Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
APLICA-SE A: todas as camadas do Gerenciamento de API
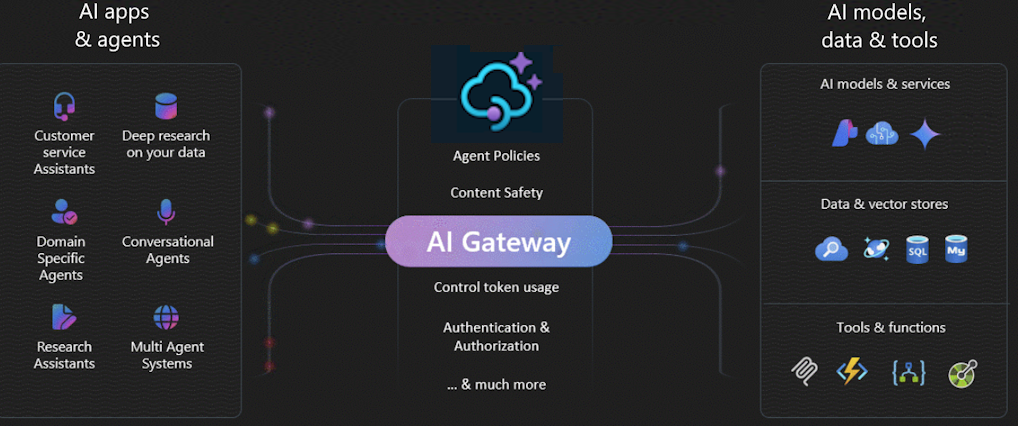
O gateway AI em Gerenciamento de API do Azure é um conjunto de recursos que ajudam você a gerenciar seus back-ends de IA de forma eficaz. Use esses recursos para proteger, dimensionar, monitorar e controlar modelos de IA, agentes e ferramentas que dão suporte a seus aplicativos inteligentes e cargas de trabalho.
Use o portal de IA para gerenciar uma ampla variedade de terminais de IA, incluindo:
APIs de modelo do Lanaguage que estão em conformidade com um dos seguintes esquemas de API:
- API de Conclusões ou Respostas de Chat do OpenAI
- Anthropic Messages API (atualmente com suporte nos níveis de Gerenciamento de API v2)
Os modelos podem ser implantados em vários ambientes, incluindo Microsoft Foundry ou provedores não Microsoft, como o Amazon Bedrock.
Servidores MCP remotos e APIs de agente A2A
Modelos e pontos de extremidade autogerenciados
Observação
O gateway de IA, incluindo recursos de servidor MCP, estende o gateway de API existente do Gerenciamento de API; não é uma oferta separada. Os recursos de governança e desenvolvedor relacionados estão no Centro de API do Azure.
Observação
Novo! Agora, o gateway de IA pode ser integrado diretamente ao Microsoft Foundry, permitindo que você governe modelos de IA, agentes e ferramentas de dentro do ambiente do Foundry. Saiba mais na seção AI gateway na Microsoft Foundry.
Por que usar um gateway de IA?
A adoção de IA em organizações envolve várias fases:
- Definindo requisitos e avaliando modelos de IA
- Criando aplicativos e agentes de IA que precisam de acesso a modelos e serviços de IA
- Operacionalizando e implantando aplicativos de IA e back-ends na produção
À medida que a adoção da IA amadurece, especialmente em grandes empresas, o gateway de IA ajuda a enfrentar os principais desafios. Ele ajuda a:
- Autenticar e autorizar o acesso aos serviços de IA
- Balanceamento de carga em vários terminais de IA
- Monitorar e registrar interações de IA
- Gerenciar o uso de token e cotas em vários aplicativos
- Habilitar o autoatendimento para equipes de desenvolvedores
Controle e mediação de tráfego
Usando o gateway de IA, você pode:
- Importe e configure rapidamente pontos de extremidade LLM compatíveis com OpenAI ou passagem como APIs
- Gerenciar modelos implantados em Microsoft Foundry ou provedores como o Amazon Bedrock
- Administrar finalizações de chat, respostas e APIs em tempo real
- Exponha suas APIs REST existentes como servidores MCP e ofereça suporte à passagem para servidores MCP
- Importar e gerenciar APIs de agente A2A (versão prévia)
Por exemplo, para integrar um modelo implantado no Microsoft Foundry ou em outro provedor, o Gerenciamento de API fornece assistentes simplificados para importar o esquema e configurar a autenticação para o ponto de extremidade de IA usando uma identidade gerenciada, removendo a necessidade de configuração manual. Na mesma experiência amigável, você pode pré-configurar políticas para escalabilidade, segurança e observabilidade da API.

Mais informações:
- Porte uma API de Microsoft Foundry
- Importar uma API de modelo de idioma
- Expor uma API REST como um servidor MCP
- Expor e controlar um servidor MCP existente
- Importar uma API de agente A2A
Desempenho e escalabilidade
Um dos principais recursos em serviços de IA gerativos são tokens. O Microsoft Foundry e outros provedores atribuem quotas para as suas implementações de modelos como TPM (tokens por minuto). Você distribui esses tokens entre seus consumidores de modelo, como aplicativos diferentes, equipes de desenvolvedores ou departamentos dentro da empresa.
Se você tiver um único aplicativo se conectando a um back-end de serviço de IA, poderá gerenciar o consumo de token com um limite de TPM definido diretamente na implantação do modelo. No entanto, quando seu portfólio de aplicativos cresce, você pode ter vários aplicativos chamando pontos de extremidade de serviço de IA ou individuais. Esses pontos de extremidade podem ser instâncias pagas conforme o uso ou Unidades de Taxa de Transferência Provisionadas (PTU). Você precisa garantir que um aplicativo não use toda a cota do TPM e impedir que outros aplicativos acessem os back-ends de que precisam.
Limitação de taxa de token e cotas de uso de tokens
Configure uma política de limite de token em suas APIs LLM para gerenciar e impor limites por consumidor de API com base no uso de tokens de serviço de IA. Usando essa política, você pode definir um limite de TPM ou uma cota de token durante um período especificado, como por hora, diária, semanal, mensal ou anual.
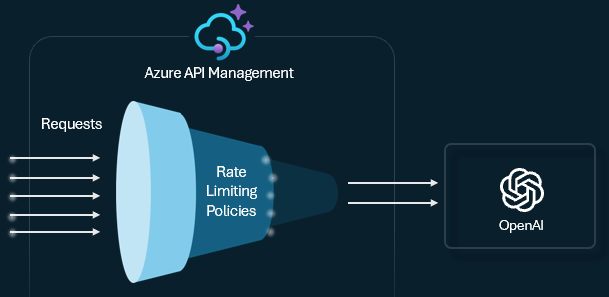
Essa política fornece flexibilidade para atribuir limites baseados em token em qualquer chave de contador, como chave de assinatura, endereço IP de origem ou uma chave arbitrária definida por meio de uma expressão de política. A política também permite o pré-cálculo de tokens de solicitações no lado do API Management do Azure, minimizando solicitações desnecessárias para o back-end do serviço de IA se a solicitação já exceder o limite.
O exemplo básico a seguir demonstra como definir um limite de TPM de 500 por chave de assinatura:
<llm-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</llm-token-limit>
Mais informações:
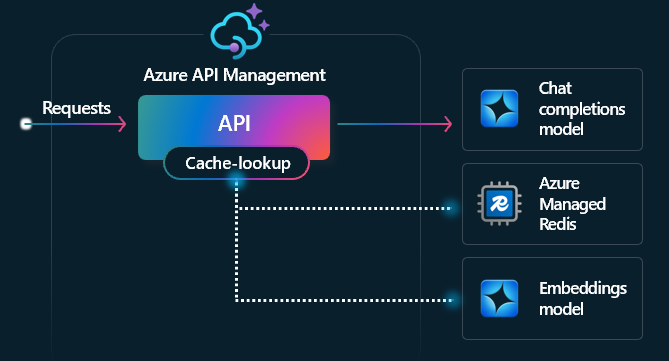
Cache semântico
O cache semântico é uma técnica que melhora o desempenho das APIs LLM ao armazenar em cache os completamentos de prompts anteriores e reutilizá-los por meio da comparação da proximidade entre o vetor do prompt e solicitações anteriores. Essa técnica reduz o número de chamadas feitas ao back-end do serviço de IA, melhora os tempos de resposta para os usuários finais e pode ajudar a reduzir os custos.
No Gerenciamento de API, habilite o cache semântico usando Azure Redis Gerenciado ou outro cache externo compatível com o RediSearch e integrado ao Gerenciamento de API do Azure. Usando a API de embeddings, as políticas llm-semantic-cache-store e llm-semantic-cache-lookup armazenam e recuperam do cache completions de prompt que são semanticamente semelhantes. Essa abordagem garante a reutilização de conclusões, resultando em redução do consumo de token e melhor desempenho de resposta.
Mais informações:
- Configurar um cache externo no Gerenciamento de API do Azure
- Habilitar cache semântico para APIs de IA no Gerenciamento de API do Azure
Recursos de dimensionamento nativos no Gerenciamento de APIs
O Gerenciamento de API também fornece recursos de dimensionamento internos para ajudar o gateway a lidar com grandes volumes de solicitações para suas APIs de IA. Esses recursos incluem a adição automática ou manual de unidades de escala de gateway e a adição de gateways regionais para implantações multirregionais. Recursos específicos dependem da camada de serviço de Gerenciamento de API.
Mais informações:
- Atualizar e dimensionar uma instância de Gerenciamento de API
- Implantar uma instância de Gerenciamento de API em várias regiões
Observação
Embora o Gerenciamento de API possa dimensionar a capacidade do gateway, você também precisa dimensionar e distribuir o tráfego para seus back-ends de IA para acomodar o aumento da carga (consulte a seção Resiliência ). Por exemplo, para aproveitar a distribuição geográfica do sistema em uma configuração de várias regiões, implante serviços de IA de back-end nas mesmas regiões que os gateways de Gerenciamento de API.
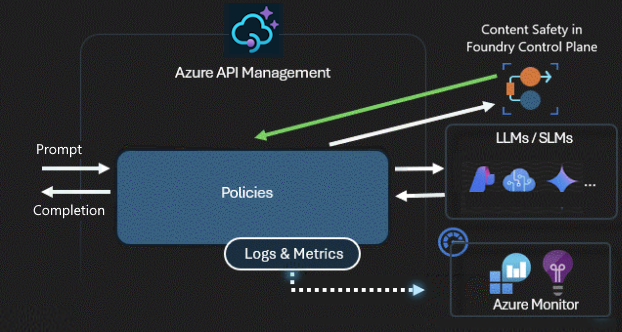
Segurança e segurança
Um gateway de IA protege e controla o acesso às APIs de IA. Usando o gateway de IA, você pode:
- Use identidades gerenciadas para autenticar em serviços de IA no Azure, portanto, você não precisa de chaves de API para autenticação
- Configurar a autorização do OAuth para aplicativos e agentes de IA para acessar APIs ou servidores MCP usando o gerenciador de credenciais do Gerenciamento de API
- Aplique políticas para moderar automaticamente os prompts de LLM usando Segurança de Conteúdo de IA do Azure
Mais informações:
- Autenticar e autorizar o acesso às APIs LLM
- Sobre as credenciais de API e o gerenciador de credenciais
- Impor verificações de segurança de conteúdo em solicitações de LLM
- Proteger o acesso aos servidores MCP
Resiliency
Um desafio ao criar aplicativos inteligentes é garantir que os aplicativos sejam resilientes a falhas de back-end e possam lidar com cargas altas. Ao configurar seus pontos de extremidade LLM com back-ends no API Management do Azure, você pode balancear a carga entre eles. Você também pode definir regras de disjuntor para interromper o encaminhamento de solicitações para back-ends do serviço de IA se elas não estiverem respondendo.
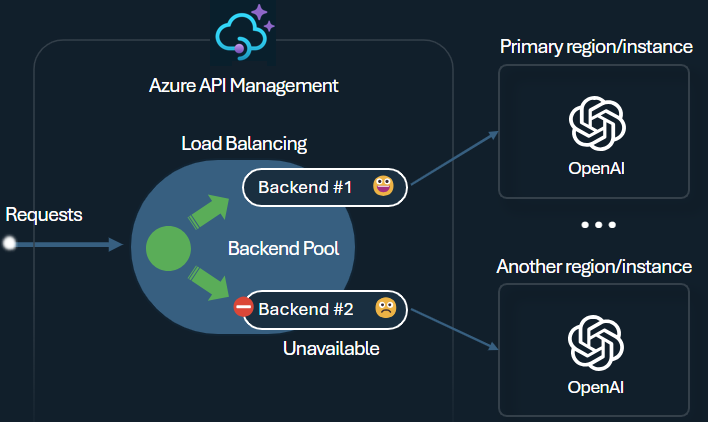
Balanceador de carga
O balanceador de carga de back-end dá suporte ao balanceamento de carga round robin, ponderado, baseado em prioridade e com reconhecimento de sessão. Você pode definir uma estratégia de distribuição de carga que atenda aos seus requisitos específicos. Por exemplo, defina prioridades na configuração do balanceador de carga para garantir a utilização ideal de endpoints específicos do Microsoft Foundry, especialmente aqueles comprados como instâncias PTU.
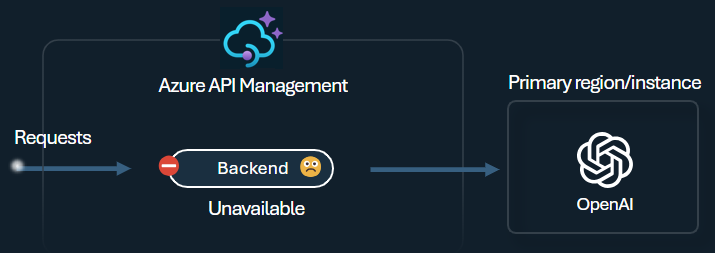
Disjuntor
O disjuntor de back-end apresenta a duração dinâmica da viagem, aplicando valores do cabeçalho Retry-After fornecido pelo back-end. Esse recurso garante a recuperação precisa e oportuna dos back-ends, maximizando a utilização de seus back-ends de prioridade.
Mais informações:
Observabilidade e governança
O Gerenciamento de API fornece recursos abrangentes de monitoramento e análise para acompanhar padrões de uso de token, otimizar custos, garantir a conformidade com suas políticas de governança de IA e solucionar problemas com suas APIs de IA. Use estes recursos para:
- Registre solicitações e resultados em Azure Monitor.
- Rastreie métricas de token por consumidor no Application Insights.
- Exiba o painel de monitoramento interno.
- Configurar políticas com expressões personalizadas.
- Gerenciar cotas de token entre aplicativos.
Por exemplo, você pode emitir métricas de token usando a política llm-emit-token-metric e adicionar dimensões personalizadas que você pode usar para filtrar a métrica em Azure Monitor. O exemplo a seguir emite métricas de token com dimensões para endereço IP do cliente, ID de API e ID de usuário (de um cabeçalho personalizado):
<llm-emit-token-metric namespace="llm-metrics">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</llm-emit-token-metric>
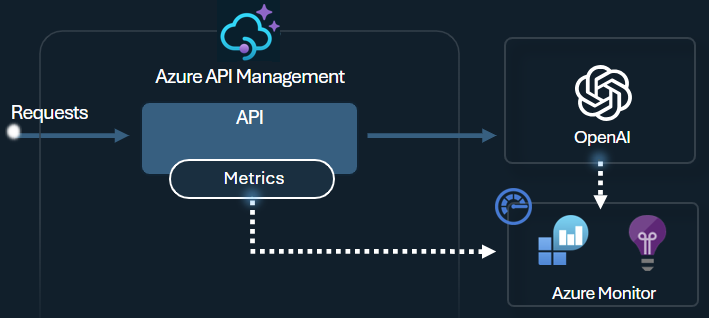
Além disso, habilita o registro em log para APIs de LLM no API Management do Azure para controlar o uso, as solicitações e as conclusões do token para cobrança e auditoria. Depois de habilitar o registro em log, você poderá analisar os logs no Application Insights e usar um painel interno no Gerenciamento de API para exibir padrões de consumo de token em suas APIs de IA.

Mais informações:
Experiência do desenvolvedor
Use o gateway de IA e Azure Centro de API para simplificar o desenvolvimento e a implantação de suas APIs de IA e servidores MCP. Além das experiências de importação e configuração de política amigáveis para cenários comuns de IA no Gerenciamento de API, você pode aproveitar:
- Fácil registro de APIs e servidores MCP em um catálogo organizacional no Centro de API Azure
- Acesso à API de autosserviço e ao servidor MCP por meio de portais de desenvolvedor no Gerenciamento de API e Centro de API.
- Kit de ferramentas de política de Gerenciamento de API para personalização
- Conector do Copilot Studio do Centro de API para estender os recursos dos agentes de IA
Mais informações:
- Registrar e descobrir servidores MCP no Centro de API
- Sincronizar APIs e servidores MCP entre o Gerenciamento de API e o Centro de API
- Portal do desenvolvedor de Gerenciamento de API
- Portal do Centro de API
- Gerenciamento de API do Azure policy toolkit
- conector API Center Copilot Studio
Gateway de IA no Microsoft Foundry (versão prévia)
Agora você pode integrar o gateway de IA diretamente ao Microsoft Foundry, permitindo que você governe o tráfego de IA em seu ambiente do Foundry. Ao criar ou associar uma instância de gateway de IA ao recurso do Foundry, você pode controlar, proteger e monitorar seus recursos do Foundry por meio do gateway.
Models: configure cotas de token e limites de taxa diretamente na interface foundry para todas as implantações de modelo, incluindo Azure OpenAI e outros provedores.
Agents: Registrar agentes em execução em qualquer lugar - Azure, outras nuvens ou em ambientes locais - no plano de controle Foundry para inventário e governança centralizados. Exiba a telemetria no Foundry ou no Application Insights e aplique políticas como limitação ou segurança de conteúdo.
Ferramentas: registre as ferramentas mcp hospedadas em qualquer ambiente para governança e descoberta automáticas. As ferramentas aparecem no inventário do Foundry, prontas para consumo por agentes.
Para cenários avançados, como políticas personalizadas, rede corporativa ou gateways federados, acesse toda a experiência de Gerenciamento de API do Azure, mantendo a continuidade com recursos gerenciados pelo Foundry.
Mais informações:
- Habilitar o gateway de IA no Microsoft Foundry
- Registrar agentes personalizados no Foundry
- Gerenciar ferramentas com o gateway de IA
- Conectar um gateway de IA ao Serviço de Agente do Foundry
Acesso antecipado aos recursos do gateway de IA
Como cliente de gestão de APIs, você pode obter acesso antecipado a novas funcionalidades por meio do canal de lançamento do Gateway de IA. Esse acesso permite que você experimente as inovações mais recentes do gateway de IA antes que elas estejam geralmente disponíveis e forneça comentários para ajudar a moldar o produto.
Mais informações:
Laboratórios e exemplos de código
- Laboratórios de recursos do gateway de IA
- Workshop de gateway de IA
- Azure OpenAI com Gerenciamento de API (Node.js)
- Python código de exemplo
- Padrão de projeto de gateway de IA unificado
Arquitetura e design
- Arquitetura de referência do gateway de IA usando o Gerenciamento de API
- Acelerador de zona de aterrissagem do gateway do hub de IA
- Planejamento e implementação de uma solução de gateway com recursos Azure OpenAI
- Usar um gateway na frente de várias implantações do Azure OpenAI
Conteúdo relacionado
- Blog: o gateway de IA no Gerenciamento de API do Azure agora está disponível no Microsoft Foundry
- Blog: Introdução aos recursos de IA no Gerenciamento de API do Azure
- Blog: integrando Azure Content Safety ao Gerenciamento de API
- Treinamento: gerenciar suas APIs de IA generativas
- Balanceamento de carga inteligente para endpoints da OpenAI