Tutorial: usar o Azure Functions e o Python para processar documentos armazenados
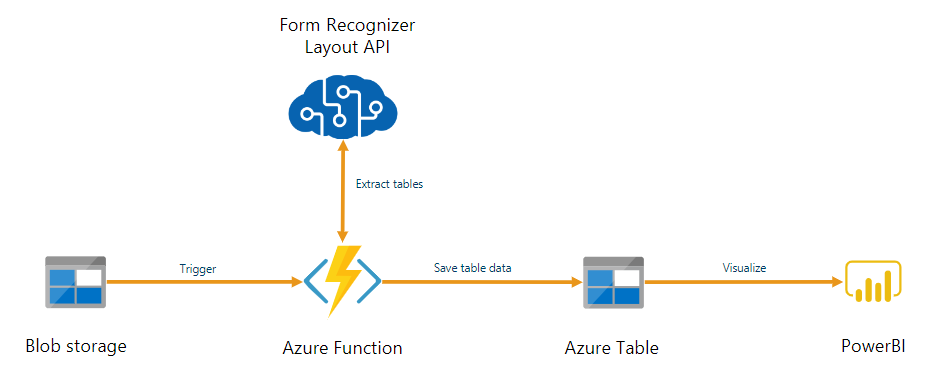
O serviço de Informação de Documentos pode ser usado como parte de um pipeline automatizado de processamento de dados criado com o Azure Functions. Este guia mostra como usar o Azure Functions para processar documentos que são carregados em um contêiner do Armazenamento de Blobs do Azure. Esse fluxo de trabalho extrai dados de tabela de documentos armazenados usando o modelo de layout do serviço de Informação de Documentos e salva os dados da tabela em um arquivo .csv no Azure. Em seguida, você pode exibir os dados usando o Microsoft Power BI (não abordado aqui).
Neste tutorial, você aprenderá como:
- Criar uma conta do Armazenamento do Azure.
- Criar um projeto do Azure Functions.
- Extrair dados de layout de formulários carregados.
- Carregar os dados de layout extraídos no Armazenamento do Azure.
Pré-requisitos
Assinatura do Azure - Criar uma gratuitamente
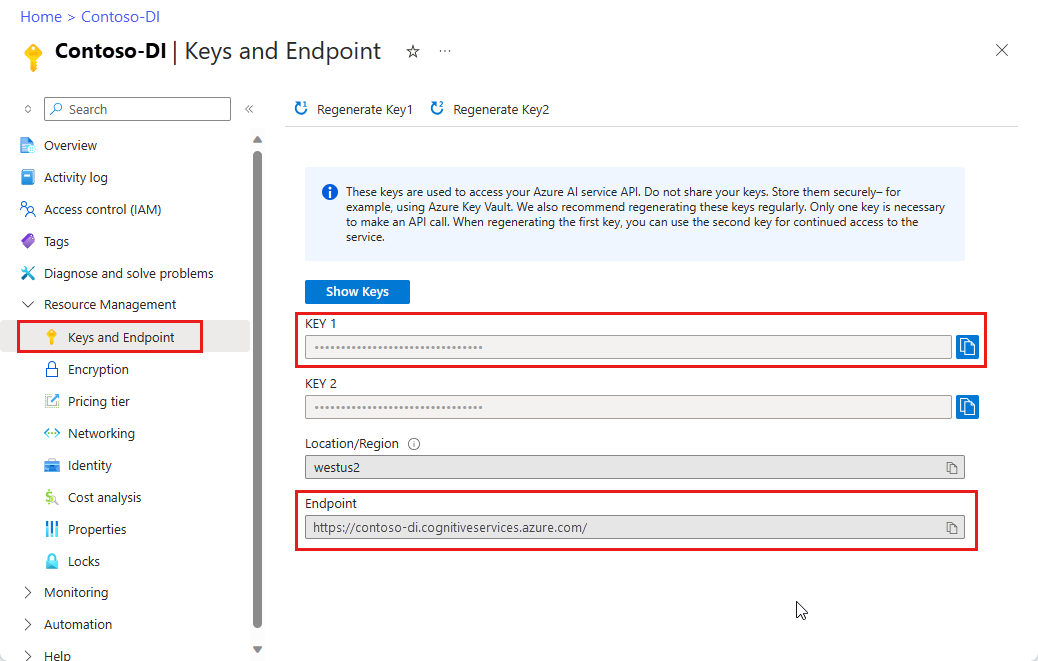
Um recurso de Informação de Documentos. Após obter sua assinatura do Azure, crie um recurso de Informação de Documentos no portal do Azure para obter a chave e o ponto de extremidade. Use o tipo de preço gratuito (
F0) para experimentar o serviço e atualizar mais tarde para um nível pago para produção.Após a implantação do recurso, selecione Ir para o recurso. Você precisará da chave e do ponto de extremidade do recurso que você criar para conectar seu aplicativo à API de Informação de Documentos. Você colará a chave e o ponto de extremidade no código abaixo mais adiante no tutorial:
Python 3.6.x, 3.7.x, 3.8.x ou 3.9.x (o Python 3.10.x não é compatível com este projeto).
A última versão do VS Code (Visual Studio Code) com as seguintes extensões instaladas:
Extensão do Azure Functions. Após a instalação, o logotipo do Azure será exibido no painel de navegação à esquerda.
Azure Functions Core Tools versão 3.x (a versão 4.x não é compatível com esse projeto).
Extensão do Python para Visual Studio Code. Para obter mais informações, confiraIntrodução ao Python no VS Code
Gerenciador de Armazenamento do Azure instalado.
Um documento PDF local a ser analisado. Você pode usar nosso documento PDF de exemplo para este projeto.
Criar uma conta do Armazenamento do Azure
Crie uma conta de Armazenamento do Azure v2 de uso geral no portal do Azure. Se você não sabe como criar uma conta de armazenamento do Azure com um contêiner de armazenamento, siga este início rápido:
- Criar uma conta de armazenamento. Ao criar sua a conta de armazenamento, selecione desempenho Standard no campo Detalhes da instância>Desempenho.
- Criar um contêiner. Ao criar seu contêiner, defina o Nível de acesso público como Contêiner (acesso de leitura anônimo de contêineres e arquivos) na janela Novo contêiner.
No painel esquerdo, selecione a guia Compartilhamento de recurso (CORS) e remova a política do CORS, caso exista.
Após a implantação da conta de armazenamento, crie dois contêineres de armazenamento de blobs vazios, chamados test e output.
Criar um projeto do Azure Functions
Crie uma pasta chamada functions-app para conter o projeto e escolha Selecionar.
Abra o Visual Studio Code e depois a paleta de comandos (Ctrl+Shift+P). Procure e escolha Python: Selecionar Interpretador → escolha um interpretador do Python instalado da versão 3.6.x, 3.7.x, 3.8.x ou 3.9.x. Essa seleção adicionará o caminho do interpretador do Python selecionado ao projeto.
Selecione o logotipo do Azure no painel de navegação à esquerda.
Você verá os recursos do Azure existentes na exibição Recursos.
Selecione a assinatura do Azure que você está usando para este projeto e, abaixo, veja o Aplicativo de Funções do Azure.
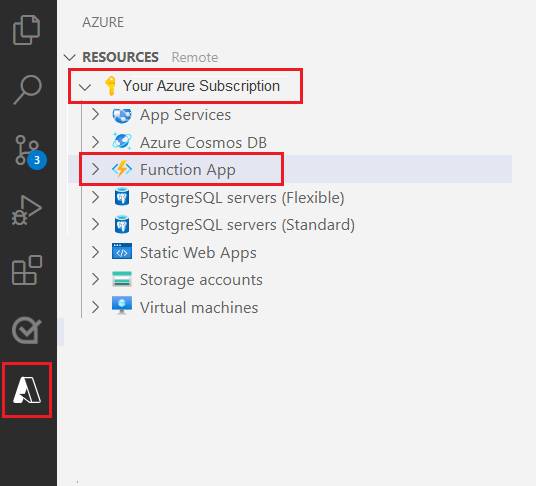
Selecione a seção Workspace (Local) localizada abaixo dos recursos listados. Selecione o símbolo de adição e clique no botão Criar Função.

Quando solicitado, escolha Criar projeto e acesse o diretório function-app. Escolha Selecionar.
Será solicitado que você defina várias configurações:
Selecione uma linguagem → Escolha o Python.
Selecione um interpretador do Python para criar um ambiente virtual → Selecione o interpretador definido como o padrão anteriormente.
Selecione um modelo → Escolha Gatilho do Armazenamento de Blobs do Azure e dê um nome ao gatilho ou aceite o nome padrão. Pressione Enter para confirmar.
Selecione a configuração → Escolha ➕Criar configuração de aplicativo local no menu suspenso.
Selecione a assinatura → Escolha sua assinatura do Azure com a conta de armazenamento que você criou → Selecione sua conta de armazenamento → Selecione o nome do contêiner de entrada de armazenamento (nesse caso,
input/{name}). Pressione Enter para confirmar.Selecione como deseja abrir o projeto → Escolha Abrir o projeto na janela atual no menu suspenso.
Quando você concluir essas etapas, o VS Code adicionará um novo projeto do Azure Function com um script Python __init__.py. Esse script será disparado quando um arquivo for carregado no contêiner de armazenamento input:
import logging
import azure.functions as func
def main(myblob: func.InputStream):
logging.info(f"Python blob trigger function processed blob \n"
f"Name: {myblob.name}\n"
f"Blob Size: {myblob.length} bytes")
Testar a função
Pressione F5 para executar a função básica. O VS Code solicitará que você selecione uma conta de armazenamento para interação.
Selecione a conta de armazenamento criada e prossiga.
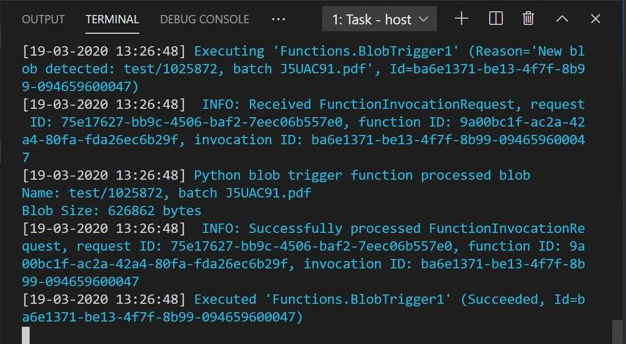
Abra o Gerenciador de Armazenamento do Azure e carregue um documento PDF de exemplo no contêiner input. Depois, verifique o terminal do VS Code. O script deve registrar que foi disparado pelo upload do PDF.
Interrompa o script antes de continuar.
Adicionar um código de processamento de documentos
A seguir, você adicionará seu próprio código ao script do Python para chamar o serviço de Informação de Documentos e analisar os documentos carregados usando o modelo de Layout da Informação de Documentos.
No VS Code, acesse o arquivo requirements.txt da função. Esse arquivo especifica as dependências do script. Adicione os seguintes pacotes do Python ao arquivo:
cryptography azure-functions azure-storage-blob azure-identity requests pandas numpyEm seguida, abra o script __init__.py. Adicione as seguintes declarações de
import:import logging from azure.storage.blob import BlobServiceClient import azure.functions as func import json import time from requests import get, post import os import requests from collections import OrderedDict import numpy as np import pandas as pdVocê pode deixar a função
maingerada no estado em que se encontra. Você adicionará o seu código personalizado dentro dessa função.# This part is automatically generated def main(myblob: func.InputStream): logging.info(f"Python blob trigger function processed blob \n" f"Name: {myblob.name}\n" f"Blob Size: {myblob.length} bytes")O bloco de código a seguir chama a API de Análise de Layout do serviço de Informação de Documentos no documento carregado. Preencha os valores de ponto de extremidade e chave.
# This is the call to the Document Intelligence endpoint endpoint = r"Your Document Intelligence Endpoint" apim_key = "Your Document Intelligence Key" post_url = endpoint + "/formrecognizer/v2.1/layout/analyze" source = myblob.read() headers = { # Request headers 'Content-Type': 'application/pdf', 'Ocp-Apim-Subscription-Key': apim_key, } text1=os.path.basename(myblob.name)Importante
Lembre-se de remover a chave do seu código quando terminar e nunca poste-a publicamente. Para produção, use uma maneira segura de armazenar e acessar suas credenciais, como o Azure Key Vault. Para obter mais informações, confira a segurança dos serviços de IA do Azure.
Em seguida, adicione código para consultar o serviço e obter os dados retornados.
resp = requests.post(url=post_url, data=source, headers=headers) if resp.status_code != 202: print("POST analyze failed:\n%s" % resp.text) quit() print("POST analyze succeeded:\n%s" % resp.headers) get_url = resp.headers["operation-location"] wait_sec = 25 time.sleep(wait_sec) # The layout API is async therefore the wait statement resp = requests.get(url=get_url, headers={"Ocp-Apim-Subscription-Key": apim_key}) resp_json = json.loads(resp.text) status = resp_json["status"] if status == "succeeded": print("POST Layout Analysis succeeded:\n%s") results = resp_json else: print("GET Layout results failed:\n%s") quit() results = resp_jsonAdicione o código a seguir para se conectar ao contêiner output do Armazenamento do Azure. Preencha com seus valores para o nome e a chave da conta de armazenamento. Você pode obter a chave na guia Chaves de acesso do recurso de armazenamento no portal do Azure.
# This is the connection to the blob storage, with the Azure Python SDK blob_service_client = BlobServiceClient.from_connection_string("DefaultEndpointsProtocol=https;AccountName="Storage Account Name";AccountKey="storage account key";EndpointSuffix=core.windows.net") container_client=blob_service_client.get_container_client("output")O código a seguir analisa a resposta retornada pelo serviço de Informação de Documentos, constrói um arquivo .csv e o carrega no contêiner de saída.
Importante
Você provavelmente precisará editar esse código para corresponder à estrutura dos seus próprios documentos.
# The code below extracts the json format into tabular data. # Please note that you need to adjust the code below to your form structure. # It probably won't work out-of-the-box for your specific form. pages = results["analyzeResult"]["pageResults"] def make_page(p): res=[] res_table=[] y=0 page = pages[p] for tab in page["tables"]: for cell in tab["cells"]: res.append(cell) res_table.append(y) y=y+1 res_table=pd.DataFrame(res_table) res=pd.DataFrame(res) res["table_num"]=res_table[0] h=res.drop(columns=["boundingBox","elements"]) h.loc[:,"rownum"]=range(0,len(h)) num_table=max(h["table_num"]) return h, num_table, p h, num_table, p= make_page(0) for k in range(num_table+1): new_table=h[h.table_num==k] new_table.loc[:,"rownum"]=range(0,len(new_table)) row_table=pages[p]["tables"][k]["rows"] col_table=pages[p]["tables"][k]["columns"] b=np.zeros((row_table,col_table)) b=pd.DataFrame(b) s=0 for i,j in zip(new_table["rowIndex"],new_table["columnIndex"]): b.loc[i,j]=new_table.loc[new_table.loc[s,"rownum"],"text"] s=s+1Por fim, o último bloco de código carrega a tabela extraída e os dados de texto em seu elemento do Armazenamento de Blobs.
# Here is the upload to the blob storage tab1_csv=b.to_csv(header=False,index=False,mode='w') name1=(os.path.splitext(text1)[0]) +'.csv' container_client.upload_blob(name=name1,data=tab1_csv)
Executar a função
Pressione F5 para executar a função novamente.
Use o Gerenciador de Armazenamento do Azure para carregar um formulário PDF de exemplo no contêiner de armazenamento input. Essa ação deve disparar o script a ser executado e você deve ver o arquivo .csv resultante (exibido como uma tabela) no contêiner output.
Você pode conectar esse contêiner ao Power BI para criar visualizações avançadas dos dados que ele contém.
Próximas etapas
Neste tutorial, você aprendeu a usar uma Função do Azure escrita em Python para processar automaticamente documentos PDF carregados e gerar seu conteúdo em um formato mais amigável. Em seguida, saiba como usar o Power BI para exibir os dados.
- O que é o serviço de Informação de Documentos?
- Saiba mais sobre o modelo de layout
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de