Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
A conversa em vários dispositivos facilita a criação de uma conversa com fala ou texto entre vários clientes e a coordenação das mensagens enviadas entre eles.
Observação
O acesso a conversas de vários dispositivos é um recurso de versão prévia.
Com a conversa em vários dispositivos, você pode:
- Conectar vários clientes à mesma conversa e gerenciar o envio e o recebimento de mensagens entre eles.
- Transcrever facilmente o áudio de cada cliente e enviar a transcrição para outros, com tradução opcional.
- Enviar facilmente mensagens de texto entre clientes, com tradução opcional.
Você pode criar um recurso ou solução que funcione em uma gama de dispositivos. Cada dispositivo pode enviar mensagens de forma independente (transcrições de áudio ou mensagens instantâneas) para todos os outros dispositivos.
Conversa em múltiplos dispositivos é adequada para cenários com vários dispositivos, cada um com um único microfone.
Importante
A conversa em vários dispositivos não dá suporte ao envio de arquivos de áudio entre clientes: somente a transcrição e/ou a tradução.
Principais recursos
- Transcrição em tempo real: todos recebem uma transcrição da conversa, para que possam acompanhar o texto em tempo real ou salvá-lo para mais tarde.
- Tradução em tempo real: com mais de 70 idiomas com suporte para tradução de texto, os usuários podem traduzir a conversa para os respectivos idiomas preferenciais.
- Transcrições legíveis: a transcrição e a tradução podem ser facilmente acompanhadas, com pontuação e quebras de frases.
- Entrada de voz ou de texto: cada usuário pode falar ou digitar no dispositivo dele, dependendo das funcionalidades de suporte ao idioma habilitadas para o idioma escolhido pelo participante. Consulte Suporte de idioma.
- Retransmissão de mensagens: o serviço de conversação com vários dispositivos distribui as mensagens enviadas por um cliente para todos os outros, nos idiomas de sua escolha.
- Identificação da mensagem: cada mensagem que os usuários recebem na conversa é marcada com o apelido do usuário que a enviou.
Casos de uso
Conversas leves
É fácil criar e ingressar em uma conversa. Um usuário atua como "host" e cria uma conversa, que gera um código de conversa aleatório de cinco letras e um código QR. Todos os outros usuários podem ingressar na conversa digitando o código de conversa ou através da leitura do código QR.
Como os usuários ingressar por meio do código de conversa e não são obrigados a compartilhar informações de contato, é fácil criar conversas rápidas e imediatas.
Reuniões inclusivas
A transcrição e a tradução em tempo real podem ajudar a tornar as conversas acessíveis para pessoas que falam idiomas diferentes e/ou surdas ou com problemas de audição. Cada pessoa também pode participar ativamente da conversa, falando em seu idioma preferencial ou enviando mensagens instantâneas.
Apresentações
Você também pode fornecer legendas para apresentações e palestras na tela e nos próprios dispositivos dos membros da audiência. Depois que o público ingressa no código de conversa, ele pode ver a transcrição, em seu idioma preferencial, em seu próprio dispositivo.
Como ele funciona
Todos os clientes usam o SDK de Fala para criar ou ingressar em uma conversa. O SDK de Fala interage com o serviço de conversação em vários dispositivos, que gerencia o tempo de vida de uma conversa. A conversa inclui a lista de participantes, o idioma escolhido por cada cliente e as mensagens enviadas.
Cada cliente pode enviar mensagens de áudio ou instantâneas. O serviço usa o reconhecimento de fala para converter áudio em texto e enviar mensagens instantâneas no estado em que se encontram. Se os clientes escolherem idiomas diferentes, o serviço traduzirá todas as mensagens para o(s) idioma(s) especificado(s) de cada cliente.
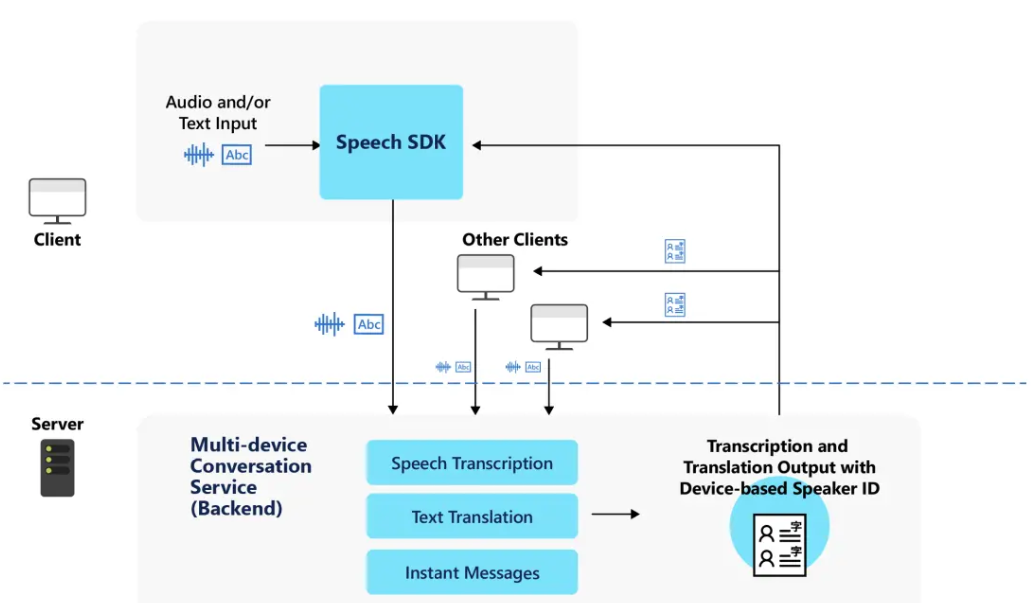
Visão Geral da Conversa, do Host e do Participante
Uma conversa é uma sessão que um usuário inicia para os outros usuários participantes ingressarem. Todos os clientes se conectam à conversa usando o código de conversa de cinco letras.
Cada conversa cria metadados que incluem:
- Os carimbos de data/hora de quando a conversa foi iniciada e encerrada
- A lista de todos os participantes na conversa, que inclui o apelido escolhido de cada usuário e o idioma principal para entrada de fala ou texto.
Há dois tipos de usuários em uma conversa: host e participante.
O host é o usuário que inicia uma conversa e que atua como o administrador dessa conversa.
- Cada conversa só pode ter um host
- O host deve estar conectado à conversa durante a conversa. Se o host sair da conversa, ela será encerrada para todos os outros participantes.
- O host possui alguns controles extras para gerenciar a conversa:
- Bloquear a conversa: impedir a entrada de mais participantes
- Silenciar todos os participantes – evitar que outros participantes enviem quaisquer mensagens para a conversa, tanto transcritas de fala quanto mensagens instantâneas.
- Silenciar participantes individuais
- Desativar o mudo para todos os participantes
- Desativar o mudo para participantes individuais
Um participante é um usuário que ingressa na uma conversa.
- Um participante pode sair e ingressar novamente na mesma conversa a qualquer momento, sem encerrar a conversa para outros participantes.
- Os participantes não podem bloquear a conversa ou ativar/desativar o mudo de outras pessoas
Observação
Cada conversa pode ter até 100 participantes, dos quais 10 podem estar falando simultaneamente a qualquer momento.
Suporte ao idioma
Cada usuário deve escolher um idioma principal ao ingressar em uma conversa. A seleção deles é o idioma em que falam e enviam mensagens instantâneas e também o idioma em que veem as mensagens de outros usuários.
Existem dois tipos de linguagens: linguagem falada para escrita e apenas texto.
Se o usuário escolher um idioma de conversão de fala em texto como seu idioma principal, ele poderá usar tanto a fala quanto a entrada de texto na conversa.
Se o usuário escolher um idioma somente de texto, ele só poderá usar a entrada de texto e enviar mensagens instantâneas na conversa. Os idiomas somente texto são os idiomas compatíveis com a tradução de texto, mas não com o reconhecimento de fala. Você pode ver os idiomas disponíveis na página de suporte ao idioma.
Além do seu idioma principal, cada participante também pode especificar mais idiomas para traduzir a conversa.
A tabela a seguir é um resumo do que o usuário pode fazer em uma conversa com vários dispositivos, com base no idioma principal escolhido.
| O que o usuário pode fazer na conversa | Conversão de fala em texto | Somente texto |
|---|---|---|
| Usar entrada de fala | ✔️ | ❌ |
| Enviar mensagens instantâneas | ✔️ | ✔️ |
| Traduzir a conversa | ✔️ | ✔️ |
Observação
Para obter listas de idiomas disponíveis para reconhecimento de fala e para tradução de texto, consulte idiomas com suporte.