Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo descreve considerações para gerenciar dados em uma arquitetura de microsserviços. Cada microsserviço gerencia seus próprios dados, de modo que a integridade dos dados e a consistência de dados representam desafios críticos.
Dois serviços não devem compartilhar um armazenamento de dados. Cada serviço gerencia seu próprio armazenamento de dados privado e outros serviços não podem acessá-lo diretamente. Essa regra impede o acoplamento não intencional entre serviços, o que acontece quando os serviços compartilham os mesmos esquemas de dados subjacentes. Se o esquema de dados for alterado, a alteração deverá ser coordenada em todos os serviços que dependem desse banco de dados. Isolar o armazenamento de dados de cada serviço limita o escopo da alteração e preserva a agilidade de implantações independentes. Cada microsserviço também pode ter modelos de dados exclusivos, consultas ou padrões de leitura e gravação. Um armazenamento de dados compartilhado limita a capacidade de cada equipe de otimizar o armazenamento de dados para seu serviço específico.
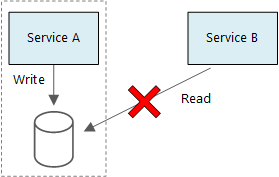
O diagrama mostra o serviço A e um banco de dados em uma seção à esquerda. Uma seta rotulada como pontos de gravação do serviço A para o banco de dados. O serviço B reside fora desta seção à direita. Uma seta rotulada como 'read' aponta para o banco de dados. Um X vermelho cruza esta seta.
Essa abordagem naturalmente leva à persistência poliglota, o que significa usar várias tecnologias de armazenamento de dados em um único aplicativo. Um serviço pode precisar dos recursos de esquema em leitura de um banco de dados de documentos. Outro serviço pode precisar da integridade referencial que um RDBMS (sistema de gerenciamento de banco de dados relacional) fornece. Cada equipe pode escolher a melhor opção para seu serviço.
Observação
Os serviços podem compartilhar com segurança o mesmo servidor de banco de dados físico. Problemas ocorrem quando os serviços compartilham o mesmo esquema ou leem e gravam no mesmo conjunto de tabelas de banco de dados.
Desafios
A abordagem distribuída para gerenciar dados apresenta vários desafios. Primeiro, a redundância pode ocorrer entre armazenamentos de dados. O mesmo item de dados pode aparecer em vários lugares. Por exemplo, os dados podem ser armazenados como parte de uma transação e armazenados em outro lugar para análise, relatório ou arquivamento. Dados duplicados ou particionados podem causar problemas de integridade e consistência de dados. Quando as relações de dados abrangem vários serviços, as técnicas tradicionais de gerenciamento de dados não podem impor essas relações.
A modelagem de dados tradicional segue a regra de um fato em um só lugar. Cada entidade aparece exatamente uma vez no esquema. Outras entidades podem referenciá-lo, mas não duplicá-lo. A principal vantagem da abordagem tradicional é que as atualizações ocorrem em um único lugar, o que impede problemas de consistência de dados. Em uma arquitetura de microsserviços, você deve considerar como as atualizações se propagam entre serviços e como gerenciar a consistência eventual quando os dados aparecem em vários lugares sem consistência forte.
Abordagens para gerenciar dados
Nenhuma abordagem única funciona para todos os casos. Considere as seguintes diretrizes gerais para gerenciar dados em uma arquitetura de microsserviços:
Defina o nível de consistência necessário para cada componente e prefira a consistência eventual sempre que possível. Identifique as áreas no sistema em que você precisa de consistência forte, ou de transações ACID (atomicidade, consistência, isolamento e durabilidade). E identifique áreas em que a consistência eventual é aceitável. Para obter mais informações, consulte Usar o DDD (design controlado pelo domínio tático) para microsserviços.
Use uma única fonte de verdade quando você precisar de consistência forte. Um serviço pode representar a fonte da verdade para uma determinada entidade e expô-la por meio de uma API. Outros serviços podem conter sua própria cópia dos dados ou um subconjunto dos dados, que eventualmente é consistente com os dados primários, mas não considerado a fonte da verdade. Por exemplo, em um sistema de comércio eletrônico que tenha um serviço de pedidos de cliente e um serviço de recomendação, o serviço de recomendação pode escutar eventos do serviço de pedidos. Mas se um cliente solicitar um reembolso, o serviço de pedido, não o serviço de recomendação, terá o histórico de transações completo.
Aplique padrões de transação para manter a consistência entre os serviços. Use padrões como o Supervisor do Agente do Agendador e Transação Compensatória para manter os dados consistentes em vários serviços. Para evitar falhas parciais entre vários serviços, talvez seja necessário armazenar uma parte extra dos dados que captura o estado de uma unidade de trabalho que abrange vários serviços. Por exemplo, mantenha um item de trabalho em uma fila durável enquanto uma transação de várias etapas está em andamento.
Armazene apenas os dados de que um serviço precisa. Um serviço pode precisar apenas de um subconjunto de informações sobre uma entidade de domínio. Por exemplo, no contexto de envio limitado, você precisa saber qual cliente está associado a uma entrega específica. Mas você não precisa do endereço de cobrança do cliente porque o contexto limitado das contas gerencia essas informações. Uma análise de domínio cuidadosa e uma abordagem DDD podem impor esse princípio.
Considere se seus serviços são coerentes e fracamente acoplados. Se dois serviços trocam informações continuamente entre si e criam APIs tagarelas, talvez seja necessário redesenhar seus limites de serviço. Mesclar os dois serviços ou refatorar sua funcionalidade.
Use um estilo de arquitetura controlado por eventos. Nesse estilo de arquitetura, um serviço publica um evento quando ocorrem alterações em seus modelos ou entidades públicas. Outros serviços podem inscrever-se nesses eventos. Por exemplo, outro serviço pode usar os eventos para construir uma exibição materializada dos dados mais adequados para consulta.
Publicar um esquema para eventos. Um serviço que possui eventos deve publicar um esquema para automatizar a serialização e desserialização de eventos. Essa abordagem evita o acoplamento apertado entre editores e assinantes. Considere o esquema JSON ou uma estrutura como Protobuf ou Avro.
Reduza os gargalos de eventos em grande escala. Em alta escala, os eventos podem se tornar um gargalo no sistema. Considere usar agregação ou envio em lote para reduzir a carga total.
Exemplo: escolher armazenamentos de dados para o aplicativo de entrega de drone
Os artigos anteriores desta série descrevem um serviço de entrega de drones como um exemplo em execução. Para obter mais informações sobre o cenário e a arquitetura correspondente, consulte Criar uma arquitetura de microsserviços.
Para recapitular, esse aplicativo define vários microsserviços para agendar entregas por drone. Quando um usuário agenda uma nova entrega, a solicitação do cliente inclui informações sobre a entrega, como locais de retirada e entrega, e sobre o pacote, como tamanho e peso. Essas informações definem uma unidade de trabalho.
Os vários serviços de back-end usam partes diferentes das informações na solicitação e têm perfis de leitura e gravação diferentes.

Serviço de entrega
O serviço de entrega armazena informações sobre cada entrega agendada ou em andamento. Ele escuta eventos dos drones e rastreia o status das entregas em andamento. Ele também envia eventos de domínio com atualizações do status da entrega.
Os usuários verificam frequentemente o status de uma entrega enquanto esperam pelo pacote. Portanto, o serviço de entrega requer um armazenamento de dados que enfatize a taxa de transferência (leitura e gravação) em vez do armazenamento de longo prazo. O serviço de entrega não faz consultas ou análises complexas. Ele busca apenas o status mais recente para uma entrega específica. A equipe do serviço de entrega escolheu o Redis Gerenciado do Azure por seu alto desempenho de leitura e gravação. As informações armazenadas no Redis Gerenciado do Azure são de curta duração. Depois que uma entrega é concluída, o serviço de histórico de entrega se torna o sistema de registro.
Serviço de histórico de entrega
O serviço de histórico de entrega monitora eventos de status de entrega do serviço de entrega. Ele armazena esses dados no armazenamento de longo prazo. Esses dados históricos dão suporte a dois cenários, cada um com requisitos de armazenamento diferentes.
O primeiro cenário agrega dados para análise de dados para otimizar o negócio ou melhorar a qualidade do serviço. O serviço de histórico de entrega não faz a análise de dados real. Ele apenas ingere e armazena os dados. Para esse cenário, o armazenamento deve ser otimizado para análise de dados em grandes conjuntos de dados e usar uma abordagem de esquema em leitura para acomodar várias fontes de dados. O Azure Data Lake Storage é uma boa opção para esse cenário porque é um sistema de arquivos Apache Hadoop compatível com o HDFS (Sistema de Arquivos Distribuído hadoop). Ele também está ajustado para melhorar o desempenho em cenários de análise de dados.
O segundo cenário permite que os usuários pesquisem o histórico de uma entrega após a conclusão da entrega. O Data Lake Storage não dá suporte a esse cenário. Para um desempenho ideal, armazene dados de série temporal no Data Lake Storage em pastas particionadas por data. Mas essa estrutura torna as pesquisas individuais baseadas em ID ineficientes. A menos que você também conheça o carimbo de data/hora, uma pesquisa de ID exige que você examine toda a coleção. Para resolver esse problema, o serviço de histórico de entrega também armazena um subconjunto dos dados históricos no Azure Cosmos DB para uma pesquisa mais rápida. Os registros não precisam permanecer no Azure Cosmos DB indefinidamente. Você pode arquivar entregas mais antigas após um período de tempo específico, como um mês, executando um processo em lote ocasional. O arquivamento de dados pode reduzir os custos do Azure Cosmos DB e manter os dados disponíveis para relatórios históricos do Data Lake Storage.
Para obter mais informações, consulte Ajustar o Data Lake Storage para obter desempenho.
Serviço de pacote
O serviço de pacote armazena informações sobre todos os pacotes. O armazenamento de dados do serviço de pacote deve atender aos seguintes requisitos:
- Armazenamento de longo prazo
- Alta taxa de escrita para lidar com um grande volume de dados
- Consultas simples por ID do pacote sem junções complexas ou restrições de integridade referencial
Os dados do pacote não são relacionais, portanto, um banco de dados orientado a documentos funciona bem. O Azure DocumentDB pode obter alta taxa de transferência usando coleções fragmentadas. A equipe de serviços de pacotes está familiarizada com a pilha MongoDB, Express.js, AngularJS e Node.js (MEAN), portanto, eles optam por implementar o Azure DocumentDB. Essa escolha permite que eles usem a experiência existente do MongoDB ao obter os benefícios de um serviço do Azure de alto desempenho totalmente gerenciado.