Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure![]() Banco de Dados SQL no Fabric
Banco de Dados SQL no Fabric
Você pode consultar DMVs (exibições de gerenciamento dinâmico) por meio do T-SQL para monitorar o desempenho da carga de trabalho e diagnosticar problemas de desempenho, que podem ser causados por consultas bloqueadas ou de execução longa, gargalos de recursos, planos de consulta suboptimais e muito mais.
Para monitorar recursos de consulta gráfica, use o Query Store.
Dica
Considere ajuste automático de banco de dados para melhorar automaticamente o desempenho da consulta.
Monitorar o uso de recursos
Você pode monitorar o uso de recursos no nível do banco de dados usando as DMVs a seguir.
sys.dm_db_resource_stats
Como essa exibição fornece dados granulares de uso do recurso, utilize sys.dm_db_resource_stats primeiro para qualquer análise do estado atual ou solução de problemas. Por exemplo, esta consulta mostra o uso médio e máximo dos recursos do banco de dados atual durante a última hora:
SELECT
database_name = DB_NAME(),
AVG(avg_cpu_percent) AS 'Average CPU use in percent',
MAX(avg_cpu_percent) AS 'Maximum CPU use in percent',
AVG(avg_data_io_percent) AS 'Average data IO in percent',
MAX(avg_data_io_percent) AS 'Maximum data IO in percent',
AVG(avg_log_write_percent) AS 'Average log write use in percent',
MAX(avg_log_write_percent) AS 'Maximum log write use in percent',
AVG(avg_memory_usage_percent) AS 'Average memory use in percent',
MAX(avg_memory_usage_percent) AS 'Maximum memory use in percent',
MAX(max_worker_percent) AS 'Maximum worker use in percent'
FROM sys.dm_db_resource_stats
A exibição sys.dm_db_resource_stats mostra dados de uso de recursos recentes relativos aos limites do tamanho da computação. As porcentagens de CPU, E/S de dados, gravações de logs, threads de trabalho e uso de memória em relação ao limite são registradas a cada intervalo de 15 segundos e mantidas por aproximadamente uma hora.
Para outras consultas de exemplo, consulte os exemplos em sys.dm_db_resource_stats.
sys. resource_stats
A exibição sys.resource_stats no banco de dados master traz mais informações que podem ajudar você a monitorar o desempenho do banco de dados na camada de serviço e no tamanho da computação específicos. Os dados são coletados a cada 5 minutos e são mantidos por aproximadamente 14 dias. Essa exibição é útil para uma análise de histórico de longo prazo de como seu banco de dados usa recursos.
O grafo a seguir mostra o uso de recursos da CPU para um banco de dados Premium com o tamanho da computação P2 para cada hora em uma semana. Esse gráfico começa em uma segunda-feira, mostra cinco dias úteis e, depois, um fim de semana, quando ocorrem muito menos atividades no aplicativo.
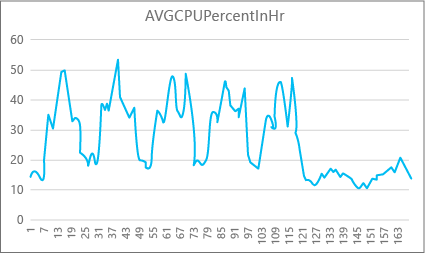
Segundo os dados, atualmente esse banco de dados tem um pico de carga de CPU de pouco mais de 50% de uso da CPU em relação ao tamanho da computação P2 (meio-dia de terça-feira). Se a CPU for o fator dominante no perfil de recursos do aplicativo, talvez você decida que P2 é o tamanho da computação certo para garantir que a carga de trabalho sempre seja adequada. Se você espera que um aplicativo cresça com o passar do tempo, é uma boa ideia ter um buffer de recursos adicional para que o aplicativo nunca atinja o limite do nível de desempenho. Aumentando o tamanho da computação, você pode ajudar a evitar erros visíveis para os clientes, que podem ocorrer quando um banco de dados não tem capacidade suficiente para processar solicitações de modo eficaz, especialmente em ambientes sensíveis à latência.
Em outros tipos de aplicativos, você pode interpretar o mesmo gráfico de forma diferente. Por exemplo, se um aplicativo tentar processar dados de folha de pagamento por dia e incluir o mesmo gráfico, esse tipo de modelo de "trabalho em lotes" poderá funcionar bem em um tamanho da computação P1. O tamanho da computação P1 tem 100 DTUs, comparadas a 200 DTUs do tamanho da computação P2. O tamanho da computação P1 fornece que metade do desempenho do P2. Portanto, 50% de uso da CPU em P2 equivale a 100% de uso da CPU em P1. Se o aplicativo não tiver tempo limite, talvez não faça diferença se um trabalho demora 2 horas ou 2,5 horas para ser concluído, desde que seja concluído hoje. Um aplicativo dessa categoria provavelmente pode usar um tamanho da computação P1. Você pode tirar proveito do fato de que há períodos do dia em que o uso de recursos é menor, o que significa que um "pico grande" pode ser extrapolado para um dos ciclos mais tarde. O tamanho da computação P1 pode ser bom para esse tipo de aplicativo (e economiza dinheiro), desde que os trabalhos possam ser concluídos no horário todos os dias.
O mecanismo de banco de dados expõe informações do recurso consumido para cada banco de dados ativo na exibição sys.resource_stats do banco de dados master em cada servidor lógico. Os dados na exibição são agregados em intervalos de cinco minutos. Pode levar vários minutos para que esses dados apareçam na tabela, por isso sys.resource_stats é mais útil para análise histórica do que para análise quase em tempo real. Consulte a exibição sys.resource_stats para ver o histórico recente de um banco de dados e validar se o tamanho da computação escolhido ofereceu o desempenho desejado quando necessário.
Observação
É necessário estar conectado ao banco de dados master para consultar sys.resource_stats nos exemplos a seguir.
Este exemplo mostra os dados em sys.resource_stats:
SELECT TOP 10 *
FROM sys.resource_stats
WHERE database_name = 'userdb1'
ORDER BY start_time DESC;
O exemplo seguinte mostra diferentes maneiras de usar o modo de exibição de catálogo sys.resource_stats para obter informações sobre como o banco de dados usa recursos:
Para conferir o uso de recursos da última semana relacionado ao banco de dados do usuário
userdb1, é possível executar esta consulta, fazendo a substituição pelo nome do seu próprio banco de dados:SELECT * FROM sys.resource_stats WHERE database_name = 'userdb1' AND start_time > DATEADD(day, -7, GETDATE()) ORDER BY start_time DESC;Para avaliar como a carga de trabalho se ajusta ao tamanho da computação, você precisa fazer drill down de cada aspecto das métricas de recursos: CPU, dados, E/S, gravação de logs, número de trabalhadores e número de sessões. Veja a seguinte consulta revisada que usa
sys.resource_statsa fim de relatar os valores médio e máximo dessas métricas de recursos, em cada tamanho da computação para o qual o banco de dados foi provisionado:SELECT rs.database_name , rs.sku , storage_mb = MAX(rs.storage_in_megabytes) , 'Average CPU Utilization In %' = AVG(rs.avg_cpu_percent) , 'Maximum CPU Utilization In %' = MAX(rs.avg_cpu_percent) , 'Average Data IO In %' = AVG(rs.avg_data_io_percent) , 'Maximum Data IO In %' = MAX(rs.avg_data_io_percent) , 'Average Log Write Utilization In %' = AVG(rs.avg_log_write_percent) , 'Maximum Log Write Utilization In %' = MAX(rs.avg_log_write_percent) , 'Maximum Requests In %' = MAX(rs.max_worker_percent) , 'Maximum Sessions In %' = MAX(rs.max_session_percent) FROM sys.resource_stats AS rs WHERE rs.database_name = 'userdb1' AND rs.start_time > DATEADD(day, -7, GETDATE()) GROUP BY rs.database_name, rs.sku;Com essas informações sobre os valores médio e máximo de cada métrica de recurso, você pode avaliar como sua carga de trabalho se ajusta ao tamanho da computação escolhido. Normalmente, os valores médios de
sys.resource_statsoferecem uma boa linha de base a ser usada em comparação ao tamanho de destino.Para bancos de dados de modelo de compra de DTU:
Por exemplo, você pode estar usando a camada de serviço Standard com o tamanho da computação S2. Os percentuais médios de uso da CPU e leituras e gravações de E/S estão abaixo de 40%, o número médio de trabalhadores está abaixo de 50 e o número médio de sessões é inferior a 200. Talvez a carga de trabalho se enquadre no tamanho da computação S1. É fácil ver se o banco de dados se encaixa nos limites de sessão e de trabalho. Para ver se um banco de dados se encaixa em um tamanho de computação menor, divida o número de DTUs do tamanho de computação menor pelo número de DTUs do tamanho de computação atual e, em seguida, multiplique o resultado por 100:
S1 DTU / S2 DTU * 100 = 20 / 50 * 100 = 40O resultado é a diferença de desempenho relativa entre os dois tamanhos da computação em percentual. Se o uso de recursos não ultrapassar essa porcentagem, a carga de trabalho poderá se ajustar ao tamanho da computação inferior. No entanto, você precisa examinar todos os intervalos de valores de uso de recursos e determinar, pelo percentual, com que frequência a carga de trabalho do banco de dados se enquadraria no tamanho da computação inferior. A consulta a seguir produz o percentual de ajuste por dimensão de recurso, com base no limite de 40% que calculamos neste exemplo:
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 40 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Com base na camada de serviço do banco de dados, você pode decidir se sua carga de trabalho se enquadra no tamanho da computação inferior. Se a meta de carga de trabalho do banco de dados é de 99,9% e a consulta anterior retorna valores superiores a 99,9% para as três dimensões de recursos, é provável que sua carga de trabalho se enquadre no tamanho da computação inferior.
A avaliação do percentual de ajuste também traz informações que indicam se você deve ir ao próximo tamanho da computação para chegar à sua meta. Por exemplo, o uso da CPU de um banco de dados de exemplo na última semana:
Percentual médio da CPU Percentual máximo da CPU 24,5 100,00 A média da CPU é de aproximadamente um quarto do limite do tamanho da computação, o que se ajustaria bem ao tamanho da computação do banco de dados.
Para os bancos de dados do modelo de compra de DTU e do modelo de compra de vCore:
O valor máximo mostra que o banco de dados atinge o limite do tamanho da computação. Você precisa ir para o próximo tamanho da computação? Avalie quantas vezes sua carga de trabalho atinge 100% e compará-la à meta de carga de trabalho de seu banco de dados.
SELECT database_name, 100*((COUNT(database_name) - SUM(CASE WHEN avg_cpu_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'CPU Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_log_write_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Log Write Fit Percent', 100*((COUNT(database_name) - SUM(CASE WHEN avg_data_io_percent >= 100 THEN 1 ELSE 0 END) * 1.0) / COUNT(database_name)) AS 'Physical Data IO Fit Percent' FROM sys.resource_stats WHERE start_time > DATEADD(day, -7, GETDATE()) AND database_name = 'sample' --remove to see all databases GROUP BY database_name;Essas porcentagens consistem no número de amostras que a carga de trabalho ajusta abaixo do tamanho de computação atual. Quando a consulta retorna um valor inferior a 99,9% para qualquer uma das três dimensões de recurso, a carga de trabalho média amostrada excedeu os limites. Considere migrar para o próximo tamanho de computação superior ou usar técnicas de ajuste de aplicativo a fim de reduzir a carga no banco de dados.
sys.dm_elastic_pool_resource_stats
Aplica-se a: somente ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Como ocorre com o sys.dm_db_resource_stats, os sys.dm_elastic_pool_resource_stats fornecem dados de uso de recursos recentes e granulares para um pool elástico do Banco de Dados SQL do Azure. A exibição pode ser consultada em qualquer banco de dados em um pool elástico para fornecer dados de uso do recurso de um pool inteiro, em vez de qualquer banco de dados específico. Os valores percentuais informados por essa DMV estão próximos aos limites do pool elástico, que podem ser maiores do que os limites de um banco de dados no pool.
Este exemplo mostra os dados resumidos de uso do recurso do pool elástico atual nos últimos 15 minutos:
SELECT dso.elastic_pool_name,
AVG(eprs.avg_cpu_percent) AS avg_cpu_percent,
MAX(eprs.avg_cpu_percent) AS max_cpu_percent,
AVG(eprs.avg_data_io_percent) AS avg_data_io_percent,
MAX(eprs.avg_data_io_percent) AS max_data_io_percent,
AVG(eprs.avg_log_write_percent) AS avg_log_write_percent,
MAX(eprs.avg_log_write_percent) AS max_log_write_percent,
MAX(eprs.max_worker_percent) AS max_worker_percent,
MAX(eprs.used_storage_percent) AS max_used_storage_percent,
MAX(eprs.allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.dm_elastic_pool_resource_stats AS eprs
CROSS JOIN sys.database_service_objectives AS dso
WHERE eprs.end_time >= DATEADD(minute, -15, GETUTCDATE())
GROUP BY dso.elastic_pool_name;
Se descobrir que qualquer uso do recurso se aproxima de 100% durante um período significativo, talvez seja necessário revisar o uso do recurso em bancos de dados individuais no mesmo pool elástico para determinar o quanto cada banco de dados contribui para o uso do recurso no nível do pool.
sys.elastic_pool_resource_stats
Aplica-se a: somente ![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
Da mesma forma que sys.resource_stats, o sys.elastic_pool_resource_stats no banco de dados master fornece dados históricos de uso do recurso de todos os pools elásticos no servidor lógico. Você pode usar sys.elastic_pool_resource_stats para o monitoramento histórico dos últimos 14 dias, incluindo análise de tendência de uso.
Este exemplo mostra os dados resumidos de uso do recurso nos últimos sete dias de todos os pools elásticos no servidor lógico atual. Execute a consulta no banco de dados master.
SELECT elastic_pool_name,
AVG(avg_cpu_percent) AS avg_cpu_percent,
MAX(avg_cpu_percent) AS max_cpu_percent,
AVG(avg_data_io_percent) AS avg_data_io_percent,
MAX(avg_data_io_percent) AS max_data_io_percent,
AVG(avg_log_write_percent) AS avg_log_write_percent,
MAX(avg_log_write_percent) AS max_log_write_percent,
MAX(max_worker_percent) AS max_worker_percent,
AVG(avg_storage_percent) AS avg_used_storage_percent,
MAX(avg_storage_percent) AS max_used_storage_percent,
AVG(avg_allocated_storage_percent) AS avg_allocated_storage_percent,
MAX(avg_allocated_storage_percent) AS max_allocated_storage_percent
FROM sys.elastic_pool_resource_stats
WHERE start_time >= DATEADD(day, -7, GETUTCDATE())
GROUP BY elastic_pool_name
ORDER BY elastic_pool_name ASC;
Solicitações simultâneas
Para ver o número atual de solicitações simultâneas, execute esta consulta no banco de dados de usuário:
SELECT COUNT(*) AS [Concurrent_Requests]
FROM sys.dm_exec_requests;
Isso é apenas um instantâneo em um único ponto no tempo. Para entender melhor sua carga de trabalho e seus requisitos de solicitações simultâneas, você precisará coletar muitas amostras durante algum tempo.
Taxa média de solicitações
Este exemplo mostra como localizar a taxa média de solicitação de um banco de dados ou de bancos de dados em um pool elástico durante um período. Neste exemplo, o período é definido como 30 segundos. Você pode ajustá-lo modificando a instrução WAITFOR DELAY. Execute essa consulta no banco de dados de usuário. Se o banco de dados estiver em um pool elástico e você tiver permissões suficientes, os resultados incluirão outros bancos de dados no pool elástico.
DECLARE @DbRequestSnapshot TABLE (
database_name sysname PRIMARY KEY,
total_request_count bigint NOT NULL,
snapshot_time datetime2 NOT NULL DEFAULT (SYSDATETIME())
);
INSERT INTO @DbRequestSnapshot
(
database_name,
total_request_count
)
SELECT rg.database_name,
wg.total_request_count
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id);
WAITFOR DELAY '00:00:30';
SELECT rg.database_name,
(wg.total_request_count - drs.total_request_count) / DATEDIFF(second, drs.snapshot_time, SYSDATETIME()) AS requests_per_second
FROM sys.dm_resource_governor_workload_groups AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
INNER JOIN @DbRequestSnapshot AS drs
ON rg.database_name = drs.database_name;
Sessões atuais
Para ver o número de sessões ativas atuais, execute esta consulta no banco de dados:
SELECT COUNT(*) AS [Sessions]
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;
Essa consulta retorna uma contagem pontual. Se você coletar várias amostras ao longo do tempo, compreenderá melhor o uso da sua sessão.
Histórico recente de solicitações, sessões e trabalhadores
Este exemplo retorna o uso histórico recente de solicitações, sessões e threads de trabalho de um banco de dados ou de bancos de dados em um pool elástico. Cada linha representa um instantâneo do uso do recurso em um ponto no tempo de um banco de dados. A coluna requests_per_second é a taxa média de solicitação durante o intervalo de tempo que termina em snapshot_time. Se o banco de dados estiver em um pool elástico e você tiver permissões suficientes, os resultados incluirão outros bancos de dados no pool elástico.
SELECT rg.database_name,
wg.snapshot_time,
wg.active_request_count,
wg.active_worker_count,
wg.active_session_count,
CAST(wg.delta_request_count AS decimal) / duration_ms * 1000 AS requests_per_second
FROM sys.dm_resource_governor_workload_groups_history_ex AS wg
INNER JOIN sys.dm_user_db_resource_governance AS rg
ON wg.name = CONCAT('UserPrimaryGroup.DBId', rg.database_id)
ORDER BY snapshot_time DESC;
Calcular tamanhos de banco de dados e objetos
A seguinte consulta retorna o tamanho dos dados no banco de dados (em megabytes):
-- Calculates the size of the database.
SELECT SUM(CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8192.) / 1024 / 1024 AS size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
A consulta a seguir retorna o tamanho do dos objetos individuais (em megabytes) no seu banco de dados:
-- Calculates the size of individual database objects.
SELECT o.name, SUM(ps.reserved_page_count) * 8.0 / 1024 AS size_mb
FROM sys.dm_db_partition_stats AS ps
INNER JOIN sys.objects AS o
ON ps.object_id = o.object_id
GROUP BY o.name
ORDER BY size_mb DESC;
Identificar problemas de desempenho da CPU
Esta seção ajuda a identificar consultas individuais que são as principais consumidoras de CPU.
Se o consumo da CPU permanecer acima de 80% por longos períodos de tempo, considere as etapas de solução de problemas a seguir, caso o problema da CPU esteja ocorrendo agora ou tenha ocorrido no passado. Você também pode seguir as etapas nesta seção para identificar proativamente as principais consultas que consomem CPU e ajustá-las. Em alguns casos, reduzir o consumo de CPU pode permitir reduzir verticalmente os bancos de dados e pools elásticos, além de economizar custos.
As etapas de solução de problemas são as mesmas para bancos de dados autônomos e bancos de dados em um pool elástico. Execute todas as consultas no banco de dados de usuário.
O problema de CPU está ocorrendo agora
Se o problema está ocorrendo no momento, há dois cenários possíveis:
Muitas consultas individuais que consomem cumulativamente alta utilização da CPU
Use a consulta a seguir para identificar as principais consultas por hash de consulta:
PRINT '-- top 10 Active CPU Consuming Queries (aggregated)--';
SELECT TOP 10 GETDATE() runtime, *
FROM (SELECT query_stats.query_hash, SUM(query_stats.cpu_time) 'Total_Request_Cpu_Time_Ms', SUM(logical_reads) 'Total_Request_Logical_Reads', MIN(start_time) 'Earliest_Request_start_Time', COUNT(*) 'Number_Of_Requests', SUBSTRING(REPLACE(REPLACE(MIN(query_stats.statement_text), CHAR(10), ' '), CHAR(13), ' '), 1, 256) AS "Statement_Text"
FROM (SELECT req.*, SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST ) AS query_stats
GROUP BY query_hash) AS t
ORDER BY Total_Request_Cpu_Time_Ms DESC;
Consultas de longa execução que consomem CPU ainda estão em execução
Use a consulta a seguir para identificar os hashes de consulta:
PRINT '--top 10 Active CPU Consuming Queries by sessions--';
SELECT TOP 10 req.session_id, req.start_time, cpu_time 'cpu_time_ms', OBJECT_NAME(ST.objectid, ST.dbid) 'ObjectName', SUBSTRING(REPLACE(REPLACE(SUBSTRING(ST.text, (req.statement_start_offset / 2)+1, ((CASE statement_end_offset WHEN -1 THEN DATALENGTH(ST.text)ELSE req.statement_end_offset END-req.statement_start_offset)/ 2)+1), CHAR(10), ' '), CHAR(13), ' '), 1, 512) AS statement_text
FROM sys.dm_exec_requests AS req
CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) AS ST
ORDER BY cpu_time DESC;
GO
O problema da CPU ocorreu no passado
Se o problema ocorreu no passado e você deseja analisar a causa raiz, use oRepositório de Consultas. Os usuários com acesso de banco de dados podem usar o T-SQL para consultar os dados dos Repositório de Consultas. Por padrão, o Repositório de Consultas captura estatísticas de consulta de agregação para intervalos de uma hora.
Use a consulta a seguir para examinar a atividade para consultas de consumo de CPU alta. Essa consulta retorna as consultas de consumo de CPU 15 principais. Lembre-se de alterar
rsi.start_time >= DATEADD(hour, -2, GETUTCDATE()para ver um período diferente das últimas duas horas:-- Top 15 CPU consuming queries by query hash -- Note that a query hash can have many query ids if not parameterized or not parameterized properly WITH AggregatedCPU AS ( SELECT q.query_hash ,SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms ,SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms ,MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms ,MAX(max_logical_io_reads) max_logical_reads ,COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans ,COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids ,SUM(CASE WHEN rs.execution_type_desc = 'Aborted' THEN count_executions ELSE 0 END) AS Aborted_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Regular' THEN count_executions ELSE 0 END) AS Regular_Execution_Count ,SUM(CASE WHEN rs.execution_type_desc = 'Exception' THEN count_executions ELSE 0 END) AS Exception_Execution_Count ,SUM(count_executions) AS total_executions ,MIN(qt.query_sql_text) AS sampled_query_text FROM sys.query_store_query_text AS qt INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id WHERE rs.execution_type_desc IN ('Regular','Aborted','Exception') AND rsi.start_time >= DATEADD(HOUR, - 2, GETUTCDATE()) GROUP BY q.query_hash ) ,OrderedCPU AS ( SELECT query_hash ,total_cpu_ms ,avg_cpu_ms ,max_cpu_ms ,max_logical_reads ,number_of_distinct_plans ,number_of_distinct_query_ids ,total_executions ,Aborted_Execution_Count ,Regular_Execution_Count ,Exception_Execution_Count ,sampled_query_text ,ROW_NUMBER() OVER ( ORDER BY total_cpu_ms DESC ,query_hash ASC ) AS query_hash_row_number FROM AggregatedCPU ) SELECT OD.query_hash ,OD.total_cpu_ms ,OD.avg_cpu_ms ,OD.max_cpu_ms ,OD.max_logical_reads ,OD.number_of_distinct_plans ,OD.number_of_distinct_query_ids ,OD.total_executions ,OD.Aborted_Execution_Count ,OD.Regular_Execution_Count ,OD.Exception_Execution_Count ,OD.sampled_query_text ,OD.query_hash_row_number FROM OrderedCPU AS OD WHERE OD.query_hash_row_number <= 15 --get top 15 rows by total_cpu_ms ORDER BY total_cpu_ms DESC;Depois de identificar as consultas com problemas, é hora de ajustar as consultas para reduzir a utilização da CPU. Como alternativa, você pode optar por aumentar o tamanho da computação do banco de dados ou do pool elástico para contornar o problema.
Para obter mais informações de como solucionar problemas de desempenho de CPU no Banco de Dados SQL do Azure, confira Diagnosticar e solucionar problemas de alta CPU no Banco de Dados SQL do Azure.
Identificar problemas de desempenho de E/S
Ao identificar problemas de desempenho de entrada/saída (E/S) no armazenamento, os principais tipos de espera são:
PAGEIOLATCH_*Para problemas de E/S de arquivos de dados (incluindo
PAGEIOLATCH_SH,PAGEIOLATCH_EX,PAGEIOLATCH_UP). Se o nome do tipo de espera contém E/S, isso indica um problema de E/S. Se não houver nenhuma E/S no nome do tempo de espera de trava da página, ela apontará para um tipo diferente de problema que não está relacionado ao desempenho do armazenamento (por exemplo, contenção detempdb).WRITE_LOGPara problemas de E/S do log de transações.
Se o problema de E/S estiver ocorrendo agora
Use o . DM exec_requests ou DM os_waiting_tasks para ver os wait_type e wait_time.
Identificar os dados e registrar o uso de E/S
Use a consulta a seguir para identificar o uso de E/S de dados e log.
SELECT
database_name = DB_NAME()
, UTC_time = end_time
, 'Data IO In % of Limit' = rs.avg_data_io_percent
, 'Log Write Utilization In % of Limit' = rs.avg_log_write_percent
FROM sys.dm_db_resource_stats AS rs --past hour only
ORDER BY rs.end_time DESC;
Para obter mais exemplos usando sys.dm_db_resource_stats, confira a seção Monitorar o uso de recursos mais adiante neste artigo.
Se o limite de E/S foi atingido, você tem duas opções:
- Atualizar o tamanho da computação ou camada de serviço
- Identificar e ajustar as consultas que consomem mais E/S.
Exibir E/S relacionada ao buffer usando o Repositório de Consultas
Para identificar as principais consultas por esperas relacionadas à E/S, você pode usar a seguinte consulta do Repositório de Consultas para exibir as últimas duas horas de atividade acompanhada:
-- Top queries that waited on buffer
-- Note these are finished queries
WITH Aggregated AS (SELECT q.query_hash, SUM(total_query_wait_time_ms) total_wait_time_ms, SUM(total_query_wait_time_ms / avg_query_wait_time_ms) AS total_executions, MIN(qt.query_sql_text) AS sampled_query_text, MIN(wait_category_desc) AS wait_category_desc
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id=q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id=p.query_id
INNER JOIN sys.query_store_wait_stats AS waits ON waits.plan_id=p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id=waits.runtime_stats_interval_id
WHERE wait_category_desc='Buffer IO' AND rsi.start_time>=DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash), Ordered AS (SELECT query_hash, total_executions, total_wait_time_ms, sampled_query_text, wait_category_desc, ROW_NUMBER() OVER (ORDER BY total_wait_time_ms DESC, query_hash ASC) AS query_hash_row_number
FROM Aggregated)
SELECT OD.query_hash, OD.total_executions, OD.total_wait_time_ms, OD.sampled_query_text, OD.wait_category_desc, OD.query_hash_row_number
FROM Ordered AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_wait_time_ms
ORDER BY total_wait_time_ms DESC;
GO
Você também pode usar a exibição sys.query_store_runtime_stats, concentrando-se nas consultas com valores grandes nas colunas avg_physical_io_reads e avg_num_physical_io_reads.
Exibir o total de E/S de log para esperas de WRITELOG
Se o tipo de espera for WRITELOG, use a seguinte consulta para exibir o total de E/S de log por instrução:
-- Top transaction log consumers
-- Adjust the time window by changing
-- rsi.start_time >= DATEADD(hour, -2, GETUTCDATE())
WITH AggregatedLogUsed
AS (SELECT q.query_hash,
SUM(count_executions * avg_cpu_time / 1000.0) AS total_cpu_ms,
SUM(count_executions * avg_cpu_time / 1000.0) / SUM(count_executions) AS avg_cpu_ms,
SUM(count_executions * avg_log_bytes_used) AS total_log_bytes_used,
MAX(rs.max_cpu_time / 1000.00) AS max_cpu_ms,
MAX(max_logical_io_reads) max_logical_reads,
COUNT(DISTINCT p.plan_id) AS number_of_distinct_plans,
COUNT(DISTINCT p.query_id) AS number_of_distinct_query_ids,
SUM( CASE
WHEN rs.execution_type_desc = 'Aborted' THEN
count_executions
ELSE 0
END
) AS Aborted_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Regular' THEN
count_executions
ELSE 0
END
) AS Regular_Execution_Count,
SUM( CASE
WHEN rs.execution_type_desc = 'Exception' THEN
count_executions
ELSE 0
END
) AS Exception_Execution_Count,
SUM(count_executions) AS total_executions,
MIN(qt.query_sql_text) AS sampled_query_text
FROM sys.query_store_query_text AS qt
INNER JOIN sys.query_store_query AS q ON qt.query_text_id = q.query_text_id
INNER JOIN sys.query_store_plan AS p ON q.query_id = p.query_id
INNER JOIN sys.query_store_runtime_stats AS rs ON rs.plan_id = p.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS rsi ON rsi.runtime_stats_interval_id = rs.runtime_stats_interval_id
WHERE rs.execution_type_desc IN ( 'Regular', 'Aborted', 'Exception' )
AND rsi.start_time >= DATEADD(HOUR, -2, GETUTCDATE())
GROUP BY q.query_hash),
OrderedLogUsed
AS (SELECT query_hash,
total_log_bytes_used,
number_of_distinct_plans,
number_of_distinct_query_ids,
total_executions,
Aborted_Execution_Count,
Regular_Execution_Count,
Exception_Execution_Count,
sampled_query_text,
ROW_NUMBER() OVER (ORDER BY total_log_bytes_used DESC, query_hash ASC) AS query_hash_row_number
FROM AggregatedLogUsed)
SELECT OD.total_log_bytes_used,
OD.number_of_distinct_plans,
OD.number_of_distinct_query_ids,
OD.total_executions,
OD.Aborted_Execution_Count,
OD.Regular_Execution_Count,
OD.Exception_Execution_Count,
OD.sampled_query_text,
OD.query_hash_row_number
FROM OrderedLogUsed AS OD
WHERE OD.query_hash_row_number <= 15 -- get top 15 rows by total_log_bytes_used
ORDER BY total_log_bytes_used DESC;
GO
Identificar problemas de desempenho do tempdb
Os tipos de espera comuns associados a problemas com tempdb são PAGELATCH_* (não PAGEIOLATCH_*). No entanto, PAGELATCH_* esperas sempre significam que você tem tempdb contenção. Essa espera também pode significar que você tem conflito de dados do usuário provocado por solicitações simultâneas dirigidas à mesma página de dados. Para confirmar adicionalmente a contenção de tempdb, use sys.dm_exec_requests a fim de confirmar se o valor wait_resource começa com 2:x:y, em que 2 é tempdb e a ID do banco de dados, x é a ID do arquivo e y é a ID da página.
Para a contenção de tempdb, um método comum é reduzir ou reescrever o código do aplicativo que se baseia em tempdb. Áreas de uso comum tempdb incluem:
- Tabelas temporárias
- Variáveis de tabela
- Parâmetros com valor de tabela
- Consultas que têm planos de consulta que usam classificações e junções de hash spools
Para saber mais, confira tempdb no SQL do Azure.
Todos os bancos de dados em um pool elástico compartilham o mesmo banco de dados tempdb. Uma alta utilização de espaço de tempdb por um banco de dados pode afetar outros bancos de dados no mesmo pool elástico.
Principais consultas que usam variáveis de tabela e tabelas temporárias
Use a consulta a seguir para identificar as principais consultas que usam tabelas temporárias e variáveis de tabela:
SELECT plan_handle, execution_count, query_plan
INTO #tmpPlan
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_query_plan(plan_handle);
GO
WITH XMLNAMESPACES('http://schemas.microsoft.com/sqlserver/2004/07/showplan' AS sp)
SELECT plan_handle, stmt.stmt_details.value('@Database', 'varchar(max)') AS 'Database'
, stmt.stmt_details.value('@Schema', 'varchar(max)') AS 'Schema'
, stmt.stmt_details.value('@Table', 'varchar(max)') AS 'table'
INTO #tmp2
FROM
(SELECT CAST(query_plan AS XML) sqlplan, plan_handle FROM #tmpPlan) AS p
CROSS APPLY sqlplan.nodes('//sp:Object') AS stmt(stmt_details);
GO
SELECT t.plan_handle, [Database], [Schema], [table], execution_count
FROM
(SELECT DISTINCT plan_handle, [Database], [Schema], [table]
FROM #tmp2
WHERE [table] LIKE '%@%' OR [table] LIKE '%#%') AS t
INNER JOIN #tmpPlan AS t2 ON t.plan_handle=t2.plan_handle;
GO
DROP TABLE #tmpPlan
DROP TABLE #tmp2
Identificar as transações de longa execução
Use a consulta a seguir para identificar transações de execução longas. As transações de execução prolongada impedem a limpeza do PVS (armazenamento de versão persistente). Para obter mais informações, consulte Solucionar problemas de recuperação acelerada do banco de dados.
SELECT DB_NAME(dtr.database_id) 'database_name',
sess.session_id,
atr.name AS 'tran_name',
atr.transaction_id,
transaction_type,
transaction_begin_time,
database_transaction_begin_time,
transaction_state,
is_user_transaction,
sess.open_transaction_count,
TRIM(REPLACE(
REPLACE(
SUBSTRING(
SUBSTRING(
txt.text,
(req.statement_start_offset / 2) + 1,
((CASE req.statement_end_offset
WHEN -1 THEN
DATALENGTH(txt.text)
ELSE
req.statement_end_offset
END - req.statement_start_offset
) / 2
) + 1
),
1,
1000
),
CHAR(10),
' '
),
CHAR(13),
' '
)
) Running_stmt_text,
recenttxt.text 'MostRecentSQLText'
FROM sys.dm_tran_active_transactions AS atr
INNER JOIN sys.dm_tran_database_transactions AS dtr
ON dtr.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_tran_session_transactions AS sess
ON sess.transaction_id = atr.transaction_id
LEFT JOIN sys.dm_exec_requests AS req
ON req.session_id = sess.session_id
AND req.transaction_id = sess.transaction_id
LEFT JOIN sys.dm_exec_connections AS conn
ON sess.session_id = conn.session_id
OUTER APPLY sys.dm_exec_sql_text(req.sql_handle) AS txt
OUTER APPLY sys.dm_exec_sql_text(conn.most_recent_sql_handle) AS recenttxt
WHERE atr.transaction_type != 2
AND sess.session_id != @@spid
ORDER BY start_time ASC;
Identificar problemas de desempenho de espera de concessão de memória
Se o tipo de espera superior for RESOURCE_SEMAPHORE, você poderá ter um problema de espera de concessão de memória em que as consultas não podem começar a ser executadas até que obtenham uma concessão de memória suficientemente grande.
Determinar se uma espera RESOURCE_SEMAPHORE é uma espera máxima
Use a consulta a seguir para determinar se uma espera RESOURCE_SEMAPHORE é uma espera máxima. Outro indicativo seria uma classificação de tempo de espera crescente de RESOURCE_SEMAPHORE no histórico recente. Para saber como solucionar problemas de espera de concessão de memória, confira Solucionar problemas de desempenho lento ou pouca memória causados por concessões de memória no SQL Server.
SELECT wait_type,
SUM(wait_time) AS total_wait_time_ms
FROM sys.dm_exec_requests AS req
INNER JOIN sys.dm_exec_sessions AS sess
ON req.session_id = sess.session_id
WHERE is_user_process = 1
GROUP BY wait_type
ORDER BY SUM(wait_time) DESC;
Identificar instruções altas que consomem memória
Se você encontrar erros de memória insuficiente no Banco de Dados SQL do Azure, revise sys.dm_os_out_of_memory_events. Para saber mais, confira Solucionar erros de falta de memória no Banco de Dados SQL do Azure.
Primeiro, modifique o script abaixo para atualizar os valores relevantes de start_time e end_time. Em seguida, execute a seguinte consulta para identificar instruções que consomem muita memória:
SELECT IDENTITY(INT, 1, 1) rowId,
CAST(query_plan AS XML) query_plan,
p.query_id
INTO #tmp
FROM sys.query_store_plan AS p
INNER JOIN sys.query_store_runtime_stats AS r
ON p.plan_id = r.plan_id
INNER JOIN sys.query_store_runtime_stats_interval AS i
ON r.runtime_stats_interval_id = i.runtime_stats_interval_id
WHERE start_time > '2018-10-11 14:00:00.0000000'
AND end_time < '2018-10-17 20:00:00.0000000';
WITH cte
AS (SELECT query_id,
query_plan,
m.c.value('@SerialDesiredMemory', 'INT') AS SerialDesiredMemory
FROM #tmp AS t
CROSS APPLY t.query_plan.nodes('//*:MemoryGrantInfo[@SerialDesiredMemory[. > 0]]') AS m(c) )
SELECT TOP 50
cte.query_id,
t.query_sql_text,
cte.query_plan,
CAST(SerialDesiredMemory / 1024. AS DECIMAL(10, 2)) SerialDesiredMemory_MB
FROM cte
INNER JOIN sys.query_store_query AS q
ON cte.query_id = q.query_id
INNER JOIN sys.query_store_query_text AS t
ON q.query_text_id = t.query_text_id
ORDER BY SerialDesiredMemory DESC;
Identificar as 10 principais concessão de memória
Use a consulta a seguir para identificar 10 principais concessão de memória:
SELECT TOP 10
CONVERT(VARCHAR(30), GETDATE(), 121) AS runtime,
r.session_id,
r.blocking_session_id,
r.cpu_time,
r.total_elapsed_time,
r.reads,
r.writes,
r.logical_reads,
r.row_count,
wait_time,
wait_type,
r.command,
OBJECT_NAME(txt.objectid, txt.dbid) 'Object_Name',
TRIM(REPLACE(REPLACE(SUBSTRING(SUBSTRING(TEXT, (r.statement_start_offset / 2) + 1,
( (
CASE r.statement_end_offset
WHEN - 1
THEN DATALENGTH(TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset
) / 2
) + 1), 1, 1000), CHAR(10), ' '), CHAR(13), ' ')) AS stmt_text,
mg.dop, --Degree of parallelism
mg.request_time, --Date and time when this query requested the memory grant.
mg.grant_time, --NULL means memory has not been granted
mg.requested_memory_kb / 1024.0 requested_memory_mb, --Total requested amount of memory in megabytes
mg.granted_memory_kb / 1024.0 AS granted_memory_mb, --Total amount of memory actually granted in megabytes. NULL if not granted
mg.required_memory_kb / 1024.0 AS required_memory_mb, --Minimum memory required to run this query in megabytes.
max_used_memory_kb / 1024.0 AS max_used_memory_mb,
mg.query_cost, --Estimated query cost.
mg.timeout_sec, --Time-out in seconds before this query gives up the memory grant request.
mg.resource_semaphore_id, --Non-unique ID of the resource semaphore on which this query is waiting.
mg.wait_time_ms, --Wait time in milliseconds. NULL if the memory is already granted.
CASE mg.is_next_candidate --Is this process the next candidate for a memory grant
WHEN 1 THEN
'Yes'
WHEN 0 THEN
'No'
ELSE
'Memory has been granted'
END AS 'Next Candidate for Memory Grant',
qp.query_plan
FROM sys.dm_exec_requests AS r
INNER JOIN sys.dm_exec_query_memory_grants AS mg
ON r.session_id = mg.session_id
AND r.request_id = mg.request_id
CROSS APPLY sys.dm_exec_sql_text(mg.sql_handle) AS txt
CROSS APPLY sys.dm_exec_query_plan(r.plan_handle) AS qp
ORDER BY mg.granted_memory_kb DESC;
Conexões do monitor
É possível usar a exibição sys.dm_exec_connections para recuperar informações sobre as conexões estabelecidas com um banco de dados específico e os detalhes de cada conexão. Se um banco de dados estiver em um pool elástico e você tiver permissões suficientes, a exibição retorna o conjunto de conexões de todos os bancos de dados no pool elástico. Além disso, a exibição sys.dm_exec_sessions é útil ao recuperar informações sobre todas as conexões de usuário e tarefas internas ativas.
Exibir as sessões atuais
A consulta a seguir recupera informações para a conexão e sessão atuais. Para exibir todas as conexões e sessões, remova a cláusula WHERE.
Você consultará todas as sessões em execução no banco de dados somente se tiver a permissão VIEW DATABASE STATE nele ao executar as exibições sys.dm_exec_requests e sys.dm_exec_sessions. Caso contrário, somente a sessão atual será exibida.
SELECT
c.session_id, c.net_transport, c.encrypt_option,
c.auth_scheme, s.host_name, s.program_name,
s.client_interface_name, s.login_name, s.nt_domain,
s.nt_user_name, s.original_login_name, c.connect_time,
s.login_time
FROM sys.dm_exec_connections AS c
INNER JOIN sys.dm_exec_sessions AS s
ON c.session_id = s.session_id
WHERE c.session_id = @@SPID; --Remove to view all sessions, if permissions allow
Monitorar o desempenho da consulta
Consultas de execução lenta ou longa podem consumir recursos significativos do sistema. Esta seção demonstra como usar exibições de gerenciamento dinâmico para detectar alguns problemas comuns de desempenho de consulta usando a exibição de gerenciamento dinâmico sys.dm_exec_query_stats. A exibição contém uma linha por instrução de consulta dentro do plano em cache e o tempo de vida das linhas é ligado ao próprio plano. Quando um plano é removido do cache, as linhas correspondentes são eliminadas desta exibição. Se uma consulta não tiver um plano armazenado em cache, por exemplo, porque OPTION (RECOMPILE) é usada, ela não estará presente nos resultados dessa exibição.
Encontrar as principais consultas por tempo de CPU
O exemplo a seguir retorna informações sobre as 15 principais consultas classificadas de acordo com o tempo médio de CPU por execução. Este exemplo agrega as consultas de acordo com sua hash de consulta, para que as consultas logicamente equivalentes sejam agrupadas em função de seu consumo de recursos cumulativos.
SELECT TOP 15 query_stats.query_hash AS Query_Hash,
SUM(query_stats.total_worker_time) / SUM(query_stats.execution_count) AS Avg_CPU_Time,
MIN(query_stats.statement_text) AS Statement_Text
FROM
(SELECT QS.*,
SUBSTRING(ST.text, (QS.statement_start_offset/2) + 1,
((CASE statement_end_offset
WHEN -1 THEN DATALENGTH(ST.text)
ELSE QS.statement_end_offset END
- QS.statement_start_offset)/2) + 1) AS statement_text
FROM sys.dm_exec_query_stats AS QS
CROSS APPLY sys.dm_exec_sql_text(QS.sql_handle) AS ST
) AS query_stats
GROUP BY query_stats.query_hash
ORDER BY Avg_CPU_Time DESC;
Monitorar planos de consulta quanto ao tempo cumulativo de CPU
Um plano de consulta ineficiente também pode aumentar o consumo de CPU. O exemplo a seguir determina qual consulta usa a CPU mais cumulativa no histórico recente.
SELECT
highest_cpu_queries.plan_handle,
highest_cpu_queries.total_worker_time,
q.dbid,
q.objectid,
q.number,
q.encrypted,
q.[text]
FROM
(SELECT TOP 15
qs.plan_handle,
qs.total_worker_time
FROM
sys.dm_exec_query_stats AS qs
ORDER BY qs.total_worker_time desc
) AS highest_cpu_queries
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
ORDER BY highest_cpu_queries.total_worker_time DESC;
Monitorar consultas bloqueadas
Consultas lentas ou demoradas podem contribuir para consumo excessivo de recursos e ser a consequência de consultas bloqueadas. A causa do bloqueio pode ser projeto inadequado de aplicativos, planos de consulta incorretos, a falta de índices úteis e assim por diante.
É possível usar a exibição sys.dm_tran_locks para saber mais sobre a atividade de bloqueio atual no banco de dados. Para obter exemplos de código, confira sys.dm_tran_locks. Para obter mais informações sobre como solucionar problemas de bloqueio, consulte entender e resolver problemas de bloqueio do SQL do Azure.
Monitorar deadlocks
Em alguns casos, duas ou mais consultas podem bloquear-se mutuamente, resultando em um deadlock.
Você pode criar um rastreamento de Eventos Estendidos para capturar eventos de deadlock e encontrar consultas relacionadas e os respectivos planos de execução no Repositório de Consultas. Saiba mais em Analisar e evitar deadlocks no Banco de Dados SQL do Azure, que também contém um laboratório para Causar um deadlocks no AdventureWorksLT. Saiba mais sobre os tipos de recursos propensos a deadlock.
Permissões
No Banco de Dados SQL do Azure, dependendo do tamanho de computação, da opção de implantação e dos dados na DMV, consultar uma DMV pode exigir permissão VIEW DATABASE STATE, VIEW SERVER PERFORMANCE STATEou VIEW SERVER SECURITY STATE. As duas últimas permissões estão incluídas na permissão VIEW SERVER STATE. As permissões View server state são concedidas por meio da subscrição às funções de servidor correspondentes. Para determinar quais permissões são necessárias para consultar uma DMV específica, confira Exibições de gerenciamento dinâmico e localize o artigo que descreve a DMV.
Para conceder a permissão VIEW DATABASE STATE a um usuário do banco de dados, execute a seguinte consulta, substituindo database_user pelo nome da entidade de usuário no banco de dados:
GRANT VIEW DATABASE STATE TO [database_user];
Para conceder subscrição na função de servidor ##MS_ServerStateReader## a um logon chamado login_name em um servidor lógico, conecte-se ao banco de dados master e execute a seguinte consulta como exemplo:
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER [login_name];
Pode levar alguns minutos para que a concessão de permissão entre em vigor. Para obter mais informações, confira Limitações de funções de nível de servidor.
Conteúdo relacionado
- Diagnosticar e solucionar problemas de alta CPU em Banco de Dados SQL do Azure
- Ajustar aplicativos e bancos de dados com relação ao desempenho no Banco de Dados SQL do Azure
- Entender e resolver problemas de bloqueio do Banco de Dados SQL do Azure
- Analisar e evitar deadlocks no Banco de Dados SQL do Azure
- Insights sobre Desempenho de Consultas
- sys.dm_db_resource_stats
- sys. resource_stats
- sys.dm_elastic_pool_resource_stats
- sys.elastic_pool_resource_stats