL:
- Visualização Premium para diretrizes de Banco de Dados SQL. Uma introdução ao Banco de Dados SQL Premium e diretrizes sobre quando escolhê-lo nas edições Banco de Dados SQL Web e Business.
- Diretrizes e limitações (banco de dados SQL do Azure). Página do portal que vincula à documentação sobre limitações de Banco de Dados SQL, incluindo uma que se concentra em SQL Server recursos que Banco de Dados SQL não dá suporte.
- SQL Server no Máquinas Virtuais do Azure. Página do portal que vincula à documentação sobre como executar SQL Server no Azure.
- Scott Guthrie explica os Bancos de Dados SQL no Azure. Introdução em vídeo de 6 minutos ao Banco de Dados SQL por Scott Guthrie.
- Padrões de aplicativo e estratégias de desenvolvimento para SQL Server no Máquinas Virtuais do Azure.
Usando o Entity Framework e Banco de Dados SQL em um aplicativo Web ASP.NET
- Introdução com o EF 6 usando o MVC 5. Série de tutoriais de nove partes que orienta você na criação de um aplicativo MVC que usa eF e implanta o banco de dados no Azure e Banco de Dados SQL.
- ASP.NET Implantação da Web usando o Visual Studio. Série de tutoriais de doze partes que aborda mais detalhadamente como implantar um banco de dados usando o Código EF Primeiro.
- Implante um aplicativo do Secure ASP.NET MVC 5 com Associação, OAuth e Banco de Dados SQL em um Site do Azure. Tutorial passo a passo que orienta você na criação de um aplicativo Web que usa autenticação, armazena tabelas de aplicativos no banco de dados de associação, modifica o esquema de banco de dados e implanta o aplicativo no Azure.
- ASP.NET Mapa de Conteúdo de Acesso a Dados. Links para recursos para trabalhar com EF e Banco de Dados SQL.
Usando o MongoDB no Azure:
- MongoDB Atlas no Azure. Página do portal para obter a documentação sobre como executar o MongoDB Atlas no Azure.
- Crie um site do Azure que se conecta ao MongoDB em execução em uma máquina virtual no Azure. Tutorial passo a passo que mostra como usar um banco de dados MongoDB em um aplicativo Web ASP.NET.
HDInsight (Hadoop no Azure):
- HDInsight. Documentação do Portal para HDInsight no site do Azure .
- Hadoop e HDInsight: Big Data no Azure. Artigo da MSDN Magazine de Bruno Terkaly e Ricardo Villalobos, apresentando o Hadoop no Azure.
- Padrões e práticas da Microsoft – Diretrizes do Azure. Confira Padrão MapReduce.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de