Ideias de soluções
Este artigo descreve uma ideia de solução. Seu arquiteto de nuvem pode usar essa orientação para ajudar a visualizar os principais componentes para uma implementação típica dessa arquitetura. Use este artigo como ponto de partida para projetar uma solução bem arquitetada que se alinhe aos requisitos específicos de sua carga de trabalho.
Este artigo é um guia de implementação e um cenário de exemplo que fornece uma implantação de exemplo da solução descrita em Implementar conversão de fala em texto personalizada:
Arquitetura
Baixe um Arquivo Visio dessa arquitetura.
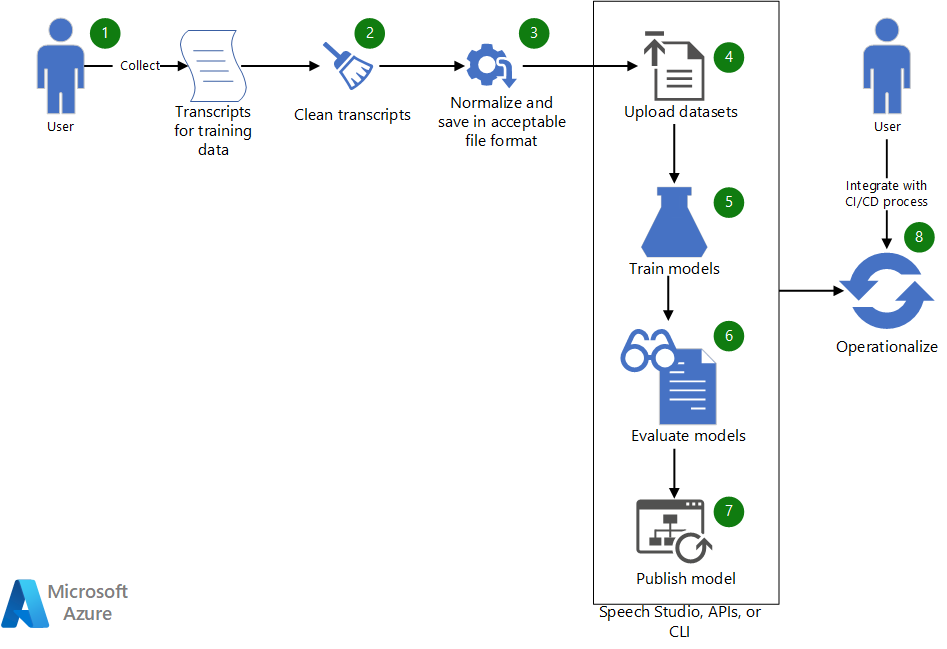
Workflow
- Colete transcrições existentes a usar para treinar um modelo de fala personalizado.
- Se as transcrições estiverem no formato WebVTT ou SRT, limpe os arquivos para que eles incluam apenas as partes de texto das transcrições.
- Normalize o texto removendo qualquer pontuação, separando palavras repetidas e soletrando valores numéricos grandes. Você pode combinar várias transcrições limpas em uma para criar um conjunto de dados. Da mesma forma, crie um conjunto de dados para teste.
- Depois que os conjuntos de dados estiverem prontos, carregue-os usando o Speech Studio. Como alternativa, se o conjunto de dados estiver em um armazenamento de blobs, você poderá usar a API de conversão de fala em texto do Azure e a CLI de Fala. Na API e na CLI, você pode passar ao URI do conjunto de dados uma entrada para criar um conjunto de dados para treinar e testar o modelo.
- No Speech Studio ou por meio da API ou da CLI, use o novo conjunto de dados para treinar um modelo de fala personalizado.
- Avalie o modelo recém-treinado em relação ao conjunto de dados de teste.
- Se o desempenho do modelo personalizado atender às suas expectativas de qualidade, publique-o para usar na transcrição de fala. Caso contrário, use o Speech Studio para examinar a taxa de erros de palavra (WER) e os detalhes de erro específicos, e determine quais dados adicionais são necessários para o treinamento.
- Use as APIs e a CLI para ajudar a operacionalizar o processo de criação, avaliação e implantação do modelo.
Componentes
- Azure Machine Learning é um serviço de nível empresarial para o ciclo de vida do aprendizado de máquina de ponta a ponta.
- Serviços de IA do Azure são um conjunto de APIs, SDKs e serviços que pode ajudar a tornar seus aplicativos mais inteligentes, atrativos e detectáveis.
- O Speech Studio é um conjunto de ferramentas baseadas na interface do usuário para criar e integrar recursos do serviço de Fala de IA do Azure nos seus aplicativos. Veja uma alternativa para os conjuntos de dados de treinamento. Também é usado para examinar os resultados do treinamento.
- API REST de Fala em Texto é uma API que você pode usar para carregar seus próprios dados, testar e treinar um modelo personalizado, comparar a precisão entre os modelos e implantar um modelo em um ponto de extremidade personalizado. Você também pode usá-lo para operacionalizar a criação, a avaliação e a implantação do modelo.
- CLI de Fala é uma ferramenta da linha de comando para usar o serviço de Fala sem a necessidade de codificação. Fornece uma alternativa para criar e treinar conjuntos de dados, além de operacionalizar seus processos.
Detalhes do cenário
Este artigo baseia-se no seguinte cenário fictício:
Contoso, Ltd., é uma empresa de mídia que faz transmissões e comentários sobre eventos olímpicos. Como parte do contrato de transmissão, a Contoso fornece transcrição de eventos para acessibilidade e mineração de dados.
A Contoso quer usar o serviço de Fala do Azure para fornecer legendagem ao vivo e transcrição de áudio para os eventos olímpicos. A Contoso emprega homens e mulheres comentaristas de todo o mundo que falam com sotaques diversos. Além disso, cada esporte individual tem uma terminologia específica que pode dificultar a transcrição. Este artigo descreve o processo de desenvolvimento de aplicativos para este cenário: fornecendo legendagem para um aplicativo que precisa fornecer uma transcrição precisa dos eventos.
A Contoso já tem esses componentes de pré-requisito necessários em vigor:
- Transcrições geradas por pessoas para eventos olímpicos anteriores. As transcrições representam comentários de diferentes esportes e comentaristas diversos.
- Um recurso dos Serviços Cognitivos do Azure. Você pode criar um no portal do Azure.
Desenvolver um aplicativo personalizado baseado em fala
Um aplicativo baseado em fala usa o SDK de Fala do Azure para se conectar ao serviço de Fala do Azure e gerar uma transcrição de áudio baseada em texto. O serviço de fala dá suporte a vários idiomas e dois modos de fluência: conversa e ditado. Para desenvolver um aplicativo personalizado baseado em fala, você geralmente precisa concluir estas etapas:
- Use o Speech Studio, o SDK de Fala do Azure, a CLI de Fala ou a API REST para gerar transcrições para frases faladas e enunciados.
- Compare a transcrição gerada com a transcrição gerada por pessoas.
- Se determinadas palavras específicas do domínio forem transcritas incorretamente, considere a criação de um modelo de fala personalizado para esse domínio específico.
- Examine as várias opções para criar modelos personalizados. Decida se um ou muitos modelos personalizados funcionarão melhor.
- Colete dados de treinamento e teste.
- Verifique se os dados estão em um formato aceitável.
- Treine, teste, avalie e implante o modelo.
- Use o modelo personalizado para a transcrição.
- Operacionalize o processo de criação, avaliação e implantação do modelo.
Examinaremos mais de perto estas etapas:
1. Use o Speech Studio, o SDK de Fala do Azure, a CLI de Fala ou a API REST para gerar transcrições para frases faladas e enunciados
A Fala do Azure fornece SDKs, uma interface da CLI e uma API REST para gerar transcrições de arquivos de áudio ou diretamente a partir da entrada do microfone. Se o conteúdo estiver em um arquivo de áudio, ele precisará estar em um formato com suporte. Nesse cenário, a Contoso tem gravações de eventos anteriores (áudio e vídeo) em arquivos .avi. A Contoso pode usar ferramentas como FFmpeg para extrair áudio dos arquivos de vídeo e salvá-lo em um formato compatível com o SDK de Fala do Azure, como .wav.
No código a seguir, o codec de áudio PCM padrão, pcm_s16le, é usado para extrair áudio em um único canal (mono) que tem uma taxa de amostragem de 8 kilohertz (kHz).
ffmpeg.exe -i INPUT_FILE.avi -acodec pcm_s16le -ac 1 -ar 8000 OUTPUT_FILE.wav
2. Compare a transcrição gerada com a transcrição gerada por pessoas
Para fazer a comparação, a Contoso amostra um áudio de comentários de vários esportes e usa o Speech Studio para comparar a transcrição gerada por pessoas com os resultados transcritos pelo serviço de Fala do Azure. As transcrições geradas por pessoas da Contoso estão em um formato WebVTT. Para usar essas transcrições, a Contoso as limpa e gera um arquivo .txt simples que tem texto normalizado sem informações do selo de data/hora.
Para obter informações sobre como usar o Speech Studio para criar e avaliar um conjunto de dados, consulte Conjuntos de dados de treinamento e teste.
O Speech Studio fornece uma comparação lado a lado da transcrição gerada por pessoas e das transcrições produzidas a partir dos modelos selecionados para comparação. Os resultados do teste incluem um WER para os modelos, como mostrado aqui:
| Modelar | Taxa de erros | Inserção | Substituição | Exclusão |
|---|---|---|---|---|
| Modelo 1: 20211030 | 14,69% | 6 (2,84%) | 22 (10,43%) | 3 (1,42%) |
| Modelo 2: Olympics_Skiing_v6 | 6,16% | 3 (1,42%) | 8 (3,79%) | 2 (0,95%) |
Para obter mais informações sobre o WER, consulte Avaliar a taxa de erros de palavra.
Com base nesses resultados, o modelo personalizado (Olympics_Skiing_v6) é melhor do que o modelo base (20211030) para o conjunto de dados.
Observe as taxas de Inserção e Exclusão, que indicam que o arquivo de áudio está relativamente limpo e tem baixo ruído de fundo.
3. Se determinadas palavras específicas do domínio forem transcritas incorretamente, considere a criação de um modelo de fala personalizado para esse domínio específico
Com base nos resultados da tabela anterior, para o modelo base, Modelo 1: 20211030, cerca de 10% das palavras são substituídas. No Speech Studio, use o recurso de comparação detalhado para identificar as palavras específicas do domínio ignoradas. A tabela a seguir mostra uma seção da comparação.
| Transcrição gerada por pessoas | Modelo 1 | Modelo 2 |
|---|---|---|
| campeã olímpica ir consecutivamente na especialidade downhill desde 1998, a grande katja seizinger da Alemanha o que 94 e 98 | campeã olímpica ir consecutivamente na especialidade downhill desde 1998, a grande ganha tamanho são da Alemanha o que 94 e 98 | campeã olímpica ir consecutivamente na especialidade downhill desde 1998, a grande katja seizinger da Alemanha o que 94 e 98 |
| ela destronou a campeã olímpica goggia | ela destronou a campeã olímpica georgia | ela destronou a campeã olímpica goggia |
O modelo 1 não reconhece as palavras específicas do domínio, como os nomes das atletas "Katia Seizinger" e "Goggia". No entanto, quando o modelo personalizado é treinado com dados que incluem os nomes das atletas e outras palavras e frases específicas do domínio, ele consegue aprender e os reconhece.
4. Examine as várias opções para criar modelos personalizados. Decida se um ou muitos modelos personalizados funcionarão melhor
Ao experimentar várias maneiras de criar modelos personalizados, a Contoso descobriu que eles teriam melhor precisão usando a personalização do modelo de pronúncia e linguagem. (Consulte o primeiro artigo neste guia.) A Contoso também observou pequenas melhorias ao incluir dados acústicos (áudio original) para a criação do modelo personalizado. No entanto, os benefícios não foram significativos o suficiente para valer a pena manter e treinar para um modelo acústico personalizado.
A Contoso descobriu que criar modelos de linguagem personalizados separados para cada esporte (um modelo para esqui alpino, um para trenó, um para snowboard etc.) forneceu melhores resultados de reconhecimento. Também foi observado que a criação de modelos acústicos separados com base no tipo de esporte para aumentar os modelos de linguagem não era necessária.
5. Colete dados de treinamento e teste
O artigo Conjuntos de dados de treinamento e teste fornece detalhes sobre como coletar os dados necessários para treinar um modelo personalizado. A Contoso coletou transcrições para vários esportes olímpicos de diversos comentaristas e usou a adaptação do modelo de linguagem para criar um modelo por tipo de esporte. No entanto, foi usado um arquivo de pronúncia para todos os modelos personalizados (um para cada esporte). Como os dados de teste e treinamento são mantidos separados, depois que um modelo personalizado foi criado, a Contoso usou o áudio do evento cujas transcrições não foram incluídas no conjunto de dados de treinamento para a avaliação de modelo.
6. Verifique se os dados estão em um formato aceitável
Como descrito em Conjuntos de dados de treinamento e teste, os conjuntos de dados usados para criar um modelo personalizado ou testar o modelo precisam estar em um formato específico. Os dados da Contoso estão em arquivos WebVTT. Eles criaram algumas ferramentas simples para produzir arquivos de texto que contêm texto normalizado para a adaptação do modelo de linguagem.
7. Treine, teste, avalie e implante o modelo
Novas gravações de evento são usadas para testar mais e avaliar o modelo treinado. Podes ser necessárias algumas iterações de teste e avaliação para ajustar um modelo. Por fim, quando o modelo gera transcrições que têm taxas de erro aceitáveis, ele é implantado (publicado) para ser consumido a partir do SDK.
8. Use o modelo personalizado para a transcrição
Depois que o modelo personalizado for implantado, você poderá usar o seguinte código C# para usar o modelo no SDK para a transcrição:
String endpoint = "Endpoint ID from Speech Studio";
string locale = "en-US";
SpeechConfig config = SpeechConfig.FromSubscription(subscriptionKey: speechKey, region: region);
SourceLanguageConfig sourceLanguageConfig = SourceLanguageConfig.FromLanguage(locale, endPoint);
recognizer = new SpeechRecognizer(config, sourceLanguageConfig, audioInput);
Observações sobre o código:
endpointé a ID do ponto de extremidade do modelo personalizado implantado na etapa 7.subscriptionKeyeregionsão a chave de assinatura dos Serviços de IA do Azure e a região. Você pode obter esses valores no portal do Azure acessando o grupo de recursos onde o recurso dos Serviços de IA do Azure foi criado e examinando suas chaves.
9. Operacionalize o processo de criação, avaliação e implantação do modelo
Depois que o modelo personalizado é publicado, ele precisa ser avaliado e atualizado regularmente se um novo vocabulário é adicionado. Sua empresa pode evoluir e talvez você precise de mais modelos personalizados para aumentar a cobertura para mais domínios. A equipe de Fala do Azure também lança novos modelos base, que são treinados com mais dados, à medida que eles ficam disponíveis. A automação pode ajudá-lo a acompanhar essas alterações. A próxima seção deste artigo fornece mais detalhes sobre como automatizar as etapas anteriores.
Implantar este cenário
Para obter informações sobre como usar scripts para simplificar e automatizar todo o processo de criação de conjuntos de dados para treinamento e teste, criação e avaliação de modelos, e publicação de novos modelos quando necessário, consulte Custom-speech-STT no GitHub.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Autor principal:
- Pratyush Mishra | Gerente Principal de Engenharia
Outros colaboradores:
- Mick Alberts | Redator Técnico
- Rania Bayoumy | Gerente Sênior de Programa Técnico
Para ver perfis não públicos do LinkedIn, entre no LinkedIn.
Próximas etapas
- O que é Fala Personalizada?
- O que é conversão de texto em fala?
- Treinar um modelo de Fala Personalizada
- Implementar a conversão de fala em texto personalizada
- Azure/custom-speech-STT no GitHub