A Inteligência Artificial oferece o potencial de transformar o varejo como o conhecemos hoje. É plausível acreditar que os varejistas desenvolverão uma arquitetura de experiência do cliente com suporte da inteligência artificial. Algumas expectativas são de que uma plataforma aprimorada com Inteligência Artificial fornecerá uma aumento de receita devido à hiperpersonalização. O comércio digital continua a reforçar o comportamento, as preferências e as expectativas dos clientes. Demandas como participação em tempo real, recomendações relevantes e hiperpersonalização estão levando velocidade e conveniência com um clique de um botão. Possibilitamos o uso da inteligência em aplicativos por meio de fala natural, visão e assim por diante. Essa inteligência proporciona melhorias no varejo que aumentarão o valor, gerando uma revolução no modo como os clientes fazem compras.
Este documento concentra-se no conceito de Pesquisa Visual da IA e oferece algumas considerações importantes sobre sua implementação. Ele fornece um exemplo de fluxo de trabalho e mapeia seus estágios para as tecnologias do Azure relevantes. O conceito fundamenta-se na possibilidade dos clientes aproveitarem uma imagem tirada com seu dispositivo móvel ou encontrada na internet. A partir disso, eles realizariam uma pesquisa de itens relacionados e semelhantes, dependendo da intenção da experiência. Assim, a Pesquisa Visual melhora a velocidade da entrada enviada por texto para uma imagem com vários pontos de metadados para exibir todos os itens compatíveis que estão disponíveis.
Mecanismos de pesquisa visual
Mecanismos de Pesquisa Visual recuperam informações usando imagens como entrada e muitas vezes, mas não exclusivamente, como saída também.
Os mecanismos estão se tornando cada vez mais comuns no setor de varejo, o que se dá por motivos muito bons:
- Cerca de 75% dos usuários de Internet pesquisam por imagens ou vídeos de um produto antes de fazerem uma compra, de acordo com um relatório do Emarketer publicado em 2017.
- 74% dos consumidores também consideram pesquisas de texto ineficientes, de acordo com o relatório de 2015 da Slyce (uma empresa de pesquisa visual).
Portanto, o mercado de reconhecimento de imagem valerá mais de USD 25 bilhões até 2019, de acordo com uma pesquisa pela Markets & Markets.
A tecnologia já ocupou espaço entre as principais marcas de comércio eletrônico, que também contribuíram significativamente para seu desenvolvimento. Os usuários pioneiros mais proeminentes provavelmente são:
- O eBay, com suas ferramentas de pesquisa de imagem e "Localizar no eBay" em seu aplicativo (que, atualmente, é apenas uma experiência móvel).
- O Pinterest, com sua ferramenta de descoberta visual Lentes.
- A Microsoft, com a Pesquisa Visual do Bing.
Adotar e adaptar
Felizmente, você não precisa grandes quantidades de poder de computação para tirar proveito da Pesquisa Visual. Qualquer empresa com um catálogo de imagens pode tirar proveito da experiência de Inteligência Artificial da Microsoft criada em seus serviços do Azure.
A API da Pesquisa Visual do Bing fornece uma maneira para extrair informações de contexto de imagens, identificando, por exemplo, móveis domésticos, moda, vários tipos de produtos e assim por diante.
Ela também retornará imagens visualmente semelhantes fora de seu próprio catálogo, produtos com fontes de compra relativas, pesquisas relacionadas. Embora seja interessante, isso será de uso limitado se a empresa não for uma dessas fontes.
O Bing também fornecerá:
- Marcas que permitem a você explorar objetos ou conceitos encontrados na imagem.
- Caixas delimitadoras para regiões de interesse na imagem (como itens vestuário ou móveis).
Você pode aproveitar essa informação para reduzir o espaço (e o tempo) de pesquisa no catálogo de produtos da empresa significativamente, restringindo-a a objetos como aqueles na região e categoria de interesse.
Implementar a sua própria solução
Há alguns componentes principais a considerar ao implementar a Pesquisa Visual:
- Ingestão e filtragem de imagens
- Técnicas de armazenamento e de recuperação
- Personalização, codificação ou "hash"
- Medidas de similaridade ou distâncias e classificação

Figura 1: exemplo de pipeline de Pesquisa Visual
Fornecimento de imagens
Se você não tem um catálogo de imagens, talvez precise treinar os algoritmos em conjuntos de dados abertamente disponíveis, como um banco de dados MNIST de moda, deep fashion e similares. Eles contêm várias categorias de produtos e são normalmente usados como parâmetro de comparação de algoritmos de pesquisa e de categorização de imagens.

Figura 2: um exemplo do conjunto de dados da DeepFashion
Filtrando as imagens
A maioria dos conjuntos de dados de parâmetro de comparação (como aqueles mencionados antes) já foram pré-processados.
Se criar seu próprio benchmark, você desejará, pelo menos, que as imagens tenham todas o mesmo tamanho, ditado principalmente pela entrada para a qual seu modelo é treinado.
Em muitos casos, também é melhor normalizar a luminosidade das imagens. Dependendo do nível de detalhe da pesquisa, a cor também pode ser uma informação redundante. Assim, reduzir para preto e branco ajudará nos tempos de processamento.
Por último, mas não menos importante, o conjunto de dados de imagem deve ser balanceado entre as diferentes classes que ele representa.
Banco de dados de imagens
A camada de dados é um componente especialmente delicado da sua arquitetura. Ele conterá:
- Imagens
- Todos os metadados sobre as imagens (tamanho, marcas, SKUs de produto, descrição)
- Dados gerados pelo modelo de machine learning (por exemplo, um vetor numérico de elemento de 4096 pixels por imagem)
Conforme você recupera imagens de origens diferentes ou usa diversos modelos de machine learning para otimizar o desempenho, a estrutura dos dados é alterada. Portanto, é importante escolher uma tecnologia ou uma combinação que possa lidar com os dados semiestruturados e nenhum esquema fixo.
Também convém exigir um número mínimo de pontos de dados úteis (como uma chave ou identificador de imagem, um SKU do produto, uma descrição ou um campo de tag).
O Azure Cosmos DB oferece a flexibilidade necessária e uma variedade de mecanismos de acesso para aplicativos criados nele (que ajudarão com sua pesquisa de catálogo). No entanto, é preciso ter cuidado para obter a melhor relação entre preço e desempenho. O Azure Cosmos DB permite que os anexos de documento sejam armazenados, mas há um limite total por conta e essa pode ser uma proposta dispendiosa. É uma prática comum para armazenar os arquivos de imagem propriamente ditos em blobs e inserir um link para eles no banco de dados. No caso do Azure Cosmos DB, isso implica na criação de um documento que contém as propriedades de catálogo associadas a essa imagem (como SKU, tag etc.) e um anexo que contém a URL do arquivo de imagem (por exemplo, no Armazenamento de Blobs do Azure, no OneDrive etc).
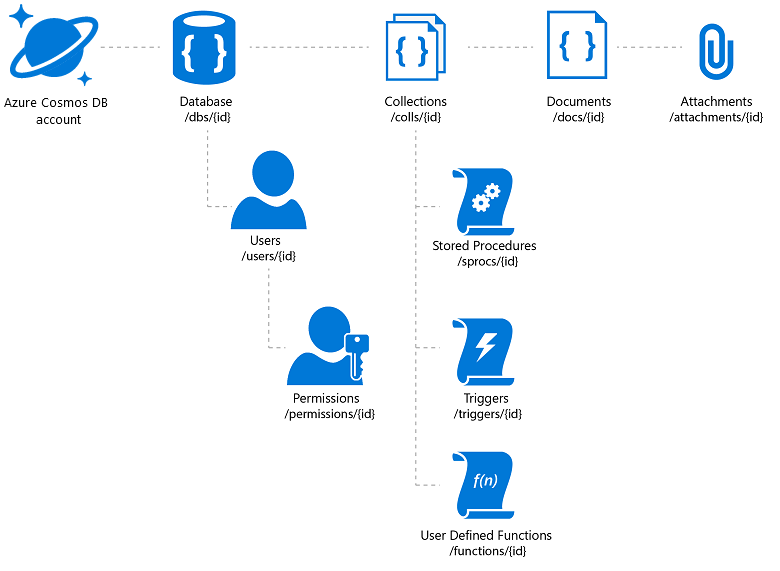
Figura 3: Modelo de recurso hierárquico do Azure Cosmos DB
Se você planeja tirar proveito da distribuição global do Azure Cosmos DB, observe que ele replicará os documentos e anexos, mas não os arquivos vinculados. Talvez você queira considerar uma rede de distribuição de conteúdo para esses arquivos.
Outras tecnologias aplicáveis são uma combinação do Banco de Dados SQL do Azure (se o esquema fixo é aceitável) e blobs ou até mesmo Tabelas do Azure e blobs, para armazenamento e recuperação rápidos e baratos.
Extração & codificação de características
O processo de codificação extrai as características mais evidentes de imagens no banco de dados e mapeia cada uma delas para um vetor de "características" esparso (um vetor com muitos zeros) que pode ter milhares de componentes. Esse vetor é uma representação numérica das características (como bordas e formas) que compõem a imagem. Algo semelhante a um código.
Normalmente, as técnicas de extração de características usam mecanismos de aprendizado de transferência. Isso ocorre quando você seleciona uma rede neural previamente treinada, executa cada imagem nela e armazena o vetor de recurso produzido de volta em seu banco de dados de imagem. Dessa forma, você "transfere" a aprendizagem de quem quer que tenha treinado a rede. A Microsoft desenvolveu e publicou várias redes previamente treinadas que foram amplamente usadas para tarefas de reconhecimento de imagem, como ResNet50.
Dependendo da rede neural, o vetor de recurso será mais ou menos longo e esparso, portanto, os requisitos de memória e armazenamento variarão.
Além disso, você pode descobrir que diferentes redes são aplicáveis a diferentes categorias, portanto, uma implementação de Pesquisa Visual poderá, na verdade, gerar vetores de característica de tamanhos variados.
As redes neurais pré-treinadas são relativamente fáceis de usar, mas podem não ser tão eficientes quanto um modelo personalizado no seu catálogo de imagem. Essas redes previamente treinadas são normalmente criadas para classificação de conjuntos de dados de parâmetro de comparação em vez de pesquisa em sua coleção específica de imagens.
Talvez você deseje modificar e retreinar essas redes para que elas produzam tanto uma previsão de categoria quanto vetor denso (ou seja, menor, não esparso), o que será muito útil para restringir o espaço de pesquisa e reduzir os requisitos de memória e de armazenamento. Vetores binários podem ser usados e geralmente são chamados de " hash semântico", um termo derivado de técnicas de codificação e recuperação de documentos. A representação binária simplifica os cálculos posteriores.

Figura 4: modificações a ResNet para Pesquisa Visual – F. Yang et al., 2017
Se você escolher modelos pré-treinados ou preferir desenvolver seus próprios, você ainda precisará decidir onde executar a personalização e/ou o treinamento do modelo propriamente dito.
O Azure oferece várias opções: VMs, Lote do Azure, IA do Lote, clusters do Databricks. Em todos os casos, no entanto, a melhor relação preço/desempenho é obtida pelo uso de GPUs.
A Microsoft anunciou recentemente também a disponibilidade de FPGAs para computação rápida em uma fração do custo da GPU (projeto Brainwave). No entanto, no momento da escrita, esta oferta é limitada a determinadas arquiteturas de rede, portanto, você precisará avaliar seu desempenho de perto.
Medidas de similaridade ou distâncias
Quando as imagens são representadas no espaço de vetor de recurso, encontrar semelhanças torna-se uma questão de definir uma medida de distância entre pontos em tal espaço. Depois que uma distância for definida, você poderá calcular clusters de imagens similares e/ou definir matrizes de similaridade. Dependendo da métrica de distância selecionada, os resultados podem variar. A medida de distância Euclidiana mais comum em vetores de número real, por exemplo, é fácil de entender: ela captura a magnitude da distância. No entanto, é bastante ineficiente em termos de computação.
A distância do cosseno geralmente é usada para capturar a orientação do vetor, e não sua magnitude.
Alternativas como a distância de Hamming em representações binárias sacrificam alguma precisão por velocidade e eficiência.
A combinação de tamanho do vetor e medida da distância determinará o quão intensiva a pesquisa será em termos de computação e de uso de memória.
Pesquisa & classificação
Após a similaridade ser definida, é necessário planejar um método eficiente para recuperar os N itens mais próximos àquele passado como entrada, depois retornar uma lista de identificadores. Isso também é conhecido como "classificação de imagem". Em um conjunto de dados grande, o tempo para calcular cada distância é proibitivo, então usamos algoritmos aproximados de vizinho mais próximo. Existem várias bibliotecas de software livre para eles, então você não terá de codificá-los do zero.
Por fim, os requisitos de memória e computação determinarão a escolha da tecnologia de implantação para o modelo treinado, bem como alta disponibilidade. Normalmente, o espaço de pesquisa será particionado e várias instâncias do algoritmo de classificação serão executadas em paralelo. Uma opção que permite a escalabilidade e disponibilidade é o uso de clusters do Kubernetes do Azure. Nesse caso, é aconselhável implantar o modelo de classificação entre vários contêineres (cada um dos quais lidando com uma partição do espaço de pesquisa) e vários nós (para alta disponibilidade).
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Principais autores:
- Giovanni Marchetti | Gerente, Arquitetos de Soluções do Azure
- Mariya Zorotovich | Chefe de experiência do cliente, HLS & Emerging Technology
Outros colaboradores:
- Scott Seely | Arquiteto de software
Próximas etapas
A implementação da Pesquisa Visual não precisa ser complexa. Você pode usar o Bing ou criar a sua própria com os serviços do Azure, enquanto se beneficia da pesquisa e das ferramentas de IA da Microsoft.
Desenvolver
- Para começar a criação de um serviço personalizado, confira Visão geral da API da Pesquisa Visual do Bing
- Para criar sua primeira solicitação, confira os inícios rápidos: C# | Java | node.js | Python
- Familiarize-se com a Referência da API de Pesquisa Visual.
Tela de fundo
- Segmentação de imagem de aprendizado profundo: o documento da Microsoft descreve o processo de separar imagens de telas de fundo
- Pesquisa Visual no Ebay: pesquisa da Universidade de Cornell
- Descoberta Visual no Pinterest pesquisa da Universidade de Cornell
- Hash semântico pesquisa da Universidade de Toronto