O caching é uma técnica comum que tem o objetivo de melhorar o desempenho e a escalabilidade de um sistema. Ele armazena dados em cache copiando temporariamente dados acessados com frequência para um armazenamento rápido localizado próximo ao aplicativo. Se esse armazenamento rápido de dados estiver mais próximo do aplicativo do que a fonte original, o caching poderá melhorar significativamente os tempos de resposta para aplicativos cliente ao fornecer dados com mais rapidez.
O caching é mais eficaz quando uma instância do cliente lê repetidamente os mesmos dados, especialmente se todas as condições a seguir se aplicarem ao armazenamento de dados original:
- Ele permanece relativamente estático.
- É lento em comparação à velocidade do cache.
- Está sujeito a um alto nível de contenção.
- Está bem distante quando a latência de rede pode causar a lentidão do acesso.
Caching em aplicativos distribuídos
Aplicativos distribuídos normalmente implementam uma ou ambas as estratégias a seguir ao colocar dados em cache:
- Usa um cache privado, onde os dados são mantidos localmente no computador que executa uma instância de um aplicativo ou de um serviço.
- Usa um cache compartilhado, servindo como uma fonte comum que pode ser acessada por vários processos e computadores.
Em ambos os casos, o cache pode ser executado no lado do cliente e do servidor. O caching do lado do cliente é feito pelo processo que fornece a interface de usuário para um sistema, como um navegador da Web ou um aplicativo de área de trabalho. O caching do lado do servidor é feito pelo processo que fornece os serviços de negócios que estão sendo executados remotamente.
Caching particular
O tipo mais básico de cache é um repositório na memória. Ele é mantido no espaço de endereço de um único processo e acessado diretamente pelo código que é executado nesse processo. Esse tipo de cache é de rápido acesso. Também pode fornecer um meio eficaz para armazenar quantidades modestas de dados estáticos. O tamanho de um cache é normalmente limitado pela quantidade de memória disponível na máquina que hospeda o processo.
Se você precisar colocar em cache mais informações do que é possível armazenar fisicamente na memória, você pode gravar dados colocados em cache no sistema de arquivos local. O processo será mais lento do que acessar dados mantidos na memória, mas ainda deve ser mais rápido e confiável do que recuperar dados por uma rede.
Se você tiver várias instâncias de um aplicativo que usa esse modelo em execução simultânea, cada instância do aplicativo terá seu próprio cache independente com sua própria cópia dos dados.
Pense em um cache como um instantâneo dos dados originais, em algum ponto no passado. Se esses dados não forem estáticos, provavelmente as instâncias diferentes do aplicativo terão versões diferentes dos dados no cache. Portanto, a mesma consulta executada por essas instâncias pode retornar resultados diferentes, como mostra a Figura 1.
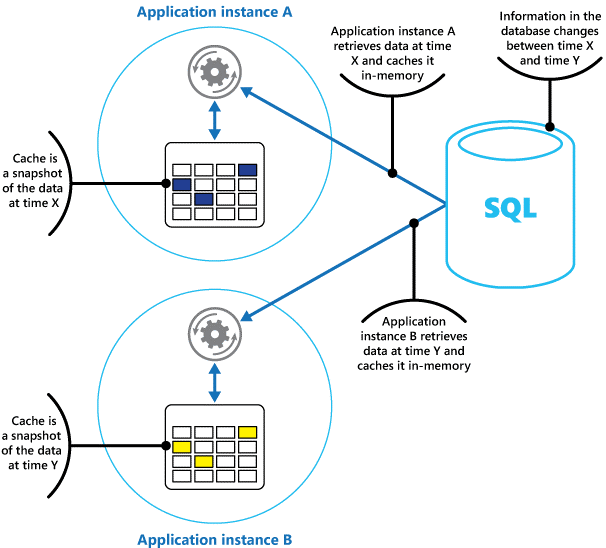
Figura 1: uso de um cache em memória em diferentes instâncias de um aplicativo.
Cache compartilhado
Usar um cache compartilhado pode ajudar a aliviar a preocupação de que os dados podem apresentar diferenças em cada cache, o que pode ocorrer com o caching em memória. O cache compartilhado garante que diferentes instâncias de aplicativo vejam os mesmos dados armazenados em cache. Ele coloca o cache em um local separado, que é normalmente hospedado como parte de um serviço separado, como mostra a Figura 2.
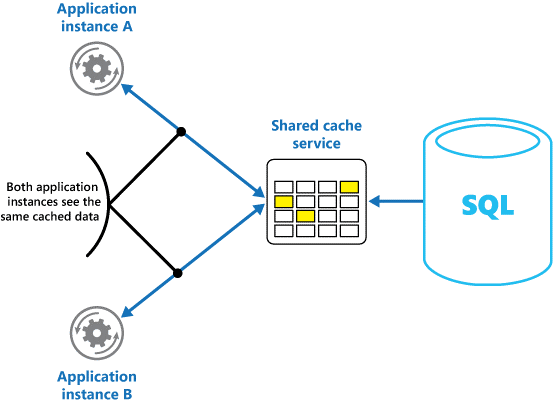
Figura 2: uso de um cache compartilhado.
Um benefício importante da abordagem de cache compartilhado é a escalabilidade que ele oferece. Muitos serviços de cache compartilhado são implementados por meio de um cluster de servidores e usam um software para distribuir os dados no cluster de maneira transparente. Uma instância do aplicativo simplesmente envia uma solicitação para o serviço de cache. A infraestrutura subjacente determina a localização dos dados armazenados em cache no cluster. Você pode facilmente dimensionar o cache adicionando mais servidores.
Há duas desvantagens principais na abordagem de cache compartilhado:
- O acesso ao cache é mais lento, pois ele não é mais mantido localmente para cada instância do aplicativo.
- A necessidade de implementar um serviço de cache separado pode adicionar complexidade à solução.
Considerações para o uso de caching
As seções a seguir descrevem detalhadamente as considerações para a criação e uso de um cache.
Decidir quando armazenar dados em cache
Caching pode melhorar drasticamente o desempenho, a escalabilidade e a disponibilidade. Quanto mais dados você tiver e quanto maior for o número de usuários que precisam acessar esses dados, maior serão as vantagens do caching. O cache reduz a latência e a contenção associadas à manipulação de grandes volumes de solicitações simultâneas no armazenamento de dados original.
Por exemplo, um banco de dados pode oferecer suporte a uma quantidade limitada de conexões simultâneas. No entanto, recuperar dados de um cache compartilhado em vez de no banco de dados subjacente possibilita a um aplicativo cliente acessar esses dados, mesmo que o número de conexões disponíveis esteja esgotado no momento. Além disso, se o banco de dados ficar indisponível, os aplicativos cliente poderão continuar usando os dados mantidos no cache.
Uma opção é armazenar em cache os dados lidos com frequência, mas que não são modificados frequentemente (por exemplo, os dados com uma proporção maior de operações de leitura em relação às operações de gravação). No entanto, não recomendamos o uso do cache como o repositório autoritativo de informações críticas. Em vez disso, certifique-se de que todas as alterações que seu aplicativo não pode perder sejam salvas sempre um armazenamento de dados persistente. Se o cache ficar indisponível, o aplicativo ainda poderá continuar operando usando o repositório de dados e você não perderá informações importantes.
Determinar como armazenar os dados em cache com eficiência
A chave para uso eficiente de um cache reside em determinar os dados mais apropriados para ele e colocar esses dados em cache no momento apropriado. Os dados poderão ser adicionados ao cache sob demanda na primeira vez em que forem recuperados por um aplicativo. O aplicativo precisa buscar os dados apenas uma vez no armazenamento de dados e o acesso subsequente pode ser atendido pelo uso do cache.
Como alternativa, um cache pode ser parcial ou totalmente preenchido com dados com antecedência, normalmente quando o aplicativo é iniciado (um método conhecido como propagação). No entanto, não é aconselhável implementar a propagação em um cache grande, pois essa abordagem pode impor uma carga elevada e repentina sobre o repositório de dados original quando o aplicativo começa a ser executado.
Geralmente, uma análise de padrões de uso pode ajudar você a decidir entre preencher com antecedência um cache de forma total ou parcial, e também a escolher os dados para o armazenamento em cache. Por exemplo, você pode propagar o cache com os dados estáticos de perfil de usuário para os clientes que usam o aplicativo regularmente (talvez todos os dias), mas não para os clientes que usam o aplicativo apenas uma vez por semana.
O caching geralmente funciona bem com dados imutáveis ou que mudam com pouca frequência. Os exemplos incluem informações de referência como informações sobre preço e produto em um aplicativo de comércio eletrônico, ou recursos compartilhados estáticos que são caros de construir. Alguns ou todos esses dados podem ser colocados em cache na inicialização do aplicativo, para minimizar a demanda por recursos e melhorar o desempenho. Você também pode querer ter um processo em segundo plano que atualize periodicamente os dados de referência no cache para garantir que eles estejam atualizados. Ou o processo em segundo plano pode atualizar o cache quando os dados de referência são alterados.
O caching é menos útil para dados dinâmicos, embora haja algumas exceções a essa consideração (consulte a seção Cache de dados altamente dinâmicos posteriormente neste artigo para saber mais). Quando os dados originais são alterados regularmente, as informações em cache tornam-se obsoletas rapidamente ou a sobrecarga de sincronizar o cache com o repositório de dados original reduz a eficácia do armazenamento em cache.
Observe que um cache não precisa incluir os dados completos para uma entidade. Por exemplo, se um item de dados representa um objeto com vários valores, como um cliente de banco com nome, endereço e saldo da conta bancária, alguns desses elementos podem permanecer estáticos, como o nome e o endereço. Outros elementos, como o saldo da conta, podem ser mais dinâmicos. Nessas situações, pode ser útil armazenar em cache as partes estáticas dos dados e recuperar (ou calcular) apenas as informações restantes quando for necessário.
Recomendamos que você realize a análise de uso e o teste de desempenho para determinar se o preenchimento prévio ou o carregamento sob demanda do cache, ou uma combinação de ambos, é apropriado. A decisão deve se basear na volatilidade e no padrão de uso dos dados. A análise de desempenho e a utilização do cache são importantes em aplicativos que encontram cargas pesadas e precisam ser altamente escalonáveis. Por exemplo, em cenários altamente escalonáveis, você pode propagar o cache para reduzir a carga no repositório de dados em horários de pico.
O caching também pode ser usado para evitar a repetição de computações durante a execução do aplicativo. Se uma operação transforma dados ou executa um cálculo complicado, ele pode salvar os resultados da operação no cache. Se o mesmo cálculo for exigido posteriormente, o aplicativo poderá simplesmente recuperar os resultados do cache.
Um aplicativo pode modificar os dados mantidos em um cache. No entanto, recomendamos que você pense no cache como um armazenamento de dados temporários que pode desaparecer a qualquer momento. Não armazene dados valiosos somente no cache; mantenha as informações no repositório de dados original também. Isso significa que se o cache ficar indisponível, a possibilidade de perda de dados será minimizada.
Cache de dados altamente dinâmicos
Quando você armazenar informações que mudam rapidamente em um armazenamento de dados persistente, isso poderá impor uma sobrecarga ao sistema. Por exemplo, considere um dispositivo que reporta continuamente o status ou alguma outra medida. Se um aplicativo decide não armazenar esses dados em cache tendo como motivo o fato de que as informações em cache quase sempre estariam desatualizadas, então a mesma consideração pode ser verdadeira ao armazenar e recuperar essas informações do repositório de dados. Durante o tempo utilizado para salvar e coletar esses dados, eles poderão ter mudado.
Em uma situação como essa, considere as vantagens de armazenar as informações dinâmicas diretamente no cache em vez de no repositório de dados persistente. Se os dados não forem críticos e não precisarem de auditoria, a possibilidade de perda da alteração ocasional não será importante.
Gerenciar a expiração de dados em um cache
Na maioria dos casos, os dados armazenados em um cache são uma cópia dos dados mantidos no repositório de dados original. Os dados no repositório de dados original podem mudar depois de terem sido armazenado em cache, fazendo com que os dados em cache tornem-se obsoletos. Muitos sistemas de armazenamento em cache permitem configurar o cache para expirar dados e reduzir o período pelo qual os dados podem permanecer desatualizados.
Quando os dados armazenados em cache expiram, eles são removidos do cache e o aplicativo precisa recuperar os dados do armazenamento de dados original (ele pode colocar as informações recém-buscadas novamente no cache). Você pode definir uma política de expiração padrão quando configura o cache. Em muitos serviços de cache, você também pode determinar o período de validade de objetos individuais ao armazená-los programaticamente no cache. Alguns caches permitem que você especifique o período de validade como um valor absoluto ou como um valor deslizante, que faz com que o item seja removido do cache se não for acessado dentro do período especificado. Essa configuração substitui qualquer política de expiração em todo o cache, mas somente para os objetos especificados.
Observação
Considere cuidadosamente o período de validade para o cache e os objetos que ele contém. Se o período for definido com um valor excessivamente curto, os objetos expirarão rápido demais e isso reduzirá os benefícios de usar o cache. Se o período for definido com um valor excessivamente longo, você correrá o risco de os dados se tornarem obsoletos.
Também é possível que o cache fique cheio, caso os dados possam permanecer armazenados ali por um longo tempo. Nesse caso, todas as solicitações para adicionar novos itens no cache podem causar a retirada forçada de alguns itens, em um processo conhecido como remoção. Os serviços de cache normalmente dão preferência à remoção de dados LRU (usados menos recentemente), mas geralmente você pode substituir essa política e impedir que determinados itens sejam removidos. No entanto, se você adotar essa abordagem, correrá o risco de exceder a memória disponível no cache. Um aplicativo que tenta adicionar um item ao cache falhará com uma exceção.
Algumas implementações de caching podem fornecer políticas de remoção adicionais. Há vários tipos de políticas de remoção. Estão incluídos:
- Uma política de mais utilizados recentemente (na expectativa de que os dados não serão exigidos novamente).
- Uma política de primeiro a entrar, primeiro a sair (os dados mais antigos são removidos primeiro).
- Uma política de remoção explícita baseada em um evento disparado (como a modificação dos dados).
Invalidar dados em um cache no lado do cliente
Geralmente, os dados mantidos em um cache no lado do cliente são considerados fora da responsabilidade do serviço que fornece os dados ao cliente. Um serviço não pode forçar diretamente um cliente a adicionar ou a remover informações de um cache do lado do cliente.
Isso significa que é possível que um cliente que use um cache mal configurado continue a usar informações desatualizadas. Por exemplo, se as políticas de expiração do cache não forem implementadas corretamente, um cliente poderá usar as informações desatualizadas armazenadas em cache localmente quando as informações na fonte de dados original forem alteradas.
Se você estiver criando um aplicativo Web que sirva dados em uma conexão HTTP, poderá forçar implicitamente um cliente Web (como um navegador ou proxy Web) a coletar as informações mais recentes. Você poderá fazer isso se um recurso for atualizado por uma alteração no URI desse recurso. Os clientes Web normalmente usam o URI de um recurso como a chave no cache do lado do cliente. Portanto, se o URI for alterado, o cliente Web ignorará quaisquer versões de um recurso previamente armazenadas em cache e, em vez disso, buscará a nova versão.
Gerenciando simultaneidade em um cache
Caches são frequentemente projetados para serem compartilhados por várias instâncias de um aplicativo. Cada instância do aplicativo pode ler e modificar dados no cache. Consequentemente, os mesmos problemas de simultaneidade que surgem com qualquer repositório de dados compartilhado também são aplicáveis a um cache. Em uma situação em que um aplicativo precisa modificar dados mantidos no cache, talvez você precise garantir que as atualizações feitas por uma instância do aplicativo não substitua as alterações feitas por outra instância.
Dependendo da natureza dos dados e da probabilidade de colisões, você pode adotar uma dessas duas abordagens para simultaneidade:
- Otimista. O aplicativo verifica, imediatamente antes de atualizar os dados, se eles sofreram alterações no cache desde que foram recuperados. Se os dados ainda são os mesmos, a alteração pode ser feita. Caso contrário, o aplicativo precisará decidir se quer atualizá-los. A lógica de negócios que impulsiona essa decisão é específica do aplicativo. Essa abordagem é adequada para situações em que as atualizações são pouco frequentes ou em que é improvável que ocorram colisões.
- Pessimista. Durante a recuperação dos dados, o aplicativo bloqueia o cache para impedir que outra instância altere esses dados. Esse processo garante que as colisões não ocorrerão, mas elas também poderão bloquear outras instâncias que precisem processar os mesmos dados. A simultaneidade pessimista pode afetar a escalabilidade de uma solução e é recomendada apenas para operações de curta duração. Essa abordagem pode ser apropriada para situações em que há maior probabilidade de colisões, especialmente se um aplicativo atualiza vários itens no cache e precisa garantir que essas alterações sejam aplicadas de modo consistente.
Implementar a alta disponibilidade e a escalabilidade e melhorar o desempenho
Evite usar um cache como o repositório principal dos dados; essa é a função do repositório de dados original, por meio do qual o cache é preenchido. O repositório de dados original é responsável por garantir a persistência dos dados.
Tenha cuidado para não introduzir, em suas soluções, dependências críticas sobre a disponibilidade de um serviço de cache compartilhado. Um aplicativo deverá ser capaz de continuar funcionando se o serviço que fornece o cache compartilhado não estiver disponível. O aplicativo não deve ficar sem resposta ou falhar enquanto aguarda a retomada do serviço de cache.
Portanto, o aplicativo deve estar preparado para detectar a disponibilidade do serviço de cache e voltar para o repositório de dados original se o cache estiver inacessível. O padrão Circuit-Breaker é útil para lidar com esse cenário. O serviço que fornece o cache pode ser recuperado e, depois que ele se torna disponível, o cache pode ser populado novamente, já que os dados são lidos do armazenamento de dados original, seguindo uma estratégia como o padrão Cache-aside.
No entanto, a escalabilidade do sistema poderá ser afetada se o aplicativo recorrer ao armazenamento de dados original quando o cache estiver temporariamente indisponível. Durante a recuperação do armazenamento de dados, o armazenamento de dados original pode ser inundado com solicitações de dados, resultando em tempos limite e conexões com falha.
Considere a implementação de um cache local e privado em cada instância de um aplicativo, junto com o cache compartilhado que todas as instâncias do aplicativo acessam. Quando o aplicativo recupera um item, ele pode verificar primeiro em seu cache local, em seguida no cache compartilhado e, por fim, no armazenamento de dados original. O cache local pode ser preenchido usando os dados do cache compartilhado ou no banco de dados, se o cache compartilhado não estiver disponível.
Essa abordagem requer configuração cuidadosa para impedir que o cache local se torne muito desatualizado em relação ao cache compartilhado. No entanto, o cache local atua como um buffer se o cache compartilhado estiver inacessível. A Figura 3 mostra essa estrutura.
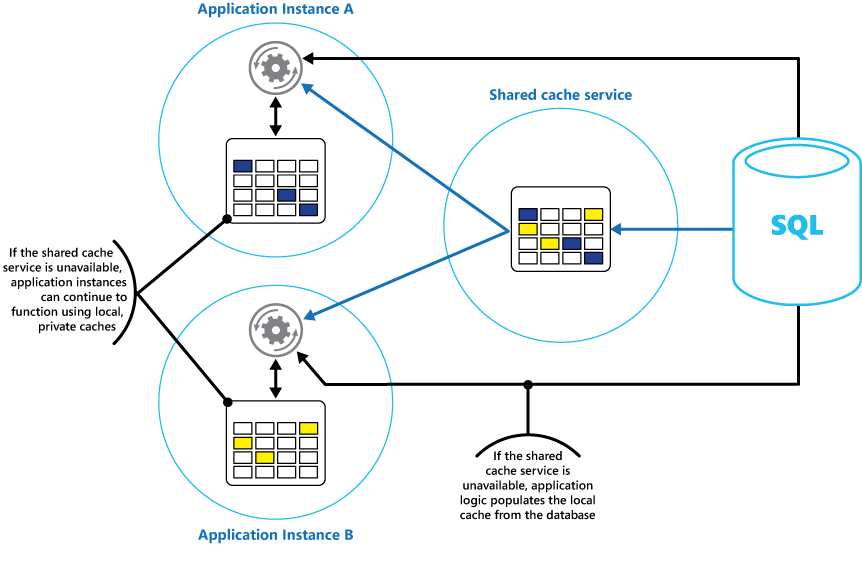
Figura 3: uso de um cache privado local com um cache compartilhado.
Para dar suporte a caches grandes que mantêm dados de vida útil relativamente longa, alguns serviços de cache fornecem uma opção de alta disponibilidade, que implementa o failover automático se o cache fica indisponível. Essa abordagem geralmente envolve a replicação dos dados em cache armazenados em um servidor de cache primário para um servidor de cache secundário, alternando para o servidor secundário se o servidor primário falha ou se a conectividade é perdida.
Para reduzir a latência associada à gravação em múltiplos destinos, a replicação para o servidor secundário pode ocorrer de modo assíncrono quando os dados são gravados em cache no servidor primário. Essa abordagem leva à possibilidade de algumas informações em cache serem perdidas em caso de falha, mas a proporção desses dados deve ser pequena em comparação com o tamanho geral do cache.
Se um cache compartilhado for grande, pode ser benéfico particionar os dados em cache em nós para reduzir as chances de contenção e melhorar a escalabilidade. Em vários caches compartilhados, há suporte para a capacidade de adicionar dinamicamente (e remover) nós e rebalancear os dados em partições. Essa abordagem pode envolver o clustering, em que a coleção de nós é apresentada a aplicativos cliente como um cache único e transparente. Internamente, no entanto, os dados ficam dispersos entre nós após uma estratégia de distribuição predefinida que equilibra a carga de maneira uniforme. Para saber mais sobre estratégias de particionamento possíveis, confira Orientação de particionamento de dados.
O clustering também pode aumentar a disponibilidade do cache. Se um nó falhar, o restante do cache ainda poderá ser acessado. O clustering é usado frequentemente em conjunto com a replicação e failover. Cada nó pode ser replicado, e a réplica pode ser colocada online rapidamente se o nó falhar.
Muitas operações de leitura e gravação provavelmente envolvem valores ou objetos únicos de dados. No entanto, às vezes pode ser necessário armazenar ou recuperar rapidamente grandes volumes de dados. Por exemplo, a propagação de um cache pode envolver a gravação de centenas ou milhares de itens no cache. Um aplicativo também pode precisar recuperar uma grande quantidade de itens relacionados do cache como parte da mesma solicitação.
Muitos caches em larga escala oferecem operações em lote para esses fins. Isso permite que um aplicativo cliente empacote um grande volume de itens em uma única solicitação e reduza a sobrecarga associada à realização de uma grande quantidade de solicitações pequenas.
Caching e consistência eventual.
Para que o padrão cache-aside funcione, a instância do aplicativo que preenche o cache deve ter acesso à versão mais recente e consistente dos dados. Em um sistema que implementa a consistência eventual (como um repositório de dados replicados), esse pode não ser o caso.
Uma instância de um aplicativo pode modificar um item de dados e invalidar a versão em cache desse item. Outra instância do aplicativo pode tentar ler esse item no cache causando um erro de cache; por isso, ele lê os dados no repositório de dados e adiciona-os ao cache. No entanto, se o repositório de dados não foi totalmente sincronizado com as outras réplicas, a instância do aplicativo pode ler e preencher o cache com o valor antigo.
Para saber mais sobre como lidar com consistência de dados, veja o Data consistency primer (Primer de consistência de dados).
Proteger dados em cache
Independentemente do serviço de cache que você usar, pense em como proteger os dados mantidos no cache contra o acesso não autorizado. Há dois problemas principais:
- A privacidade dos dados no cache.
- A privacidade dos dados que fluem entre o cache e o aplicativo usando o cache.
Para proteger os dados no cache, o serviço de cache pode implementar um mecanismo de autenticação que exige que os aplicativos especifiquem o seguinte:
- Quais identidades podem acessar os dados no cache.
- Quais operações (leitura e gravação) que essas identidades têm permissão para executar.
Para reduzir os custos associados à leitura e à gravação de dados, uma identidade pode usar todos os dados no cache após ter recebido acesso de leitura ou gravação nesse cache.
Se for necessário restringir o acesso a subconjuntos dos dados armazenados em cache, você pode realizar um dos seguintes procedimentos:
- Dividir o cache em partições (usando servidores de cache diferentes) e conceder às identidades o acesso somente às partições que elas devem ter permissão para usar.
- Criptografar os dados em cada subconjunto usando chaves diferentes e fornecer as chaves de criptografia apenas às identidades que devem ter acesso a cada subconjunto. Um aplicativo cliente pode ainda ser capaz de recuperar todos os dados no cache, mas ele só poderá descriptografar os dados para os quais tem as chaves.
Você também deve proteger os dados conforme eles entram e saem do cache. Para fazer isso, você depende dos recursos de segurança fornecidos pela infraestrutura de rede usada pelos aplicativos cliente para se conectarem ao cache. Se o cache for implementado usando um servidor local dentro da mesma organização que hospeda os aplicativos cliente, pode ser que o isolamento da rede em si não exija etapas adicionais. Se o cache estiver localizado remotamente e exigir uma conexão TCP ou HTTP por uma rede pública (como a Internet), considere a possibilidade de implementar SSL.
Considerações sobre como implementar o cache com no Azure
O Cache do Azure para Redis é uma implementação do cache Redis de código aberto que é executada como um serviço em um datacenter do Azure. Ele fornece um serviço de cache que pode ser acessado de qualquer aplicativo do Azure, seja o aplicativo implementado como um serviço de nuvem, um site, ou dentro de uma máquina virtual do Azure. Os caches podem ser compartilhados por aplicativos cliente que têm a chave de acesso apropriada.
O Cache do Azure para Redis é uma solução de cache de alto desempenho que fornece disponibilidade, escalabilidade e segurança. Normalmente, ele é executado como um serviço espalhado por um ou mais computadores dedicados. Ele tenta armazenar tanta informação quanto possível na memória para garantir o acesso rápido. Essa arquitetura destina-se a oferecer baixa latência e alta taxa de transferência, reduzindo a necessidade de executar operações de E/S lentas.
O Cache do Azure para Redis é compatível com muitas das várias APIs que são usadas pelos aplicativos cliente. Se você tiver aplicativos existentes que já usam o Cache do Azure para Redis em execução local, o Cache do Azure para Redis fornecerá um caminho de migração rápida para o cache na nuvem.
Recursos do Redis
O Redis é mais do que um simples servidor de cache. Ele fornece um banco de dados distribuído na memória com um conjunto abrangente de comandos que oferece suporte a vários cenários comuns. Eles serão descritos posteriormente neste documento, na seção Como usar o caching Redis. Essa seção resume alguns dos principais recursos oferecidos pelo Redis.
Redis como um banco de dados na memória
O Redis oferece suporte tanto a operações de leitura quanto de gravação. No Redis, as gravações podem ser protegidas contra falhas do sistema, seja armazenando-as periodicamente em um arquivo de instantâneo local ou em um arquivo de log do tipo que apenas acrescenta. Esse não é o caso em muitos caches (que devem ser considerados repositórios de dados transitórios).
Todas as gravações são assíncronas e não bloqueiam a leitura e gravação de dados por clientes. Quando o Redis começa a ser executado, ele lê os dados do arquivo de instantâneo ou de log e usa-os para construir o cache na memória. Para saber mais, confira Redis persistence no site do Redis.
Observação
O Redis não garante que todas as gravações serão salvas no caso de uma falha catastrófica, mas, no pior caso possível, você deverá perder apenas os dados equivalentes a alguns segundos. Lembre-se de que um cache não se destina a agir como uma fonte de dados autoritativa, é responsabilidade dos aplicativos usar o cache para garantir que os dados críticos sejam salvos com êxito em um repositório de dados apropriado. Para saber mais, confira o Padrão cache-aside.
Tipos de dados do Redis
Redis é um repositório de chave-valor, onde os valores podem conter tipos simples ou estruturas de dados complexas como hashes, listas e conjuntos. Ele oferece suporte a um conjunto de operações atômicas nesses tipos de dados. As chaves podem ser permanentes ou marcadas com um tempo limite de expiração, ponto em que a chave e seu valor correspondente são automaticamente removidos do cache. Para saber mais sobre chaves e valores do Redis, visite a página An introduction to Redis data types and abstractions (Uma introdução a abstrações e tipos de dados do Redis) no site do Redis.
Replicação e clustering do Redis
O Redis dá suporte à replicação primária/subordinada para ajudar a garantir a disponibilidade e manter a taxa de transferência. As operações de gravação em um nó primário do Redis são replicadas para um ou mais nós subordinados. As operações de leitura podem ser fornecidas pelo primário ou por um dos subordinados.
Se você tiver uma partição de rede, os subordinados poderão continuar fornecendo dados e ressincronizá-los de maneira transparente com o primário quando a conexão for restabelecida. Para obter mais detalhes, visite a página Replicação no site do Redis.
O Redis também oferece clustering, o que permite que você distribua a carga e particione os dados em fragmentos entre servidores de modo transparente. Esse recurso melhora a escalabilidade, pois os novos servidores do Redis podem ser adicionados e os dados reparticionados conforme o tamanho do cache aumenta.
Além disso, cada servidor do cluster pode ser replicado usando a replicação primária/subordinada. Isso garante a disponibilidade em cada nó no cluster. Para saber mais sobre clustering e fragmentação, visite a página de tutorial do cluster Redis no site do Redis.
Uso da memória no Redis
Um cache Redis tem um tamanho limitado, dependendo dos recursos disponíveis no computador do host. Quando configura um servidor Redis, você pode especificar a quantidade máxima de memória que ele pode usar. Também é possível configurar uma chave em um cache Redis para ter um tempo de validade, após o qual ele será removido do cache automaticamente. Esse recurso pode ajudar a impedir que o cache de memória seja preenchido com dados antigos ou obsoletos.
Conforme a memória é preenchida, o Redis pode remover automaticamente as chaves e seus valores, seguindo uma série de políticas. O padrão é LRU (menos utilizados recentemente), mas você também pode selecionar outras políticas como remover chaves aleatoriamente ou desativar completamente a remoção (nesse caso, as tentativas de adicionar itens ao cache falharão se o cache estiver cheio). A página Using Redis as an LRU cache (Usar Redis como uma cache LRU) fornece mais informações a respeito.
Lotes e transações do Redis
O Redis habilita um aplicativo cliente a enviar uma série de operações que leem e gravam dados em cache como uma transação atômica. Todos os comandos na transação têm garantia de serem executados em sequência, e nenhum comando emitido por outros clientes simultâneos será colocado entre eles.
No entanto, essas não são transações verdadeiras, já que seriam executadas por um banco de dados relacional. O processamento de transações é comporto por duas etapas: a primeira é quando os comandos estão em fila, e a segunda é quando os comandos são executados. Durante o estágio de enfileiramento de comandos, os comandos que compõem a transação são enviados pelo cliente. Se ocorrer algum tipo de erro neste momento (por exemplo, um erro de sintaxe ou número errado de parâmetros), o Redis se recusará a processar a transação inteira e a descartará.
Durante a fase de execução, o Redis executa em sequência cada comando enfileirado. Se um comando falhar durante essa fase, o Redis continuará com o próximo comando na fila e não reverterá os efeitos de quaisquer comandos já executados. Esse modo simplificado de transação ajuda a manter o desempenho e evitar problemas de desempenho causados por contenção.
O Redis implementa um modo de bloqueio otimista para ajudar a manter a consistência. Para obter informações detalhadas sobre as transações e bloqueio com o Redis, visite a página Transações no site do Redis.
O Redis também dá suporte ao envio em lote não transacional de solicitações. O protocolo Redis, que os clientes usam para enviar comandos para um servidor Redis, habilita um cliente a enviar uma série de operações como parte da mesma solicitação. Isso pode ajudar a reduzir a fragmentação de pacotes na rede. Quando o lote é processado, cada comando é executado. Se qualquer um desses comandos for malformado, será rejeitado (o que não acontece com uma transação), mas os restantes serão executados. Além disso, não há nenhuma garantia quanto à ordem em que os comandos em lote serão processados.
Segurança no Redis
O Redis concentra-se puramente no fornecimento de acesso rápido aos dados, e foi projetado para execução em um ambiente confiável que pode ser acessado somente por clientes confiáveis. O Redis oferece suporte a um modelo de segurança limitada com base na autenticação da senha. (É possível remover a autenticação completamente, embora isso não seja recomendável).
Todos os clientes autenticados compartilham a mesma senha global e têm acesso aos mesmos recursos. Se precisar de segurança de logon mais abrangente, você deverá implementar sua própria camada de segurança na frente do servidor do Redis e todas as solicitações de cliente devem passar por essa camada adicional. O Redis não deve ser exposto diretamente a clientes não confiáveis ou não autenticados.
Você pode restringir o acesso aos comandos desabilitando-os ou renomeando-os (e fornecendo os novos nomes apenas a clientes privilegiados).
Ele não oferece suporte direto a nenhuma forma de criptografia de dados, portanto, toda codificação deve ser realizada por aplicativos cliente. Além disso, o Redis não fornece qualquer forma de segurança de transporte. Se você precisar proteger os dados conforme eles fluem pela rede, recomendamos a implementação de um proxy SSL.
Para saber mais, visite a página Redis security (Segurança do Redis) no site do Redis.
Observação
O Cache do Azure para Redis fornece uma camada de segurança própria por meio da qual os clientes se conectam. Os servidores Redis subjacentes não são expostos à rede pública.
Cache Redis do Azure
O Cache do Azure para Redis fornece acesso aos servidores Redis hospedados em um datacenter do Azure. Ele atua como uma fachada que fornece controle de acesso e segurança. Você pode provisionar um cache usando o Portal do Azure.
O portal fornece várias configurações predefinidas. Essas configurações variam desde um cache de 53 GB em execução como um serviço dedicado, que oferece suporte a comunicações SSL (para privacidade) e replicação de mestre/subordinados com uma disponibilidade de SLA (contrato de nível de serviço) de 99,9%, até um cache de 250 MB sem replicação (nenhuma garantia de disponibilidade) em execução em hardware compartilhado.
Usando o Portal do Azure, você também pode configurar a política de remoção do cache, além de controlar o acesso ao cache adicionando usuários às funções fornecidas. Essas funções, que definem as operações que os membros podem executar, incluem Proprietário, Colaborador e Leitor. Por exemplo, os membros da função Proprietário têm controle completo sobre o cache (incluindo segurança) e seu conteúdo; os membros da função Colaborador podem ler e gravar informações no cache, enquanto os membros da função Leitor só podem recuperar dados por meio do cache.
A maioria das tarefas administrativas é executada no Portal do Azure. Por esse motivo, muitos dos comandos administrativos disponíveis na versão padrão do Redis não estão disponíveis, incluindo a capacidade de modificar a configuração programaticamente, desligar o servidor Redis, configurar servidores subordinados adicionais ou salvar dados em disco de modo forçado.
O Portal do Azure inclui uma exibição gráfica prática, que permite a você monitorar o desempenho do cache. Por exemplo, você pode exibir o número de conexões que estão sendo feitas, o número de solicitações sendo realizadas, o volume de leituras e gravações e o número de ocorrências no cache versus perdas no cache. Usando essas informações você pode determinar a eficiência do cache e, se necessário, alternar para uma configuração diferente ou alterar a política de remoção.
Além disso, você pode criar alertas que enviam mensagens de email para um administrador se uma ou mais métricas de tipo crítico estiverem fora de um intervalo esperado. Por exemplo, convém alertar um administrador se o número de erros de cache exceder um valor especificado na última hora, pois isso significa que o cache pode ser muito pequeno ou os dados podem estar sendo removidos demasiadamente rápido.
Você também pode monitorar a CPU, memória e uso de rede para o cache.
Para obter mais informações e exemplos que mostram como criar e configurar um Cache do Azure para Redis, acesse a página Visão geral do Cache do Azure para Redis no blog do Azure.
Caching de estado de sessão e saída HTML
Se você criar aplicativos Web ASP.NET que são executados usando funções Web do Azure, você pode salvar informações de estado de sessão e de saída HTML em um Cache Redis do Azure. O provedor de estado de sessão do Cache do Azure para Redis permite que você compartilhe informações de sessão entre diferentes instâncias de um aplicativo Web ASP.NET e é muito útil em situações de Web farm em que a afinidade de cliente-servidor não está disponível e o cache de dados de sessão na memória não seria apropriado.
O uso do provedor de estado de sessão com o Cache do Azure para Redis oferece vários benefícios, incluindo:
- O compartilhamento do estado de sessão com um grande número de instâncias de aplicativos Web ASP.NET.
- Maior escalabilidade.
- Suporte ao acesso controlado e simultâneo aos mesmos dados de estado de sessão para múltiplos leitores e um único gravador.
- Uso da compactação para economizar memória e melhorar o desempenho da rede.
Para obter mais informações, confira Provedor de estado de sessão ASP.NET para o Cache do Azure para Redis.
Observação
Não use o provedor de estado de sessão para o Cache do Azure para Redis com os aplicativos ASP.NET que são executados fora do ambiente do Azure. A latência de acessar o cache de fora do Azure pode eliminar os benefícios de desempenho obtidos pelo caching de dados.
Da mesma forma, o provedor de cache de saída do Cache do Azure para Redis permite que você salve as respostas HTTP geradas por um aplicativo Web ASP.NET. O uso do provedor de cache de saída com o Cache do Azure para Redis pode aprimorar os tempos de resposta dos aplicativos que renderizam uma saída HTML complexa. As instâncias de aplicativo que geram respostas semelhantes podem usar os fragmentos de saída compartilhados no cache em vez de gerar essa saída HTML novamente. Para obter mais informações, confira Provedor de cache de saída ASP.NET do Cache do Azure para Redis.
Criando um cache Redis personalizado
O Cache do Azure para Redis funciona como uma fachada para os servidores Redis subjacentes. Se você precisa de uma configuração avançada não contemplada pelo Cache Redis do Azure (como um cache maior que 53 GB), você pode criar e hospedar seus próprios servidores Redis usando máquinas virtuais do Azure.
Esse é um processo potencialmente complexo, pois talvez seja necessário criar várias VMs para funcionar como nós primários e subordinados caso você deseje implementar a replicação. Além disso, se você quiser criar um cluster, precisará de vários servidores primários e subordinados. Uma topologia mínima de replicação de cluster que fornece um alto grau de disponibilidade e escalabilidade consiste em, pelo menos, seis VMs organizadas como três pares de servidores primários/subordinados (um cluster precisa conter, pelo menos, três nós primários).
Cada par primário/subordinado deve estar localizado próximo um do outro para minimizar a latência. No entanto, cada conjunto de pares pode ser executado em diferentes datacenters do Azure localizados em diferentes regiões, caso você deseje posicionar os dados armazenados em cache perto dos aplicativos que têm mais probabilidade de usá-los. Para obter um exemplo de criação e configuração de um nó Redis em execução como uma VM do Azure, veja Execução do Redis em uma VM Linux CentOS no Azure.
Observação
Se você implementar um cache Redis próprio dessa forma, será responsável por monitorar, gerenciar e proteger o serviço.
Particionando um cache Redis
O particionamento de cache envolve dividir o cache por diversos computadores. Essa estrutura oferece várias vantagens em relação ao uso de um único servidor de cache, incluindo:
- Criação de um cache muito maior do que o que é possível armazenar em um único servidor.
- Distribuição de dados entre servidores, melhorando a disponibilidade. Se um servidor falha ou fica inacessível, os dados que ele contém ficam indisponíveis; os dados nos servidores restantes ainda podem ser acessados. Para um cache, isso não é crucial porque os dados em cache são apenas uma cópia temporária dos dados mantida em um banco de dados. Em vez disso, os dados armazenados em cache em um servidor que se torna inacessível podem ser armazenados em cache em um servidor diferente.
- Distribuir a carga entre servidores, o que melhora o desempenho e escalabilidade.
- Mantenha os dados geograficamente próximos dos usuários que os acessam, reduzindo assim a latência.
Para um cache, o modo mais comum de particionamento é a fragmentação. Nessa estratégia, cada partição (ou fragmento) é um cache Redis por si só. Os dados são direcionados para uma partição específica usando a lógica de fragmentação, que pode usar diversas abordagens para distribuir os dados. O padrão de Fragmentação fornece mais informações sobre como implementar a fragmentação.
Para implementar o particionamento em um cache Redis, você pode usar uma das abordagens a seguir:
- Roteamento de consulta no lado do servidor. Nessa técnica, um aplicativo cliente envia uma solicitação para qualquer um dos servidores Redis que compõem o cache (provavelmente o servidor mais próximo). Cada servidor Redis armazena metadados que descrevem a partição contida nele, além de conter informações sobre quais partições estão localizadas em outros servidores. O servidor Redis examina a solicitação do cliente. Se ela puder ser resolvida localmente, o servidor executará a operação solicitada. Caso contrário, ele encaminhará a solicitação para o servidor adequado. Esse modelo é implementado usando o clustering do Redis e é descrito mais detalhadamente na página Tutorial de cluster do Redis, no site do Redis. O clustering do Redis é transparente para os aplicativos cliente e outros servidores do Redis podem ser adicionados ao cluster (e os dados particionados novamente) sem a necessidade de reconfigurar os clientes.
- Particionamento no lado do cliente. Nesse modelo, o aplicativo cliente contém uma lógica (possivelmente na forma de uma biblioteca) que encaminha solicitações para o servidor Redis apropriado. Essa abordagem pode ser usada com o Cache do Azure para Redis. Crie vários Caches do Azure para Redis (um para cada partição de dados) e implemente a lógica do lado do cliente que roteia as solicitações para o cache correto. Se o esquema de particionamento for alterado (se um Cache do Azure para Redis adicional for criado, por exemplo), os aplicativos cliente poderão precisar ser reconfigurados.
- Particionamento assistido por proxy. Nesse esquema, aplicativos cliente enviam solicitações para um serviço de proxy intermediário que compreende como os dados são particionados e então encaminha a solicitação para o servidor Redis apropriado. Essa abordagem também pode ser usada com o Cache do Azure para Redis; o serviço de proxy pode ser implementado como um serviço de nuvem do Azure. Essa abordagem exige um nível adicional de complexidade para implementar o serviço e as solicitações podem levar mais tempo do que o particionamento no lado do cliente.
A página Particionamento: como dividir dados entre várias instâncias do Redis no site do Redis fornece mais informações sobre a implementação do particionamento com o Redis.
Implementar aplicativos de cliente do Cache Redis
O Redis oferece suporte a aplicativos cliente escritos em numerosas linguagens de programação. Se você está criando novos aplicativos usando o .NET Framework, a abordagem recomendada é utilizar a biblioteca de cliente StackExchange.Redis. Esta biblioteca fornece um modelo de objeto do .NET Framework que abstrai os detalhes para conectar-se a um servidor Redis, enviar comandos e receber respostas. Ela está disponível no Visual Studio como um pacote NuGet. Você pode usar essa mesma biblioteca para se conectar a um Cache do Azure para Redis ou a um cache Redis personalizado hospedado em uma VM.
Para se conectar a um servidor do Redis, você utiliza o método Connect estático da classe ConnectionMultiplexer. A conexão que cria esse método é projetada para ser usada durante a vida útil do aplicativo cliente e a mesma conexão pode ser usada por vários threads simultâneos. Não se reconecte e se desconecte sempre que executar uma operação do Redis, já que isso pode prejudicar o desempenho.
Você pode especificar os parâmetros de conexão, como o endereço do host Redis e a senha. Se você estiver usando o Cache do Azure para Redis, a senha será a chave primária ou secundária gerada para o Cache do Azure para Redis por meio do portal do Azure.
Após conectar-se ao servidor Redis, você pode obter um identificador no banco de dados Redis que atua como o cache. A conexão Redis oferece o método GetDatabase para fazer isso. Você pode recuperar itens do cache e armazenar dados nele usando os métodos StringGet e StringSet. Esses métodos esperam uma chave como um parâmetro, e retornam o item no cache com um valor correspondente (StringGet) ou adicionam o item com essa chave (StringSet) ao cache.
Dependendo do local do servidor Redis, muitas operações podem causar alguma latência enquanto uma solicitação é transmitida para o servidor e uma resposta é retornada ao cliente. A biblioteca do StackExchange fornece versões assíncronas de muitos dos métodos que ela expõe para ajudar aplicativos cliente a permanecerem responsivos. Esses métodos oferecem suporte ao Padrão Assíncrono baseado em Tarefa no .NET Framework.
O snippet de código a seguir mostra um método chamado RetrieveItem. Ele ilustra um exemplo de uma implementação do padrão cache-aside com base em Redis e na biblioteca do StackExchange. O método utiliza um valor de chave de cadeia de caracteres e tenta recuperar o item correspondente do cache do Redis, chamando o método StringGetAsync (a versão assíncrona do StringGet).
Se o item não for encontrado, ele será extraído da fonte de dados subjacente usando o método GetItemFromDataSourceAsync (que é um método local e não faz parte da biblioteca do StackExchange). Em seguida, ele é adicionado ao cache usando o método StringSetAsync para que, da próxima vez, esse item possa ser recuperado mais rapidamente.
// Connect to the Azure Redis cache
ConfigurationOptions config = new ConfigurationOptions();
config.EndPoints.Add("<your DNS name>.redis.cache.windows.net");
config.Password = "<Redis cache key from management portal>";
ConnectionMultiplexer redisHostConnection = ConnectionMultiplexer.Connect(config);
IDatabase cache = redisHostConnection.GetDatabase();
...
private async Task<string> RetrieveItem(string itemKey)
{
// Attempt to retrieve the item from the Redis cache
string itemValue = await cache.StringGetAsync(itemKey);
// If the value returned is null, the item was not found in the cache
// So retrieve the item from the data source and add it to the cache
if (itemValue == null)
{
itemValue = await GetItemFromDataSourceAsync(itemKey);
await cache.StringSetAsync(itemKey, itemValue);
}
// Return the item
return itemValue;
}
Os métodos StringGet e StringSet não são restritos à recuperação ou armazenamento de valores de cadeia de caracteres. Eles podem usar qualquer item serializado como uma matriz de bytes. Se você precisa salvar um objeto .NET, poderá serializá-lo como um fluxo de bytes e usar o método StringSet para gravá-lo no cache.
De modo similar, você pode ler um objeto no cache usando o método StringGet e desserializá-lo como um objeto .NET. O seguinte código mostra um conjunto de métodos de extensão para a interface IDatabase (o método GetDatabase de uma conexão do Redis retorna um objeto IDatabase) e um código de exemplo que usa esses métodos para ler e gravar um objeto BlogPost no cache:
public static class RedisCacheExtensions
{
public static async Task<T> GetAsync<T>(this IDatabase cache, string key)
{
return Deserialize<T>(await cache.StringGetAsync(key));
}
public static async Task<object> GetAsync(this IDatabase cache, string key)
{
return Deserialize<object>(await cache.StringGetAsync(key));
}
public static async Task SetAsync(this IDatabase cache, string key, object value)
{
await cache.StringSetAsync(key, Serialize(value));
}
static byte[] Serialize(object o)
{
byte[] objectDataAsStream = null;
if (o != null)
{
var jsonString = JsonSerializer.Serialize(o);
objectDataAsStream = Encoding.ASCII.GetBytes(jsonString);
}
return objectDataAsStream;
}
static T Deserialize<T>(byte[] stream)
{
T result = default(T);
if (stream != null)
{
var jsonString = Encoding.ASCII.GetString(stream);
result = JsonSerializer.Deserialize<T>(jsonString);
}
return result;
}
}
O código a seguir ilustra um método chamado RetrieveBlogPost que usa esses métodos de extensão para ler e gravar um objeto serializável BlogPost no cache, seguindo o padrão cache-aside:
// The BlogPost type
public class BlogPost
{
private HashSet<string> tags;
public BlogPost(int id, string title, int score, IEnumerable<string> tags)
{
this.Id = id;
this.Title = title;
this.Score = score;
this.tags = new HashSet<string>(tags);
}
public int Id { get; set; }
public string Title { get; set; }
public int Score { get; set; }
public ICollection<string> Tags => this.tags;
}
...
private async Task<BlogPost> RetrieveBlogPost(string blogPostKey)
{
BlogPost blogPost = await cache.GetAsync<BlogPost>(blogPostKey);
if (blogPost == null)
{
blogPost = await GetBlogPostFromDataSourceAsync(blogPostKey);
await cache.SetAsync(blogPostKey, blogPost);
}
return blogPost;
}
O Redis oferece suporte ao pipelining de comandos, caso um aplicativo cliente envie múltiplas solicitações assíncronas. O Redis pode multiplexar as solicitações usando a mesma conexão, em vez de receber os comandos e respondê-los em uma sequência estrita.
Essa abordagem ajuda a reduzir a latência, fazendo uso mais eficiente da rede. O snippet de código a seguir mostra um exemplo que obtém os detalhes de dois clientes simultaneamente. O código envia duas solicitações e, em seguida, executa algum outro processamento (não mostrado) antes de esperar para receber os resultados. O método Wait do objeto de cache é semelhante ao método Task.Wait do .NET Framework:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
var task1 = cache.StringGetAsync("customer:1");
var task2 = cache.StringGetAsync("customer:2");
...
var customer1 = cache.Wait(task1);
var customer2 = cache.Wait(task2);
Para obter informações adicionais sobre como escrever aplicativos cliente que podem usar o Cache do Azure para Redis, confira a documentação do Cache do Azure para Redis. Mais informações também estão disponíveis em StackExchange.Redis.
A página Pipelines e multiplexadores no mesmo site fornece mais informações sobre operações assíncronas e pipeline com Redis e a biblioteca do StackExchange.
Como usar o caching do Redis
O uso mais simples de Redis para questões de armazenamento em cache é com pares chave/valor, nos quais o valor é uma cadeia de caracteres não interpretada de comprimento arbitrário, que pode conter quaisquer dados binários. (Essencialmente, é uma matriz de bytes que pode ser tratada como uma cadeia de caracteres). Esse cenário foi ilustrado na seção Implementar aplicativos de cliente do Cache Redis, anteriormente neste artigo.
Observe que as chaves também contêm dados não interpretados, assim você pode usar qualquer informação binária como chave. No entanto, quanto mais longa for a chave, mais espaço será necessário para armazenar e mais tempo levará para executar operações de pesquisa. Para facilidade de uso e de manutenção, projete seu keyspace com cuidado e use chaves significativas (mas não detalhadas).
Por exemplo, use chaves estruturadas, como "cliente:100" para representar a chave para o cliente com ID 100, em vez de utilizar simplesmente "100". Esse esquema permite distinguir facilmente entre valores que armazenam tipos de dados diferentes. Por exemplo, você também pode usar a chave "pedidos:100" para representar a chave para o pedido com ID 100.
Além de cadeias de caracteres binárias unidimensionais, um valor em um par chave/valor do Redis também pode conter informações mais estruturadas, incluindo listas, conjuntos (classificados e não classificados) e hashes. O Redis oferece um conjunto abrangente de comandos capazes de manipular esses tipos e muitos desses comandos estão disponíveis para aplicativos do .NET Framework, por meio de uma biblioteca de cliente como StackExchange. A página Uma introdução aos tipos de dados do Redis e abstrações no site do Redis fornece uma visão geral mais detalhada desses tipos e os comandos que você pode usar para manipulá-los.
Esta seção resume alguns casos de uso comuns para esses comandos e tipos de dados.
Executar operações atômicas e em lote
O Redis oferece suporte a uma série de operações atômicas de obtenção e definição de valores de cadeia de caracteres. Essas operações removem os riscos de corrida possíveis que podem ocorrer ao usar comandos GET e SET separados. As operações disponíveis incluem:
INCR,INCRBY,DECReDECRBY, que executam operações atômicas de acréscimo e decréscimo em valores de dados numéricos inteiros. A biblioteca do StackExchange fornece versões sobrecarregadas dos métodosIDatabase.StringIncrementAsynceIDatabase.StringDecrementAsyncpara executar essas operações e retornam o valor resultante armazenado no cache. O snippet de código a seguir ilustra como usar estes métodos:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... await cache.StringSetAsync("data:counter", 99); ... long oldValue = await cache.StringIncrementAsync("data:counter"); // Increment by 1 (the default) // oldValue should be 100 long newValue = await cache.StringDecrementAsync("data:counter", 50); // Decrement by 50 // newValue should be 50GETSETque recupera o valor associado a uma chave e altera-o para um novo valor. A biblioteca do StackExchange disponibiliza essa operação por meio do métodoIDatabase.StringGetSetAsync. O snippet de código a seguir mostra um exemplo desse método. Esse código retorna o valor atual associado à chave "data:counter" do exemplo anterior. Em seguida, ele redefine o valor desta chave como zero, tudo como parte da mesma operação:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... string oldValue = await cache.StringGetSetAsync("data:counter", 0);MGETeMSET, que podem retornar ou alterar um conjunto de valores de cadeia de caracteres como uma única operação. Os métodosIDatabase.StringGetAsynceIDatabase.StringSetAsyncsão sobrecarregados para oferecerem suporte a essa funcionalidade, conforme mostrado no exemplo a seguir:ConnectionMultiplexer redisHostConnection = ...; IDatabase cache = redisHostConnection.GetDatabase(); ... // Create a list of key-value pairs var keysAndValues = new List<KeyValuePair<RedisKey, RedisValue>>() { new KeyValuePair<RedisKey, RedisValue>("data:key1", "value1"), new KeyValuePair<RedisKey, RedisValue>("data:key99", "value2"), new KeyValuePair<RedisKey, RedisValue>("data:key322", "value3") }; // Store the list of key-value pairs in the cache cache.StringSet(keysAndValues.ToArray()); ... // Find all values that match a list of keys RedisKey[] keys = { "data:key1", "data:key99", "data:key322"}; // values should contain { "value1", "value2", "value3" } RedisValue[] values = cache.StringGet(keys);
Você também pode combinar várias operações em uma única transação Redis, conforme descrito na seção Transações e lotes do Redis, anteriormente neste artigo. A biblioteca do StackExchange fornece suporte para transações por meio da interface ITransaction.
Crie um objeto ITransaction usando o método IDatabase.CreateTransaction. Invoque comandos para a transação usando os métodos fornecidos pelo objeto ITransaction .
A interface ITransaction fornece acesso a um conjunto de métodos semelhantes àqueles acessados pela interface IDatabase, exceto pelo fato de que todos os métodos são assíncronos. Isso significa que eles são executados apenas quando o método ITransaction.Execute é invocado. O valor retornado pelo método ITransaction.Execute indica se a transação foi criada com êxito (true) ou se falhou (false).
O snippet de código a seguir mostra um exemplo em que ocorre incremento e decremento a dois contadores como parte da mesma transação:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
ITransaction transaction = cache.CreateTransaction();
var tx1 = transaction.StringIncrementAsync("data:counter1");
var tx2 = transaction.StringDecrementAsync("data:counter2");
bool result = transaction.Execute();
Console.WriteLine("Transaction {0}", result ? "succeeded" : "failed");
Console.WriteLine("Result of increment: {0}", tx1.Result);
Console.WriteLine("Result of decrement: {0}", tx2.Result);
Lembre-se de que as transações de Redis são diferentes de transações em bancos de dados relacionais. O método Execute simplesmente coloca em fila todos os comandos que compõem a transação que será executada e, se algum deles estiver malformado, a transação será interrompida. Se todos os comandos foram enfileirados com êxito, cada comando será executado de modo assíncrono.
Se algum comando falhar, o processamento dos outros ainda continuará. Se você precisar verificar se um comando foi concluído com êxito, você deve buscar os resultados do comando usando a propriedade Result da tarefa correspondente, conforme mostrado no exemplo acima. A leitura da propriedade Result bloqueará o thread chamador até a conclusão da tarefa.
Para saber mais, confira Transações em Redis.
Ao executar operações em lote, você pode usar a interface IBatch da biblioteca do StackExchange. Essa interface fornece acesso a um conjunto de métodos semelhantes àqueles acessados pela interface IDatabase , exceto pelo fato de que todos os métodos são assíncronos.
Você cria um objeto IBatch usando o método IDatabase.CreateBatch e, em seguida, executa o lote usando o método IBatch.Execute, conforme mostra o exemplo a seguir. Esse código simplesmente define um valor de cadeia de caracteres, incrementa e decrementa os mesmos contadores usados no exemplo anterior e exibe os resultados:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
IBatch batch = cache.CreateBatch();
batch.StringSetAsync("data:key1", 11);
var t1 = batch.StringIncrementAsync("data:counter1");
var t2 = batch.StringDecrementAsync("data:counter2");
batch.Execute();
Console.WriteLine("{0}", t1.Result);
Console.WriteLine("{0}", t2.Result);
É importante entender que, ao contrário de uma transação, se um comando em um lote falhar por estar malformado, outros comandos ainda poderão ser executados. O método IBatch.Execute não retorna qualquer indicação de sucesso ou falha.
Executar operações de cache do tipo disparar e esquecer
O Redis oferece suporte a operações do tipo disparar e esquecer usando sinalizadores de comando. Nessa situação, o cliente simplesmente inicia uma operação, mas não tem interesse no resultado e não espera até o comando ser concluído. O exemplo a seguir mostra como executar o comando INCR como uma operação de disparar e esquecer:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
await cache.StringSetAsync("data:key1", 99);
...
cache.StringIncrement("data:key1", flags: CommandFlags.FireAndForget);
Especificar chaves com validade automática
Quando você armazena um item em um cache do Redis, você pode especificar um tempo limite após o qual o item será removido automaticamente do cache. Você também pode consultar quanto tempo uma chave ainda tem antes de expirar usando o comando TTL . Esse comando está disponível para aplicativos do StackExchange usando o método IDatabase.KeyTimeToLive .
O snippet de código a seguir mostra como configurar um tempo de expiração de 20 segundos em uma chave, e consulta do ciclo de vida restante da chave:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration time of 20 seconds
await cache.StringSetAsync("data:key1", 99, TimeSpan.FromSeconds(20));
...
// Query how much time a key has left to live
// If the key has already expired, the KeyTimeToLive function returns a null
TimeSpan? expiry = cache.KeyTimeToLive("data:key1");
Você também pode definir o horário de expiração para uma data e hora específicos usando o comando EXPIRE, disponível na biblioteca do StackExchange como o método KeyExpireAsync :
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Add a key with an expiration date of midnight on 1st January 2015
await cache.StringSetAsync("data:key1", 99);
await cache.KeyExpireAsync("data:key1",
new DateTime(2015, 1, 1, 0, 0, 0, DateTimeKind.Utc));
...
Dica
Você pode remover manualmente um item do cache usando o comando DEL, que está disponível por meio da biblioteca do StackExchange como o método IDatabase.KeyDeleteAsync.
Usar marcas para correlação cruzada entre itens em cache
Um conjunto do Redis é uma coleção de vários itens que compartilham uma única chave. Você pode criar um conjunto usando o comando SADD. Você pode recuperar os itens em um conjunto usando o comando SMEMBERS. A biblioteca do StackExchange implementa o comando SADD com o método IDatabase.SetAddAsync, e o comando SMEMBERS com o método IDatabase.SetMembersAsync.
Você também pode combinar conjuntos existentes para criar novos conjuntos usando os comandos SUNION (união de conjunto), SINTER (interseção de conjunto) e SDIFF (diferença de conjunto). A biblioteca do StackExchange unifica essas operações no método IDatabase.SetCombineAsync . O primeiro parâmetro para esse método especifica a operação set a ser executada.
Os snippets de código a seguir mostram como conjuntos podem ser úteis para armazenar e recuperar coleções de itens relacionados rapidamente. Esse código usa o tipo BlogPost , que foi descrito na seção Implementar aplicativos de cliente do Cache Redis, anteriormente neste artigo.
Um objeto BlogPost contém quatro campos — uma ID, um título, uma pontuação de classificação e uma coleção de marcas. O primeiro snippet de código abaixo mostra os dados de exemplo usados para popular uma lista em C# com objetos BlogPost :
List<string[]> tags = new List<string[]>
{
new[] { "iot","csharp" },
new[] { "iot","azure","csharp" },
new[] { "csharp","git","big data" },
new[] { "iot","git","database" },
new[] { "database","git" },
new[] { "csharp","database" },
new[] { "iot" },
new[] { "iot","database","git" },
new[] { "azure","database","big data","git","csharp" },
new[] { "azure" }
};
List<BlogPost> posts = new List<BlogPost>();
int blogKey = 0;
int numberOfPosts = 20;
Random random = new Random();
for (int i = 0; i < numberOfPosts; i++)
{
blogKey++;
posts.Add(new BlogPost(
blogKey, // Blog post ID
string.Format(CultureInfo.InvariantCulture, "Blog Post #{0}",
blogKey), // Blog post title
random.Next(100, 10000), // Ranking score
tags[i % tags.Count])); // Tags--assigned from a collection
// in the tags list
}
Você pode armazenar as marcas para cada objeto BlogPost como um conjunto em um cache do Redis e associar cada conjunto à ID do BlogPost. Isso permite que um aplicativo localize rapidamente todas as marcas que pertencem a uma postagem de blog específica. Para habilitar a pesquisa na direção oposta e localizar todas as postagens de blog que compartilham uma marca específica, você pode criar outro conjunto contendo postagens de blog que fazem referência à ID de marca na chave:
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
// Tags are easily represented as Redis Sets
foreach (BlogPost post in posts)
{
string redisKey = string.Format(CultureInfo.InvariantCulture,
"blog:posts:{0}:tags", post.Id);
// Add tags to the blog post in Redis
await cache.SetAddAsync(
redisKey, post.Tags.Select(s => (RedisValue)s).ToArray());
// Now do the inverse so we can figure out which blog posts have a given tag
foreach (var tag in post.Tags)
{
await cache.SetAddAsync(string.Format(CultureInfo.InvariantCulture,
"tag:{0}:blog:posts", tag), post.Id);
}
}
Essas estruturas permitem executar muitas consultas comuns de maneira muito eficiente. Por exemplo, você pode encontrar e exibir todas as marcas para a postagem de blog 1 desse modo:
// Show the tags for blog post #1
foreach (var value in await cache.SetMembersAsync("blog:posts:1:tags"))
{
Console.WriteLine(value);
}
Você pode encontrar todas as marcas que são comuns às postagens de blog 1 e 2 executando uma operação de interseção de conjunto, da seguinte maneira:
// Show the tags in common for blog posts #1 and #2
foreach (var value in await cache.SetCombineAsync(SetOperation.Intersect, new RedisKey[]
{ "blog:posts:1:tags", "blog:posts:2:tags" }))
{
Console.WriteLine(value);
}
E você pode encontrar todas as postagens de blog que contêm uma marca específica:
// Show the ids of the blog posts that have the tag "iot".
foreach (var value in await cache.SetMembersAsync("tag:iot:blog:posts"))
{
Console.WriteLine(value);
}
Localizar itens acessados recentemente
Uma tarefa comum exigida para muitos aplicativos é localizar os itens acessados mais recentemente. Por exemplo, um site de blog talvez queira exibir informações sobre as postagens de blog lidas mais recentemente.
Você pode implementar essa funcionalidade usando uma lista do Redis. Uma lista do Redis contém vários itens que compartilham a mesma chave. A lista atua como uma fila com duas extremidades. Usando os comandos LPUSH (deslocar para a esquerda) e RPUSH (deslocar para a direita), você pode enviar itens para ambas as extremidades da lista. Você pode recuperar itens de qualquer das duas extremidades da lista usando os comandos LPOP e RPOP. Você também pode retornar um conjunto de elementos usando os comandos LRANGE e RRANGE.
Os snippets de código a seguir mostram como você pode executar essas operações usando a biblioteca do StackExchange. Esse código usa o tipo BlogPost dos exemplos anteriores. Conforme uma postagem de blog é lida por um usuário, o método IDatabase.ListLeftPushAsync envia o título da postagem de blog para uma lista associada à chave "blog:recent_posts" no cache do Redis.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:recent_posts";
BlogPost blogPost = ...; // Reference to the blog post that has just been read
await cache.ListLeftPushAsync(
redisKey, blogPost.Title); // Push the blog post onto the list
Conforme mais postagens do blog são lidas, seus títulos são deslocados pela mesma lista. A lista é ordenada de acordo com a sequência na qual os títulos foram adicionados. As postagens no blog lidas mais recentemente estão na extremidade esquerda da lista. (Se a mesma postagem de blog for lida mais de uma vez, ela terá várias entradas na lista).
Você pode exibir os títulos das postagens lidas mais recentemente usando o método IDatabase.ListRange . Este método usa a chave que contém a lista, um ponto inicial e um ponto final. O código a seguir recupera os títulos das 10 postagens de blog (itens de 0 a 9) posicionadas mais à esquerda na lista:
// Show latest ten posts
foreach (string postTitle in await cache.ListRangeAsync(redisKey, 0, 9))
{
Console.WriteLine(postTitle);
}
Observe que o método ListRangeAsync não remove itens da lista. Para fazer isso, você pode usar os métodos IDatabase.ListLeftPopAsync e IDatabase.ListRightPopAsync.
Para impedir que a lista aumente indefinidamente, você pode retirar itens periodicamente, encurtando a lista. O snippet de código a seguir mostra como remover todos os itens, com exceção dos cinco itens mais à esquerda na lista:
await cache.ListTrimAsync(redisKey, 0, 5);
Implementar uma classificação
Por padrão, os itens em um conjunto não são mantidos em nenhuma ordem específica. Você pode criar um conjunto ordenado, usando o comando ZADD (o método IDatabase.SortedSetAdd na biblioteca do StackExchange). Os itens são ordenados por meio de um valor numérico chamado de pontuação, que é fornecido como um parâmetro para o comando.
O snippet de código a seguir adiciona o título de uma postagem de blog a uma lista ordenada. No exemplo, cada publicação de blog também tem um campo de pontuação que contém a classificação da postagem do blog.
ConnectionMultiplexer redisHostConnection = ...;
IDatabase cache = redisHostConnection.GetDatabase();
...
string redisKey = "blog:post_rankings";
BlogPost blogPost = ...; // Reference to a blog post that has just been rated
await cache.SortedSetAddAsync(redisKey, blogPost.Title, blogPost.Score);
Você pode recuperar os títulos de postagens de blog em ordem crescente segundo a pontuação usando o método IDatabase.SortedSetRangeByRankWithScores:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(redisKey))
{
Console.WriteLine(post);
}
Observação
A biblioteca do StackExchange também fornece o método IDatabase.SortedSetRangeByRankAsync que retorna os dados em ordem de pontuação, mas não retorna as pontuações.
Você também pode recuperar itens em ordem decrescente segundo suas pontuações e limitar o número de itens retornados, fornecendo parâmetros adicionais ao método IDatabase.SortedSetRangeByRankWithScoresAsync. O exemplo a seguir exibe os títulos e pontuações das 10 postagens de blog com melhor classificação:
foreach (var post in await cache.SortedSetRangeByRankWithScoresAsync(
redisKey, 0, 9, Order.Descending))
{
Console.WriteLine(post);
}
O exemplo a seguir usa o método IDatabase.SortedSetRangeByScoreWithScoresAsync , que você pode usar para limitar os itens retornados àqueles cuja pontuação se encontra em um determinado intervalo:
// Blog posts with scores between 5000 and 100000
foreach (var post in await cache.SortedSetRangeByScoreWithScoresAsync(
redisKey, 5000, 100000))
{
Console.WriteLine(post);
}
Mensagem usando canais
Além de atuar como um cache de dados, um servidor Redis oferece envio de mensagens por meio de um mecanismo de editor/assinante de alto desempenho. Aplicativos cliente podem se inscrever em um canal, enquanto outros aplicativos ou serviços podem publicar mensagens no canal. Aplicativos inscritos receberão então essas mensagens e poderão processá-las.
O Redis fornece o comando SUBSCRIBE para aplicativos cliente usarem para se inscrever em canais. Esse comando espera que o nome de um ou mais canais no qual o aplicativo aceitará mensagens. A biblioteca do StackExchange inclui a interface ISubscription, que habilita um aplicativo do .NET Framework a inscrever-se e publicar em canais.
Crie um objeto ISubscription usando o método GetSubscriber da conexão com o servidor Redis. Em seguida, escute as mensagens em um canal usando o método SubscribeAsync desse objeto. O exemplo de código a seguir mostra como assinar um canal denominado "messages:blogPosts":
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
await subscriber.SubscribeAsync("messages:blogPosts", (channel, message) => Console.WriteLine("Title is: {0}", message));
O primeiro parâmetro para o método Subscribe é o nome do canal. Esse nome segue as mesmas convenções usadas por chaves no cache. O nome pode conter quaisquer dados binários, mas recomendamos usar cadeias de caracteres relativamente curtas e significativas para ajudar a garantir o bom desempenho e a capacidade de manutenção.
Observe também que o namespace usado pelos canais é separado daquele usado por chaves. Isso significa que você pode ter canais e chaves com o mesmo nome, embora isso possa dificultar ainda mais a manutenção do código de seu aplicativo.
O segundo parâmetro é um delegado Action. Esse delegado é executado assincronamente sempre que uma nova mensagem aparece no canal. Este exemplo simplesmente exibe a mensagem no console (a mensagem conterá o título de uma postagem de blog).
Para publicar em um canal, um aplicativo pode usar o comando PUBLISH do Redis. A biblioteca do StackExchange fornece o método IServer.PublishAsync para executar essa operação. O próximo snippet de código mostra como publicar uma mensagem no canal "messages:blogPosts":
ConnectionMultiplexer redisHostConnection = ...;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
...
BlogPost blogPost = ...;
subscriber.PublishAsync("messages:blogPosts", blogPost.Title);
Há vários pontos que você deve compreender sobre o mecanismo de publicação/assinatura:
- Vários assinantes podem se inscrever no mesmo canal, e todos eles receberão as mensagens publicadas nesse canal.
- Os assinantes só recebem mensagens que foram publicadas depois de sua inscrição. Os canais não são armazenados em buffer e, assim que uma mensagem é publicada, a infraestrutura do Redis envia a mensagem por push para cada assinante e depois a remove.
- Por padrão, as mensagens são recebidas pelos assinantes na ordem em que são enviadas. Em um sistema muito ativo com um grande número de mensagens e muitos editores e assinantes, entrega sequencial garantida de mensagens pode diminuir o desempenho do sistema. Se cada mensagem for independente e a ordem for irrelevante, você poderá habilitar processamento simultâneo pelo sistema Redis, que pode ajudar a melhorar a capacidade de resposta. Você pode obter isso em um cliente StackExchange definindo a PreserveAsyncOrder da conexão usada pelo assinante como false:
ConnectionMultiplexer redisHostConnection = ...;
redisHostConnection.PreserveAsyncOrder = false;
ISubscriber subscriber = redisHostConnection.GetSubscriber();
Considerações sobre serialização
Quando você escolher um formato de serialização, considere o equilíbrio entre desempenho, interoperabilidade, controle de versão, compatibilidade com sistemas existentes, compactação de dados e sobrecarga de memória. Quando você avaliar o desempenho, lembre-se de que os benchmarks são altamente dependentes do contexto. Eles podem não refletir sua carga de trabalho real e podem não considerar as bibliotecas ou as versões mais recentes. Não há nenhum serializador "rápido" único para todos os cenários.
Algumas opções a serem consideradas incluem:
Buffers de Protocolo (também chamado de protobuf) é um formato de serialização desenvolvido pelo Google para serializar dados estruturados de forma eficiente. Ele usa arquivos de definição fortemente tipados para definir estruturas de mensagem. Esses arquivos de definição, em seguida, são compilados para código de linguagem específico para serialização e desserialização de mensagens. O Protobuf pode ser usado em mecanismos existentes de RPC, ou pode gerar um serviço RPC.
O Apache Thrift usa uma abordagem semelhante, com arquivos de definição fortemente tipados e uma etapa de compilação para gerar o código de serialização e os serviços RPC.
O Apache Avro oferece funcionalidade semelhante à de Buffers de Protocolo e Thrift, mas não há nenhuma etapa de compilação. Em vez disso, os dados serializados sempre incluem um esquema que descreve a estrutura.
O JSON é um padrão aberto que usa campos de texto legível. Ele tem amplo suporte de plataforma cruzada. O JSON não usa os esquemas de mensagens. Como é um formato baseado em texto, não é muito eficiente eletronicamente. Em alguns casos, no entanto, você pode estar retornando itens em cache diretamente para um cliente por HTTP, caso no qual armazenar o JSON poderá economizar o custo de desserialização de outro formato e então serializar para JSON.
O JSON binário (BSON) é um formato de serialização binária que usa uma estrutura semelhante ao JSON. O BSON foi projetado para ser leve, fácil de examinar e rápido para serializar e desserializar em relação ao JSON. As cargas são semelhantes em tamanho às do JSON. Dependendo dos dados, uma carga BSON pode ser menor ou maior do que uma carga JSON. O BSON tem alguns tipos de dados adicionais que não estão disponíveis em JSON, especialmente BinData (para matrizes de bytes) e Date.
MessagePack é um formato de serialização binária projetado para ser compacto para transmissão eletrônica. Não existem esquemas de mensagens ou verificação de tipo de mensagem.
O Bond é uma estrutura de plataforma cruzada para trabalhar com dados esquematizados. Ele dá suporte à serialização e à desserialização entre linguagens. As diferenças perceptíveis de outros sistemas listados aqui são suporte a herança, aliases de tipo e genéricos.
O gRPC é um sistema RPC de código aberto desenvolvido pela Google. Por padrão, ele usa o Buffers de Protocolo como sua linguagem de definição e o formato de intercâmbio de mensagens subjacente.
Próximas etapas
- Documentação do Cache do Azure para Redis
- Perguntas frequentes sobre o Cache Redis do Azure
- Padrão assíncrono baseado em tarefa
- Documentação de Redis
- StackExchange.Redis
- Guia de particionamento de dados
Recursos relacionados
Os padrões a seguir também podem ser relevantes para seu cenário ao implementar cache em seus aplicativos:
O padrão Cache-aside: esse padrão descreve como carregar dados em um cache sob demanda por meio de um repositório de dados. Esse padrão também ajuda a manter a consistência entre os dados armazenados no cache e os dados no repositório de dados original.
O padrão Sharding fornece informações sobre como implementar o particionamento horizontal, para ajudar a melhorar a escalabilidade ao armazenar e acessar grandes volumes de dados.