Criar e treinar um modelo de classificação personalizado
Este conteúdo se aplica a:![]() v4.0 (versão prévia) | Versões anteriores:
v4.0 (versão prévia) | Versões anteriores:![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)
Importante
Modelo de classificação personalizado está atualmente em visualização pública. Recursos, abordagens e processos podem ser alterados, antes da Disponibilidade Geral (GA), com base nos comentários do usuário.
Os modelos de classificação personalizados podem classificar cada página em um arquivo de entrada para identificar um ou mais documentos dentro dele. Os modelos de classificador também pode identificar vários documentos ou várias instâncias de um único documento no arquivo de entrada. Os modelos personalizados da Informação de Documentos exigem apenas cinco documentos de treinamento por classe de documento para serem introduzidos. Para começar a treinar um modelo de classificação personalizado, você precisa de pelo menos cinco documentos para cada classe e duas classes de documentos.
Requisitos de entrada do modelo de classificação personalizado
Verifique se o conjunto de dados de treinamento segue os requisitos de entrada da Informação de Documentos.
Formatos de arquivo com suporte:
Modelar PDF Image,: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLer ✔ ✔ ✔ Layout ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview, 2023-10-31-preview) Documento geral ✔ ✔ Predefinida ✔ ✔ Extração personalizada ✔ ✔ Classificação personalizada ✔ ✔ ✔ (2024-07-31-preview, 2024-02-29-preview) Para ter melhores resultados, forneça uma foto clara ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de camada gratuita, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para análise de documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 x 50 pixels e 10.000 x 10.000 pixels.
Se os PDFs estiverem com bloqueio de senha, você deverá remover o bloqueio antes do envio.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1.024 x 768 pixels. Essa dimensão corresponde a aproximadamente
8pontos de texto a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para o treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é de
1GB, com um máximo de 10.000 páginas. Para 2024-07-31-preview e versões posteriores, o tamanho total dos dados de treinamento é de2GB com um máximo de 10.000 páginas.
Dicas de dados de treinamento
Siga estas dicas para otimizar seu conjunto de dados para treinamento:
Se possível, use documentos PDF de texto em vez de documentos baseados em imagem. Os PDFs digitalizados são tratados como imagens.
Se as imagens de formulário forem de qualidade inferior, use um conjunto de dados maior (10 a 15 imagens, por exemplo).
Carregar os dados de treinamento
Depois de reunir o conjunto de formulários ou documentos para treinamento, você precisará carregá-lo em um contêiner do Armazenamento de Blobs do Azure. Se você não sabe como criar uma conta de armazenamento do Azure com um contêiner, siga o guia de início rápido do Armazenamento do Microsoft Azure no portal do Azure. Use o tipo de preço gratuito (F0) para experimentar o serviço e atualizar mais tarde para um nível pago para produção. Se o conjunto de dados estiver organizado como pastas, preserve essa estrutura, pois o Estúdio poderá usar os nomes de pasta nos rótulos para simplificar o processo de rotulagem.
Crie um projeto de classificação no Estúdio de Informação de Documentos
O Estúdio de Informação de Documentos fornece e orquestra todas as chamadas à API exigidas para completar seu conjunto de dados e treinar seu modelo.
Comece navegando até o Estúdio de Informação de Documentos. Na primeira vez que você usar o Estúdio, precisará inicializar sua assinatura, grupo de recursos e recurso. Em seguida, siga os pré-requisitos para projetos personalizados para configurar o Studio para acessar seu conjunto de dados de treinamento.
No Estúdio, selecione o bloco Modelo de classificação personalizado, na seção de modelos personalizados da página e selecione o botão Criar um projeto.
Na caixa de diálogo
Create Project, forneça um nome para seu projeto, opcionalmente uma descrição e selecione continuar.Avançar, escolha ou selecione criar um recurso de Informação de Documentos antes de continuar.
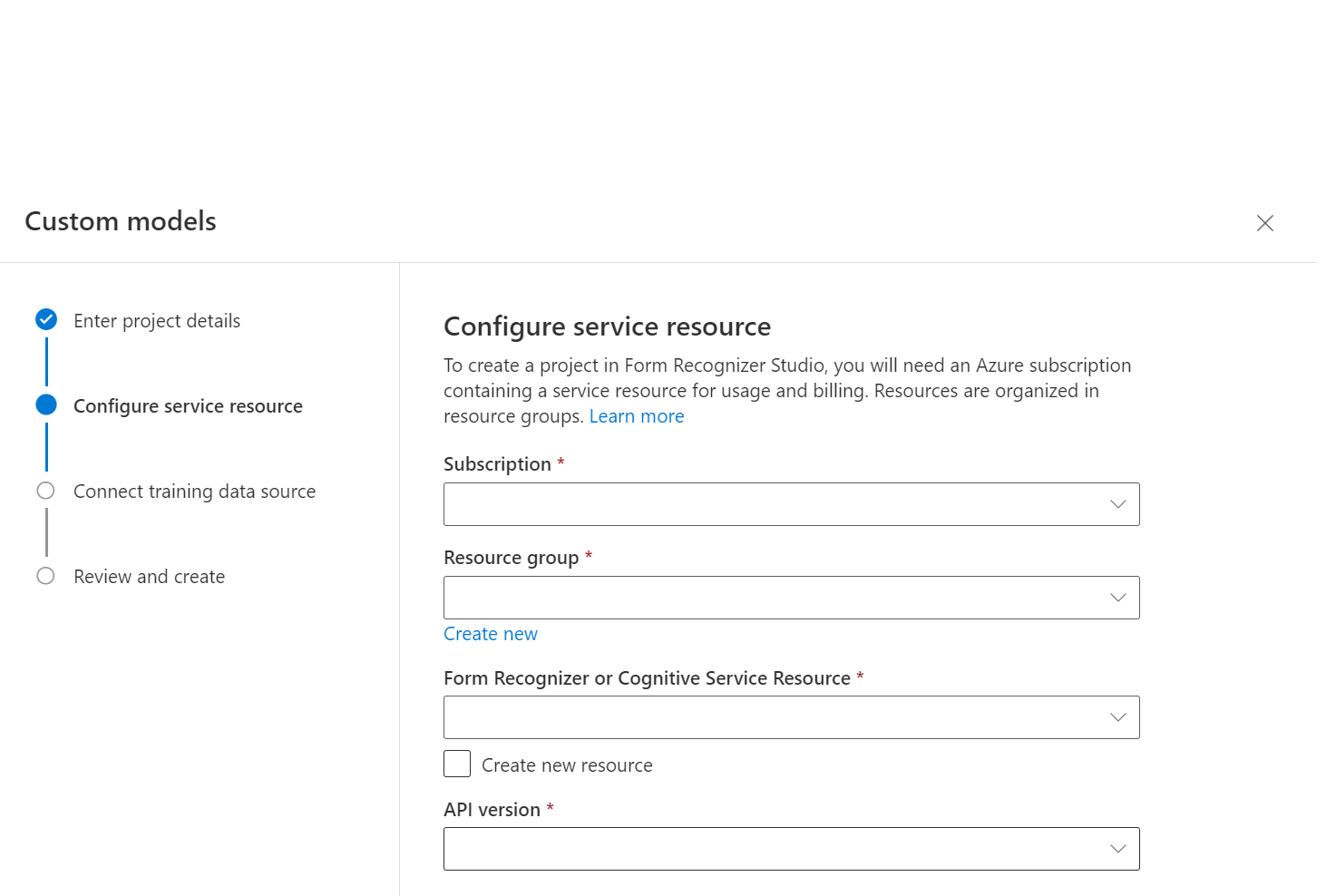
Em seguida, selecione a conta de armazenamento que você usou para carregar seu conjunto de dados de treinamento de modelo personalizado. O Caminho da pasta deverá estar vazio se os documentos de treinamento estiverem na raiz do contêiner. Se os documentos estiverem em uma subpasta, insira o caminho relativo da raiz do contêiner no campo Caminho da pasta. Depois que sua conta de armazenamento estiver configurada, selecione continuar.
Importante
Você pode organizar o conjunto de dados de treinamento por pastas em que o nome da pasta é o rótulo ou a classe de documentos ou criar uma lista plana de documentos aos quais você pode atribuir um rótulo no Estúdio.
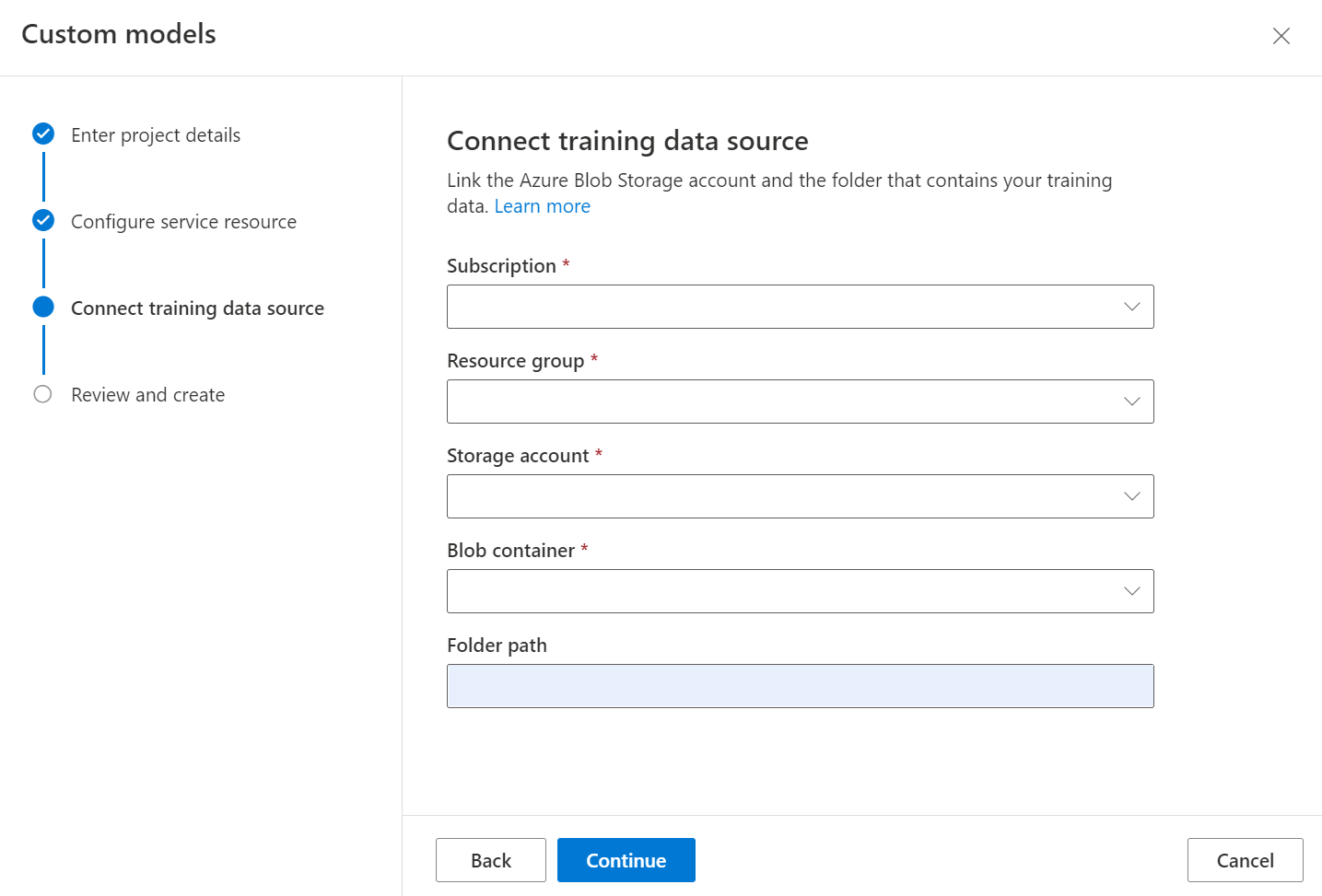
Treinar um classificador personalizado requer a saída do modelo de layout para cada documento em seu conjunto de dados. Execute o layout em todos os documentos antes do processo de treinamento do modelo.
Por fim, revise as configurações do projeto e selecione Criar projeto para criar um novo projeto. Agora você deve estar na janela de rotulagem e ver os arquivos no seu conjunto de dados listado.
Rotular seus dados.
Em seu projeto, você só precisa rotular cada documento com o rótulo de classe apropriado.
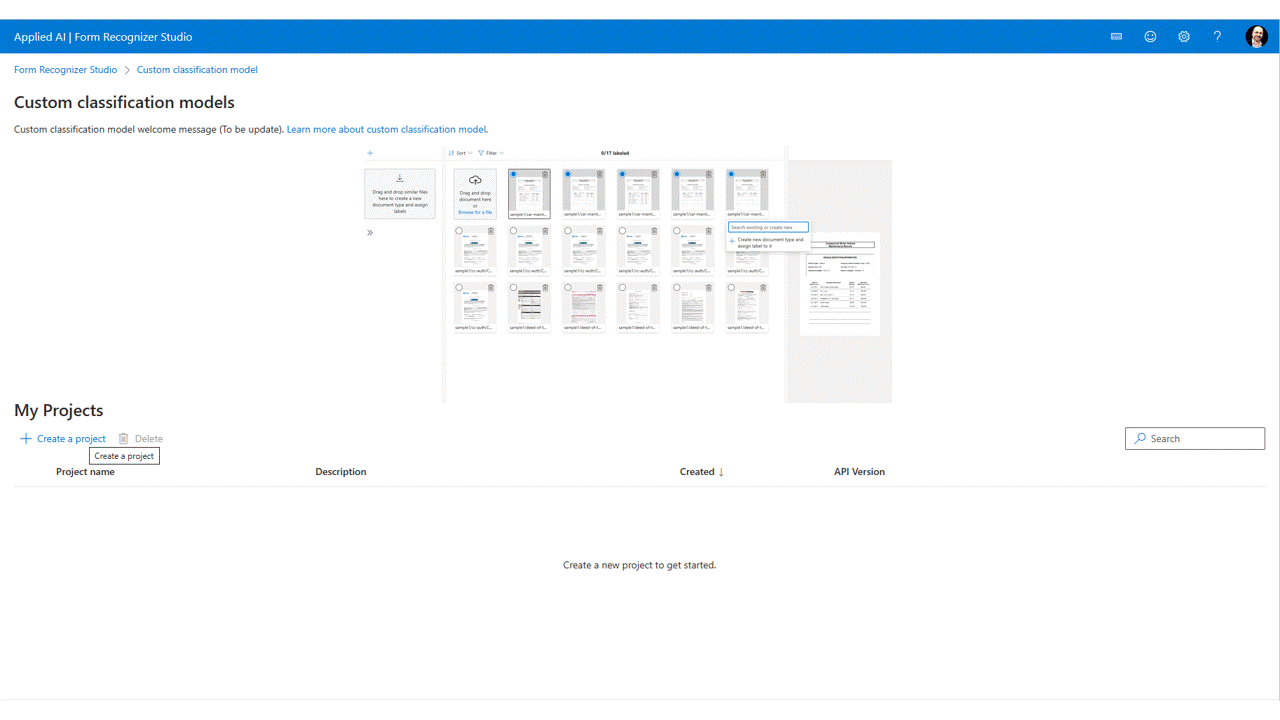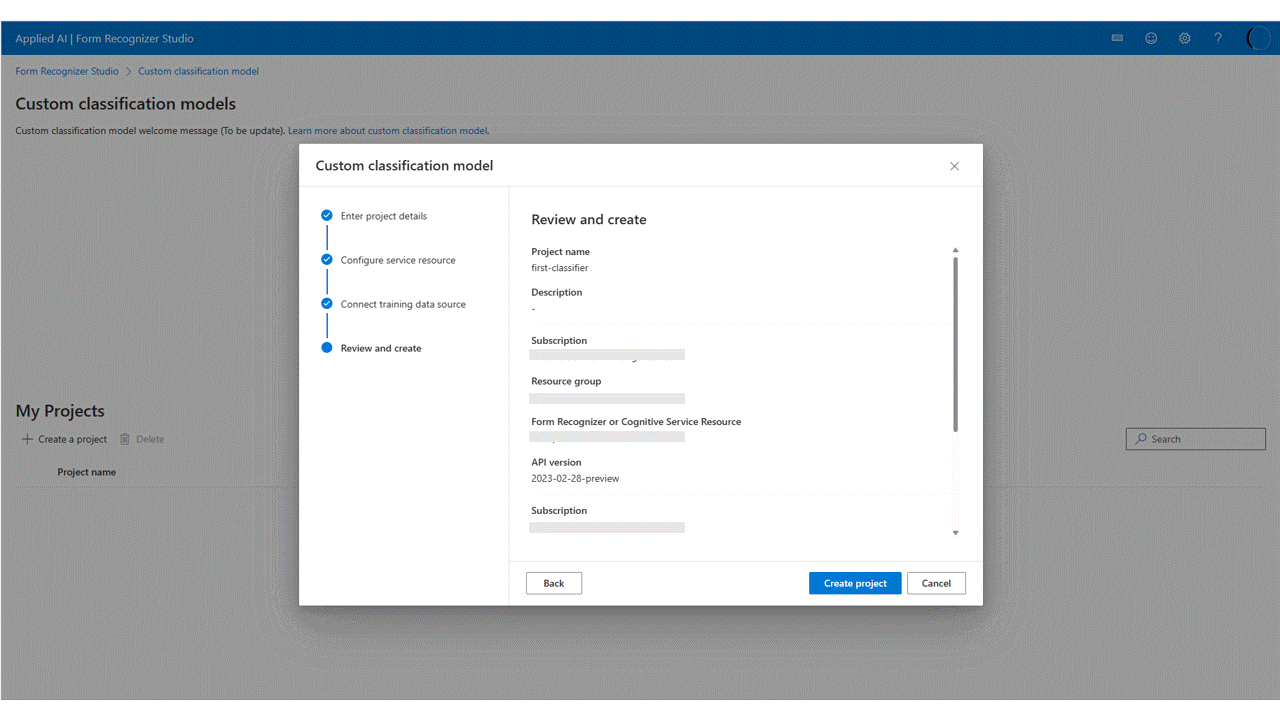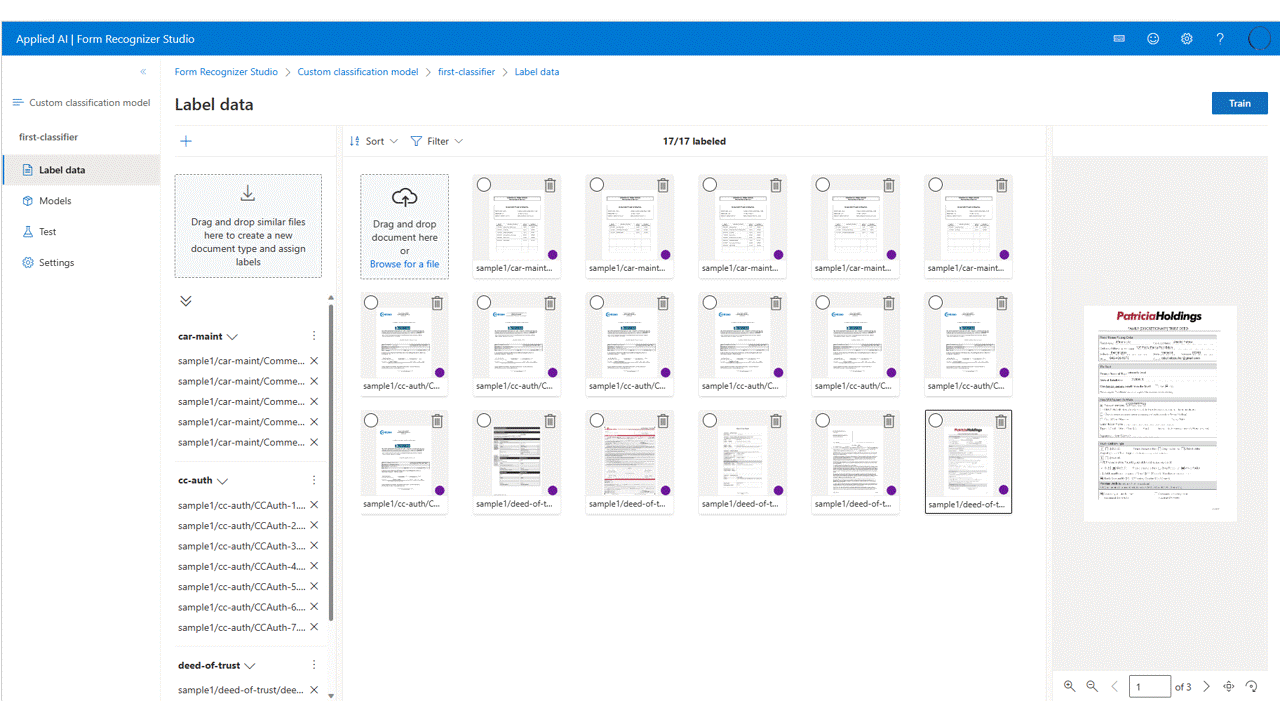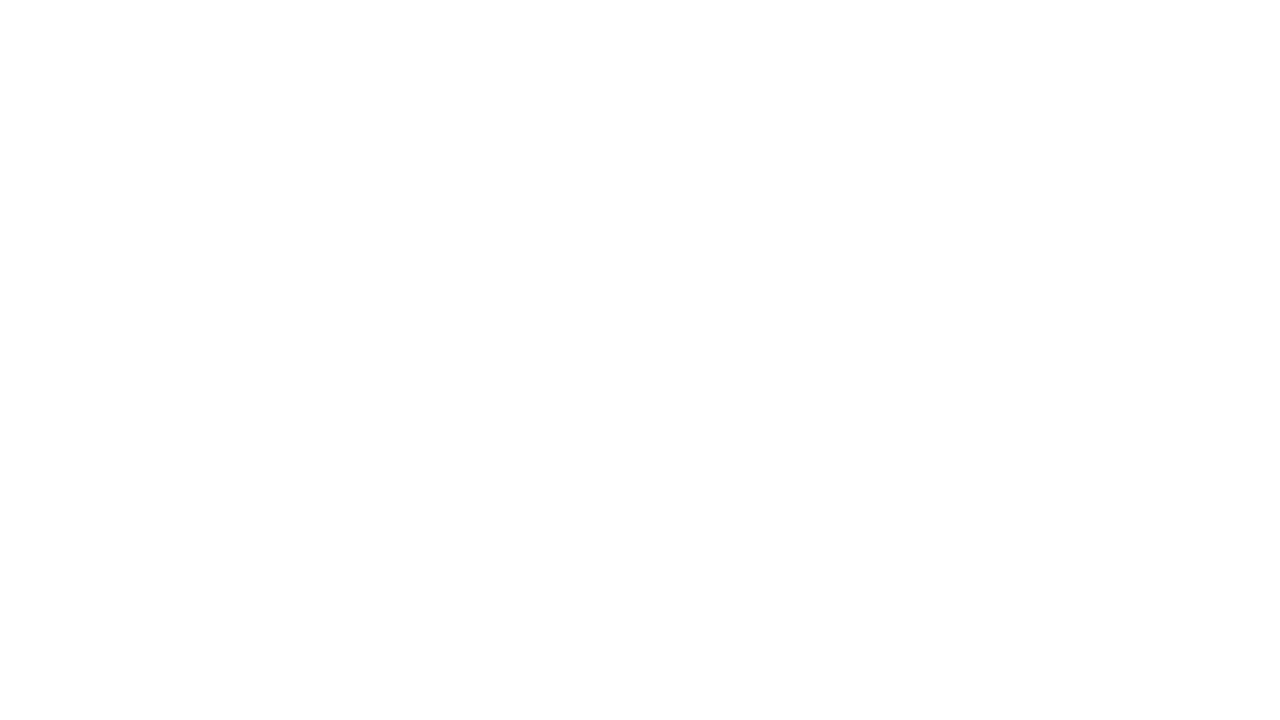
Você verá os arquivos carregados para armazenamento na lista de arquivos, prontos para serem rotulados. Você tem algumas opções para rotular seu conjunto de dados.
Se os documentos forem organizados em pastas, o Estúdio solicitará que você use os nomes da pasta como rótulos. Essa etapa simplifica sua rotulagem para uma única seleção.
Para atribuir um rótulo a um documento, selecione
add label selection markpara atribuir um rótulo.Use a tecla Ctrl para selecionar vários documentos para atribuir um rótulo
Agora todos os documentos dentro do seu conjunto de dados devem estar rotulados. Se você olhar a conta de armazenamento, encontrará arquivos .ocr.json que correspondem a cada documento no seu conjunto de dados e a um novo arquivo class-name.jsonl para cada classe rotulada. Esse conjunto de dados é enviado para treinar o modelo.
Treinar seu modelo
Com o seu conjunto de dados rotulado, agora você está pronto para treinar seu modelo. Selecione o botão Treinar no canto superior direito.
Na caixa de diálogo Treinar modelo, forneça uma ID de classificador exclusiva e, opcionalmente, uma descrição. A ID de classificador aceita um tipo de dados de cadeia de caracteres.
Selecione Treinar para iniciar o processo de treinamento.
Os modelos de classificador treinam em alguns minutos.
Navegue até o menu Modelos para exibir o status da operação de treinamento.
Testar o modelo
Depois que o treinamento do modelo for concluído, você poderá testar seu modelo selecionando o modelo na página da lista de modelos.
Selecione o modelo e o botão Testar.
Adicione um novo arquivo procurando um arquivo ou soltando um arquivo no seletor de documento.
Com um arquivo selecionado, escolha o botão Analisar para testar o modelo.
Os resultados do modelo são exibidos com a lista de documentos identificados, uma pontuação de confiança para cada documento identificado e o intervalo de páginas para cada um dos documentos identificados.
Valide seu modelo avaliando os resultados de cada documento identificado.
Treinar um classificador personalizado usando o SDK ou a API
O Studio orquestra as chamadas à API para que você treine um classificador personalizado. O conjunto de dados de treinamento do classificador requer a saída da API de layout que corresponde à versão da API para seu modelo de treinamento. O uso de resultados de layout de uma versão mais antiga da API pode resultar em um modelo com menor precisão.
O Studio gerará os resultados de layout para o conjunto de dados de treinamento se o conjunto de dados não contiver resultados de layout. Ao usar a API ou o SDK para treinar um classificador, você precisa adicionar os resultados do layout às pastas que contêm os documentos individuais. Os resultados do layout devem estar no formato da resposta da API ao chamar o layout diretamente. O modelo de objeto do SDK é diferente. Verifique se layout results são os resultados da API e não SDK response.
Solucionar problemas
O modelo de classificação requer resultados do modelo de layout para cada documento de treinamento. Se você não forneceu os resultados do layout, o Studio tentará executar o modelo de layout para cada documento antes de treinar o classificador. Esse processo é limitado e pode resultar em uma resposta 429.
No Studio, antes do treinamento com o modelo de classificação, execute o modelo de layout em cada documento e faça o upload para o mesmo local do documento original. Depois que os resultados do layout forem adicionados, você poderá treinar o modelo do classificador com seus documentos.