O TDSP é uma metodologia de ciência de dados ágil e iterativa que você pode usar para fornecer soluções de análise preditiva e aplicativos de IA com eficiência. O TDSP aprimora a colaboração e o aprendizado da equipe, recomendando formas de integrações ideais das funções dela. O TDSP incorpora as práticas recomendadas e as estruturas da Microsoft e de outros líderes do setor para ajudar sua equipe a implementar iniciativas de ciência de dados com eficiência. O TDSP permite que você aproveite todos os benefícios do seu programa de análise.
Este artigo fornece uma visão geral do TDSP e de seus principais componentes. Ele apresenta orientações sobre como implementar o TDSP usando ferramentas e infraestrutura da Microsoft. Você pode encontrar recursos mais detalhados ao longo do artigo.
Principais componentes do TDSP
O TDSP tem os seguintes componentes principais:
- Uma definição de ciclo de vida de ciência de dados
- Estrutura de projeto padronizada
- Infraestrutura e recursos ideais para projetos de ciência de dados
- IA responsável: e um compromisso com o avanço da IA, impulsionado por princípios éticos
Ciclo de vida de ciência de dados
O TDSP fornece um ciclo de vida que você pode usar para estruturar o desenvolvimento de seus projetos de ciência de dados. O ciclo de vida descreve as etapas completas que projetos bem-sucedidos seguem.
Você pode combinar o TDSP baseado em tarefas com outros ciclos de vida da ciência de dados, como o processo padrão intersetorial para mineração de dados (CRISP-DM), o processo de descoberta de conhecimento em bancos de dados (KDD) ou outro processo personalizado. Em um alto nível, essas metodologias diferentes têm muito em comum.
Use esse ciclo de vida se tiver um projeto de ciência de dados que faça parte de um aplicativo inteligente. Aplicativos inteligentes implantam modelos de aprendizado de máquina ou IA para análise preditiva. Você também pode usar este processo para projetos de ciência de dados exploratórios e os projetos de análise improvisados.
O ciclo de vida do TDSP consiste em cinco estágios principais que sua equipe executa de forma iterativa. Esses estágios incluem:
- Noções básicas sobre negócios
- Aquisição de dados e entendimento
- Modelagem
- Implantação
- Aceitação do cliente
Esta é uma representação visual do ciclo de vida do TDSP:
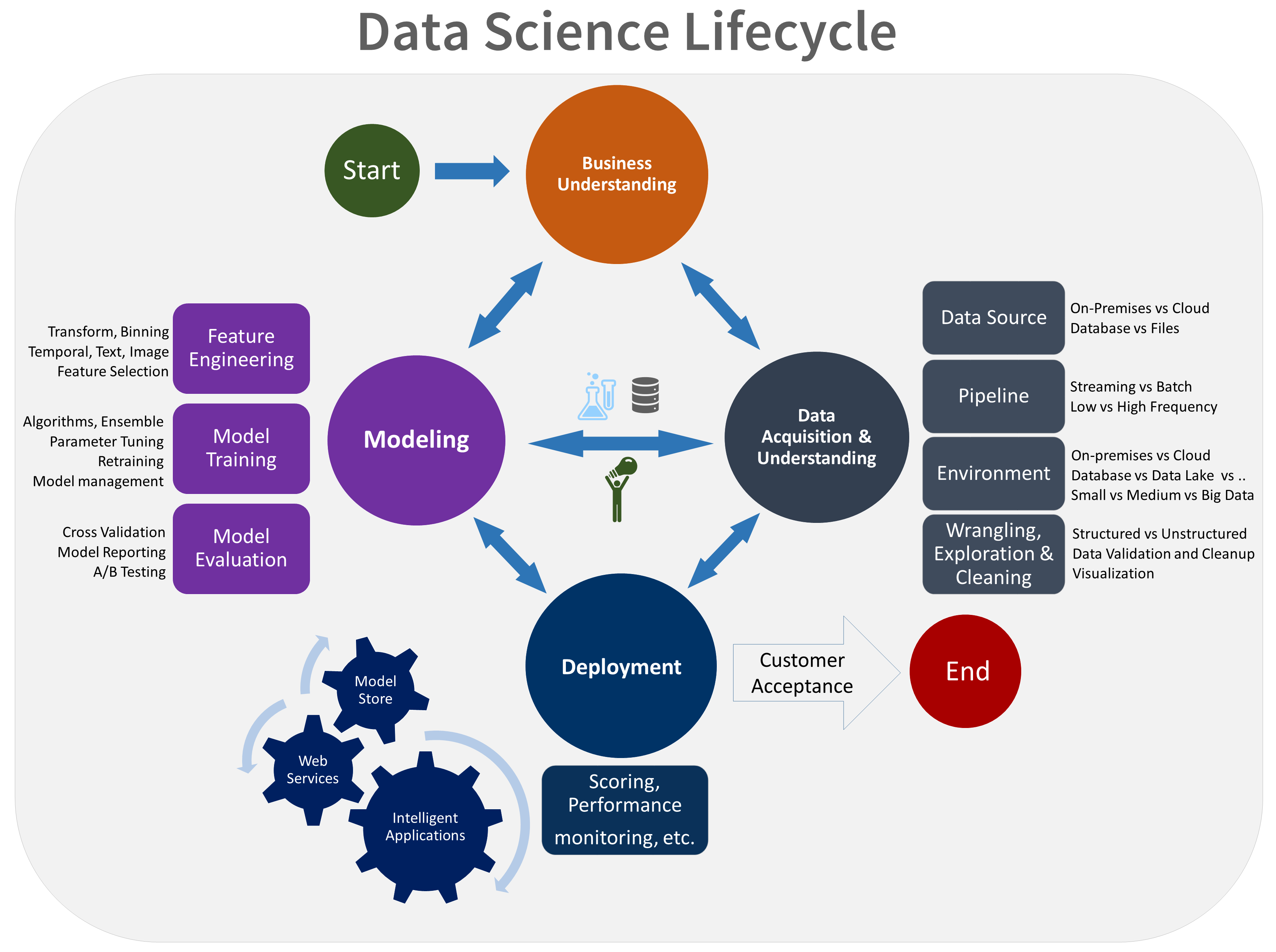
Para obter mais informações sobre as metas, tarefas e artefatos de documentação para cada estágio, consulte O ciclo de vida do TDSP.
Essas tarefas e artefatos se alinham a funções do projeto, como:
- Arquiteto de solução
- Gerente de projeto
- Engenheiro de dados
- Cientista de dados
- Desenvolvedor de aplicativo
- Líder de projeto
O diagrama a seguir exibe as tarefas (em azul), e os artefatos (em verde) que correspondem a cada estágio do ciclo de vida mostrado no eixo horizontal e para as funções mostradas no eixo vertical.

Estrutura de projeto padronizada
Sua equipe pode usar a infraestrutura do Azure para organizar seus ativos de ciência de dados.
O Azure Machine Learning dá suporte ao MLflow de código aberto. Recomendamos o uso do MLflow para ciência de dados e gerenciamento de projetos de IA. O MLflow foi projetado para gerenciar o ciclo de vida completo do aprendizado de máquina. Ele treina e serve modelos em diferentes plataformas, para que você possa usar um conjunto consistente de ferramentas, independentemente de onde seus experimentos são executados. Você pode usar o MLflow localmente em seu computador, em um destino de computação remoto, em uma máquina virtual ou em uma instância de computação do Machine Learning.
O MLflow consiste em várias funcionalidades principais:
Acompanhar experimentos: você pode usar o MLflow para acompanhar os experimentos, incluindo parâmetros, versões de código, métricas e arquivos de saída. Esse recurso ajuda você a comparar diferentes execuções e gerenciar o processo de experimentação de forma eficiente.
Código do pacote: ele fornece um formato padronizado para empacotar código de aprendizado de máquina, que inclui dependências e configurações. Esse empacotamento facilita a reprodução de execuções e o compartilhamento de código com outras pessoas.
Gerenciar modelos: o MLflow fornece funcionalidades para gerenciamento e controle de versão de modelos. Ele oferece suporte a várias estruturas de aprendizado de máquina para que você possa armazenar e fornecer modelos, bem como controlar suas versões.
Fornecer e implantar modelos: o MLflow integra recursos de serviço e implantação de modelos para que você possa implantar modelos facilmente em diversos ambientes.
Registrar modelos: você pode gerenciar o ciclo de vida de um modelo, incluindo controle de versão, transições de estágio e anotações. Você pode usar o MLflow para manter um repositório de modelos centralizado em um ambiente colaborativo.
Use uma API e uma interface do usuário: dentro do Azure, o MLflow é empacotado na API do Machine Learning versão 2, para que você possa interagir com o sistema programaticamente. Você pode usar o portal do Azure para interagir com uma interface do usuário.
O MLflow simplifica e padroniza o processo de desenvolvimento de aprendizado de máquina, desde a experimentação até a implantação.
O Machine Learning integra-se aos repositórios Git para que você possa usar muitos serviços compatíveis com Git, como GitHub, GitLab, Bitbucket, Azure DevOps ou outro serviço compatível com Git. Além dos ativos já rastreados no Machine Learning, sua equipe pode desenvolver sua própria taxonomia dentro de seu serviço compatível com Git para armazenar outros dados do projeto, como:
- Documentação
- Dados do projeto: por exemplo, o relatório final do projeto
- Relatório de dados: por exemplo, o dicionário de dados ou relatórios de qualidade de dados
- Modelo: por exemplo, relatórios de modelos
- Código
- Preparação de dados
- Desenvolvimento do modelo
- Operacionalização, que inclui segurança e conformidade
Infraestrutura e recursos
O TDSP fornece recomendações sobre como gerenciar a infraestrutura compartilhada de análise e armazenamento nas seguintes categorias:
- Sistemas de arquivos de nuvem para armazenar conjuntos de dados
- Banco de dados de nuvem
- Clusters de Big Data que usam SQL ou Spark
- Serviços de aprendizado de máquina e IA
Sistemas de arquivos de nuvem para armazenar conjuntos de dados
Os sistemas de arquivos em nuvem são cruciais para o TDSP por vários motivos:
Armazenamento centralizado de dados: os sistemas de arquivos de nuvem fornecem um local centralizado para armazenar conjuntos de dados, o que é essencial para a colaboração entre os membros da equipe de ciência de dados. A centralização garante que todos os membros da equipe possam acessar os dados mais atuais e reduz o risco de trabalhar com conjuntos de dados desatualizados ou inconsistentes.
Escalabilidade: os sistemas de arquivos de nuvem podem lidar com grandes volumes de dados, o que é comum em projetos de ciência de dados. Os sistemas de arquivos fornecem soluções de armazenamento escaláveis que crescem de acordo com as necessidades do projeto. Eles permitem que as equipes armazenem e processem grandes conjuntos de dados sem se preocupar com limitações de hardware.
Acessibilidade: com sistemas de arquivos de nuvem, você pode acessar dados de qualquer lugar com conexão à Internet. Esse acesso é importante para equipes distribuídas ou quando os membros da equipe precisam trabalhar remotamente. Os sistemas de arquivos de nuvem facilitam a colaboração perfeita e garantem que os dados estejam sempre acessíveis.
Segurança e conformidade: os provedores de nuvem geralmente implementam medidas de segurança robustas, que incluem criptografia, controles de acesso e conformidade com os padrões e regulamentos do setor. Medidas de segurança fortes podem proteger dados confidenciais e ajudar sua equipe a atender aos requisitos legais e regulatórios.
Controle de versão: os sistemas de arquivos de nuvem geralmente incluem recursos de controle de versão que as equipes podem usar para rastrear alterações nos conjuntos de dados ao longo do tempo. O controle de versão é crucial para manter a integridade dos dados e reproduzir os resultados em projetos de ciência de dados. Ele também ajuda a auditar e solucionar quaisquer problemas que surgirem.
Integração com ferramentas: os sistemas de arquivos de nuvem podem se integrar perfeitamente a várias ferramentas e plataformas de ciência de dados. A integração de ferramentas facilita a ingestão, o processamento e a análise de dados. Por exemplo, o Armazenamento do Azure se integra bem ao Machine Learning, ao Azure Databricks e a outras ferramentas de ciência de dados.
Colaboração e compartilhamento: os sistemas de arquivos de nuvem facilitam o compartilhamento de conjuntos de dados com outros membros da equipe ou stakeholders. Esses sistemas dão suporte a recursos colaborativos, como pastas compartilhadas e gerenciamento de permissões. Os recursos de colaboração facilitam o trabalho em equipe e garantem que as pessoas certas tenham acesso aos dados de que precisam.
Redução de custos: os sistemas de arquivos de nuvem podem ser mais econômicos do que manter soluções de armazenamento local. Os provedores de nuvem têm modelos de preços flexíveis que incluem opções de pagamento conforme o uso, que podem ajudar a gerenciar custos com base no uso real e nos requisitos de armazenamento do seu projeto de ciência de dados.
Recuperação de desastres: os sistemas de arquivos de nuvem geralmente incluem recursos para backup de dados e recuperação de desastres. Esses recursos ajudam a proteger os dados contra falhas de hardware, exclusões acidentais e outros desastres. Eles proporcionam tranquilidade e dão suporte à continuidade nas operações de ciência de dados.
Automação e integração de fluxo de trabalho: os sistemas de armazenamento em nuvem podem se integrar a fluxos de trabalho automatizados, o simplifica a transferência de dados entre diferentes estágios do processo de ciência de dados. A automação pode ajudar a melhorar a eficiência e reduzir o esforço manual necessário para gerenciar dados.
Recursos recomendados do Azure para sistemas de arquivos de nuvem
- Armazenamento de Blobs do Azure: documentação abrangente sobre o Armazenamento de Blobs do Azure, que é um serviço de armazenamento de objetos escalonável para dados não estruturados.
- Azure Data Lake Storage: informações sobre o Azure Data Lake Storage Gen2, criado para análise de Big Data e que dá suporte a conjuntos de dados em grande escala.
- Arquivos do Azure: detalhes sobre os Arquivos do Azure, que permitem compartilhamentos de arquivos totalmente gerenciados na nuvem.
Em suma, os sistemas de arquivos de nuvem são cruciais para o TDSP, pois fornecem soluções de armazenamento escaláveis, seguras e acessíveis que dão suporte a todo o ciclo de vida dos dados. Os sistemas de arquivos de nuvem permitem a integração perfeita de dados de várias fontes, o que dá suporte à aquisição e à compreensão abrangentes de dados. Os cientistas de dados podem usar sistemas de arquivos de nuvem para armazenar, gerenciar e acessar com eficiência grandes conjuntos de dados. Essa funcionalidade é essencial para treinar e implantar modelos de aprendizado de máquina. Esses sistemas também aprimoram a colaboração, permitindo que os membros da equipe compartilhem e trabalhem em dados simultaneamente em um ambiente unificado. Os sistemas de arquivos de nuvem fornecem recursos de segurança robustos que ajudam a proteger os dados e torná-los compatíveis com os requisitos regulatórios, o que é vital para manter a integridade e a confiança dos dados.
Banco de dados de nuvem
Os bancos de dados de nuvem desempenham um papel crítico no TDSP por vários motivos:
Escalabilidade: os bancos de dados de nuvem fornecem soluções escaláveis que podem crescer facilmente para atender às crescentes necessidades de dados de um projeto. A escalabilidade é crucial para projetos de ciência de dados que frequentemente lidam com conjuntos de dados grandes e complexos. Os bancos de dados de nuvem podem lidar com cargas de trabalho variadas sem a necessidade de intervenção manual ou atualizações de hardware.
Otimização de desempenho: os desenvolvedores otimizam os bancos de dados de nuvem para desempenho usando recursos como indexação automática, otimização de consulta e balanceamento de carga. Esses recursos ajudam a garantir que a recuperação e o processamento de dados sejam rápidos e eficientes, o que é crucial para tarefas de ciência de dados que exigem acesso a dados em tempo real ou quase em tempo real.
Acessibilidade e colaboração: as equipes podem acessar dados armazenados em bancos de dados de nuvem de qualquer local. Essa acessibilidade promove a colaboração entre os membros da equipe que podem estar geograficamente dispersos. A acessibilidade e a colaboração são importantes para equipes distribuídas ou pessoas que trabalham remotamente. Os bancos de dados de nuvem dão suporte a ambientes multiusuário que permitem acesso e colaboração simultâneos.
Integração com ferramentas de ciência de dados: os bancos de dados de nuvem se integram perfeitamente a várias ferramentas e plataformas de ciência de dados. Por exemplo, os bancos de dados de nuvem do Azure se integram bem ao Machine Learning, Power BI e outras ferramentas de análise de dados. Essa integração simplifica o pipeline de dados, desde a ingestão e o armazenamento até a análise e a visualização.
Segurança e conformidade: os provedores de nuvem implementam medidas de segurança robustas que incluem criptografia de dados, controles de acesso e conformidade com os padrões e regulamentos do setor. Medidas de segurança protegem dados confidenciais e ajudar sua equipe a atender aos requisitos legais e regulatórios. Os recursos de segurança são vitais para manter a integridade e a privacidade dos dados.
Redução de custos: os bancos de dados de nuvem frequentemente operam em um modelo de pagamento conforme o uso, que pode ser mais econômico do que manter sistemas de bancos de dados locais. Essa flexibilidade de preços permite que as organizações gerenciem seus orçamentos com eficiência e paguem apenas pelos recursos de armazenamento e computação que usam.
Backups automáticos e recuperação de desastres: os bancos de dados de nuvem fornecem soluções automáticas de backup e recuperação de desastres. Essas soluções ajudam a evitar a perda de dados se houver falhas de hardware, exclusões acidentais ou outros desastres. A confiabilidade é crucial para manter a continuidade e a integridade dos dados em projetos de ciência de dados.
Processamento de dados em tempo real: muitos bancos de dados de nuvem oferecem suporte ao processamento e à análise de dados em tempo real, o que é essencial para tarefas de ciência de dados que exigem as informações mais atuais. Esse recurso ajuda os cientistas de dados a tomar decisões oportunas com base nos dados disponíveis mais recentes.
Integração de dados: os bancos de dados de nuvem podem se integrar facilmente a outras fontes de dados, bancos de dados, data lakes e feeds de dados externos. A integração ajuda os cientistas de dados a combinar dados de várias fontes e fornece uma visão abrangente e uma análise mais sofisticada.
Flexibilidade e variedade: os bancos de dados de nuvem vêm em várias formas, como bancos de dados relacionais, bancos de dados NoSQL e data warehouses. Essa variedade permite que as equipes de ciência de dados escolham o melhor tipo de banco de dados para suas necessidades específicas, sejam elas de armazenamento de dados estruturados, manipulação de dados não estruturados ou análise de dados em grande escala.
Suporte para análises avançadas: os bancos de dados de nuvem geralmente vêm com suporte integrado para análises avançadas e aprendizado de máquina. Por exemplo, o Banco de Dados SQL do Azure fornece serviços internos de aprendizado de máquina. Esses serviços ajudam os cientistas de dados a realizar análises avançadas diretamente no ambiente de banco de dados.
Recursos recomendados do Azure para bancos de dados de nuvem
- Banco de Dados SQL do Azure: documentação sobre o Banco de Dados SQL do Azure, um serviço de banco de dados relacional totalmente gerenciado.
- Azure Cosmos DB: informações sobre o Azure Cosmos DB, um serviço de banco de dados multimodelo distribuído globalmente.
- Banco de Dados do Azure para PostgreSQL: guia para o Banco de Dados do Azure para PostgreSQL, um serviço de banco de dados gerenciado para desenvolvimento e implantação de aplicativos.
- Banco de Dados do Azure para MySQL: detalhes sobre o Banco de Dados do Azure para MySQL, um serviço gerenciado para bancos de dados MySQL.
Em suma, os bancos de dados de nuvem são cruciais para o TDSP porque fornecem soluções escalonáveis, confiáveis e eficientes de armazenamento e gerenciamento de dados que dão suporte a projetos controlados por dados. Eles facilitam a integração perfeita de dados, o que ajuda os cientistas de dados a ingerir, pré-processar e analisar grandes conjuntos de dados de várias fontes. Os bancos de dados de nuvem permitem consultas e processamento de dados rápidos, o que é essencial para desenvolver, testar e implantar modelos de aprendizado de máquina. Além disso, os bancos de dados de nuvem aprimoram a colaboração, fornecendo uma plataforma centralizada para os membros da equipe acessarem e trabalharem com dados simultaneamente. Por fim, os bancos de dados de nuvem fornecem recursos avançados de segurança e suporte de conformidade para manter os dados protegidos e em conformidade com os padrões regulatórios, o que é crítico para manter a integridade e a confiança dos dados.
Clusters de Big Data que usam SQL ou Spark
Os clusters de Big Data, como aqueles que usam SQL ou Spark, são fundamentais para o TDSP por vários motivos:
Gerenciar grandes volumes de dados: os clusters de Big Data são criados para lidar com grandes volumes de dados com eficiência. Os projetos de ciência de dados frequentemente envolvem grandes conjuntos de dados que excedem a capacidade dos bancos de dados tradicionais. Os clusters de Big Data baseados em SQL e o Spark podem gerenciar e processar esses dados em grande escala.
Computação distribuída: os clusters de Big Data usam computação distribuída para distribuir dados e tarefas computacionais em vários nós. A capacidade de processamento paralelo acelera significativamente as tarefas de processamento e análise de dados, o que é essencial para obter insights oportunos em projetos de ciência de dados.
Escalabilidade: os clusters de Big Data fornecem alta escalabilidade, tanto horizontalmente, adicionando mais nós, quanto verticalmente, aumentando o poder dos nós existentes. A escalabilidade ajuda a garantir que a infraestrutura de dados aumente com as necessidades do projeto, gerenciando tamanhos e complexidades crescentes de dados.
Integração com ferramentas de ciência de dados: os clusters de Big Data se integram bem a várias ferramentas e plataformas de ciência de dados. Por exemplo, o Spark se integra perfeitamente ao Hadoop, e os clusters SQL funcionam com várias ferramentas de análise de dados. A integração facilita o fluxo de trabalho, desde a ingestão de dados até a análise e a visualização.
Análise avançada: os clusters de Big Data oferecem suporte a análises avançadas e aprendizado de máquina. Por exemplo, o Spark fornece as seguintes bibliotecas internas:
- Machine Learning, MLlib
- Processamento de gráficos, GraphX
- Processamento de fluxo, Spark Streaming
Esses recursos ajudam os cientistas de dados a realizar análises complexas diretamente no cluster.
Processamento de dados em tempo real: os clusters de Big Data, especialmente os que usam o Spark, oferecem suporte ao processamento de dados em tempo real. Esse recurso é crucial para projetos que exigem análise de dados e tomada de decisão imediatas. O processamento em tempo real ajuda em cenários como detecção de fraudes, recomendações em tempo real e preços dinâmicos.
Transformação de dados e extração, transformação e carregamento (ETL): os clusters de Big Data são ideais para processos de transformação de dados e ETL. Eles podem gerenciar de modo eficiente transformações de dados complexas, tarefas de limpeza e agregação, que geralmente são necessárias antes de os dados serem analisados.
Redução de custos: os clusters de Big Data podem ser econômicos, especialmente quando você usa soluções baseadas em nuvem, como o Azure Databricks e outros serviços de nuvem. Esses serviços fornecem modelos de preços flexíveis que incluem pagamento conforme o uso, o que pode ser mais econômico do que manter a infraestrutura de Big Data local.
Tolerância a falhas: os clusters de Big Data são criados pensando na tolerância a falhas. Eles replicam dados entre nós para ajudar a garantir que o sistema permaneça operacional mesmo que alguns nós falhem. Essa confiabilidade é crítica para manter a integridade e a disponibilidade dos dados em projetos de ciência de dados.
Integração do data lake: os clusters de Big Data frequentemente se integram perfeitamente aos data lakes, o que permite que os cientistas de dados acessem e analisem diversas fontes de dados de maneira unificada. A integração promove análises mais abrangentes, dando suporte a uma combinação de dados estruturados e não estruturados.
Processamento baseado em SQL: para cientistas de dados familiarizados com SQL, os clusters de Big Data que funcionam com consultas SQL, como Spark SQL ou SQL no Hadoop, fornecem uma interface familiar para consultar e analisar Big Data. Essa facilidade de uso pode acelerar o processo de análise e torná-lo mais acessível a uma gama mais ampla de usuários.
Colaboração e compartilhamento: os clusters de Big Data dão suporte a ambientes colaborativos em que vários cientistas e analistas de dados podem trabalhar juntos nos mesmos conjuntos de dados. Eles fornecem recursos para compartilhamento de código, notebooks e resultados que promovem o trabalho em equipe e o compartilhamento de conhecimentos.
Segurança e conformidade: os clusters de Big Data fornecem recursos de segurança robustos, como criptografia de dados, controles de acesso e conformidade com os padrões do setor. Os recursos de segurança protegem dados confidenciais e ajudam sua equipe a atender aos requisitos regulatórios.
Recursos recomendados do Azure para clusters de Big Data
- Apache Spark no Machine Learning: a integração do Machine Learning com o Azure Synapse Analytics fornece acesso fácil a recursos de computação distribuídos por meio da estrutura do Apache Spark.
- Azure Synapse Analytics: documentação abrangente do Azure Synapse Analytics, que integra Big Data e armazenamento de dados.
Em suma, os clusters de Big Data, sejam SQL ou Spark, são cruciais para o TDSP, porque fornecem o poder computacional e a escalabilidade necessários para lidar com grandes quantidades de dados de maneira eficiente. Os clusters de Big Data permitem que os cientistas de dados realizem consultas complexas e análises avançadas em grandes conjuntos de dados que facilitam insights profundos e o desenvolvimento preciso de modelos. Quando você usa a computação distribuída, esses clusters permitem a análise e o processamento rápidos de dados, o que acelera o fluxo de trabalho geral da ciência de dados. Os clusters de Big Data também dão suporte à integração perfeita com várias fontes de dados e ferramentas, o que melhora a capacidade de ingestão, processamento e análise de dados de vários ambientes. Os clusters de Big Data também promovem a colaboração e a reprodutibilidade, fornecendo uma plataforma unificada onde as equipes podem compartilhar recursos, fluxos de trabalho e resultados com eficiência.
Serviços de aprendizado de máquina e IA
Os serviços de IA e Machine Learning (ML) são parte integrante do TDSP por vários motivos:
Análise avançada: os serviços de IA e ML permitem análises avançadas. Os cientistas de dados podem usar análises avançadas para descobrir padrões complexos, fazer previsões e gerar insights que não são possíveis com os métodos analíticos tradicionais. Esses recursos avançados são cruciais para a criação de soluções de ciência de dados de alto impacto.
Automação de tarefas repetitivas: os serviços de IA e ML podem automatizar tarefas repetitivas, como limpeza de dados, engenharia de recursos e treinamento de modelos. A automação economiza tempo e ajuda os cientistas de dados a se concentrarem em aspectos mais estratégicos do projeto, o que melhora a produtividade geral.
Precisão e desempenho aprimorados: os modelos de ML podem melhorar a precisão e o desempenho das previsões e análises aprendendo com os dados. Esses modelos podem melhorar continuamente à medida que são expostos a mais dados, o que leva a uma melhor tomada de decisão e resultados mais confiáveis.
Escalabilidade: os serviços de IA e ML fornecidos por plataformas de nuvem, como Machine Learning, são altamente escaláveis. Eles podem lidar com grandes volumes de dados e cálculos complexos, o que ajuda as equipes de ciência de dados a dimensionar suas soluções para atender às demandas crescentes sem se preocupar com as limitações de infraestrutura subjacentes.
Integração com outras ferramentas: os serviços de IA e ML se integram perfeitamente a outras ferramentas e serviços dentro do ecossistema da Microsoft, como Azure Data Lake, Azure Databricks e Power BI. A integração dá suporte a um fluxo de trabalho simplificado, desde a ingestão e o processamento de dados até a implantação e a visualização do modelo.
Implantação e gerenciamento de modelos: os serviços de IA e ML fornecem ferramentas robustas para implantar e gerenciar modelos de Machine Learning em produção. Recursos como controle de versão, monitoramento e retreinamento automatizado ajudam a garantir que os modelos permaneçam precisos e eficazes ao longo do tempo. Essa abordagem simplifica a manutenção de soluções de ML.
Processamento em tempo real: os serviços de IA e ML dão suporte ao processamento de dados e à tomada de decisões em tempo real. O processamento em tempo real é essencial para aplicativos que exigem insights e ações imediatas, como detecção de fraudes, preços dinâmicos e sistemas de recomendação.
Personalização e flexibilidade: os serviços de IA e ML fornecem diversas opções personalizáveis, desde APIs e modelos predefinidos até estruturas para criar modelos personalizados do zero. Essa flexibilidade ajuda as equipes de ciência de dados a adaptar soluções para necessidades de negócios e casos de uso específicos.
Acesso a algoritmos de ponta: os serviços de IA e ML fornecem aos cientistas de dados acesso a algoritmos e tecnologias de ponta desenvolvidos pelos principais pesquisadores. O acesso garante que a equipe possa usar os avanços mais recentes em IA e ML para seus projetos.
Colaboração e compartilhamento: as plataformas de IA e ML oferecem suporte a ambientes de desenvolvimento colaborativo, onde vários membros da equipe podem trabalhar juntos no mesmo projeto, compartilhar códigos e reproduzir experimentos. A colaboração aprimora o trabalho em equipe e ajuda a garantir a consistência no desenvolvimento de modelos.
Redução de custos: os serviços de IA e ML na nuvem podem ser mais econômicos do que criar e manter soluções locais. Os provedores de nuvem têm modelos de preços flexíveis que incluem opções de pagamento conforme o uso, o que pode reduzir custos e otimizar o uso de recursos.
Segurança e conformidade aprimoradas: os serviços de IA e ML vêm com recursos de segurança robustos, que incluem criptografia de dados, controles de acesso seguro e conformidade com os padrões e regulamentos do setor. Esses recursos ajudam a proteger seus dados e modelos e atendem aos requisitos legais e regulatórios.
APIs e modelos e predefinidos: muitos serviços de IA e ML fornecem modelos e APIs predefinidos para tarefas comuns, como processamento de linguagem natural, reconhecimento de imagem e detecção de anomalias. As soluções pré-criadas podem acelerar o desenvolvimento e a implantação e ajudar as equipes a integrar rapidamente os recursos de IA aos seus aplicativos.
Experimentação e prototipagem: as plataformas de IA e ML fornecem ambientes para experimentação e prototipagem rápidas. Os cientistas de dados podem testar rapidamente diferentes algoritmos, parâmetros e conjuntos de dados para encontrar a melhor solução. A experimentação e a prototipagem dão suporte a uma abordagem iterativa para o desenvolvimento de modelos.
Recursos recomendados do Azure para serviços de IA e ML
O Machine Learning é o principal recurso que recomendamos para aplicativos de ciência de dados e TDSP. Além disso, o Azure fornece serviços de IA que têm modelos de IA prontos para uso para aplicativos específicos.
- Machine Learning: a página de documentação principal do Machine Learning que abrange a configuração, o treinamento de modelos, a implantação e assim por diante.
- Serviços de IA do Azure: informações sobre serviços de IA que fornecem modelos de IA predefinidos para tarefas de visão, fala, linguagem e tomada de decisão.
Em suma, os serviços de IA e ML são cruciais para o TDSP, pois fornecem ferramentas e estruturas eficientes que simplificam o desenvolvimento, o treinamento e a implantação de modelos de Machine Learning. Esses serviços automatizam tarefas complexas, como seleção de algoritmos e ajuste de hiperparâmetros, o que acelera muito o processo de desenvolvimento de modelos. Esses serviços também fornecem uma infraestrutura escalável que ajuda os cientistas de dados a lidar com grandes conjuntos de dados e tarefas com uso intensivo de computação. As ferramentas de IA e ML se integram perfeitamente a outros serviços do Azure e aprimoram a ingestão de dados, o pré-processamento e a implantação de modelos. A integração ajuda a garantir um fluxo de trabalho tranquilo de ponta a ponta. Além disso, esses serviços promovem a colaboração e a reprodutibilidade. As equipes podem compartilhar insights e experimentar resultados e modelos enquanto mantêm altos padrões de segurança e conformidade.
IA responsável
Com soluções de IA ou ML, a Microsoft promove ferramentas de IA responsável em suas soluções de IA e ML. Essas ferramentas dão suporte ao Padrão de Uso Responsável de IA da Microsoft. Sua carga de trabalho ainda deve abordar individualmente os danos relacionados à IA.
Citações revisadas por pares
O TDSP é uma metodologia bem estabelecida que as equipes usam em todos os contratos da Microsoft. O TDSP é documentado e estudado na literatura revisada por pares. As citações fornecem uma oportunidade de investigar os recursos e aplicativos do TDSP. Para obter mais informações e uma lista de citações, consulte O ciclo de vida do TDSP.