Este artigo descreve como uma equipe de desenvolvimento usou métricas para encontrar gargalos e melhorar o desempenho de um sistema distribuído. O artigo é baseado no teste de carga real que foi feito para um aplicativo de exemplo. O aplicativo é originado da Linha de base do Serviço de Kubernetes do Azure (AKS) para microsserviços.
Este artigo faz parte de uma série. Leia a primeira parte aqui.
Cenário: um aplicativo cliente inicia uma transação comercial que envolve várias etapas.
Esse cenário envolve um aplicativo de entrega de drones que é executado no AKS. Os clientes usam um aplicativo Web para agendar entregas por drone. Cada transação requer várias etapas que são executadas por microsserviços separados no back-end:
- O serviço Entrega gerencia as entregas.
- O serviço Agendador de Drone agenda drones para retirada.
- O serviço Pacote gerencia pacotes.
Há dois outros serviços: um serviço de ingestão que aceita solicitações de clientes e as coloca em uma fila para processamento e um serviço de Fluxo de Trabalho que coordena as etapas no fluxo de trabalho.
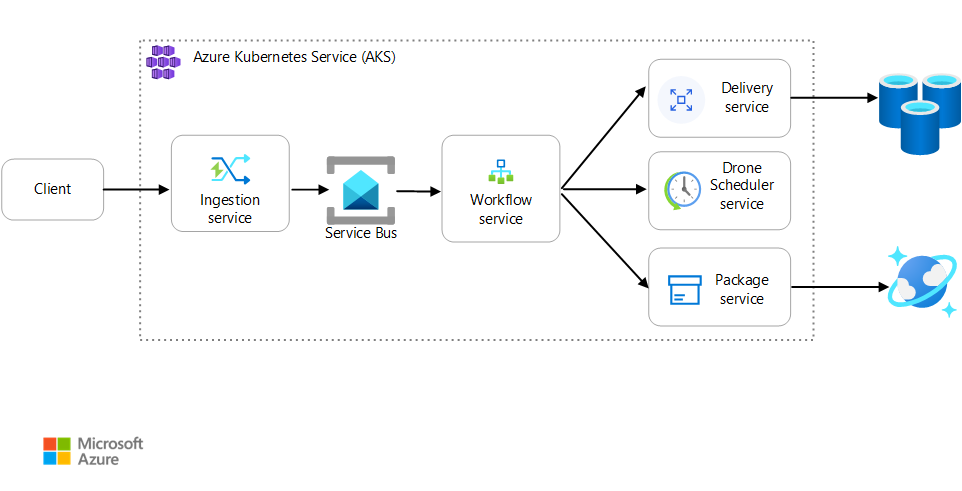
Para obter mais informações sobre esse cenário, consulte Projetar uma arquitetura de microsserviços.
Teste 1: Linha de base
Para o primeiro teste de carga, a equipe criou um cluster do AKS de seis nós e implantou três réplicas de cada microsserviço. O teste de carga foi um teste de carga em etapas, começando com dois usuários simulados e aumentando para 40.
| Configuração | Valor |
|---|---|
| Nós de cluster | 6 |
| Pods | 3 por serviço |
O gráfico a seguir mostra os resultados do teste de carga, conforme mostrado no Visual Studio. A linha roxa plota a carga do usuário, e a linha laranja, o total de solicitações.

A primeira coisa a perceber sobre esse cenário é que as solicitações de cliente por segundo não são uma métrica útil de desempenho. Isso ocorre porque o aplicativo processa as solicitações de forma assíncrona, para que o cliente obtenha uma resposta imediatamente. O código de resposta é sempre HTTP 202 (Aceito), o que significa que a solicitação foi aceita, mas o processamento não está concluído.
Na verdade, queremos saber se o back-end está acompanhando a taxa de solicitação. A fila do Barramento de Serviço pode absorver picos, mas se o back-end não conseguir lidar com uma carga sustentada, o processamento ficará cada vez mais aquém.
Aqui está um gráfico mais informativo. Ele plota o número de mensagens de entrada e saída na fila do Barramento de Serviço. As mensagens recebidas são mostradas em azul claro, e as de saída são mostradas em azul escuro:
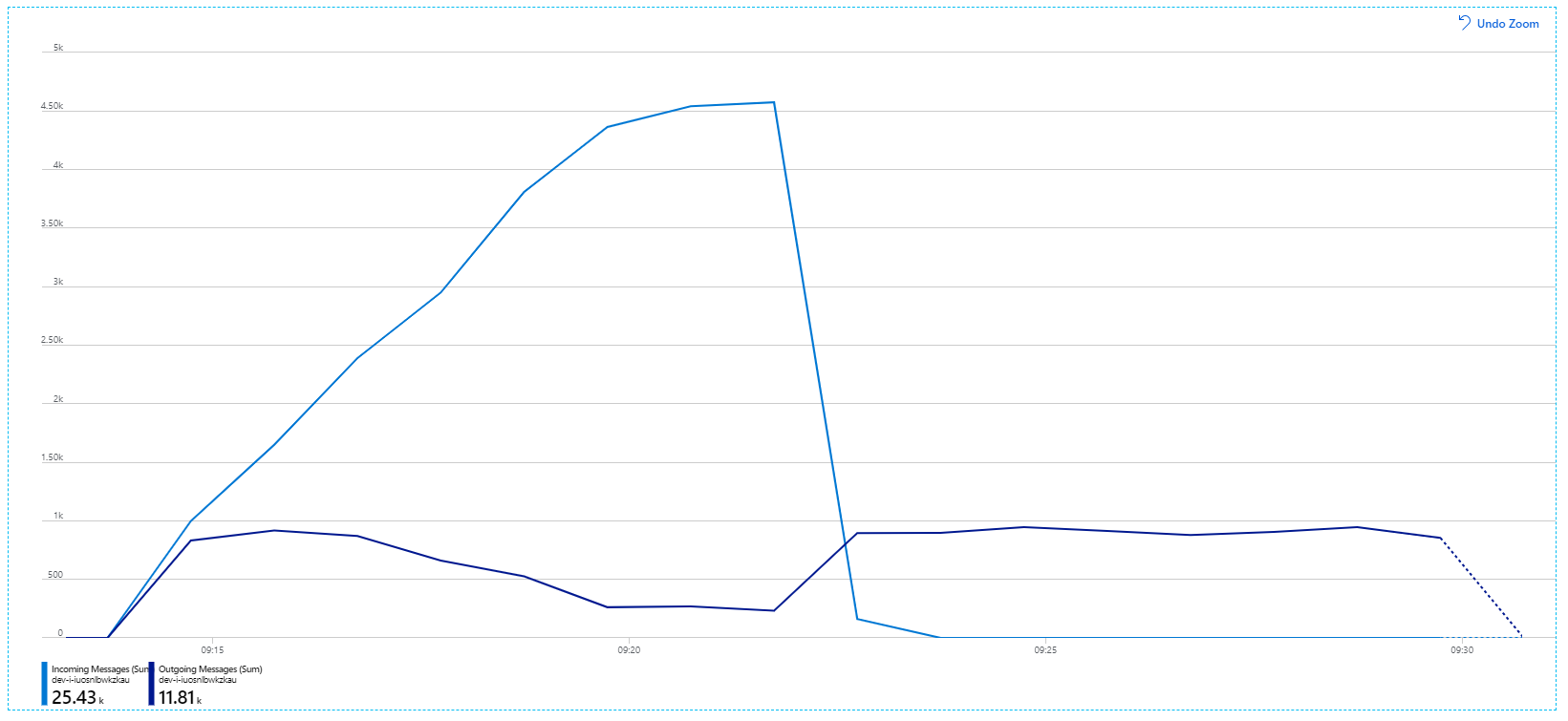
Esse gráfico mostra que a taxa de mensagens recebidas aumenta, atingindo um pico e, em seguida, caindo para zero no final do teste de carga. Mas o número de mensagens enviadas atinge o pico no início do teste e depois cai. Isso significa que o serviço de Fluxo de Trabalho, que lida com as solicitações, não está acompanhando. Mesmo após o término do teste de carga (por volta das 9h22 no gráfico), as mensagens ainda estão sendo processadas à medida que o serviço de Fluxo de Trabalho continua drenando fila.
O que está atrasando o processamento? Primeiro, procure ou exceções que possam indicar um problema sistemático. O Mapa de Aplicativo no Azure Monitor mostra o gráfico de chamadas entre componentes e é uma maneira rápida de identificar problemas e clicar para obter mais detalhes.
O Mapa do Aplicativo mostra que o serviço de Fluxo de Trabalho está recebendo erros do serviço de Entrega:

Para ver mais detalhes, você pode selecionar um nó no gráfico e clicar em uma exibição de transação de ponta a ponta. Nesse caso, ele mostra que o serviço de Entrega está retornando erros HTTP 500. As mensagens de erro indicam que uma exceção está sendo lançada devido a limites de memória no Cache do Azure para Redis.

Você pode notar que essas chamadas para Redis não aparecem no Mapa do Aplicativo. Isso ocorre porque a biblioteca .NET para Application Insights não tem suporte interno para controlar o Redis como uma dependência. (Para obter uma lista do que é suportado de forma imediata, consulte Coleta automática de dependência.) Como fallback, você pode usar a API TrackDependency para controlar qualquer dependência. O teste de carga geralmente revela esses tipos de lacunas na telemetria, que podem ser corrigidas.
Teste 2: Aumento do tamanho do cache
Para o segundo teste de carga, a equipe de desenvolvimento aumentou o tamanho do cache no Cache do Azure para Redis. (Veja Como dimensionar o Cache do Azure para Redis.) Essa alteração resolveu as exceções de falta de memória, e agora o Mapa do Aplicativo mostra zero erros:

No entanto, ainda há um atraso grande no processamento de mensagens. No pico do teste de carga, a taxa de mensagens de entrada é superior a 5× a taxa de saída:

O gráfico a seguir mede a taxa de transferência em termos de conclusão de mensagens, ou seja, a taxa na qual o serviço de Fluxo de Trabalho marca as mensagens do Barramento de Serviço como concluídas. Cada ponto no gráfico representa 5 segundos de dados, mostrando cerca de 16/seg de taxa de transferência máxima.

Este gráfico foi gerado executando uma consulta no workspace do Log Analytics usando a linguagem de consulta Kusto:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Teste 3: Expandir os serviços de back-end
Parece que o back-end é o gargalo. Uma próxima etapa fácil é escalar horizontalmente os serviços de negócios (Pacote, Entrega e Agendador de Drone) e ver se a taxa de transferência melhora. Para o próximo teste de carga, a equipe dimensionou esses serviços de três réplicas para seis réplicas.
| Configuração | Valor |
|---|---|
| Nós de cluster | 6 |
| Serviço de ingestão | 3 réplicas |
| Serviço de Fluxo de Trabalho | 3 réplicas |
| Serviços de Pacote, Entrega, Agendador de Drone | 6 réplicas cada |
Infelizmente, este teste de carga mostra apenas uma melhoria modesta. As mensagens de saída ainda não estão acompanhando as mensagens recebidas:

A taxa de transferência é mais consistente, mas o máximo alcançado é próximo ao do teste anterior:

Além disso, analisando os insights de contêiner do Azure Monitor, parece que o problema não é causado pelo esgotamento de recursos no cluster. Primeiro, as métricas no nível do nó mostram que a utilização da CPU permanece abaixo de 40%, mesmo no percentil 95, e a utilização da memória é de cerca de 20%.

Em um ambiente Kubernetes, é possível que pods individuais sejam limitados por recursos, mesmo quando os nós não são. Mas a exibição no nível do pod mostra que todos os pods estão íntegros.

A partir desse teste, parece que adicionar mais pods ao back-end não ajudará. A próxima etapa é examinar mais de perto o serviço de Fluxo de Trabalho para entender o que está acontecendo quando ele processa mensagens. O Application Insights mostra que a duração média da operação Process do serviço de Fluxo de Trabalho é de 246 ms.

Também podemos executar uma consulta para obter métricas sobre as operações individuais dentro de cada transação:
| destino | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| entrega contínua | 37 | 57 |
| package | 12 | 17 |
| dronescheduler | 21 | 41 |
A primeira linha desta tabela representa a fila do Barramento de Serviço. As outras linhas são as chamadas para os serviços de back-end. Para referência, aqui está a consulta do Log Analytics para esta tabela:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target

Essas latências parecem razoáveis. Mas aqui está o principal insight: se o tempo total de operação for de cerca de 250 ms, isso inclui um limite superior estrito na velocidade em que as mensagens podem ser processadas em série. A chave para melhorar a taxa de transferência, portanto, é um paralelismo maior.
Isso deve ser possível nesse cenário, por dois motivos:
- Essas são chamadas de rede, portanto, a maior parte do tempo é gasto aguardando a conclusão da E/S
- As mensagens são independentes e não precisam ser processadas em ordem.
Teste 4: Aumentar o paralelismo
Para esse teste, a equipe concentrou-se em aumentar o paralelismo. Para isso, eles ajustaram duas configurações no cliente do Barramento de Serviço usado pelo serviço de Fluxo de Trabalho:
| Configuração | Descrição | Padrão | Novo valor |
|---|---|---|---|
MaxConcurrentCalls |
O número máximo de mensagens a serem processadas simultaneamente. | 1 | 20 |
PrefetchCount |
Quantas mensagens o cliente buscará antecipadamente no cache local. | 0 | 3000 |
Para saber mais informações sobre essas configurações, consulte Práticas recomendadas para melhorias de desempenho usando o Sistema de Mensagens do Barramento de Serviço. A execução do teste com essas configurações produziu o seguinte gráfico:

Lembre-se de que as mensagens recebidas são mostradas em azul claro e as enviadas em azul escuro.
À primeira vista, esse é um gráfico muito estranho. Por um tempo, a taxa de mensagens de saída rastreia exatamente a taxa de entrada. Mas então, por volta da marca de 2:03, a taxa de mensagens recebidas se estabiliza, enquanto o número de mensagens de saída continua a aumentar, excedendo o número total de mensagens recebidas. Isso parece impossível.
A pista para esse mistério pode ser encontrada na visualização Dependências no Application Insights. Este gráfico resume todas as chamadas que o serviço de Fluxo de Trabalho fez para o Barramento de Serviço:

Observe a entrada para DeadLetter. Essas chamadas indicam que as mensagens estão indo para a fila de mensagens mortas do Barramento de Serviço.
Para entender o que está acontecendo, você precisa entender a semântica Peek-Lock no Barramento de Serviço. Quando um cliente usa o Peek-Lock, o Barramento de Serviço recupera e bloqueia atomicamente uma mensagem. Enquanto o bloqueio é mantido, a mensagem não é entregue a outros receptores. Se o bloqueio expirar, a mensagem ficará disponível para outros receptores. Após um número máximo de tentativas de entrega (que é configurável), o Barramento de Serviço colocará as mensagens em uma fila de mensagens mortas, onde poderá ser examinada posteriormente.
Lembre-se de que o serviço Fluxo de Trabalho está fazendo uma pré-busca de grandes lotes de mensagens — 3.000 mensagens por vez). Isso significa que o tempo total para processar cada mensagem é maior, resultando em mensagens que atingem o tempo limite, voltam para a fila e, eventualmente, vão para a fila de mensagens mortas.
Você também pode ver esse comportamento nas exceções, onde várias exceções MessageLostLockException são registradas:

Teste 5: Aumentar a duração do bloqueio
Para esse teste de carga, a duração do bloqueio de mensagens foi definida como 5 minutos para evitar tempos limite de bloqueio. O gráfico de mensagens recebidas e enviadas agora mostra que o sistema está acompanhando a taxa de mensagens recebidas:

Durante todo o teste de carga de 8 minutos, o aplicativo completou 25 mil operações, com uma taxa de transferência de pico de 72 operações/seg, representando um aumento de 400% na taxa de transferência máxima.

No entanto, a execução do mesmo teste com uma duração mais longa mostrou que o aplicativo não poderia sustentar essa taxa:

As métricas de contêiner mostram que a utilização máxima da CPU foi próxima de 100%. Neste ponto, o aplicativo parece estar vinculado à CPU. O dimensionamento do cluster pode melhorar o desempenho agora, ao contrário da tentativa anterior de expansão.

Teste 6: Dimensionar os serviços de back-end (novamente)
Para o teste de carga final da série, a equipe dimensionou o cluster e os pods do Kubernetes da seguinte maneira:
| Configuração | Valor |
|---|---|
| Nós de cluster | 12 |
| Serviço de ingestão | 3 réplicas |
| Serviço de Fluxo de Trabalho | 6 réplicas |
| Serviços de Pacote, Entrega, Agendador de Drone | 9 réplicas cada |
Esse teste resultou em uma taxa de transferência sustentada mais alta, sem atrasos significativos no processamento de mensagens. Além disso, a utilização da CPU do nó permaneceu abaixo de 80%.

Resumo
Para esse cenário, foram identificados os seguintes gargalos:
- Exceções de falta de memória no Cache do Azure para Redis.
- Falta de paralelismo no processamento de mensagens.
- Duração insuficiente do bloqueio de mensagens, levando a tempos limite de bloqueio e mensagens sendo colocadas na fila de mensagens mortas.
- Esgotamento de CPU.
Para diagnosticar esses problemas, a equipe de desenvolvimento baseou-se nas seguintes métricas:
- A taxa de mensagens do Barramento de Serviço de entrada e saída.
- Mapa de Aplicativos no Application Insights.
- Erros e exceções.
- Consultas personalizadas do Log Analytics.
- Utilização da CPU e da memória nos insights de contêiner do Azure Monitor.
Próximas etapas
Para obter mais informações sobre o design desse cenário, consulte Projetar uma arquitetura de microsserviços.