Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Neste artigo, você aprenderá a proteger o acesso de contêiner aos recursos para suas cargas de trabalho do Serviço de Kubernetes do Azure (AKS) usando os namespaces de usuário, AppArmor e os recursos de segurança do Linux seccomp integrados.
Visão geral da segurança de acesso de contêiner
Da mesma forma que deve conceder a usuários ou grupos os privilégios mínimos necessários, você também deve limitar os contêineres apenas às ações e aos processos necessários. Para minimizar o risco de ataques, evite configurar aplicativos e contêineres que exijam privilégios elevados ou acesso à raiz.
Você pode usar contextos de segurança de pod internos do Kubernetes para definir mais permissões, como o usuário ou grupo a ser executado como, as funcionalidades do Linux a serem expostas ou configuradas allowPrivilegeEscalation: false no manifesto do pod. Para obter mais práticas recomendadas, confira Proteger o acesso do pod a recursos.
Para melhorar o isolamento do host e diminuir o movimento lateral no Linux, você pode usar namespaces de usuário. Para um controle ainda mais granular das ações de contêiner, você pode usar recursos de segurança internos do Linux, como AppArmor e seccomp. Esses recursos ajudam a limitar as ações que os contêineres podem executar definindo os recursos de segurança do Linux no nível do nó e implementando-os por meio de um manifesto de pod.
Os recursos de segurança internos do Linux estão disponíveis apenas em nós e pods do Linux.
Observação
Atualmente, os ambientes do Kubernetes não são seguros para uso hostil multilocatário. Outros recursos de segurança, como Microsoft Defender para Contêineres, AppArmor, seccomp, namespaces de usuário, Admissão de Segurança de Pods ou Controle de Acesso Baseado em Papéis do Kubernetes (RBAC) para nós, bloqueiam ataques com eficiência.
Para a segurança verdadeira ao executar cargas de trabalho multilocatários hostis, confie apenas em um hipervisor. O domínio de segurança para o Kubernetes se torna o cluster inteiro, não um nó individual.
Para esses tipos de cargas de trabalho multilocatário hostis, você deve usar clusters fisicamente isolados.
Pré-requisitos para namespaces de usuário
- Um cluster do AKS existente. Se você não tiver um cluster, crie um usando a CLI do Azure, Azure PowerShell, ou o portal do Azure.
- Versão mínima do Kubernetes 1.33 para o plano de controle e nodos de trabalho. Se você não estiver usando o Kubernetes versão 1.33 ou superior, precisará atualizar sua versão do Kubernetes.
- Nós de trabalho que executam o Azure Linux 3.0 ou Ubuntu 24.04 para garantir que você atenda aos requisitos mínimos de pilha para habilitar namespaces de usuário. Se você precisar atualizar a versão do sistema operacional (SO), confira atualizar a versão do sistema operacional.
Limitações para namespaces de usuário
- O recurso namespaces de usuário é para o kernel do Linux e não tem suporte para pools de nós do Windows.
- Verifique a documentação do Kubernetes sobre namespaces de usuário para quaisquer outras limitações.
Visão geral dos namespaces de usuário
Os pods do Linux são executados usando vários namespaces por padrão: namespaces de rede para isolar a identidade de rede e um namespace do PID para isolar os processos. Um namespace de usuário (user_namespace) isola os usuários dentro do contêiner dos usuários no host. Ele também limita o escopo dos recursos e as interações do pod com o restante do sistema.
Os UIDs e GIDs dentro do contêiner são mapeados para usuários sem privilégios no host, portanto, toda a interação com o restante do host ocorre como aqueles UID e GID não privilegiados. Por exemplo, a raiz dentro do contêiner (UID 0) pode ser mapeada para o usuário 65536 no host. O Kubernetes cria o mapeamento para garantir que ele não se sobreponha a outros pods usando namespaces de usuário no sistema.
A implementação do Kubernetes tem alguns benefícios importantes. Para saber mais, consulte a documentação de Namespaces de Usuários do Kubernetes.
Habilitar namespaces de usuário
Crie um arquivo chamado
mypod.yamle copie-o para o manifesto a seguir. Para usar namespaces de usuário, o YAML precisa ter o campohostUsers: false.apiVersion: v1 kind: Pod metadata: name: userns spec: hostUsers: false containers: - name: shell command: ["sleep", "infinity"] image: debianImplante o aplicativo usando o comando
kubectl applye especifique o nome do manifesto YAML.kubectl apply -f mypod.yamlVerifique o status dos pods implantados usando o comando
kubectl get pods.kubectl get podsExecute no pod usando o comando
kubectl exec.kubectl exec -ti userns -- bashDentro do pod, verifique
/proc/self/uid_mapusando o seguinte comando:cat /proc/self/uid_mapA saída deve ter 65536 na última coluna. Por exemplo:
0 833617920 65536Essa saída indica que a raiz dentro do contêiner (UID 0) é mapeada para um usuário 65536 no host.
Vulnerabilidades e exposições comuns (CVEs) atenuadas por namespaces de usuário
A tabela a seguir descreve algumas vulnerabilidades e exposições comuns (CVEs) que são parcial ou totalmente atenuadas usando user_namespaces:
| CVE | Pontuação de severidade | Nível de gravidade |
|---|---|---|
| CVE-2019-5736 | 8,6 | High |
| CVE 2024-21262 | 8,6 | High |
| CVE 2022-0492 | 7,8 | High |
| CVE-2021-25741 | 8.1 / 8.8 | Alto/Alto |
| CVE-2017-1002101 | 9.6 / 8.8 | Crítico/Alto |
Tenha em mente que essa lista não é exaustiva. Para saber mais, consulte Kubernetes v1.33: Namespaces de usuário habilitados por padrão.
Pré-requisitos do AppArmor
- Um cluster do AKS existente. Se você não tiver um cluster, crie um usando a CLI do Azure, Azure PowerShell, ou o portal do Azure.
Observação
O Azure Linux 3.0 dá suporte ao AppArmor a partir da versão VHD de 7 de novembro de 2025.
Visão geral do AppArmor
Para limitar as ações de contêineres, use o módulo de segurança de kernel do Linux AppArmor. O AppArmor está disponível como parte do sistema operacional (OS) do nó do AKS subjacente e é habilitado por padrão. Você pode criar perfis AppArmor que restringem ações de leitura, gravação ou execução ou funções do sistema, como a montagem de sistemas de arquivos. Perfis padrão do AppArmor restringem o acesso a vários locais /proc e /sys e fornecem um meio para isolar logicamente os contêineres do nó subjacente. O AppArmor funciona para qualquer aplicativo executado no Linux, não apenas para os pods do Kubernetes.
Observação
Antes do Kubernetes v1.30, AppArmor era especificado por meio de anotações. Da versão 1.30 em diante, o AppArmor é especificado através do campo securityContext na especificação do pod. Para obter mais informações, consulte a documentação do Kubernetes AppArmor.
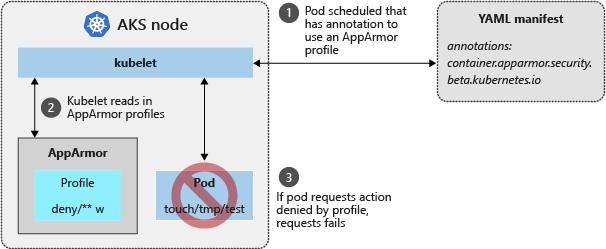
Assegurar os pods com o uso de AppArmor
Você pode especificar perfis AppArmor no nível do pod ou do contêiner. O perfil AppArmor do contêiner tem precedência sobre o perfil appArmor do pod. Se nenhum dos dois for especificado, o contêiner será executado sem restrições. Para obter mais informações sobre perfis AppArmor, consulte a documentação Protegendo um Pod com AppArmor Kubernetes.
Configurar um perfil personalizado do AppArmor
O exemplo a seguir cria um perfil que impede a gravação em arquivos de dentro de um contêiner.
Conecte-se por SSH a um nó do AKS.
Crie um arquivo chamado deny-write.profile e cole o seguinte conteúdo:
#include <tunables/global> profile k8s-apparmor-example-deny-write flags=(attach_disconnected) { #include <abstractions/base> file, # Deny all file writes. deny /** w, }Carregue o perfil AppArmor no nó.
# This example assumes that node names match host names, and are reachable via SSH. NODES=($( kubectl get node -o jsonpath='{.items[*].status.addresses[?(.type == "Hostname")].address}' )) for NODE in ${NODES[*]}; do ssh $NODE 'sudo apparmor_parser -q <<EOF #include <tunables/global> profile k8s-apparmor-example-deny-write flags=(attach_disconnected) { #include <abstractions/base> file, # Deny all file writes. deny /** w, } EOF' done
Implantar um pod com o perfil AppArmor personalizado
Implante um pod "Hello AppArmor" com o perfil para negar gravação.
apiVersion: v1 kind: Pod metadata: name: hello-apparmor spec: securityContext: appArmorProfile: type: Localhost localhostProfile: k8s-apparmor-example-deny-write containers: - name: hello image: busybox:1.28 command: [ "sh", "-c", "echo 'Hello AppArmor!' && sleep 1h" ]Aplique o manifesto do pod usando o
kubectl applycomando.kubectl apply -f hello-apparmor.yamlExecute no pod e verifique se o contêiner está em execução com o perfil AppArmor.
kubectl exec hello-apparmor -- cat /proc/1/attr/currentA saída deve mostrar o perfil AppArmor em uso. Por exemplo:
k8s-apparmor-example-deny-write (enforce)
Pré-requisitos de seccomp
- Um cluster do AKS existente. Se você não tiver um cluster, crie um usando a CLI do Azure, Azure PowerShell, ou o portal do Azure.
- É necessário registrar o sinalizador do recurso
KubeletDefaultSeccompProfilePreviewpara usar perfis seccomp padrão em seus agrupamentos de nós.
Registrar o sinalizador de recurso KubeletDefaultSeccompProfilePreview
Importante
As versões prévias de recursos do AKS estão disponíveis em uma base de autoatendimento e aceitação. As versões prévias são fornecidas "como estão" e "conforme disponíveis" e são excluídas dos contratos de nível de serviço e da garantia limitada. As versões prévias do AKS são parcialmente cobertas pelo suporte ao cliente em uma base de melhor esforço. Dessa forma, esses recursos não são destinados ao uso em produção. Para obter mais informações, consulte os seguintes artigos de suporte:
Registre o sinalizador de recurso
KubeletDefaultSeccompProfilePreviewusando o comandoaz feature register.az feature register --namespace "Microsoft.ContainerService" --name "KubeletDefaultSeccompProfilePreview"Demora alguns minutos para o status exibir Registrado.
Verifique o status do registro usando o comando
az feature show.az feature show --namespace "Microsoft.ContainerService" --name "KubeletDefaultSeccompProfilePreview"Quando o status reflete Registrado, atualize o registro do provedor de recursos Microsoft.ContainerService usando o comando
az provider register.az provider register --namespace Microsoft.ContainerService
Limitações de seccomp
- O AKS só dá suporte aos perfis seccomp padrão (
RuntimeDefaulteUnconfined). Não há suporte para perfis de seccomp personalizados. -
SeccompDefaultnão é um parâmetro com suporte para pools de nós do Windows.
Visão geral dos perfis de seccomp padrão (versão prévia)
Enquanto AppArmor funciona para qualquer aplicativo Linux, o seccomp (ou computação segura) funciona no nível do processo. O Seccomp também é um módulo de segurança do kernel do Linux. O containerd runtime usado pelos nós do AKS fornece suporte nativo para seccomp. Com o seccomp, você pode limitar as chamadas do sistema de um contêiner. O Seccomp estabelece uma camada extra de proteção contra vulnerabilidades comuns de chamada do sistema exploradas por atores mal-intencionados e permite que você especifique um perfil padrão para todas as cargas de trabalho no nó.
Você pode aplicar perfis seccomp padrão usando configurações de nó personalizadas ao criar um novo pool de nós do Linux. O AKS dá suporte aos valores RuntimeDefault e Unconfined. Algumas cargas de trabalho podem exigir um número menor de restrições de syscall do que outras. Isso significa que eles podem falhar durante o tempo de execução com o perfil RuntimeDefault. Para atenuar essa falha, você pode especificar o perfil de Unconfined. Se sua carga de trabalho exigir um perfil personalizado, consulte Configurar um perfil seccomp personalizado.
Restringir chamadas do sistema de contêiner com seccomp
-
Siga as etapas para aplicar um perfil seccomp na configuração do kubelet especificando
"seccompDefault": "RuntimeDefault". - Conecte-se ao host.
- Verifique se a configuração foi aplicada aos nós.
Resolver falhas de carga de trabalho com seccomp
Quando SeccompDefault está habilitado, o perfil de seccomp padrão do runtime do contêiner é usado por padrão para todas as cargas de trabalho agendadas no nó, o que pode fazer com que as cargas de trabalho falhem devido a chamadas bloqueadas. Se ocorrer uma falha de carga de trabalho, você poderá ver erros como:
- A carga de trabalho está saindo inesperadamente depois que o recurso está habilitado, com erro de "permissão negada".
- Mensagens de erro seccomp também podem ser vistas em auditoria ou syslog substituindo SCMP_ACT_ERRNO por SCMP_ACT_LOG no perfil padrão.
Se você tiver esses erros, recomendamos que você altere seu perfil seccomp para Unconfined.
Unconfined não impõe restrições às chamadas, permitindo que todas as chamadas do sistema sejam executadas.
Visão geral dos perfis de seccomp personalizados
Com um perfil seccomp personalizado, você tem um controle mais granular sobre as chamadas de sistema restritas dos seus contêineres. Você pode criar seus próprios perfis seccomp:
- Usando filtros para especificar quais ações permitir ou negar.
- Anotar em um manifesto YAML do pod para associação ao filtro de seccomp.
Observação
Para obter ajuda com a solução de problemas de seu perfil seccomp, consulte Solucionar problemas de configuração de perfil seccomp no AKS (Serviço de Kubernetes do Azure).
Configurar um perfil de seccomp personalizado
Para ver o seccomp em ação, crie um filtro que impeça a alteração das permissões em um arquivo.
Conecte-se por SSH a um nó do AKS.
Crie um filtro de seccomp chamado /var/lib/kubelet/seccomp/prevent-chmod.
Copie e cole o seguinte conteúdo:
{ "defaultAction": "SCMP_ACT_ALLOW", "syscalls": [ { "name": "chmod", "action": "SCMP_ACT_ERRNO" }, { "name": "fchmodat", "action": "SCMP_ACT_ERRNO" }, { "name": "chmodat", "action": "SCMP_ACT_ERRNO" } ] }Na versão 1.19 e posterior, você precisa configurar:
{ "defaultAction": "SCMP_ACT_ALLOW", "syscalls": [ { "names": ["chmod","fchmodat","chmodat"], "action": "SCMP_ACT_ERRNO" } ] }No computador local, crie um manifesto de pod chamado aks-seccomp.yaml e cole o conteúdo a seguir. Esse manifesto define uma anotação para
seccomp.security.alpha.kubernetes.ioe faz referência ao filtro prevent-chmod existente.apiVersion: v1 kind: Pod metadata: name: chmod-prevented annotations: seccomp.security.alpha.kubernetes.io/pod: localhost/prevent-chmod spec: containers: - name: chmod image: mcr.microsoft.com/dotnet/runtime-deps:6.0 command: - "chmod" args: - "777" - /etc/hostname restartPolicy: NeverNa versão 1.19 e posterior, você precisa configurar:
apiVersion: v1 kind: Pod metadata: name: chmod-prevented spec: securityContext: seccompProfile: type: Localhost localhostProfile: prevent-chmod containers: - name: chmod image: mcr.microsoft.com/dotnet/runtime-deps:6.0 command: - "chmod" args: - "777" - /etc/hostname restartPolicy: NeverImplante o pod de exemplo usando o
kubectl applycomando:kubectl apply -f ./aks-seccomp.yamlExiba o status do pod usando o
kubectl get podscomando.kubectl get podsNa saída, você deverá ver que o pod reporta um erro. O comando
chmodé impedido de ser executado pelo filtro seccomp, conforme mostrado na saída de exemplo:NAME READY STATUS RESTARTS AGE chmod-prevented 0/1 Error 0 7s
Opções de perfil de segurança seccomp
Os perfis de segurança seccomp são um conjunto de chamadas syscalls definidas permitidas ou restritas. A maioria dos runtimes de contêiner tem um perfil seccomp padrão semelhante, se não o mesmo que o que o Docker usa. Para obter mais informações sobre perfis disponíveis, consulte os perfis padrão de seccomp do Docker ou containerd.
O AKS usa o perfil de seccomp padrão de containerd para RuntimeDefault quando você configura o seccomp usando a configuração de nó personalizado.
Chamadas syscalls significativas bloqueadas pelo perfil padrão
O Docker e o containerd mantêm listas de chamadas de sistema seguras. Quando são feitas alterações no Docker e no containerd, o AKS atualiza a configuração padrão para corresponder. As atualizações dessa lista podem causar falha na carga de trabalho. Para ver as atualizações de versão, consulte as notas de versão do AKS.
A tabela a seguir lista syscalls significativas que são efetivamente bloqueadas porque não estão na lista de permissões. Essa lista não é completa. Se a sua carga de trabalho exigir qualquer uma das syscalls bloqueadas, não use o perfil seccomp RuntimeDefault.
| Chamada de syscall bloqueada | Descrição |
|---|---|
acct |
Syscall de contabilidade, que pode permitir que os contêineres desabilitem seus próprios limites de recursos ou a contabilização de processos. Também fechado por CAP_SYS_PACCT. |
add_key |
Impedir que os contêineres usem o keyring do kernel, que não é espaçado por nomes. |
bpf |
Negar o carregamento de programas bpf potencialmente persistentes no kernel, já fechado por CAP_SYS_ADMIN. |
clock_adjtime |
A hora/data não está com o nome espaçado. Também fechado por CAP_SYS_TIME. |
clock_settime |
A hora/data não está com o nome espaçado. Também fechado por CAP_SYS_TIME. |
clone |
Negar a clonagem de novos namespaces. Também fechado por sinalizadores CAP_SYS_ADMIN for CLONE_*, exceto CLONE_NEWUSER. |
create_module |
Negar manipulação e funções em módulos de kernel. Obsoleto. Também fechado por CAP_SYS_MODULE. |
delete_module |
Negar manipulação e funções em módulos de kernel. Também fechado por CAP_SYS_MODULE. |
finit_module |
Negar manipulação e funções em módulos de kernel. Também fechado por CAP_SYS_MODULE. |
get_kernel_syms |
Negar a recuperação de símbolos de kernel e módulo exportados. Obsoleto. |
get_mempolicy |
Syscall que modifica a memória do kernel e as configurações NUMA. Já fechado por CAP_SYS_NICE. |
init_module |
Negar manipulação e funções em módulos de kernel. Também fechado por CAP_SYS_MODULE. |
ioperm |
Impedir que os contêineres modifiquem os níveis de privilégio de E/S do kernel. Já fechado por CAP_SYS_RAWIO. |
iopl |
Impedir que os contêineres modifiquem os níveis de privilégio de E/S do kernel. Já fechado por CAP_SYS_RAWIO. |
kcmp |
Restrinja os recursos de inspeção do processo, já bloqueados por remoção CAP_SYS_PTRACE. |
kexec_file_load |
Irmã syscall de kexec_load que faz a mesma coisa, argumentos ligeiramente diferentes. Também fechado por CAP_SYS_BOOT. |
kexec_load |
Negue o carregamento de um novo kernel para execução posterior. Também fechado por CAP_SYS_BOOT. |
keyctl |
Impedir que os contêineres usem o keyring do kernel, que não é espaçado por nomes. |
lookup_dcookie |
Syscall de rastreamento/criação de perfil, que pode vazar informações no host. Também fechado por CAP_SYS_ADMIN. |
mbind |
Syscall que modifica a memória do kernel e as configurações NUMA. Já fechado por CAP_SYS_NICE. |
mount |
Negar montagem, já fechado por CAP_SYS_ADMIN. |
move_pages |
Syscall que modifica a memória do kernel e as configurações NUMA. |
nfsservctl |
Negar interação com o daemon nfs do kernel. Obsoleto desde o Linux 3.1. |
open_by_handle_at |
Causa de uma fuga de contêiner antiga. Também fechado por CAP_DAC_READ_SEARCH. |
perf_event_open |
Syscall de rastreamento/criação de perfil, que pode vazar informações no host. |
personality |
Impedir que o contêiner habilite a emulação do BSD. Não inerentemente perigoso, mas mal testado, potencial para vulns kernel. |
pivot_root |
Negar pivot_root, deve ser uma operação privilegiada. |
process_vm_readv |
Restrinja os recursos de inspeção do processo, já bloqueados por remoção CAP_SYS_PTRACE. |
process_vm_writev |
Restrinja os recursos de inspeção do processo, já bloqueados por remoção CAP_SYS_PTRACE. |
ptrace |
Syscall de rastreamento/criação de perfil. Bloqueado nas versões do kernel do Linux antes da 4.8 para evitar o bypass do seccomp. Os processos arbitrários de rastreamento/criação de perfil já estão bloqueados removendo CAP_SYS_PTRACE, pois podem vazar informações sobre o host. |
query_module |
Negar manipulação e funções em módulos de kernel. Obsoleto. |
quotactl |
Syscall de cotação, que pode permitir que os contêineres desabilitem seus próprios limites de recursos ou a contabilização de processos. Também fechado por CAP_SYS_ADMIN. |
reboot |
Não permita que os contêineres reinicializem o host. Também fechado por CAP_SYS_BOOT. |
request_key |
Impedir que os contêineres usem o keyring do kernel, que não é espaçado por nomes. |
set_mempolicy |
Syscall que modifica a memória do kernel e as configurações NUMA. Já fechado por CAP_SYS_NICE. |
setns |
Negar associar um thread a um namespace. Também fechado por CAP_SYS_ADMIN. |
settimeofday |
A hora/data não está com o nome espaçado. Também fechado por CAP_SYS_TIME. |
stime |
A hora/data não está com o nome espaçado. Também fechado por CAP_SYS_TIME. |
swapon |
Negar a troca inicial/parada para o arquivo/dispositivo. Também fechado por CAP_SYS_ADMIN. |
swapoff |
Negar a troca inicial/parada para o arquivo/dispositivo. Também fechado por CAP_SYS_ADMIN. |
sysfs |
Chamada obsoleta. |
_sysctl |
Obsoleto, substituído por /proc/sys. |
umount |
Deve ser uma operação privilegiada. Também fechado por CAP_SYS_ADMIN. |
umount2 |
Deve ser uma operação privilegiada. Também fechado por CAP_SYS_ADMIN. |
unshare |
Negar a clonagem de novos namespaces para processos. Também controlado por CAP_SYS_ADMIN (exceto por unshare --user). |
uselib |
Chamadas mais antigas relacionadas a bibliotecas compartilhadas, não usadas por muito tempo. |
userfaultfd |
Tratamento de falhas de página do userspace, em grande parte necessário para migração de processo. |
ustat |
Chamada obsoleta. |
vm86 |
Na máquina virtual do modo real do kernel x86. Também fechado por CAP_SYS_ADMIN. |
vm86old |
Na máquina virtual do modo real do kernel x86. Também fechado por CAP_SYS_ADMIN. |
Conteúdo relacionado
Para saber mais sobre como proteger o cluster do AKS, confira os seguintes artigos: