Ideias de solução
Esse artigo é uma ideia de solução. Caso deseje que ampliemos o conteúdo com mais informações, como possíveis casos de uso, serviços alternativos, considerações sobre implementação ou diretrizes de preços, fale conosco enviando seus comentários no GitHub.
Implemente uma solução de NLP (processamento de linguagem natural) no Azure. Use o Spark NLP para tarefas como detecção e análise de tópicos e sentimentos.
Apache®, Apache Spark e o logotipo da chama são marcas registradas ou marcas comerciais da Apache Software Foundation nos Estados Unidos e/ou em outros países. O uso desta marca não implica aprovação por parte da Apache Software Foundation.
Arquitetura

Baixe um Arquivo Visio dessa arquitetura.
Workflow
- Os Hubs de Eventos do Azure e/ou o Azure Data Factory recebem documentos ou dados de texto não estruturados.
- Os Hubs de Eventos e o Data Factory armazenam os dados no formato de arquivo no Azure Data Lake Storage. Recomendamos que você configure uma estrutura de diretório que esteja em conformidade com os requisitos de negócios.
- A API da Pesquisa Visual Computacional do Azure usa a funcionalidade de OCR (reconhecimento óptico de caracteres) para consumir os dados. Em seguida, a API grava os dados na camada bronze. Essa plataforma de consumo usa uma arquitetura de lakehouse.
- Na camada bronze, vários recursos do Spark NLP processam previamente o texto. Entre os exemplos estão a divisão, a correção de ortografia, a limpeza e a compreensão da gramática. Recomendamos executar a classificação de documentos na camada bronze e, em seguida, gravar os resultados na camada prata.
- Na camada prata, os recursos avançados do Spark NLP executam tarefas de análise de documento, como reconhecimento de entidade nomeada, sumarização e recuperação de informações. Em algumas arquiteturas, o resultado é gravado na camada ouro.
- Na camada ouro, o Spark NLP executa várias análises visuais linguísticas nos dados de texto. Essas análises fornecem insights sobre as dependências de linguagem e ajudam na visualização de rótulos do NER.
- Os usuários consultam os dados de texto da camada ouro como um quadro de dados e visualizam os resultados no Power BI ou em aplicativos Web.
Durante as etapas de processamento, o Azure Databricks, o Azure Synapse Analytics e o Azure HDInsight são usados com o Spark NLP para fornecer a funcionalidade de NLP.
Componentes
- O Data Lake Storage é um sistema de arquivos compatível com Hadoop que conta com um namespace hierárquico integrado e a ampla escala e economia do Armazenamento de Blobs do Azure.
- O Azure Synapse Analytics é um serviço de análise para data warehouses e sistemas de big data.
- O Azure Databricks é um serviço de análise para Big Data que é fácil de usar, facilita a colaboração e é baseado no Apache Spark. Ele foi projetado para a ciência de dados e a engenharia de dados.
- Os Hubs de Eventos ingerem fluxos de dados gerados pelos aplicativos cliente. Os Hubs de Eventos armazenam os dados de streaming e preservam a sequência de eventos recebidos. Os consumidores podem se conectar aos pontos de extremidade do hub para recuperar mensagens para processamento. Os Hubs de Eventos são integrados ao Data Lake Storage, como mostra esta solução.
- O Azure HDInsight é um serviço de análise totalmente gerenciado, completo e open-source na nuvem para empresas. Você pode usar estruturas de código aberto com o Azure HDInsight, como o Hadoop, o Apache Spark, o Apache Hive, o LLAP, o Apache Kafka, o Apache Storm e o R.
- O Data Factory move os dados automaticamente entre as contas de armazenamento de diferentes níveis de segurança para garantir a diferenciação de direitos.
- A Pesquisa Visual Computacional usa as APIs de reconhecimento de texto para reconhecer um texto em imagens e extrair essas informações. A API de Leitura usa os modelos de reconhecimento mais recentes e é otimizada para documentos grandes e que contêm muito texto e para imagens com ruído. A API de OCR não é otimizada para documentos grandes, mas dá suporte a mais idiomas do que a API de Leitura. Essa solução usa o OCR para produzir dados no formato hOCR.
Detalhes do cenário
O NLP (processamento de linguagem natural) tem muitos usos: análise de sentimento, detecção de tópicos, detecção de idioma, extração de frases-chave e categorização de documentos.
O Apache Spark é uma estrutura de processamento paralelo que dá suporte ao processamento em memória para aprimorar o desempenho de aplicativos analíticos de Big Data, como o NLP. O Azure Synapse Analytics, o Azure HDInsight e o Azure Databricks oferecem acesso ao Spark e aproveitam o poder de processamento dele.
Para cargas de trabalho de NLP personalizadas, a biblioteca de código aberto Spark NLP serve como uma estrutura eficiente para processar grandes volumes de texto. Este artigo apresenta uma solução para o NLP personalizado em grande escala no Azure. A solução usa recursos do Spark NLP para processar e analisar textos. Para obter mais informações sobre o Spark NLP, confira Funcionalidades e pipelines do Spark NLP, mais adiante neste artigo.
Possíveis casos de uso
Classificação de documentos: o Spark NLP oferece várias opções para classificação de texto:
- Pré-processamento de texto no Spark NLP e algoritmos de machine learning baseados no Spark ML
- Pré-processamento de texto e inserção de palavras no Spark NLP e algoritmos de machine learning, como o GloVe, o BERT e o ELMo
- Pré-processamento de texto e inserção de frases no Spark NLP e algoritmos e modelos de machine learning, como o Universal Sentence Encoder
- Pré-processamento e classificação de texto no Spark NLP que usa o anotador ClassifierDL e se baseia no TensorFlow
NER (Reconhecimento de Entidade Nomeada): no Spark NLP, com algumas linhas de código, você pode treinar um modelo NER que usa o BERT e obter precisão de última geração. O NER é uma subtarefa da extração de informações. Ele localiza as entidades nomeadas em um texto não estruturado e as classifica em categorias predefinidas, como nomes de pessoas, organizações, locais, códigos médicos, expressões temporais, quantidades, valores monetários e percentuais. O Spark NLP usa um modelo NER de última geração com o BERT. O modelo foi inspirado em um antigo modelo NER, o LSTM-CNN bidirecional. Esse modelo anterior usa uma arquitetura recente de rede neural que detecta automaticamente os recursos de nível de palavra e de caractere. Para essa finalidade, o modelo usa uma arquitetura de LSTM e de CNN bidirecional híbrida, ou seja, elimina a necessidade de grande parte da engenharia de recursos.
Detecção de sentimentos e emoções: o Spark NLP pode detectar automaticamente aspectos positivos, negativos e neutros da linguagem.
POS (Classe gramatical): essa funcionalidade atribui um rótulo gramatical a cada token do texto de entrada.
SD (Detecção de sentença): a SD baseia-se em um modelo de rede neural de uso geral para a detecção de limite de sentença que identifica as sentenças no texto. Muitas tarefas de NLP usam uma sentença como unidade de entrada. Entre os exemplos dessas tarefas estão a marcação de POS, a análise de dependência, o reconhecimento de entidade nomeada e a tradução automática.
Funcionalidades e pipelines do Spark NLP
O Spark NLP fornece bibliotecas Python, Java e Scala que oferecem toda a funcionalidade das bibliotecas tradicionais de NLP, como o spaCy, o NLTK, o Stanford CoreNLP e o Open NLP. O Spark NLP também oferece funcionalidades como verificação ortográfica, análise de sentimento e classificação de documentos. Ele aprimora os esforços anteriores fornecendo velocidade, escalabilidade e precisão de última geração.
O Spark NLP é de longe a biblioteca de NLP de código aberto mais rápida. Parâmetros de comparação públicos recentes mostram o Spark NLP como 38 e 80 vezes mais rápido que o spaCy, com precisão comparável para treinamento de modelos personalizados. O Spark NLP é a única biblioteca de código aberto que pode usar um cluster Spark distribuído. O Spark NLP é uma extensão nativa do Spark ML que opera diretamente em quadros de dados. Como resultado, as acelerações em um cluster resultam em outra ordem de magnitude do ganho de desempenho. Como cada pipeline do Spark NLP é um pipeline do Spark ML, o Spark NLP é adequado para a criação de pipelines unificados de NLP e machine learning, como classificação de documentos, previsão de riscos e pipelines de recomendação.
Além do excelente desempenho, o Spark NLP também oferece precisão de última geração para um número cada vez maior de tarefas de NLP. A equipe do Spark NLP lê regularmente os últimos artigos acadêmicos relevantes e produz os modelos mais precisos.
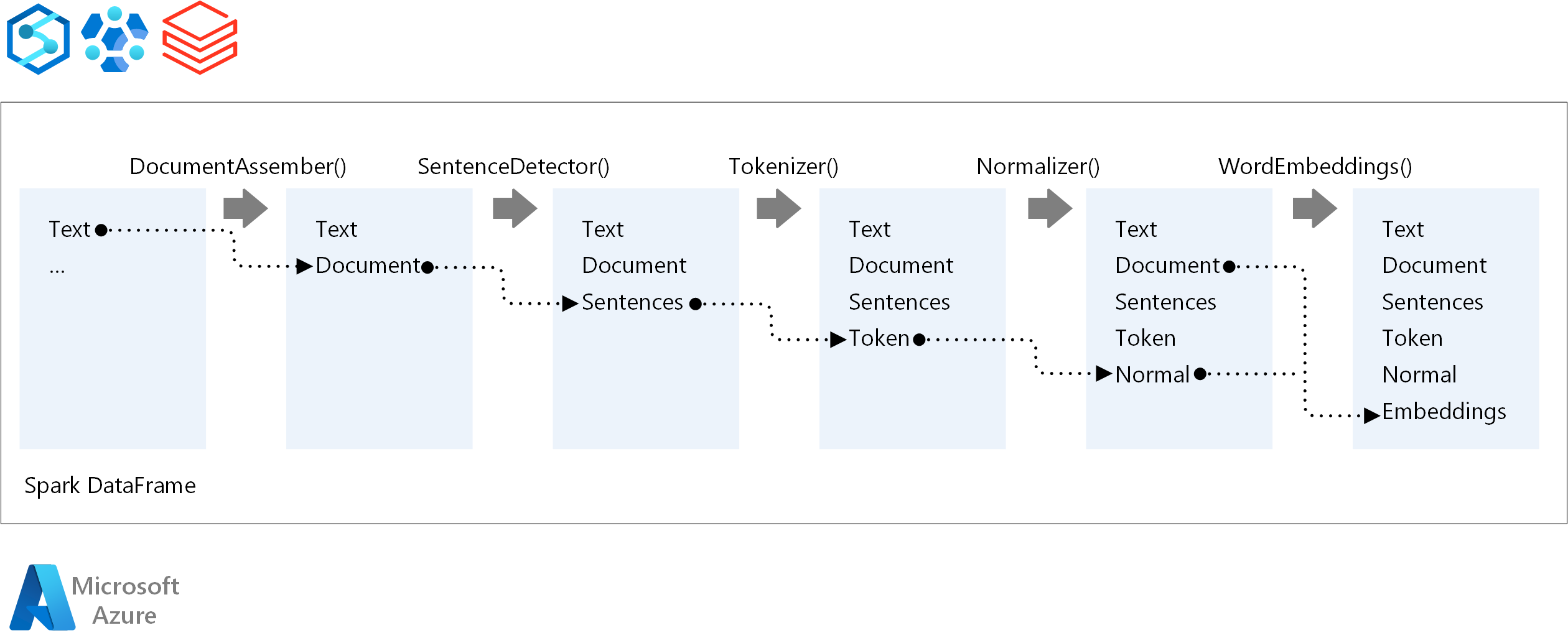
Para a ordem de execução de um pipeline de NLP, o Spark NLP segue o mesmo conceito de desenvolvimento dos modelos tradicionais de machine learning do Spark ML. No entanto, o Spark NLP aplica as técnicas de NLP. O diagrama a seguir mostra os principais componentes de um pipeline do Spark NLP.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Autor principal:
- Moritz Steller | Arquiteto sênior de soluções de nuvem
Próximas etapas
Documentação do Spark NLP:
Componentes do Azure:
Recursos relacionados
- Escolher uma tecnologia de processamento de linguagem natural
- Enriquecimento de IA com processamento de imagem e linguagem natural no Azure Cognitive Search
- Analisar news feeds com a análise quase em tempo real usando o processamento de imagem e linguagem natural
- Sugerir marcas de conteúdo com o NLP usando o aprendizado profundo