O que é a Observabilidade de Rede do Serviço de Kubernetes do Azure (AKS)?
O Kubernetes é uma ferramenta poderosa para gerenciar aplicativos em contêineres. À medida que os ambientes em contêineres aumentam em complexidade, pode ser difícil identificar e solucionar problemas de rede em um cluster do Kubernetes.
A Observabilidade de Rede é uma parte importante da manutenção de um cluster do Kubernetes íntegro e eficiente. Ao coletar e analisar dados sobre o tráfego de rede, você pode obter insights sobre como o cluster está operando e identificar possíveis problemas antes que eles causem interrupções ou degradação do desempenho.
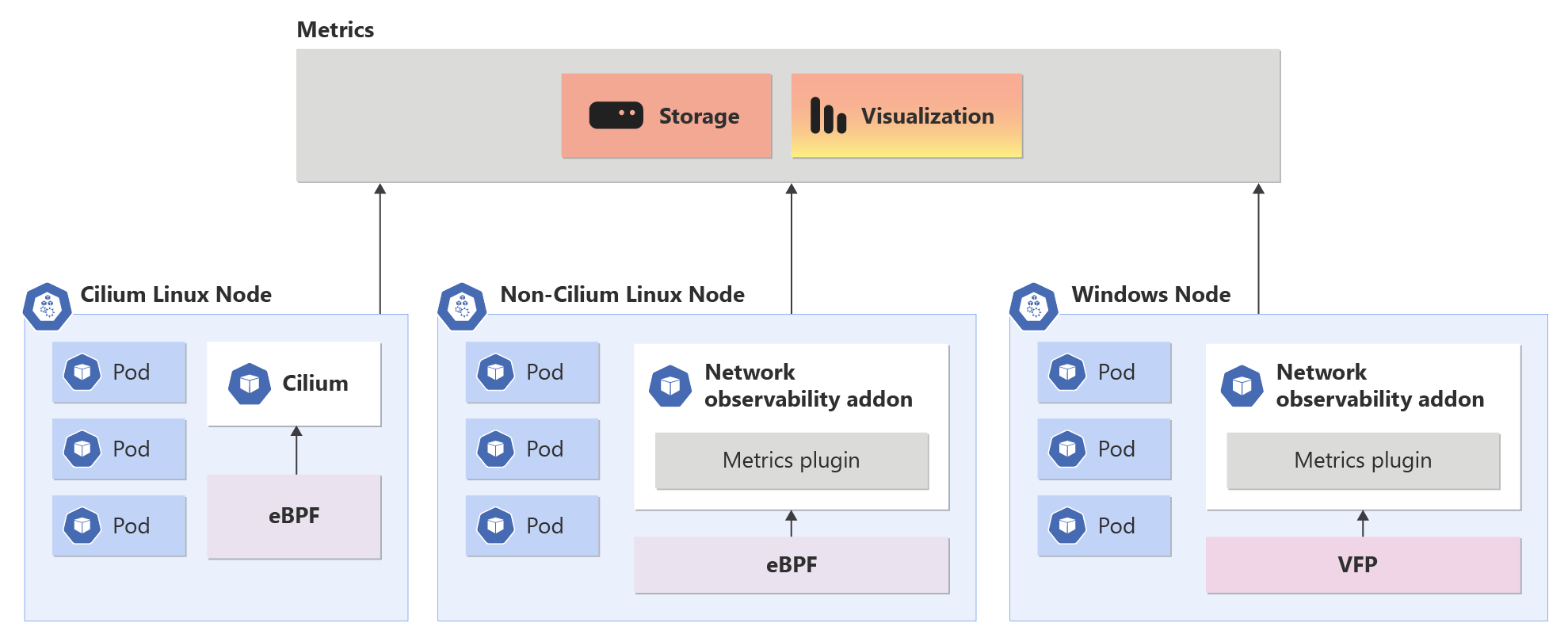
Visão geral do complemento Observabilidade de Rede no AKS
O complemento Observabilidade de Rede opera perfeitamente em planos de dados Cilium e não Cilium. Ele capacita os clientes com recursos de nível empresarial para DevOps e SecOps. Essa solução oferece uma maneira centralizada de monitorar problemas de rede em seu cluster para administradores de rede de cluster, administradores de segurança de cluster e engenheiros de DevOps.
Quando o complemento Observabilidade de Rede está habilitado, ele permite a coleta e a conversão de métricas úteis no formato Prometheus, que podem ser visualizadas no Grafana. O Azure disponibiliza ofertas para soluções gerenciadas do Prometheus e Grafana.
Prometheus e Grafana gerenciados pelo Azure:: um serviço gerenciado oferecido pelo Azure que cuida da infraestrutura e da manutenção do Prometheus e do Grafana, permitindo que você se concentre em configurar e visualizar suas métricas.
suporte a várias CNIs: o complemento de Observabilidade de Rede dá suporte a plug-ins de rede da CNI do Azure e Kubenet.
Métricas
Atualmente, o complemento de Observabilidade de Rede só dá suporte a métricas de nível de nó. Os planos de dados Cilium e Não-Cilium têm métricas diferentes, mas o painel do Grafana funciona perfeitamente para ambos.
Todas as métricas têm os seguintes rótulos:
clusterinstance(nome do nó)
No plano de dados não Cilium, o complemento Observabilidade de Rede fornece métricas em plataformas Linux e Windows. A tabela abaixo descreve as diferentes métricas geradas.
| Nome da métrica | Descrição | Etiquetas adicionais | Linux | Windows |
|---|---|---|---|---|
| networkobservability_forward_count | Número total de pacotes encaminhados | direction |
✅ | ✅ |
| networkobservability_forward_bytes | Número total de bytes encaminhados | direction |
✅ | ✅ |
| networkobservability_drop_count | Número total de pacotes descartados | direction, reason |
✅ | ✅ |
| networkobservability_drop_bytes | Número total de bytes descartados | direction, reason |
✅ | ✅ |
| networkobservability_tcp_state | Número de soquetes TCP ativos atualmente por estado de TCP. | state |
✅ | ✅ |
| networkobservability_tcp_connection_remote | Número de soquetes TCP ativos atualmente por porta/IP remoto. | address (IP), port |
✅ | ❌ |
| networkobservability_tcp_connection_stats | Estatísticas de conexão TCP. (por exemplo: ACKs atrasadas, TCPKeepAlive, TCPSackFailures) | statistic |
✅ | ✅ |
| networkobservability_tcp_flag_counters | Número de pacotes TCP por sinalizador. | flag |
❌ | ✅ |
| networkobservability_ip_connection_stats | Estatísticas de conexão de IP. | statistic |
✅ | ❌ |
| networkobservability_udp_connection_stats | Estatísticas de conexão UDP. | statistic |
✅ | ❌ |
| networkobservability_udp_active_sockets | Número de soquetes UDP ativos atualmente | ✅ | ❌ | |
| networkobservability_interface_stats | Estatísticas de interface. | InterfaceName, statistic |
✅ | ✅ |
Limitações
- Não há suporte para métricas de nível de pod.
Escala
São aplicadas determinadas limitações de escala quando você usa o Prometheus e o Grafana gerenciados pelo Azure. Para obter mais informações, confira Extrair métricas do Prometheus em escala no Azure Monitor
Próximas etapas
Para obter mais informações sobre o Serviço de Kubernetes do Azure (AKS), confira O que é o Serviço de Kubernetes do Azure (AKS)?.
Para criar um cluster do AKS com Observabilidade de Rede e Prometheus e Grafana gerenciados pelo Azure, confira Configuração da Observabilidade de Rede para o AKS (Serviço de Kubernetes do Azure) – Prometheus e Grafana gerenciados pelo Azure.

Azure Kubernetes Service