Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Importante
A partir de 20 de setembro de 2023, você não poderá criar novos recursos do Personalizador. O serviço Personalizador está sendo desativado em 1º de outubro de 2026. Recomendamos migrar para o software livre microsoft/learning-loop.
Este tutorial executa um loop do Personalizador em um Notebook do Azure, demonstrando o ciclo de vida completo de um loop do Personalizador de ponta a ponta.
O loop sugere o tipo de café que um cliente deve pedir. Os usuários e as respectivas preferências são armazenados em um conjunto de dados de usuário. As informações sobre o café são armazenadas em um conjunto de dados de café.
Usuários e café
O notebook, simulando a interação do usuário com um site, seleciona um usuário aleatório, uma hora do dia e um tipo de clima no conjunto de dados. Um resumo das informações do usuário é:
| Clientes – recursos de contexto | Horas do dia | Tipos de clima |
|---|---|---|
| Alice Bob Cathy Dave |
Manhã Tarde Noite |
Ensolarado Chuvoso Com neve |
Para ajudar o Personalizador no aprendizado, ao longo do tempo, o sistema também conhece os detalhes sobre a seleção de café de cada pessoa.
| Café – funcionalidades de ação | Tipos de temperatura | Locais de origem | Tipos de torra | Orgânico |
|---|---|---|---|---|
| Cappuccino | Dinâmica | Quênia | Escuro | Orgânico |
| Gelado | Frio | Brasil | Leve | Orgânico |
| Mocha doce | Frio | Etiópia | Leve | Não orgânico |
| Café com leite | Dinâmica | Brasil | Escuro | Não orgânico |
O propósito do loop do Personalizador é encontrar a melhor correspondência entre os usuários e o café, sempre que possível.
O código deste tutorial está disponível no repositório GitHub de Exemplos do Personalizer.
Como a simulação funciona
No início do sistema em execução, as sugestões do Personalizador são bem-sucedidas apenas entre 20% e 30%. Esse sucesso é indicado pela recompensa enviada novamente à API de Recompensa do Personalizador, com uma pontuação igual a 1. Após algumas chamadas de Classificação e Recompensa, o sistema é aprimorado.
Após as solicitações iniciais, execute uma avaliação offline. Isso permite que o Personalizador examine os dados e sugira uma política de aprendizado melhor. Aplique a nova política de aprendizado e execute o notebook novamente com 20% da contagem de solicitações anterior. O loop terá um desempenho melhor com a nova política de aprendizado.
Chamadas de classificação e recompensas
Para cada uma das algumas mil chamadas para o serviço Personalizador, o Azure Notebook envia a solicitação de classificação para a API REST:
- Uma ID exclusiva para o evento de classificação/solicitação
- Recursos de contexto: uma opção aleatória de usuário, clima e hora do dia, simulando um usuário em um site ou um dispositivo móvel
- Ações com recursos: Todos os dados de café, com base nos quais o Personalizador oferece uma sugestão
O sistema recebe a solicitação e, em seguida, compara essa previsão com a opção conhecida do usuário para a mesma hora do dia e o mesmo clima. Se a opção conhecida for a mesma que a escolha prevista, a Recompensa de 1 será enviada de volta para o Personalizador. Caso contrário, a recompensa enviada de volta será 0.
Observação
Essa é uma simulação para que o algoritmo para a recompensa seja simples. Em um cenário do mundo real, o algoritmo deve usar a lógica de negócios, possivelmente com pesos para vários aspectos da experiência do cliente, para determinar a pontuação de recompensa.
Pré-requisitos
- Uma conta Azure Notebook.
- Um recurso Personalizador de IA do Azure.
- Se você já tiver usado o recurso Personalizer, certifique-se de limpar os dados no portal do Azure para o recurso.
- Carregue todos os arquivos para a amostra em um projeto Azure Notebook.
Descrições de arquivo:
- Personalizer.ipynb é o Jupyter Notebook deste tutorial.
- User dataset é armazenado em um objeto JSON.
- Conjunto de dados doCoffee é armazenado em um objeto JSON.
- Example Request JSON é o formato esperado para uma solicitação POST para a API de Classificação.
Configurar o recurso Personalizador
No portal Azure, configure seu recurso Personalizer com a frequência do modelo update definida como 15 segundos e um tempo de espera reward de 10 minutos. Esses valores estão na página Configuração .
| Configuração | Valor |
|---|---|
| atualizar frequência do modelo | 15 segundos |
| tempo de espera para a recompensa | 10 minutos |
Esses valores têm uma duração muito curta para mostrar as alterações neste tutorial. Esses valores não devem ser usados em um cenário de produção sem validá-los para atingir sua meta com o loop do Personalizador.
Configurar o bloco de anotações Azure
- Altere o Kernel para
Python 3.6. - Abra o arquivo
Personalizer.ipynb.
Executar células do Notebook
Execute cada célula executável e aguarde o retorno dela. Você sabe que isso ocorreu quando os colchetes ao lado da célula exibem um número em vez de um *. As seções a seguir explicam o que cada célula faz programaticamente e o que esperar para a saída.
Incluir os módulos de Python
Inclua os módulos de Python necessários. A célula não tem nenhuma saída.
import json
import matplotlib.pyplot as plt
import random
import requests
import time
import uuid
Definir o nome e a chave de recurso do Personalizador
Na portal do Azure, localize a chave e ponto de extremidade na página Início Rápido do recurso Personalizador. Altere o valor de <your-resource-name> para o nome do recurso Personalizador. Altere o valor de <your-resource-key> para a chave do Personalizador.
# Replace 'personalization_base_url' and 'resource_key' with your valid endpoint values.
personalization_base_url = "https://<your-resource-name>.cognitiveservices.azure.com/"
resource_key = "<your-resource-key>"
Imprimir data e hora atuais
Use essa função para anotar as horas de início e de término da função iterativa e das iterações.
Essas células não têm nenhuma saída. A função, quando chamada, gera como saída a data e hora atual.
# Print out current datetime
def currentDateTime():
currentDT = datetime.datetime.now()
print (str(currentDT))
Obter a hora da última atualização do modelo
Quando a função, get_last_updated, é chamada, a função imprime a data e hora da última modificação em que o modelo foi atualizado.
Essas células não têm nenhuma saída. A função, quando chamada, gera como saída a última data de treinamento do modelo.
A função usa uma API REST GET para obter propriedades do modelo.
# ititialize variable for model's last modified date
modelLastModified = ""
def get_last_updated(currentModifiedDate):
print('-----checking model')
# get model properties
response = requests.get(personalization_model_properties_url, headers = headers, params = None)
print(response)
print(response.json())
# get lastModifiedTime
lastModifiedTime = json.dumps(response.json()["lastModifiedTime"])
if (currentModifiedDate != lastModifiedTime):
currentModifiedDate = lastModifiedTime
print(f'-----model updated: {lastModifiedTime}')
Obter política e configuração do serviço
Valide o estado do serviço com essas duas chamadas REST.
Essas células não têm nenhuma saída. A função, quando chamada, gera como saída os valores de serviço.
def get_service_settings():
print('-----checking service settings')
# get learning policy
response = requests.get(personalization_model_policy_url, headers = headers, params = None)
print(response)
print(response.json())
# get service settings
response = requests.get(personalization_service_configuration_url, headers = headers, params = None)
print(response)
print(response.json())
Construir URLs e ler arquivos de dados JSON
Esta célula
- compila as URLs usadas em chamadas REST
- define o cabeçalho de segurança usando a chave de recurso do Personalizador
- define a semente aleatória para o ID do evento Rank
- lê os arquivos de dados JSON
- chama o método
get_last_updated– a política de aprendizagem foi removida na saída de exemplo - chama o método
get_service_settings
A célula tem uma saída da chamada para as funções get_last_updated e get_service_settings.
# build URLs
personalization_rank_url = personalization_base_url + "personalizer/v1.0/rank"
personalization_reward_url = personalization_base_url + "personalizer/v1.0/events/" #add "{eventId}/reward"
personalization_model_properties_url = personalization_base_url + "personalizer/v1.0/model/properties"
personalization_model_policy_url = personalization_base_url + "personalizer/v1.0/configurations/policy"
personalization_service_configuration_url = personalization_base_url + "personalizer/v1.0/configurations/service"
headers = {'Ocp-Apim-Subscription-Key' : resource_key, 'Content-Type': 'application/json'}
# context
users = "users.json"
# action features
coffee = "coffee.json"
# empty JSON for Rank request
requestpath = "example-rankrequest.json"
# initialize random
random.seed(time.time())
userpref = None
rankactionsjsonobj = None
actionfeaturesobj = None
with open(users) as handle:
userpref = json.loads(handle.read())
with open(coffee) as handle:
actionfeaturesobj = json.loads(handle.read())
with open(requestpath) as handle:
rankactionsjsonobj = json.loads(handle.read())
get_last_updated(modelLastModified)
get_service_settings()
print(f'User count {len(userpref)}')
print(f'Coffee count {len(actionfeaturesobj)}')
Verifique se o rewardWaitTime da saída está definido como dez minutos e a modelExportFrequency está definida como 15 segundos.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:10:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:00:15', 'logRetentionDays': -1}
User count 4
Coffee count 4
Solução de problemas da primeira chamada REST
A célula anterior é a primeira célula que chama o Personalizador. Verifique se o código de status REST na saída é <Response [200]>. Se você receber um erro, assim como o 404, mas tiver certeza de que a chave de recurso e o nome estão corretos, recarregue o notebook.
Verifique se as contagens de café e de usuários equivalem a 4. Se receber um erro, verifique se você carregou todos os três arquivos JSON.
Configurar o gráfico de métricas no portal do Azure
Posteriormente neste tutorial, o processo de execução prolongada de 10.000 solicitações é visível no navegador com uma caixa de texto em constante atualização. Ao término do processo de execução prolongada, pode ser mais fácil vê-lo em um gráfico ou como uma soma total. Para exibir essas informações, use as métricas fornecidas com o recurso. Você pode criar o gráfico agora que concluiu uma solicitação ao serviço e, em seguida, atualizar ele periodicamente enquanto o processo prolongado está em andamento.
No portal do Azure, selecione o recurso personalizador.
Na navegação de recursos, selecione Métricas abaixo de Monitoramento.
No gráfico, selecione Adicionar métrica.
O recurso e o namespace da métrica já estão definidos. Você só precisa selecionar a métrica de chamadas bem-sucedidas e a agregação de soma.
Altere o filtro de tempo para as últimas 4 horas.
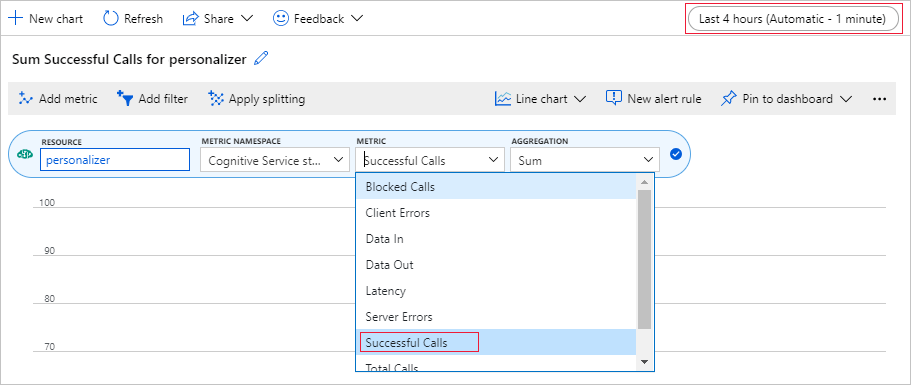
Você deve ver três chamadas bem-sucedidas no gráfico.
Gerar uma ID de evento exclusiva
Essa função gera um ID exclusivo para cada chamada de rank. A ID é usada para identificar as informações de chamada de classificação e de recompensa. Esse valor pode vir de um processo empresarial, tal como uma ID de exibição da Web ou uma ID de transação.
A célula não tem nenhuma saída. A função gera como saída a ID exclusiva quando chamada.
def add_event_id(rankjsonobj):
eventid = uuid.uuid4().hex
rankjsonobj["eventId"] = eventid
return eventid
Obter usuário aleatório, clima e hora do dia
Essa função seleciona um usuário único, um clima e uma hora do dia e, em seguida, adiciona esses itens ao objeto JSON para enviar para a solicitação de classificação.
A célula não tem nenhuma saída. Quando a função é chamada, ela retorna o nome do usuário, o clima e a hora do dia aleatórios.
A lista de 4 usuários e as respectivas preferências – somente algumas preferências são mostradas para fins de brevidade:
{
"Alice": {
"Sunny": {
"Morning": "Cold brew",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Bob": {
"Sunny": {
"Morning": "Cappucino",
"Afternoon": "Iced mocha",
"Evening": "Cold brew"
}...
},
"Cathy": {
"Sunny": {
"Morning": "Latte",
"Afternoon": "Cold brew",
"Evening": "Cappucino"
}...
},
"Dave": {
"Sunny": {
"Morning": "Iced mocha",
"Afternoon": "Iced mocha",
"Evening": "Iced mocha"
}...
}
}
def add_random_user_and_contextfeatures(namesoption, weatheropt, timeofdayopt, rankjsonobj):
name = namesoption[random.randint(0,3)]
weather = weatheropt[random.randint(0,2)]
timeofday = timeofdayopt[random.randint(0,2)]
rankjsonobj['contextFeatures'] = [{'timeofday': timeofday, 'weather': weather, 'name': name}]
return [name, weather, timeofday]
Adicionar todos os dados de café
Essa função adiciona a lista completa de café ao objeto JSON para enviar para a solicitação de classificação.
A célula não tem nenhuma saída. A função altera o rankjsonobj quando chamada.
O exemplo dos recursos de um único café é:
{
"id": "Cappucino",
"features": [
{
"type": "hot",
"origin": "kenya",
"organic": "yes",
"roast": "dark"
}
}
def add_action_features(rankjsonobj):
rankjsonobj["actions"] = actionfeaturesobj
Comparar a previsão com a preferência do usuário conhecida
Essa função é chamada depois que a API de classificação é chamada, para cada iteração.
Essa função compara a preferência do usuário para café, com base no clima e na hora do dia, com a sugestão do Personalizador para o usuário segundo esses filtros. Se a sugestão corresponder, uma pontuação de 1 será retornada, caso contrário, a pontuação será 0. A célula não tem nenhuma saída. A função gera como saída a pontuação quando chamada.
def get_reward_from_simulated_data(name, weather, timeofday, prediction):
if(userpref[name][weather][timeofday] == str(prediction)):
return 1
return 0
Loop por meio de chamadas à classificação e à recompensa
A próxima célula é o trabalho principal do notebook, obtendo um usuário aleatório, obtendo a lista de café e enviando ambos para a API de classificação. Comparar a previsão com as preferências conhecidas do usuário e, em seguida, enviar a recompensa de volta para o serviço Personalizador.
O loop é executado num_requests vezes. O Personalizador precisa de algumas mil chamadas para a classificação e a recompensa para criar um modelo.
A seguir, temos um exemplo do JSON enviado para a API de classificação. A lista de café não está completa, por questão de brevidade. Você pode ver o JSON completo do café em coffee.json.
JSON enviado para a API de classificação:
{
'contextFeatures':[
{
'timeofday':'Evening',
'weather':'Snowy',
'name':'Alice'
}
],
'actions':[
{
'id':'Cappucino',
'features':[
{
'type':'hot',
'origin':'kenya',
'organic':'yes',
'roast':'dark'
}
]
}
...rest of coffee list
],
'excludedActions':[
],
'eventId':'b5c4ef3e8c434f358382b04be8963f62',
'deferActivation':False
}
Resposta de JSON da API de classificação:
{
'ranking': [
{'id': 'Latte', 'probability': 0.85 },
{'id': 'Iced mocha', 'probability': 0.05 },
{'id': 'Cappucino', 'probability': 0.05 },
{'id': 'Cold brew', 'probability': 0.05 }
],
'eventId': '5001bcfe3bb542a1a238e6d18d57f2d2',
'rewardActionId': 'Latte'
}
Por fim, cada loop mostra a seleção aleatória de usuário, clima, hora do dia e a recompensa determinada. A recompensa de 1 indica que o recurso Personalizador selecionou o tipo de café correto para determinado usuário, clima e hora do dia.
1 Alice Rainy Morning Latte 1
A função usa:
- Classificação: uma API REST POST para obter a classificação.
- Recompensa: uma API REST POST para relatar a recompensa.
def iterations(n, modelCheck, jsonFormat):
i = 1
# default reward value - assumes failed prediction
reward = 0
# Print out dateTime
currentDateTime()
# collect results to aggregate in graph
total = 0
rewards = []
count = []
# default list of user, weather, time of day
namesopt = ['Alice', 'Bob', 'Cathy', 'Dave']
weatheropt = ['Sunny', 'Rainy', 'Snowy']
timeofdayopt = ['Morning', 'Afternoon', 'Evening']
while(i <= n):
# create unique id to associate with an event
eventid = add_event_id(jsonFormat)
# generate a random sample
[name, weather, timeofday] = add_random_user_and_contextfeatures(namesopt, weatheropt, timeofdayopt, jsonFormat)
# add action features to rank
add_action_features(jsonFormat)
# show JSON to send to Rank
print('To: ', jsonFormat)
# choose an action - get prediction from Personalizer
response = requests.post(personalization_rank_url, headers = headers, params = None, json = jsonFormat)
# show Rank prediction
print ('From: ',response.json())
# compare personalization service recommendation with the simulated data to generate a reward value
prediction = json.dumps(response.json()["rewardActionId"]).replace('"','')
reward = get_reward_from_simulated_data(name, weather, timeofday, prediction)
# show result for iteration
print(f' {i} {currentDateTime()} {name} {weather} {timeofday} {prediction} {reward}')
# send the reward to the service
response = requests.post(personalization_reward_url + eventid + "/reward", headers = headers, params= None, json = { "value" : reward })
# for every N rank requests, compute total correct total
total = total + reward
# every N iteration, get last updated model date and time
if(i % modelCheck == 0):
print("**** 10% of loop found")
get_last_updated(modelLastModified)
# aggregate so chart is easier to read
if(i % 10 == 0):
rewards.append( total)
count.append(i)
total = 0
i = i + 1
# Print out dateTime
currentDateTime()
return [count, rewards]
Executar 10.000 iterações
Execute o loop do Personalizador para 10.000 iterações. Esse é um evento de execução prolongada. Não feche o navegador que está executando o notebook. Atualize o gráfico de métricas no portal Azure periodicamente para ver o total de chamadas para o serviço. Quando você tem cerca de 20.000 chamadas, uma chamada de classificação e de recompensa para cada iteração do loop, as iterações são feitas.
# max iterations
num_requests = 200
# check last mod date N% of time - currently 10%
lastModCheck = int(num_requests * .10)
jsonTemplate = rankactionsjsonobj
# main iterations
[count, rewards] = iterations(num_requests, lastModCheck, jsonTemplate)
Gráfico de resultados para observar a melhoria
Crie um gráfico do count e do rewards.
def createChart(x, y):
plt.plot(x, y)
plt.xlabel("Batch of rank events")
plt.ylabel("Correct recommendations per batch")
plt.show()
Gráfico de execução para 10.000 solicitações de classificação
Execute a função createChart.
createChart(count,rewards)
Ler o gráfico
Este gráfico mostra o sucesso do modelo para a política de aprendizado padrão atual.
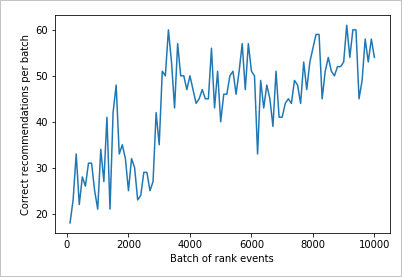
O objetivo ideal é que, ao final do teste, o loop alcance uma taxa de sucesso média próxima de 100%, excluindo a exploração. O valor padrão de exploração é de 20%.
100-20=80
Esse valor de exploração é encontrado no portal Azure, para o recurso Personalizador, na página Configuration.
Para encontrar uma melhor política de aprendizado, com base em seus dados para a API de classificação, execute uma avaliação offline no portal para o loop do Personalizador.
Executar uma avaliação offline
No portal Azure, abra a página Evaluations do recurso personalizador.
Selecione Criar Avaliação.
Insira os dados necessários, do nome da avaliação e do intervalo de datas para a avaliação do loop. O intervalo de datas deve incluir apenas os dias nos quais você está se concentrando para sua avaliação.
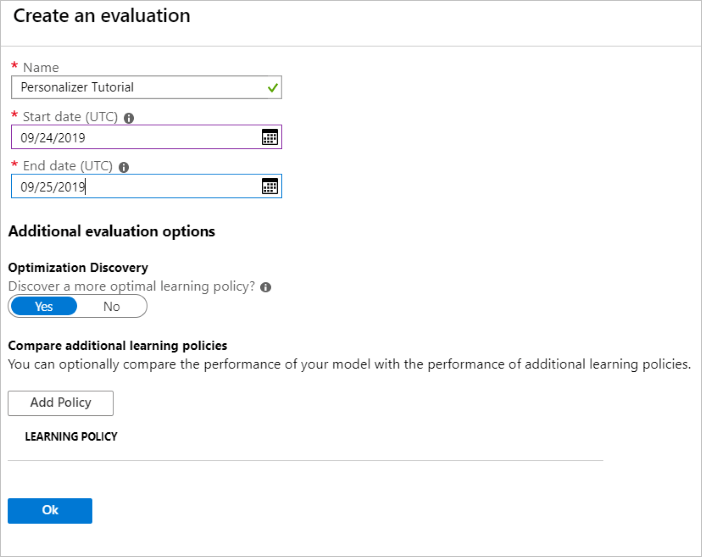
A finalidade de executar essa avaliação offline é determinar se há uma melhor política de aprendizado para os recursos e as ações usadas neste loop. Para descobrir essa política de aprendizado mais adequada, verifique se a Descoberta de Otimização está ativada.
Selecione OK para iniciar a avaliação.
Esta página Avaliações lista a nova avaliação e o status atual dela. Dependendo da quantidade de dados que você tem, essa avaliação pode levar algum tempo. Você pode voltar para esta página depois de alguns minutos para ver os resultados.
Quando a avaliação estiver concluída, selecione a avaliação e, em seguida, selecione Comparação de diferentes políticas de aprendizado. Isso mostra as políticas de aprendizado disponíveis e como elas se comportariam com os dados.
Selecione a política de aprendizado mais alta na tabela e selecione Aplicar. Isso aplica a melhor política de aprendizado ao seu modelo e treina-o novamente.
Alterar a frequência do modelo de atualização para 5 minutos
- No portal Azure, ainda no recurso Personalizador, selecione a página Configuration.
- Altere a frequência de atualização do modelo e o tempo de espera pela recompensa para 5 minutos e selecione Salvar.
Saiba mais sobre o tempo de espera para a recompensa e a frequência de atualização do modelo.
#Verify new learning policy and times
get_service_settings()
Verifique se o rewardWaitTime e o modelExportFrequency da saída estão definidos como 5 minutos.
-----checking model
<Response [200]>
{'creationTime': '0001-01-01T00:00:00+00:00', 'lastModifiedTime': '0001-01-01T00:00:00+00:00'}
-----model updated: "0001-01-01T00:00:00+00:00"
-----checking service settings
<Response [200]>
{...learning policy...}
<Response [200]>
{'rewardWaitTime': '00:05:00', 'defaultReward': 0.0, 'rewardAggregation': 'earliest', 'explorationPercentage': 0.2, 'modelExportFrequency': '00:05:00', 'logRetentionDays': -1}
User count 4
Coffee count 4
Validar nova política de aprendizado
Retorne ao arquivo Azure Notebooks e continue executando o mesmo loop, mas para apenas 2.000 iterações. Atualize o gráfico de métricas no portal Azure periodicamente para ver o total de chamadas para o serviço. Quando você tem cerca de 4.000 chamadas, uma chamada de classificação e de recompensa para cada iteração do loop, as iterações são feitas.
# max iterations
num_requests = 2000
# check last mod date N% of time - currently 10%
lastModCheck2 = int(num_requests * .10)
jsonTemplate2 = rankactionsjsonobj
# main iterations
[count2, rewards2] = iterations(num_requests, lastModCheck2, jsonTemplate)
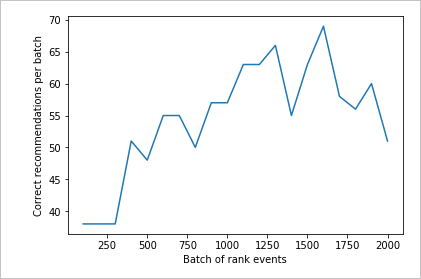
Executar o gráfico para 2.000 solicitações de classificação
Execute a função createChart.
createChart(count2,rewards2)
Examinar o segundo gráfico
O segundo gráfico deve mostrar um aumento visível nas previsões de classificação que se alinham com as preferências do usuário.
Limpar os recursos
Se você não pretende continuar a série de tutoriais, limpe os seguintes recursos:
- Exclua seu projeto do Azure Notebook.
- Exclua o recurso Personalizer.
Próximas etapas
Os arquivos de dados e notebook Jupyter usados neste exemplo estão disponíveis no repositório GitHub do Personalizador.