Solucionar problemas de gargalos de desempenho no Azure Databricks
Observação
Este artigo se baseia em uma biblioteca de código aberto hospedada no GitHub em: https://github.com/mspnp/spark-monitoring.
A biblioteca original dá suporte ao Azure Databricks Runtimes 10.x (Spark 3.2.x) e versões anteriores.
O Databricks contribuiu com uma versão atualizada para dar suporte ao Azure Databricks Runtimes 11.0 (Spark 3.3.x) e superior na l4jv2 ramificação em: https://github.com/mspnp/spark-monitoring/tree/l4jv2.
Observe que a versão 11.0 não é compatível com versões anteriores devido aos diferentes sistemas de log usados nos Databricks Runtimes. Certifique-se de usar a compilação correta para o Databricks Runtime. A biblioteca e o repositório do GitHub estão em modo de manutenção. Não há planos para lançamentos futuros, e o suporte a problemas será apenas de melhor esforço. Para quaisquer perguntas adicionais sobre a biblioteca ou o roteiro para monitoramento e registro em log de seus ambientes do Azure Databricks, entre em contato com azure-spark-monitoring-help@databricks.com.
Este artigo descreve como usar painéis de monitoramento para encontrar gargalos de desempenho em trabalhos do Spark no Azure Databricks.
O Azure Databricks é um serviço de análise baseado no Apache Spark que facilita o desenvolvimento e a implantação rápidos de análises de big data. Monitorar e solucionar problemas de desempenho é essencial ao operar cargas de trabalho de produção do Azure Databricks. Para identificar problemas comuns de desempenho, é útil usar visualizações de monitoramento com base em dados de telemetria.
Pré-requisitos
Para configurar os painéis do Grafana mostrados neste artigo, faça o seguinte:
Configure seu cluster Databricks para enviar telemetria a um workspace do Log Analytics usando a Biblioteca de Monitoramento do Azure Databricks. Para saber mais, confira o Arquivo leia-me do GitHub.
Implante o Grafana em uma máquina virtual. Confira Use painéis para visualizar as métricas do Azure Databricks.
O painel do Grafana implantado inclui um conjunto de visualizações de séries temporais. Cada gráfico consiste em um gráfico de séries temporais de métricas relacionadas a um trabalho do Apache Spark, estágios do trabalho e tarefas que compõem cada estágio.
Visão geral de desempenho do Azure Databricks
O Azure Databricks é baseado no Apache Spark, um sistema de computação distribuída de uso geral. O código do aplicativo, conhecido como trabalho, é executado em um cluster do Apache Spark, coordenado pelo gerenciador de cluster. Em geral, um trabalho é a unidade de computação de nível mais alto. Um trabalho representa a operação completa realizada pelo aplicativo Spark. Uma operação típica inclui ler dados de uma fonte, aplicar transformações de dados e gravar os resultados no armazenamento ou em outro destino.
Os trabalhos são divididos em estágios. O trabalho progride de maneira sequencial, o que significa que os estágios posteriores devem aguardar a conclusão dos anteriores. Esses estágios contêm grupos de tarefas idênticas que podem ser executadas em paralelo em diversos nós do cluster Spark. As tarefas são a unidade de execução mais granular que ocorre em um subconjunto dos dados.
As próximas seções descrevem algumas visualizações de painel que são úteis para a solução de problemas de desempenho.
Latência de trabalho e estágio
A latência de trabalho é a duração de uma execução do trabalho desde o início até a conclusão. Ela é mostrada como percentis de uma execução de trabalho por cluster e ID de aplicativo para permitir a visualização de execuções. O gráfico a seguir mostra um histórico de trabalho em que o percentil 90 atingiu 50 segundos, embora o percentil 50 tenha sido mantido consistentemente em torno de 10 segundos.
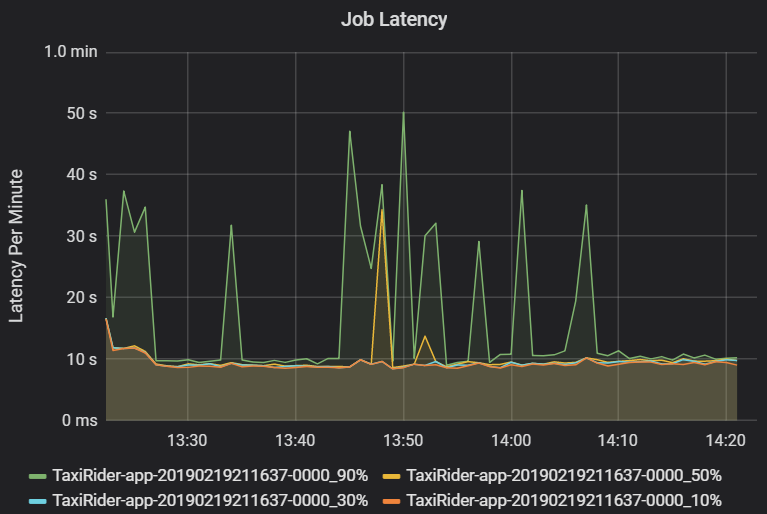
Investigue a execução de trabalhos por cluster e aplicativo em busca de picos de latência. Depois que os clusters e aplicativos com alta latência forem identificados, avance para a investigação da latência de estágio.
A latência de estágio também é mostrada como percentis para permitir a visualização de exceções. Ela é dividida por cluster, aplicativo e nome do estágio. Identifique picos de latência de tarefas no gráfico para determinar quais tarefas estão impedindo a conclusão do estágio.
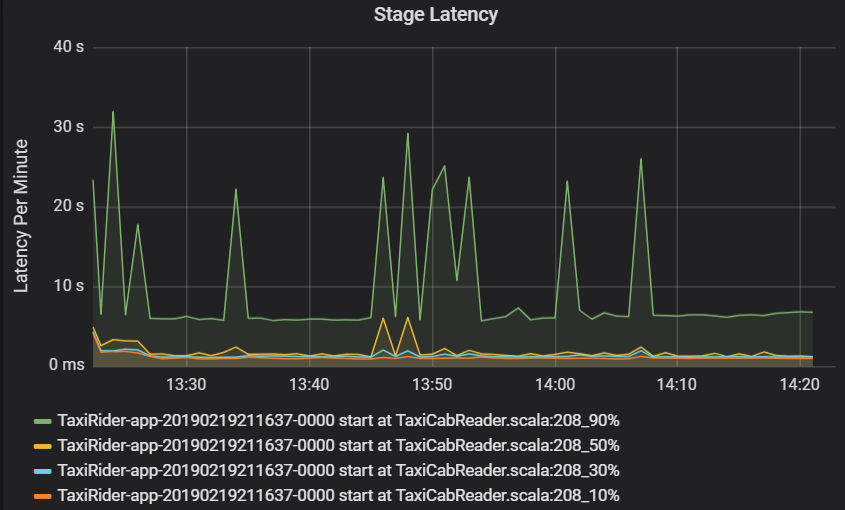
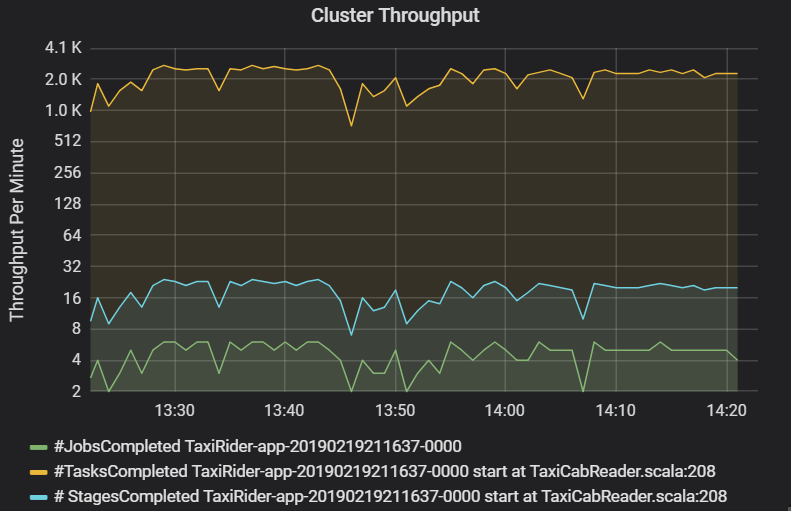
O gráfico de taxa de transferência do cluster mostra o número de trabalhos, estágios e tarefas concluídos por minuto. Isso ajuda você a entender a carga de trabalho em termos do número relativo de estágios e tarefas por trabalho. Veja a seguir que o número de trabalhos por minuto varia entre 2 e 6, enquanto o número de estágios é de cerca de 12 a 24 por minuto.
Soma da latência de execução de tarefa
Essa visualização mostra a soma da latência de execução de tarefa por host em execução em um cluster. Use este gráfico para detectar tarefas executadas lentamente devido à lentidão do host em um cluster ou a uma alocação incorreta de tarefas por executor. No gráfico a seguir, a maioria dos hosts tem uma soma de cerca de 30 segundos. No entanto, dois dos hosts têm somas de cerca de 10 minutos. Os hosts estão lentos ou o número de tarefas por executor está mal alocado.
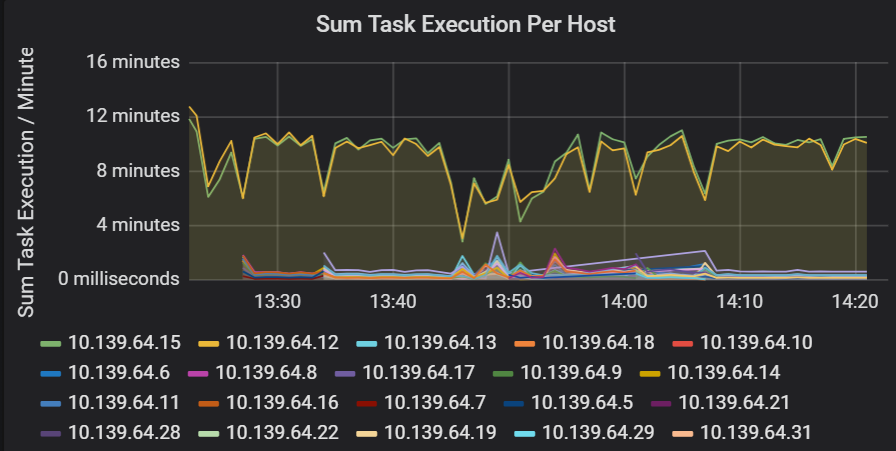
O número de tarefas por executor mostra que dois executores recebem um número desproporcional de tarefas, o que causa um gargalo.
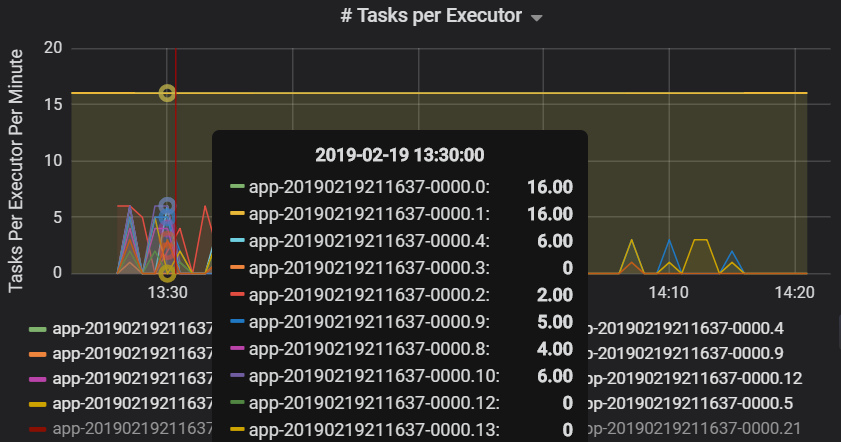
Métricas de tarefa por estágio
A visualização de métricas de tarefa fornece a divisão de custos para a execução de uma tarefa. É possível usá-la para ver o tempo relativo gasto em tarefas como serialização e desserialização. Esses dados podem mostrar oportunidades de otimização, por exemplo, o uso de variáveis de transmissão para evitar o envio de dados. As métricas de tarefa também mostram o tamanho dos dados aleatórios para uma tarefa e os tempos de leitura e gravação aleatória. Se esses valores forem altos, significa que muitos dados estão sendo movidos pela rede.
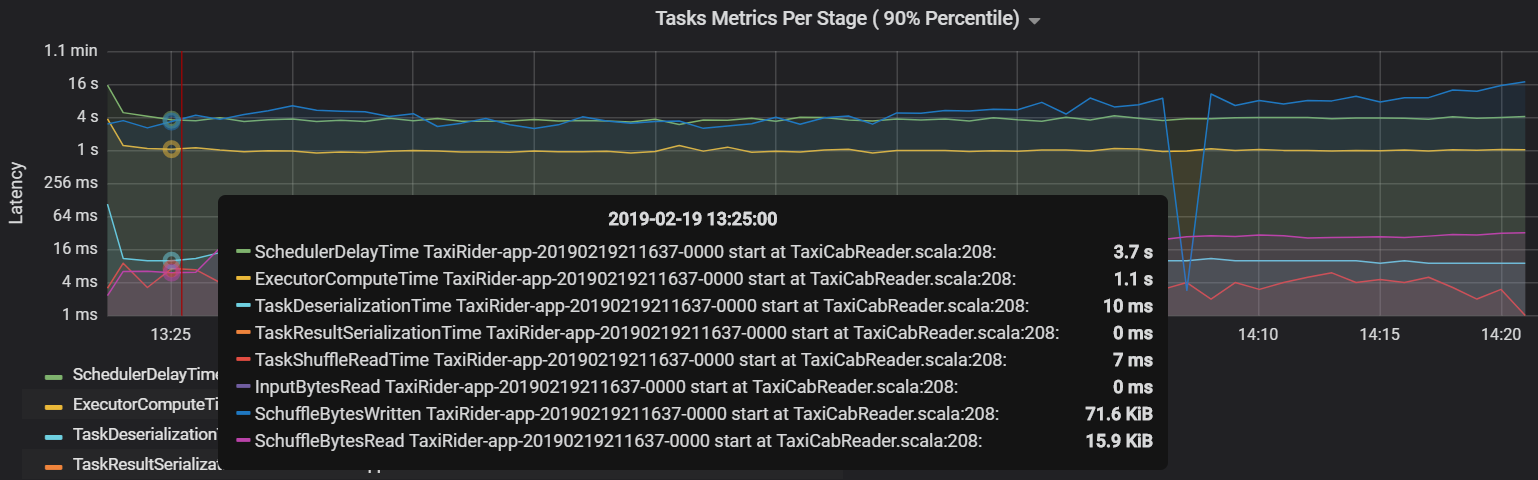
Outra métrica de tarefa é o atraso do agendador, que mede quanto tempo leva para agendar uma tarefa. Idealmente, esse valor deve ser baixo em comparação com o tempo de computação do executor, que é o tempo gasto na execução da tarefa.
O gráfico a seguir mostra um tempo de atraso do agendador (3,7 s) que excede o tempo de computação do executor (1,1 s). Isso significa que mais tempo é gasto esperando que as tarefas sejam agendadas do que fazendo o trabalho real.
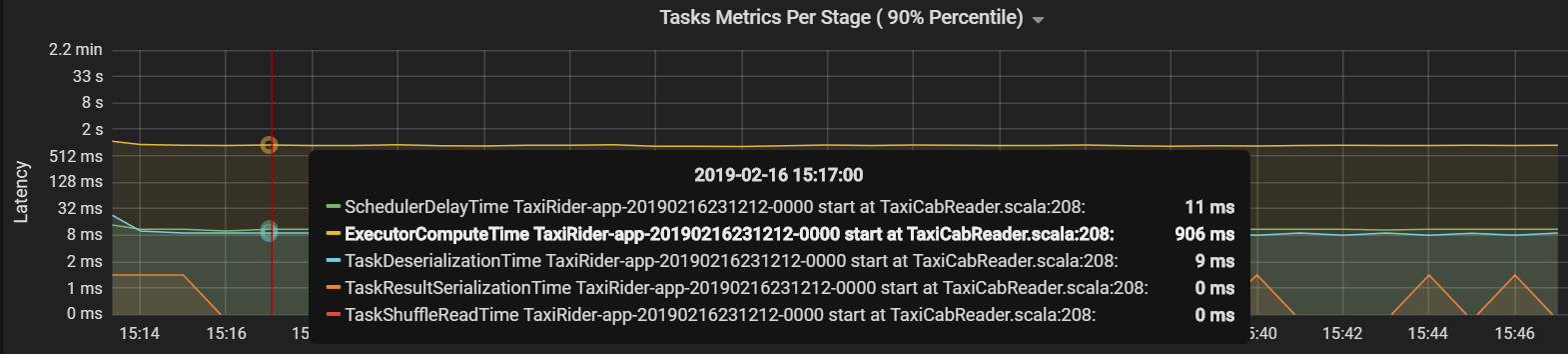
Nesse caso, o problema foi causado pelo excesso de partições, o que causou muita sobrecarga. A redução do número de partições reduziu o tempo de atraso do agendador. O próximo gráfico mostra que a maior parte do tempo é gasto na execução da tarefa.
Taxa de transferência e latência de streaming
A taxa de transferência de streaming está diretamente relacionada ao streaming estruturado. Há duas métricas importantes associadas à taxa de transferência de streaming: linhas de entrada por segundo e linhas processadas por segundo. Se as linhas de entrada por segundo ultrapassarem as linhas processadas por segundo, significa que o sistema de processamento de fluxo está ficando para trás. Além disso, se os dados de entrada vierem de Hubs de Eventos ou do Kafka, as linhas de entrada por segundo deverão acompanhar a taxa de ingestão de dados no front-end.
Dois trabalhos podem ter uma taxa de transferência de cluster semelhante, mas métricas de streaming muito diferentes. A captura de tela a seguir mostra duas cargas de trabalho diferentes. Elas são semelhantes em termos de taxa de transferência do cluster (trabalhos, estágios e tarefas por minuto). No entanto, a segunda execução processa 12.000 linhas/s vs. 4.000 linhas/s.
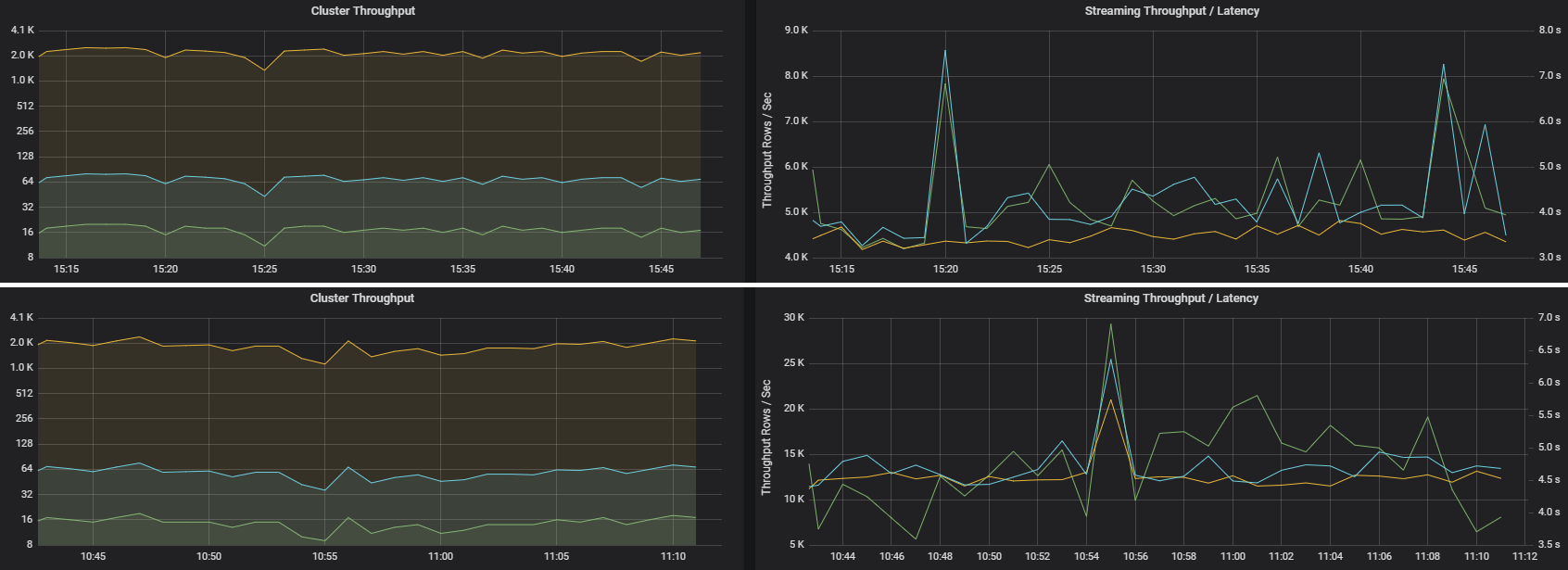
A taxa de transferência de streaming geralmente é uma métrica de negócios melhor do que a taxa de transferência do cluster, pois ela mede o número de registros de dados processados.
Consumo de recursos por executor
Estas métricas ajudam a entender o trabalho que cada executor realiza.
As métricas de porcentagem medem quanto tempo um executor gasta em diversas coisas, expresso como uma proporção de tempo gasto vs. o tempo total de computação do executor. Essas métricas são:
- % de tempo de serialização
- % de tempo de desserialização
- % de tempo do executor da CPU
- % de tempo de JVM
Essas visualizações mostram o quanto cada uma dessas métricas contribui para o processamento geral do executor.
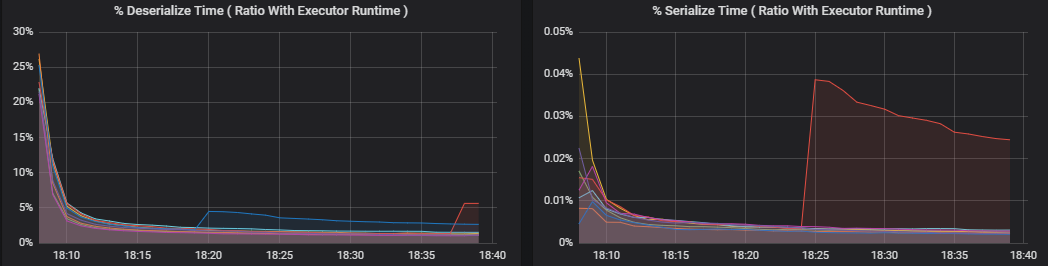
As métricas aleatórias são métricas relacionadas ao embaralhamento de dados entre os executores.
- E/S aleatória
- Memória aleatória
- Uso do sistema de arquivos
- Uso de disco
Gargalos comuns de desempenho
Dois gargalos de desempenho comuns no Spark são atrasos de tarefas e uma contagem de partição aleatória não ideal.
Atrasos de tarefa
Os estágios em um trabalho são executados sequencialmente, com os anteriores bloqueando os posteriores. Se uma tarefa executa uma partição aleatória mais lentamente do que outras tarefas, todas as tarefas no cluster devem esperar que a tarefa lenta seja recuperada antes que o estágio possa terminar. Isso pode ocorrer pelos seguintes motivos:
Um host ou grupo de hosts está lento. Sintomas: alta latência de tarefa, estágio ou trabalho e baixa taxa de transferência do cluster. A soma das latências de tarefas por host não será distribuída uniformemente. No entanto, o consumo de recursos será distribuído uniformemente entre os executores.
As tarefas têm uma agregação de execução cara (distorção de dados). Sintomas: alta latência de tarefa, alta latência de estágio, alta latência de trabalho ou baixa taxa de transferência de cluster, mas a soma de latências por host é distribuída uniformemente. O consumo de recursos será distribuído uniformemente entre os executores.
Se as partições forem de tamanho desigual, uma partição maior poderá causar a execução desequilibrada da tarefa (distorção da partição). Sintomas: consumo de recursos do executor alto em comparação com outros executores em execução no cluster. Todas as tarefas executadas nesse executor ficarão lentas e atrasarão a execução do estágio no pipeline. Esses estágios são chamados de barreiras de estágio.
Contagem de partição aleatória não ideal
Durante uma consulta de streaming estruturado, a atribuição de uma tarefa a um executor é uma operação de uso intensivo de recursos para o cluster. Se os dados aleatórios não tiverem o tamanho ideal, a quantidade de atraso de uma tarefa afetará negativamente a taxa de transferência e a latência. Se houver poucas partições, os núcleos do cluster serão subutilizados, o que pode resultar em ineficiência de processamento. Por outro lado, se houver muitas partições, haverá uma grande sobrecarga de gerenciamento para um pequeno número de tarefas.
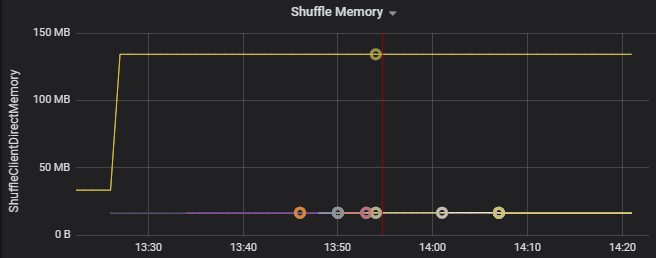
Use as métricas de consumo de recursos para solucionar problemas de distorção de partição e alocação incorreta de executores no cluster. Se uma partição estiver distorcida, os recursos do executor serão elevados em comparação com outros executores em execução no cluster.
Por exemplo, o gráfico a seguir mostra que a memória usada pela ordem aleatória nos dois primeiros executores é 90 vezes maior que nos seguintes:
Próximas etapas
- Como monitorar o Azure Databricks em um workspace do Azure Log Analytics
- Caminho de aprendizagem: Criar e operar soluções de machine learning com o Azure Databricks
- Documentação do Azure Databricks
- Visão geral do Azure Monitor
Recursos relacionados
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de