2. Examine a integridade do nó e do pod
Este artigo faz parte de uma série. Comece com essa visão geral.
Se as verificações de cluster executadas na etapa anterior estiverem claras, verifique a integridade dos nós de trabalho do AKS (Serviço de Kubernetes do Azure). Siga as seis etapas neste artigo para verificar a integridade dos nós, determinar o motivo de um nó não íntegro e resolver o problema.
Etapa 1: Verificar a integridade dos nós de trabalho
Vários fatores podem contribuir para nós não íntegros em um cluster AKS. Uma razão comum é a falha de comunicação entre o plano de controle e os nós. Essa falha de comunicação geralmente é causada por configurações incorretas nas regras de roteamento e firewall.
Ao configurar seu cluster AKS para roteamento definido pelo usuário, você deve configurar caminhos de saída por meio de um NVA (dispositivo virtual de rede) ou um firewall, como um firewall do Azure. Para resolver um problema de configuração incorreta, recomendamos que você configure o firewall para permitir as portas necessárias e os FQDNs (nomes de domínio totalmente qualificados) de acordo com as diretrizes de tráfego de saída do AKS.
Outra razão para nós não íntegros pode ser recursos inadequados de computação, memória ou armazenamento que criam pressões kubelet. Nesses casos, a ampliação dos recursos pode efetivamente resolver o problema.
Em um cluster AKS privado, problemas de resolução de DNS (Sistema de Nomes de Domínio) podem causar problemas de comunicação entre o plano de controle e os nós. Você deve verificar se o nome DNS do servidor de API do Kubernetes é resolvido para o endereço IP privado do servidor de API. A configuração incorreta de um servidor DNS personalizado é uma causa comum de falhas de resolução de DNS. Se você usar servidores DNS personalizados, certifique-se de especificá-los corretamente como servidores DNS na rede virtual em que os nós são provisionados. Confirme também se o servidor de API privada do AKS pode ser resolvido por meio do servidor DNS personalizado.
Depois de resolver esses possíveis problemas relacionados à comunicação do plano de controle e à resolução de DNS, você pode resolver e resolver com eficiência problemas de integridade do nó no cluster AKS.
Você pode avaliar a integridade dos nós usando um dos métodos a seguir.
Exibição de integridade de contêineres do Azure Monitor
Para exibir a integridade de nós, pods de usuário e pods do sistema em seu cluster AKS, execute estas etapas:
- No portal do Azure, vá para o Azure Monitor.
- Na seção Insights do painel de navegação, selecione Contêineres.
- Selecione Clusters monitorados para obter uma lista dos clusters AKS que estão sendo monitorados.
- Escolha um cluster AKS na lista para exibir a integridade dos nós, pods de usuário e pods do sistema.

Exibição de nós AKS
Para garantir que todos os nós no cluster AKS estejam no estado pronto, siga estas etapas:
- No portal do Azure, acesse o seu cluster AKS.
- Na seção Configurações do painel de navegação, selecione Pools de nós.
- Selecione Nós.
- Verifique se todos os nós estão no estado pronto.

Monitoramento em cluster com o Prometheus e o Grafana
Se tiver implantado o Prometheus e o Grafana em seu cluster AKS, você poderá usar o Painel de Detalhes do Cluster K8 para obter insights. Este painel mostra as métricas de cluster do Prometheus e apresenta informações vitais, como uso da CPU, uso da memória, atividade da rede e uso do sistema de arquivos. Ele também mostra estatísticas detalhadas para pods individuais, contêineres e serviços systemd.
No painel, selecione Condições do nó para ver as métricas sobre a integridade e o desempenho do cluster. Você pode controlar nós que podem ter problemas, como problemas com sua programação, a rede, a pressão de disco, a pressão de memória, a PID (pressão de derivada integral) proporcional ou o espaço em disco. Monitore essas métricas para que você possa identificar e resolver proativamente quaisquer problemas potenciais que afetem a disponibilidade e o desempenho do cluster AKS.

Monitorar o serviço gerenciado para Prometheus e o Espaço Gerenciado do Azure para Grafana
Você pode usar painéis predefinidos para visualizar e analisar métricas do Prometheus. Para fazer isso, você deve configurar seu cluster do AKS para coletar métricas do Prometheus em Monitorar o serviço gerenciado para Prometheus e conectar seu espaço de trabalho do Monitor a um espaço de trabalho do Espaço Gerenciado do Azure para Grafana. Esses painéis fornecem uma visão abrangente do desempenho e da integridade do cluster Kubernetes.
Os painéis são provisionados na instância especificada do Espaço Gerenciado do Azure para Grafana na pasta Prometheus Gerenciado. Alguns painéis incluem:
- Kubernetes/Recursos de computação/Cluster
- Kubernetes/Recursos de computação/Namespace (Pods)
- Kubernetes/Recursos de computação/Nó (Pods)
- Kubernetes/Recursos de computação/Pod
- Kubernetes/Recursos de computação/Namespace (Cargas de trabalho)
- Kubernetes/Recursos de computação/Carga de trabalho
- Kubernetes/Kubelet
- Exportador de nós/Método USE/Nó
- Exportador de nós/Nós
- Kubernetes / Recursos de computação / Cluster (Windows)
- Kubernetes / Recursos de computação / Namespace (Windows)
- Kubernetes / Recursos de computação / Pod (Windows)
- Kubernetes / Método USE / Cluster (Windows)
- Kubernetes / Método USE / Nó (Windows)
Esses painéis integrados são amplamente utilizados na comunidade de código aberto para monitorar clusters do Kubernetes com Prometheus e Grafana. Use esses painéis para ver métricas, como uso de recursos, integridade do pod e atividade de rede. Você também pode criar painéis personalizados adaptados às suas necessidades de monitoramento. Os painéis ajudam você a monitorar e analisar com eficiência as métricas do Prometheus em seu cluster do AKS, o que permite otimizar o desempenho, solucionar problemas e garantir o bom funcionamento de suas cargas de trabalho do Kubernetes.
Você pode usar o painel Kubernetes/Recursos de Computação/Nó (Pods) para ver as métricas dos nós do agente do Linux. Você pode visualizar o uso da CPU, a cota da CPU, o uso de memória e a cota de memória para cada pod.

Se o cluster incluir nós de agente do Windows, você poderá usar o painel Kubernetes/Método USE/Nó (Windows) para visualizar as métricas do Prometheus coletadas desses nós. Esse painel fornece uma visão abrangente do consumo de recursos e do desempenho para nós do Windows em seu cluster.
Aproveite esses painéis dedicados para que você possa monitorar e analisar facilmente métricas importantes relacionadas à CPU, memória e outros recursos nos nós do agente Linux e Windows. Essa visibilidade permite identificar possíveis gargalos, otimizar a alocação de recursos e garantir uma operação eficiente em todo o cluster AKS.
Etapa 2: Verificar a conectividade do plano de controle e do nó de trabalho
Se os nós de trabalho estiverem íntegros, você deverá examinar a conectividade entre o plano de controle AKS gerenciado e os nós de trabalho do cluster. O AKS permite a comunicação entre o servidor de API do Kubernetes e o kubelets de nós individuais por meio de um método de comunicação de túnel seguro. Esses componentes podem se comunicar mesmo se estiverem em redes virtuais diferentes. O túnel é protegido com criptografia mTLS (Mutual Transport Layer Security). O túnel principal que o AKS usa chama-se Konnectivity(anteriormente conhecido como apiserver-network-proxy). Verifique se todas as regras de rede e FQDNs atendem às regras de rede do Azure necessárias.
Para verificar a conectividade entre o plano de controle AKS gerenciado e os nós de trabalho do cluster de um cluster AKS, você pode usar a ferramenta de linha de comando kubectl.
Para garantir que os pods do agente Konnectivity funcionem corretamente, execute o seguinte comando:
kubectl get deploy konnectivity-agent -n kube-system
Certifique-se de que os pods estejam em um estado pronto.
Se houver um problema com a conectividade entre o plano de controle e os nós de trabalho, estabeleça a conectividade depois de garantir que as regras de tráfego de saída AKS necessárias sejam permitidas.
Execute o seguinte comando para reiniciar os pods konnectivity-agent:
kubectl rollout restart deploy konnectivity-agent -n kube-system
Se reiniciar os pods não corrigir a conexão, verifique se há anomalias nos registros. Execute o comando a seguir para exibir os logs dos pods konnectivity-agent:
kubectl logs -l app=konnectivity-agent -n kube-system --tail=50
Os logs devem mostrar a seguinte saída:
I1012 12:27:43.521795 1 options.go:102] AgentCert set to "/certs/client.crt".
I1012 12:27:43.521831 1 options.go:103] AgentKey set to "/certs/client.key".
I1012 12:27:43.521834 1 options.go:104] CACert set to "/certs/ca.crt".
I1012 12:27:43.521837 1 options.go:105] ProxyServerHost set to "sethaks-47983508.hcp.switzerlandnorth.azmk8s.io".
I1012 12:27:43.521841 1 options.go:106] ProxyServerPort set to 443.
I1012 12:27:43.521844 1 options.go:107] ALPNProtos set to [konnectivity].
I1012 12:27:43.521851 1 options.go:108] HealthServerHost set to
I1012 12:27:43.521948 1 options.go:109] HealthServerPort set to 8082.
I1012 12:27:43.521956 1 options.go:110] AdminServerPort set to 8094.
I1012 12:27:43.521959 1 options.go:111] EnableProfiling set to false.
I1012 12:27:43.521962 1 options.go:112] EnableContentionProfiling set to false.
I1012 12:27:43.521965 1 options.go:113] AgentID set to b7f3182c-995e-4364-aa0a-d569084244e4.
I1012 12:27:43.521967 1 options.go:114] SyncInterval set to 1s.
I1012 12:27:43.521972 1 options.go:115] ProbeInterval set to 1s.
I1012 12:27:43.521980 1 options.go:116] SyncIntervalCap set to 10s.
I1012 12:27:43.522020 1 options.go:117] Keepalive time set to 30s.
I1012 12:27:43.522042 1 options.go:118] ServiceAccountTokenPath set to "".
I1012 12:27:43.522059 1 options.go:119] AgentIdentifiers set to .
I1012 12:27:43.522083 1 options.go:120] WarnOnChannelLimit set to false.
I1012 12:27:43.522104 1 options.go:121] SyncForever set to false.
I1012 12:27:43.567902 1 client.go:255] "Connect to" server="e9df3653-9bd4-4b09-b1a7-261f6104f5d0"
Observação
Quando um cluster AKS é configurado com uma integração de rede virtual do servidor de API e uma CNI (interface de rede de contêiner) do Azure ou uma CNI do Azure com atribuição de IP de pod dinâmico, não há necessidade de implantar agentes do Konnectivity. Os pods de servidor de API integrados podem estabelecer comunicação direta com os nós de trabalho do cluster por meio de rede privada.
No entanto, quando você usa a integração de rede virtual do servidor de API com o Azure CNI Overlay ou traz seu próprio CNI (BYOCNI), o Konnectivity é implantado para facilitar a comunicação entre os servidores de API e os IPs de pod. A comunicação entre os servidores de API e os nós de trabalho permanece direta.
Você também pode pesquisar os logs de contêiner no serviço de log e monitoramento para recuperar os logs. Para obter um exemplo que procura os erros de conectividade aks-link, consulte Logs de consulta de insights de contêiner.
Execute a seguinte consulta para recuperar os logs:
ContainerLogV2
| where _ResourceId =~ "/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.ContainerService/managedClusters/<cluster-ID>" // Use the IDs and names of your resources for these values.
| where ContainerName has "aks-link"
| project LogSource,LogMessage, TimeGenerated, Computer, PodName, ContainerName, ContainerId
| order by TimeGenerated desc
| limit 200
Execute a seguinte consulta para pesquisar logs de contêiner para qualquer pod com falha em um namespace específico:
let KubePodInv = KubePodInventory
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where _ResourceId =~ "<cluster-resource-ID>" // Use your resource ID for this value.
| where Namespace == "<pod-namespace>" // Use your target namespace for this value.
| where PodStatus == "Failed"
| extend ContainerId = ContainerID
| summarize arg_max(TimeGenerated, *) by ContainerId, PodStatus, ContainerStatus
| project ContainerId, PodStatus, ContainerStatus;
KubePodInv
| join
(
ContainerLogV2
| where TimeGenerated >= startTime and TimeGenerated < endTime
| where PodNamespace == "<pod-namespace>" //update with target namespace
) on ContainerId
| project TimeGenerated, PodName, PodStatus, ContainerName, ContainerId, ContainerStatus, LogMessage, LogSource
Se você não conseguir obter os logs usando consultas ou a ferramenta kubectl, use a autenticação SSH (Secure Shell). Este exemplo localiza o pod tunnelfront depois de se conectar ao nó via SSH.
kubectl pods -n kube-system -o wide | grep tunnelfront
ssh azureuser@<agent node pod is on, output from step above>
docker ps | grep tunnelfront
docker logs …
nslookup <ssh-server_fqdn>
ssh -vv azureuser@<ssh-server_fqdn> -p 9000
docker exec -it <tunnelfront_container_id> /bin/bash -c "ping bing.com"
kubectl get pods -n kube-system -o wide | grep <agent_node_where_tunnelfront_is_running>
kubectl delete po <kube_proxy_pod> -n kube-system
Etapa 3: Validar a resolução DNS ao restringir a saída
A resolução DNS é um aspecto crucial do seu cluster AKS. Se a resolução DNS não estiver funcionando corretamente, ela poderá causar erros no plano de controle ou falhas de extração de imagem de contêiner. Para garantir que a resolução DNS para o servidor de API do Kubernetes esteja funcionando corretamente, execute estas etapas:
Execute o comando kubectl exec para abrir um shell de comando no contêiner que está sendo executado no pod.
kubectl exec --stdin --tty your-pod --namespace <namespace-name> -- /bin/bashVerifique se as ferramentas nslookup ou dig estão instaladas no contêiner.
Se nenhuma ferramenta estiver instalada no pod, execute o seguinte comando para criar um pod utilitário no mesmo namespace.
kubectl run -i --tty busybox --image=busybox --namespace <namespace-name> --rm=true -- shVocê pode recuperar o endereço do servidor de API na página de visão geral do cluster AKS no portal do Azure ou pode executar o comando a seguir.
az aks show --name <aks-name> --resource-group <resource-group-name> --query fqdn --output tsvExecute o comando a seguir para tentar resolver o servidor de API do AKS. Para obter mais informações, consulte Solucionar problemas de falhas de resolução de DNS de dentro do pod, mas não do nó de trabalho.
nslookup myaks-47983508.hcp.westeurope.azmk8s.ioVerifique o servidor DNS upstream no pod para determinar se a resolução DNS esteja funcionando corretamente. Por exemplo, para o DNS do Azure, execute o comando
nslookup.nslookup microsoft.com 168.63.129.16Se as etapas anteriores não fornecerem insights, conecte-se a um dos nós de trabalho e tente a resolução DNS desde o nó. Esta etapa ajuda a identificar se o problema está relacionado ao AKS ou à configuração de rede.
Se a resolução DNS for bem-sucedida desde o nó, mas não do pod, o problema pode estar relacionado ao DNS do Kubernetes. Para conhecer as etapas para depurar a resolução DNS do pod, consulte Solucionar problemas de falhas de resolução DNS.
Se a resolução DNS falhar a partir do nó, revise a configuração de rede para garantir que os caminhos e portas de roteamento apropriados estejam abertos para facilitar a resolução do DNS.
Etapa 4: Verificar se há erros de kubelet
Verifique a condição do processo kubelet que é executado em cada nó de trabalho e certifique-se de que ele não esteja sob pressão. A pressão potencial pode pertencer à CPU, memória ou armazenamento. Para verificar o status de kubelets de nó individuais, você pode usar um dos métodos a seguir.
Pasta de trabalho kubelet do AKS
Para garantir que os kubelets do nó do agente funcionem corretamente, execute estas etapas:
Vá para o seu cluster AKS no portal do Azure.
Na seção Monitoramento do painel de navegação, selecione Pastas de Trabalho.
Selecione a pasta de trabalho Kubelet .

Selecione Operações e verifique se as operações de todos os nós de trabalho foram concluídas.



Monitoramento em cluster com o Prometheus e o Grafana
Se você tiver implantado o Prometheus e o Grafana em seu cluster AKS, poderá usar o painel Kubernetes/Kubelet para obter insights sobre a integridade e o desempenho de kubelets de nó individuais.

Monitorar o serviço gerenciado para Prometheus e o Espaço Gerenciado do Azure para Grafana
Você pode usar o painel predefinido do Kubernetes/Kubelet para visualizar e analisar as métricas do Prometheus para os kubelets do nó de trabalho. Para fazer isso, você deve configurar seu cluster do AKS para coletar métricas do Prometheus em Monitorar o serviço gerenciado para Prometheus e conectar seu espaço de trabalho do Monitor a um espaço de trabalho do Espaço Gerenciado do Azure para Grafana.

A pressão aumenta quando um kubelet reinicia e causa um comportamento esporádico e imprevisível. Certifique-se de que a contagem de erros não aumente continuamente. Um erro ocasional é aceitável, mas um crescimento constante indica um problema subjacente que você deve investigar e resolver.
Etapa 5: Usar a ferramenta NPD (detector de problemas do nó) para verificar a integridade do nó
O NPD é uma ferramenta do Kubernetes que você pode usar para identificar e relatar problemas relacionados ao nó. Ele opera como um serviço systemd em cada nó dentro do cluster. Ele reúne métricas e informações do sistema, como uso da CPU, uso do disco e status de conectividade de rede. Quando um problema é detectado, a ferramenta NPD gera um relatório sobre os eventos e a condição do nó. No AKS, a ferramenta NPD é usada para monitorar e gerenciar nós em um cluster do Kubernetes hospedado na nuvem do Azure. Para obter mais informações, consulte NPD em nós AKS.
Etapa 6: Verificar as operações IOPS (E/S de disco por segundo) para limitação
Para garantir que as IOPS não estejam sendo limitadas e afetando serviços e cargas de trabalho no cluster AKS, você pode usar um dos seguintes métodos.
Pasta de trabalho de E/S de disco do nó AKS
Para monitorar as métricas relacionadas à E/S de disco dos nós de trabalho no cluster AKS, você pode usar a pasta de trabalho E/S de disco do nó. Siga estas etapas para acessar a pasta de trabalho:
Vá para o seu cluster AKS no portal do Azure.
Na seção Monitoramento do painel de navegação, selecione Pastas de Trabalho.
Selecione a pasta de trabalho E/S do Disco do Nó.

Revise as métricas relacionadas a E/S.
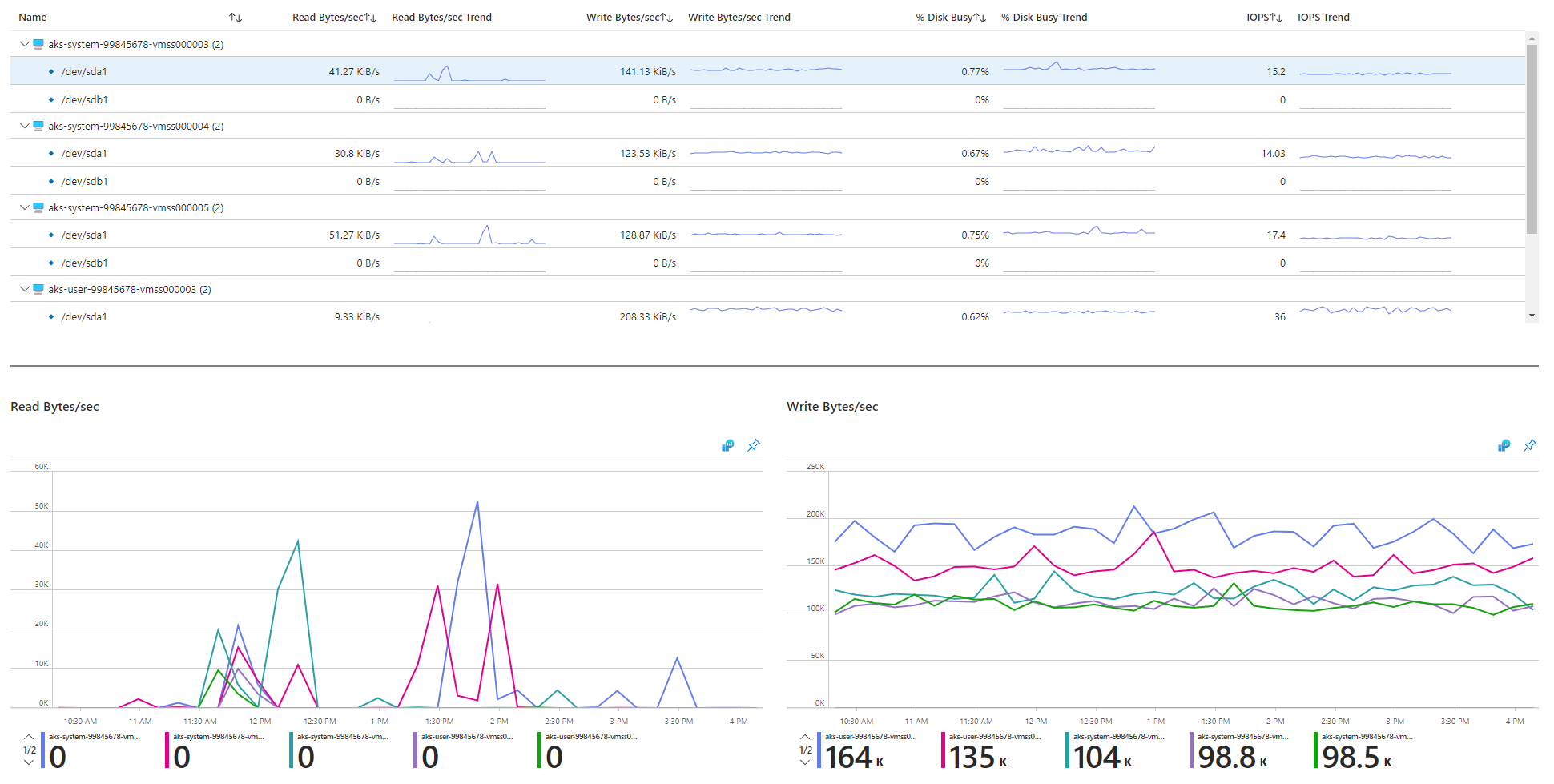


Monitoramento em cluster com o Prometheus e o Grafana
Se tiver implantado o Prometheus e o Grafana em seu cluster AKS, você poderá usar o painel Método USE/Nó para obter insights sobre a E/S de disco para os nós de trabalho do cluster.

Monitorar o serviço gerenciado para Prometheus e o Espaço Gerenciado do Azure para Grafana
Você pode usar o painel predefinido Exportador de Nós/Nós para visualizar e analisar métricas relacionadas a E/S de disco dos nós de trabalho. Para fazer isso, você deve configurar seu cluster do AKS para coletar métricas do Prometheus em Monitorar o serviço gerenciado para Prometheus e conectar seu espaço de trabalho do Monitor a um espaço de trabalho do Espaço Gerenciado do Azure para Grafana.

IOPS e discos do Azure
Os dispositivos de armazenamento físico têm limitações inerentes em termos de largura de banda e do número máximo de operações de arquivo que podem manipular. Os discos do Azure são usados para armazenar o sistema operacional executado em nós AKS. Os discos estão sujeitos às mesmas restrições de armazenamento físico que o sistema operacional.
Considere o conceito de taxa de transferência. Você pode multiplicar o tamanho médio de E/S pelas IOPS para determinar a taxa de transferência em megabytes por segundo (MBps). Tamanhos de E/S maiores se convertem em IOPS mais baixas devido à taxa de transferência fixa do disco.
Quando uma carga de trabalho excede os limites máximos de serviço de IOPS atribuídos aos discos do Azure, o cluster pode deixar de responder e entrar em um estado de espera de E/S. Em sistemas baseados em Linux, muitos componentes são tratados como arquivos, como soquetes de rede, CNI, Docker e outros serviços que dependem de E/S de rede. Consequentemente, se o disco não puder ser lido, a falha se estenderá a todos esses arquivos.
Vários eventos e cenários podem disparar a limitação de IOPS, incluindo:
Um número substancial de contêineres executados em nós, porque a E/S do Docker compartilha o disco do sistema operacional.
Ferramentas personalizadas ou de terceiros empregadas para segurança, monitoramento e registro em log, que podem gerar operações de E/S adicionais no disco do sistema operacional.
Eventos de failover de nó e trabalhos periódicos que intensificam a carga de trabalho ou dimensionam o número de pods. Esse aumento da carga aumenta a probabilidade de ocorrências de limitação, potencialmente fazendo com que todos os nós façam a transição para um estado não pronto até que as operações de E/S sejam concluídas.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Principais autores:
- Paolo Salvatori | Engenheiro de Clientes Principal
- Francis Simy Nazareth | Especialista Técnico Sênior
Para ver perfis não públicos do LinkedIn, entre no LinkedIn.