Este artigo descreve as práticas recomendadas para monitorar um aplicativo de microsserviços executado no Serviço de Kubernetes do Azure (AKS). Os tópicos específicos incluem coleta de telemetria, monitoramento do status de um cluster, métricas, registro em log, registro em log estruturado e rastreamento distribuído. Esse último é ilustrado neste diagrama:

Baixe um Arquivo Visio dessa arquitetura.
Coleção de telemetria
Em qualquer aplicativo complexo, em algum momento, algo dará errado. Em um aplicativo de microsserviço, você precisa controlar o que está acontecendo em dúzias ou até mesmo centenas de serviços. Para entender o que está acontecendo, você precisa coletar a telemetria do aplicativo. A telemetria pode ser dividida nessas categorias: logs, rastreamentos e métricas.
Os Logs são registros de eventos baseados em texto que ocorrem enquanto um aplicativo está em execução. Eles incluem itens como logs de aplicativos (instruções de rastreamento) e logs do servidor Web. Os logs são úteis principalmente para análise da causa raiz e análise forense.
Os rastreamentos, também chamados de operações, conectam as etapas de uma única solicitação entre várias chamadas dentro e entre os microsserviços. Eles podem fornecer observabilidade estruturada nas interações dos componentes do sistema. Os rastreamentos podem começar no início do processo de solicitação, como na interface do usuário de um aplicativo, e podem se propagar por meio de serviços de rede em uma rede de microsserviços que lidam com a solicitação.
- Intervalos são unidades de trabalho dentro de um rastreamento. Cada intervalo é conectado com um único rastreamento e pode ser aninhado com outros intervalos. Eles geralmente correspondem a solicitações individuais em uma operação de serviço, mas também podem definir o trabalho em componentes individuais dentro de um serviço. Os intervalos também rastreiam as chamadas de saída de um serviço para outro. (Às vezes, os intervalos são chamados de registros de dependência.)
Métricas são valores numéricos que podem ser analisados. Você pode usá-los para observar um sistema em tempo real (ou quase em tempo real) ou então para analisar as tendências de desempenho ao longo do tempo. Para entender um sistema de forma holística, você precisa coletar métricas em vários níveis da arquitetura, da infraestrutura física até o aplicativo, incluindo:
Métricas no nível do nó, incluindo CPU, memória, rede, disco e uso do sistema de arquivos. As métricas do sistema ajudam a compreender a alocação de recurso para cada nó no cluster e a solucionar problemas de discrepâncias.
Métricas do contêiner. Para aplicativos conteinerizados, você precisa coletar métricas no nível do contêiner, não apenas no nível da VM.
Métricas de aplicativo. Essas métricas são relevantes para entender o comportamento de um serviço. Exemplos incluem o número de solicitações HTTP de entrada na fila, a latência de solicitação e o comprimento da fila de mensagens. Os aplicativos também podem usar métricas personalizadas específicas ao domínio, como o número de transações de negócios processadas por minuto.
Métricas de serviço dependentes. Às vezes, os serviços chamam serviços ou pontos de extremidade externos, como serviços gerenciados de PaaS ou SaaS. É possível que os serviços de terceiros não forneçam métricas. Se não fornecerem, você dependerá de suas próprias métricas de aplicativo para acompanhar as estatísticas de latência e taxa de erros.
Monitorando o status do cluster
Use o Azure Monitor para monitorar a integridade dos clusters. A captura de tela a seguir mostra um cluster que tem erros críticos em pods implantados pelo usuário:

A partir daqui, você pode fazer uma busca mais detalhada para encontrar o problema. Por exemplo, se o status do pod for ImagePullBackoff, o Kubernetes não poderá efetuar pull da imagem de contêiner do registro. Esse problema pode ser causado por uma marca de contêiner inválida ou um erro de autenticação durante um pull do registro.
Se um contêiner falhar, o contêiner State se tornará Waiting, com um Reason de CrashLoopBackOff. Para um cenário típico, em que um pod faz parte de um conjunto de réplicas e a política de repetição é Always, esse problema não é exibido como um erro no status do cluster. No entanto, você pode executar consultas ou configurar alertas para essa condição. Para obter mais informações, confira Compreender o desempenho de cluster do AKS com os insights de Contêiner do Azure Monitor.
Existem várias pastas de trabalho específicas de contêiner disponíveis no painel de pastas de trabalho de um recurso do AKS. Você pode usar essas pastas de trabalho para obter uma visão geral rápida, solução de problemas, gerenciamento e insights. A captura de tela a seguir mostra uma lista de pastas de trabalho que estão disponíveis por padrão para cargas de trabalho do AKS.

Métricas
Recomendamos que você use o Monitor para coletar e visualizar métricas de seus clusters do AKS e outros serviços dependentes do Azure.
Para métricas de cluster e contêiner, habilite os insights de Contêiner do Azure Monitor. Quando esse recurso está habilitado, o Monitor coleta métricas de memória e processador de controladores, nós e contêineres por meio da API Kubernetes Metrics. Para obter mais informações sobre as métricas disponíveis nos insights do contêiner, confira as Noções básicas sobre o desempenho de clusters do AKS com os insights de Contêiner do Azure Monitor.
Use o Application Insights para coletar as métricas de aplicativo. O Application Insights é um serviço extensível de gerenciamento de desempenho de aplicativos (APM). Para usá-lo, você pode instalar um pacote de instrumentação em seu aplicativo. Esse pacote monitora o aplicativo e envia dados de telemetria para o Application Insights. Ele também pode efetuar pull de dados de telemetria do ambiente de host. Em seguida, os dados são enviados para o Monitor. O Application Insights também fornece correlação e acompanhamento de dependência internos. (Confira mais informações sobre o Rastreamento distribuído mais adiante nesse artigo.)
O Application Insights tem uma taxa de transferência máxima que é medida em eventos por segundo e limita a telemetria se a taxa de dados exceder o limite. Para obter detalhes, confira os os limites do Application Insights. Crie diferentes instâncias do Application Insights para cada ambiente, de modo que os ambientes de desenvolvimento/teste não disputem as cotas com a telemetria de produção.
Uma única operação pode gerar muitos eventos de telemetria, portanto, se um aplicativo tiver um alto volume de tráfego, é provável que sua captura de telemetria seja limitada. Para atenuar esse problema, você pode executar amostragem para reduzir o tráfego de telemetria. A desvantagem é que suas métricas serão menos precisas, a menos que a instrumentação dê suporte à pré-agregação. Nesse caso, haverá menos amostras de rastreamento para solução de problemas, mas as métricas manterão a precisão. Para obter mais informações, consulte Amostragem no Application Insights. Você também pode reduzir o volume de dados pré-agregando métricas. Ou seja, você pode calcular valores estatísticos, como média e desvio padrão, e enviar esses valores em vez da telemetria bruta. A postagem no blog descreve uma abordagem para uso do Application Insights em escala: Monitoramento do Azure e análise em escala.
Se a taxa de dados for alta o suficiente para desencadear a limitação e a amostragem ou agregação não forem aceitáveis, considere exportar as métricas para um banco de dados de série temporal, como o Azure Data Explorer, o Prometheus ou o InfluxDB, em execução no cluster.
O Azure Data Explorer é um serviço de exploração de dados nativo do Azure e altamente escalonável para dados de log e telemetria. Ele oferece suporte a vários formatos de dados, uma linguagem de consulta avançada e conexões para o consumo de dados em ferramentas populares, como Jupyter Notebooks e Grafana. O Azure Data Explorer tem conectores internos para ingerir dados de logs e métricas por meio dos Hubs de Eventos do Azure. Para obter mais informações, consulte Ingerir e consultar dados de monitoramento no Azure Data Explorer.
InfluxDB é um sistema baseado em push. É necessário que um agente envie as métricas por push. Você pode usar o TICK Stack para configurar o monitoramento do Kubernetes. Em seguida, você pode enviar métricas por push para o InfluxDB usando o Telegraf, que é um agente que coleta e relata métricas. Você pode usar o InfluxDB para eventos irregulares e tipos de dados de cadeia de caracteres.
O Prometheus é um sistema baseado em pull. Ele extrai periodicamente as métricas de locais configurados. O Prometheus pode extrair métricas geradas pelo Azure Monitor ou pelo kube-state-metrics. O serviço kube-state-metrics coleta métricas do servidor de API do Kubernetes e as disponibiliza para o Prometheus (ou um extrator que seja compatível com um ponto de extremidade de cliente do Prometheus). Para métricas do sistema, use o node exporter, que é um exportador Prometheus para métricas do sistema. O Prometheus é compatível com os dados de ponto flutuante, mas não com os dados de cadeia de caracteres, portanto, ele é apropriado para as métricas do sistema, mas não para logs. O Kubernetes Metrics Server é um agregador de dados de uso de recursos em todo o cluster.
Registrando em log
Aqui estão alguns dos desafios gerais ao registrar em log em um aplicativo de microsserviços:
- A compreensão do processo completo de uma solicitação de cliente, em que vários serviços podem ser invocados para manipular uma única solicitação.
- Consolidar logs de vários serviços em uma única visualização agregada.
- Analisar logs provenientes de várias fontes que usam seus próprios esquemas de registro ou não têm um esquema específico. Os logs podem ser gerados por componentes de terceiros que você não controla.
- As arquiteturas de microsserviços normalmente geram um volume maior de logs do que os monólitos tradicionais porque há mais serviços, chamadas de rede e etapas em uma transação. Isso significa que o próprio registro em log pode ser um gargalo de desempenho ou de recursos para o aplicativo.
Existem mais alguns desafios para arquiteturas baseadas em Kubernetes:
- Os contêineres podem ser movidos e reagendados.
- O Kubernetes tem uma abstração de rede que usa endereços IP virtuais e mapeamentos de porta.
No Kubernetes, a abordagem padrão para o registro em log é que um contêiner grave os registros em stdout e stderr. O mecanismo do contêiner redireciona esses fluxos para um driver de registro em log. Para facilitar a consulta e evitar a possível perda de dados de logs se um nó parar de responder, a abordagem mais comum é coletar os logs de cada nó e enviá-los para um local de armazenamento central.
O Azure Monitor integra-se ao AKS para dar suporte a essa abordagem. O Monitor coleta logs de contêiner e os envia para um workspace do Log Analytics. A partir daí, você pode usar a Linguagem de Consulta Kusto para gravar consultas nos logs agregados. Por exemplo, aqui está uma consulta Kusto para mostrar os logs de contêiner de um pod especificado:
ContainerLogV2
| where PodName == "podName" //update with target pod
| project TimeGenerated, Computer, ContainerId, LogMessage, LogSource
O Azure Monitor é um serviço gerenciado, e a configuração de um cluster do AKS para usar o Monitor é uma alteração de configuração simples na CLI ou no modelo do Azure Resource Manager. (Para obter mais informações, confira Como habilitar os insights de Contêiner do Azure Monitor.) Outra vantagem de usar o Azure Monitor é porque ele consolida seus logs do AKS com outros logs de plataforma do Azure para fornecer uma experiência de monitoramento unificada.
O Azure Monitor é cobrado por GB (gigabyte) de dados ingeridos no serviço. (Veja os Preços do Azure Monitor.) Em grandes volumes, o custo pode ser um fator a ser considerado. Há muitas alternativas de softwares de código aberto disponíveis para o ecossistema do Kubernetes. Por exemplo, muitas organizações usam o Fluentd com o Elasticsearch. O Fluentd é um coletor de dados de código aberto e Elasticsearch é um banco de dados de documento que é usado para pesquisa. Um desafio com essas opções é a necessidade de configuração e gerenciamento extras do cluster. Para uma carga de trabalho de produção, talvez seja necessário fazer experiências com as configurações. Você também precisará monitorar o desempenho da infraestrutura de registro em log.
OpenTelemetry
O OpenTelemetry é um esforço de vários setores para melhorar o rastreamento por meio da padronização da interface entre aplicativos, bibliotecas, telemetria e coletores de dados. Quando você usa uma biblioteca e uma estrutura que são instrumentadas com o OpenTelemetry, a maior parte do trabalho de operações de rastreamento, que tradicionalmente são operações do sistema, é tratada pelas bibliotecas subjacentes, o que inclui os seguintes cenários comuns:
- Registro em log das operações básicas de solicitação, como hora de início, hora de saída e duração
- Exceções lançadas
- Propagação de contexto (como enviar uma ID de correlação entre limites de chamada HTTP)
Em vez disso, as bibliotecas e estruturas de base que lidam com essas operações criam estruturas de dados de intervalo e rastreamento avançadas e as propagam entre contextos. Antes do OpenTelemetry, elas normalmente eram apenas injetadas como mensagens de log especiais ou como estruturas de dados proprietárias específicas do fornecedor que criou as ferramentas de monitoramento. O OpenTelemetry também incentiva um modelo de dados de instrumentação mais avançado do que uma abordagem tradicional que prioriza o registro em log, e os logs são mais úteis porque as mensagens de log estão vinculadas aos rastreamentos e intervalos em que foram geradas. Isso geralmente facilita a localização de logs associados a uma operação ou solicitação específica.
Muitos dos SDKs do Azure foram instrumentados com o OpenTelemetry ou estão em processo de implementação.
Um desenvolvedor de aplicativos pode adicionar instrumentação manual usando os SDKs do OpenTelemetry para realizar as seguintes atividades:
- Adicione instrumentação onde uma biblioteca subjacente não a fornece.
- Enriqueça o contexto do rastreamento adicionando intervalos para expor unidades de trabalho específicas do aplicativo (como um loop de ordem que cria um intervalo para o processamento de cada linha de ordem).
- Enriqueça os vãos existentes com chaves de entidade para facilitar o rastreamento. (Por exemplo, adicione uma chave/valor OrderID à solicitação que processa essa ordem.) Essas chaves são exibidas pelas ferramentas de monitoramento como valores estruturados para consulta, filtragem e agregação (sem analisar as cadeias de caracteres de mensagens de log ou procurar combinações de sequências de mensagens de log, como era comum com uma abordagem que priorizava o registro em log).
- Propague o contexto de rastreamento acessando atributos de rastreamento e intervalo, injetando traceIds em respostas e cargas e/ou lendo traceIds de mensagens de entrada, a fim de criar solicitações e intervalos.
Leia mais sobre instrumentação e os SDKs do OpenTelemetry na documentação do OpenTelemetry.
Application Insights
O Application Insights coleta dados avançados do OpenTelemetry e de suas bibliotecas de instrumentação e os captura em um armazenamento de dados eficiente para oferecer visualização avançada e suporte a consultas. As bibliotecas de instrumentação do Application Insights baseadas no OpenTelemetry, para linguagens como .NET, Java, Node.js e Python, facilitam o envio de dados de telemetria para o Application Insights.
Se você estiver usando o .NET Core, recomendamos que você também considere usar a biblioteca do Application Insights para Kubernetes . Essa biblioteca enriquece rastreamentos do Application Insights com informações adicionais, como o contêiner, o nó, o pod, os rótulos e o conjunto de réplicas.
O Application Insights mapeia o contexto OpenTelemetry para seu modelo de dados interno:
- Rastreamento –> Operação
- ID de rastreamento –> ID da operação
- Intervalo –> Solicitação ou Dependência
Leve em conta as seguintes considerações:
- O Application Insights limita a telemetria se a taxa de dados exceder um limite máximo. Para obter detalhes, confira os os limites do Application Insights. Uma única operação pode gerar vários eventos de telemetria, portanto, se um aplicativo passar por um alto volume de tráfego, é provável que ele seja limitado.
- Como o Application Insights agrupa dados em lotes, você pode perder um lote se um processo falhar devido a uma exceção não tratada.
- A cobrança do Application Insights é baseada no volume de dados. Para obter mais informações, consulte Gerenciar o preço e o volume de dados no Application Insights.
Registro em log estruturado
Para facilitar a análise de logs, use o registro em log estruturado quando puder. Quando você usa o registro em log estruturado, o aplicativo grava os logs em um formato estruturado, como JSON, em vez de gerar cadeias de caracteres de texto não estruturadas. Existem muitas bibliotecas de log estruturadas disponíveis. Por exemplo, aqui está uma instrução de registro em log que usa a biblioteca Serilog para .NET Core:
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
...
}
Aqui, a chamada para LogInformation incluir um parâmetro DeliveryInfo um parâmetro Id. Quando você usa o registro em log estruturado, esses valores não são interpolados na cadeia de caracteres da mensagem. Em vez disso, a saída do log é semelhante a esta:
{"@t":"2019-06-13T00:57:09.9932697Z","@mt":"In Put action with delivery {Id}: {@DeliveryInfo}","Id":"36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef","DeliveryInfo":{...
Trata-se de uma cadeia de caracteres JSON, em que o campo @t é um carimbo de data/hora, @mt é a cadeia de caracteres da mensagem e os pares chave/valor restantes são os parâmetros. A saída do formato JSON facilita a consulta dos dados de forma estruturada. Por exemplo, a seguinte consulta do Log Analytics, escrita na linguagem de consulta Kusto, procura instâncias dessa mensagem específica em todos os contêineres chamados fabrikam-delivery:
traces
| where customDimensions.["Kubernetes.Container.Name"] == "fabrikam-delivery"
| where customDimensions.["{OriginalFormat}"] == "In Put action with delivery {Id}: {@DeliveryInfo}"
| project message, customDimensions["Id"], customDimensions["@DeliveryInfo"]
Se você exibir o resultado no portal do Azure, poderá ver que DeliveryInfo é um registro estruturado que contém a representação serializada do modelo DeliveryInfo:

Veja o JSON desse exemplo:
{
"Id": "36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef",
"Owner": {
"UserId": "user id for logging",
"AccountId": "52dadf0c-0067-43e7-af76-86e32b48bc5e"
},
"Pickup": {
"Altitude": 0.29295161612934972,
"Latitude": 0.26815900219052985,
"Longitude": 0.79841844309047727
},
"Dropoff": {
"Altitude": 0.31507750848078986,
"Latitude": 0.753494655598651,
"Longitude": 0.89352830773849423
},
"Deadline": "string",
"Expedited": true,
"ConfirmationRequired": 0,
"DroneId": "AssignedDroneId01ba4d0b-c01a-4369-ba75-51bde0e76cc9"
}
Muitas mensagens de log marcam o início ou o fim de uma unidade de trabalho ou conectam uma entidade empresarial com um conjunto de mensagens e operações para rastreabilidade. Em muitos casos, enriquecer objetos de solicitação e intervalo do OpenTelemetry é uma abordagem melhor do que apenas registrar em log o início e o fim da operação. Ao fazer isso, adiciona esse contexto a todos os rastreamentos conectados e operações secundárias, e coloca essas informações no escopo da operação completa. Os SDKs do OpenTelemetry para várias linguagens dão suporte à criação de intervalos ou à adição de atributos personalizados em intervalos. Por exemplo, o código a seguir usa o SDK do Java OpenTelemetry, que tem é compatível com o Application Insights. Um intervalo primário existente (por exemplo, um intervalo de solicitação associado a uma chamada do controlador REST e criado pela estrutura web que está sendo usada) pode ser enriquecido com uma ID de entidade associada a ele, conforme mostrado aqui:
import io.opentelemetry.api.trace.Span;
// ...
Span.current().setAttribute("A1234", deliveryId);
Esse código define uma chave ou valor no intervalo atual, que está conectado a operações e mensagens de log que ocorrem nesse intervalo. O valor aparece no objeto de solicitação do Application Insights, conforme mostrado aqui:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project timestamp, name, url, success, resultCode, duration, operation_Id, deliveryId
Essa técnica se torna mais eficiente quando usada com logs, filtragens e anotações de rastreamentos de log com contexto de intervalo, conforme mostrado aqui:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project deliveryId, operation_Id, requestTimestamp = timestamp, requestDuration = duration // keep some request info
| join kind=inner traces on operation_Id // join logs only for this deliveryId
| project requestTimestamp, requestDuration, logTimestamp = timestamp, deliveryId, message
Se você usar uma biblioteca ou estrutura já esteja instrumentada com o OpenTelemetry, ela lidará com a criação de intervalos e solicitações, mas o código do aplicativo também poderá criar unidades de trabalho. Por exemplo, um método que faz loop em uma matriz de entidades e executa o trabalho em cada uma delas pode criar um intervalo para cada iteração do loop de processamento. Para mais informações sobre como adicionar instrumentação ao código do aplicativo e da biblioteca, confira a documentação de instrumentação do OpenTelemery.
Rastreamento distribuído
Um dos desafios quando você usa microsserviços é entender o fluxo de eventos entre os serviços. Uma única transação pode envolver chamadas para vários serviços.
Exemplo de rastreamento distribuído
Este exemplo descreve o caminho de uma transação distribuída por meio de um conjunto de microsserviços. O exemplo é baseado em um aplicativo de entrega por drone.
Nesse cenário, a transação distribuída inclui as seguintes etapas:
- O serviço ingestão coloca uma mensagem em uma fila do Barramento de Serviço do Azure.
- O serviço Fluxo de trabalho extrai a mensagem da fila.
- O serviço Fluxo de trabalho chama três serviços de back-end para processar a solicitação (Agendador de Drone, Pacote e Entrega).
A captura de tela a seguir mostra o mapa do aplicativo usado para a entrega por drone. Este mapa mostra chamadas para o ponto de extremidade da API pública que resultam em um fluxo de trabalho que envolve cinco microsserviços.
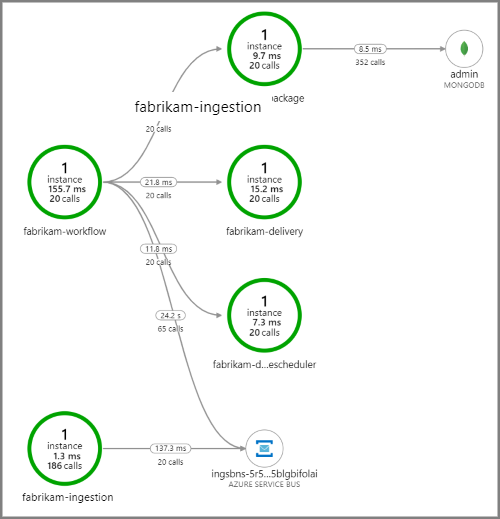
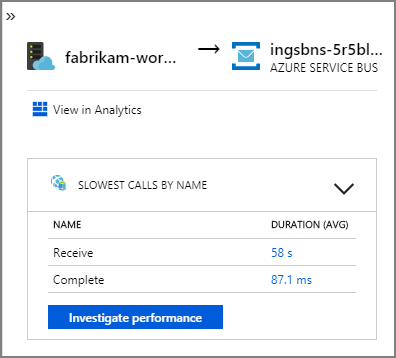
As setas de fabrikam-workflow e fabrikam-ingestion em uma fila do Barramento de Serviço mostram para onde as mensagens são enviadas e recebidas. Não é possível saber, pelo diagrama, qual serviço está enviando mensagens e qual está recebendo. As setas apenas mostram que ambos os serviços estão chamando o Barramento de Serviço. No entanto, as informações sobre qual serviço está enviando e qual está recebendo estão disponíveis nos detalhes:
Como cada chamada inclui uma ID de operação, você também pode visualizar as etapas de ponta a ponta de uma única transação, incluindo informações de tempo e as chamadas HTTP em cada etapa. Aqui está a visualização de uma dessas transações:

Essa visualização mostra as etapas de serviço desde a ingestão até a fila, da fila até o serviço Fluxo de trabalho e do serviço Fluxo de trabalho até os outros serviços de back-end. A última etapa é o serviço Fluxo de trabalho marcando a mensagem do Barramento de Serviço como concluída.
Esse exemplo mostra chamadas para um serviço de back-end que estão falhando:
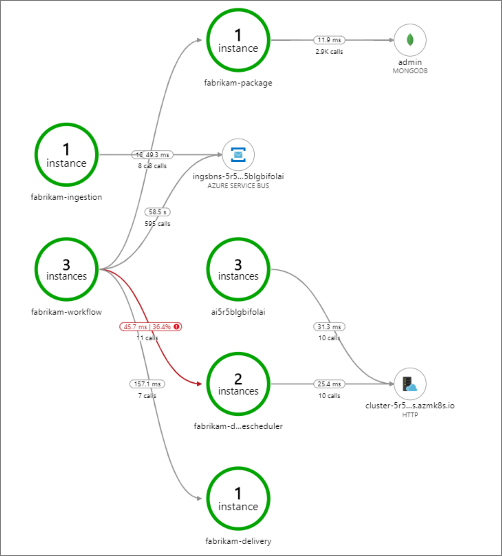
Esse mapa mostra que uma grande fração (36%) das chamadas do serviço Agendador de drones falhou durante o período da consulta. A visualização da transação de ponta a ponta revela que ocorre uma exceção quando uma solicitação HTTP PUT é enviada ao serviço:

Se você analisar mais, poderá ver que é um tipo de exceção de soquete: "Não existe tal dispositivo ou endereço".
Fabrikam.Workflow.Service.Services.BackendServiceCallFailedException:
No such device or address
---u003e System.Net.Http.HttpRequestException: No such device or address
---u003e System.Net.Sockets.SocketException: No such device or address
Essa exceção sugere que o serviço de back-end não pode ser acessado. Nesse ponto, você pode usar o kubectl para visualizar a configuração de implantação. Neste exemplo, o nome do host do serviço não está sendo resolvido devido a um erro nos arquivos de configuração do Kubernetes. O artigo Depurar Serviços na documentação do Kubernetes tem dicas para diagnosticar esse tipo de erro.
Aqui estão algumas causas comuns para esses erros:
- Bugs de código. Esses bugs podem aparecer como:
- Exceções. Verifique os logs do Application Insights para visualizar os detalhes da exceção.
- Um processo falhando. Confira o status do contêiner e do pod e visualize os logs de contêiner ou rastreamentos do Application Insights.
- Erros 5xx HTTP.
- Esgotamento de recursos:
- Procure por limitações (HTTP 429) ou solicite tempos limite.
- Analise as métricas do contêiner em relação à CPU, à memória e ao disco.
- Observe as configurações de limites de recursos de contêiner e pod.
- Descoberta de serviço. Examine a configuração do serviço Kubernetes e os mapeamentos de porta.
- Incompatibilidade de API. Procure por erros HTTP 400. Se as APIs forem versionadas, verifique a versão que está sendo chamada.
- Erro ao efetuar pull de uma imagem de contêiner. Observe a especificação do pod. Confira também se o cluster está autorizado a efetuar pull do registro de contêiner.
- Problemas de RBAC.
Próximas etapas
Saiba mais sobre os recursos no Azure Monitor que dão suporte ao monitoramento de aplicativos no AKS:
- Visão geral de Insights de contêiner do Azure Monitor
- Compreender o desempenho de cluster do AKS com os insights de Contêiner do Azure Monitor