Ajustar aplicativos e bancos de dados para desempenho na Instância Gerenciada de SQL do Azure
Aplica-se a: ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
Depois de identificar um problema de desempenho que você está enfrentando com a Instância Gerenciada de SQL do Azure, este artigo foi desenvolvido para ajudá-lo a:
- Ajustar o aplicativo e aplicar algumas melhores práticas que podem melhorar o desempenho.
- Ajustar o banco de dados alterando índices e consultas para trabalhar com os dados de forma mais eficiente.
Este artigo pressupõe que você tenha revisado a Visão geral do monitoramento e ajuste e Monitorar o desempenho usando o Repositório de Consultas. Além disso, este artigo pressupõe que você não tenha um problema de desempenho relacionado ao uso de recursos da CPU que possa ser resolvido aumentando o tamanho da computação ou a camada de serviço para fornecer mais recursos à sua Instância Gerenciada de SQL.
Observação
Para obter diretrizes semelhantes sobre o Banco de Dados SQL do Azure, confira Ajustar aplicativos e bancos de dados para aprimorar o desempenho no Banco de Dados SQL do Azure.
Ajustar seu aplicativo
No SQL Server local tradicional, o processo de planejamento de capacidade inicial frequentemente é separado do processo de executar um aplicativo em produção. Hardwares e licenças de produtos são comprados primeiro e o ajuste de desempenho é feito posteriormente. Quando você usa o SQL do Azure, é uma boa ideia integrar o processo de execução de um aplicativo e de seu ajuste. Com o modelo de pagamento por capacidade sob demanda, é possível ajustar o aplicativo para usar os recursos mínimos necessários atualmente, em vez de provisionamento excessivo em hardware com base em suposições de planos de crescimento futuros para um aplicativo, que geralmente estão incorretos.
Alguns clientes podem optar por não ajustar um aplicativo e optar por provisionar recursos de hardware em excesso. Essa abordagem poderá ser uma boa ideia se você não quiser alterar um aplicativo importante durante um período movimentado. Entretanto, ajustar o aplicativo pode minimizar os requisitos de recurso e diminuir as contas mensais.
Práticas recomendadas e antipadrões no design de aplicativos para a Instância Gerenciada de SQL do Azure
Embora as camadas de serviço da Instância Gerenciada de SQL do Azure sejam projetadas para melhorar a estabilidade e a previsibilidade de desempenho de um aplicativo, algumas práticas recomendadas podem ajudar a ajustar seu aplicativo para aproveitar melhor os recursos de um tamanho da computação. Embora vários aplicativos apresentem ganhos de desempenho significativos simplesmente passando para um tamanho da computação ou camada de serviço superior, outros precisam de ajustes adicionais para se beneficiarem de um nível de serviço mais elevado.
Para melhorar o desempenho, considere realizar ajustes adicionais em aplicativos que têm estas características:
Aplicativos com desempenho lento devido a comportamento "com ruídos"
Aplicativos barulhentos geram um excesso de operações de acesso a dados sensíveis à latência de rede. Pode ser necessário modificar esses tipos de aplicativos para reduzir o número de operações de acesso a dados no banco de dados. Por exemplo, você pode melhorar o desempenho do aplicativo usando técnicas como o envio em lote de consultas ad hoc ou a movimentação das consultas em procedimentos armazenados. Para obter mais informações, consulte Consultas em lote.
Bancos de dados com uma carga de trabalho intensiva que não pode ter suporte por um único computador inteiro
Bancos de dados que ultrapassam os recursos do maior tamanho da computação Premium podem se beneficiar de escalar horizontalmente a carga de trabalho. Para obter mais informações, consulte Fragmentação entre banco de dados e Particionamento funcional.
Aplicativos com consultas não otimizadas
Aplicativos que têm consultas mal ajustadas podem não se beneficiar de um tamanho maior da computação. Isso inclui consultas sem uma cláusula WHERE, com índices ausentes ou com estatísticas desatualizadas. Esses aplicativos se beneficiam de técnicas de ajuste de desempenho de consulta padrão. Para obter mais informações, consulte Índices ausentes e Ajuste e dicas de consulta.
Aplicativos com design de acesso a dados não otimizados
Aplicativos com problemas de simultaneidade de acesso a dados intrínsecos, por exemplo, deadlock, talvez não se beneficiem de um tamanho da computação maior. Considere reduzir as viagens de ida e volta ao banco de dados armazenando em cache os dados no lado do cliente usando o serviço de Caching do Azure ou outras tecnologias de cache. Consulte Cache da camada de aplicativo.
Para evitar deadlocks na Instância Gerenciada de SQL do Azure, confira as ferramentas Deadlock do guia Deadlocks.
Ajustar o banco de dados
Nesta seção, vemos algumas técnicas que você pode usar para ajustar o banco de dados para obter o melhor desempenho para seu aplicativo e executá-lo no menor tamanho da computação possível. Algumas dessas técnicas correspondem às práticas recomendadas tradicionais de ajuste do SQL Server, mas outras são específicas à Instância Gerenciada de SQL do Azure. Em alguns casos, você pode examinar os recursos consumidos por um banco de dados para localizar áreas para ajustar ainda mais, bem como ampliar técnicas tradicionais do SQL Server para que elas funcionem na Instância Gerenciada de SQL do Azure.
Identificar e aplicar índices ausentes
Um problema comum no desempenho do banco de dados OLTP está relacionado ao design do banco de dados físico. Com frequência, os esquemas de banco de dados são projetados e enviados sem testes em escala (seja na carga ou no volume de dados). Infelizmente, o desempenho de um plano de consulta pode ser aceitável em pequena escala, mas pode ser comprometido substancialmente diante de volumes de dados de nível de produção. A origem mais comum desse problema é a falta de índices apropriados para satisfazer filtros ou outras restrições em uma consulta. Geralmente, os índices ausentes se manifestam como uma verificação de tabela quando uma busca de índice poderia bastar.
Neste exemplo, o plano de consulta selecionado usa uma verificação, quando uma pesquisa seria suficiente:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
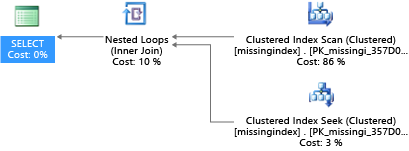
DMVs incorporadas SQL Seerver desde 2005 examinam compilações de consulta em que um índice reduziria significativamente o custo estimado para executar uma consulta. Durante a execução da consulta, o mecanismo de banco de dados monitora com que frequência cada plano de consulta é executado, bem como a lacuna estimada entre o plano de consulta em execução e o plano imaginado, em que esse índice existia. Você pode usar essas DMVs para adivinhar rapidamente quais alterações de design do banco de dados físico podem melhorar o custo da carga de trabalho geral para um banco de dados e sua carga de trabalho real.
Você pode usar esta consulta para avaliar possíveis índices ausentes:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
Neste exemplo, a consulta resultou nesta sugestão:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Após a criação, a mesma instrução SELECT escolhe um plano diferente, que usa uma busca em vez de uma verificação e executa o plano de forma mais eficiente:
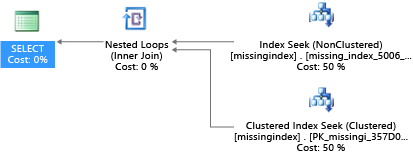
A ideia principal é que a capacidade de E/S de um sistema de mercadoria compartilhado é mais limitada que a de um computador de servidor dedicado. Há o bônus de minimizar a E/S desnecessária e, assim, tirar o máximo proveito do sistema nos recursos de cada tamanho da computação das camadas de serviço. Opções adequadas de design de banco de dados físico podem melhorar significativamente a latência de consultas individuais, melhorar a produtividade de solicitações simultâneas tratadas por unidade de escala e minimizar os custos necessários para satisfazer a consulta.
Para obter mais informações sobre como ajustar índices usando solicitações de índice ausentes, confira Ajustar índices não clusterizados com sugestões de índices ausentes.
Ajuste e dicas de consulta
O otimizador de consulta da Instância Gerenciada de SQL do Azure é semelhante ao otimizador de consulta do SQL Server tradicional. A maioria das práticas recomendadas para o ajuste de consultas e a compreensão das limitações do modelo de raciocínio para o otimizador de consulta também se aplicam à Instância Gerenciada de SQL do Azure. Se ajustar consultas na Instância Gerenciada de SQL do Azure, você poderá obter o benefício adicional de reduzir as demandas de recursos agregados. Seu aplicativo poderá ser executado com um custo menor do que um equivalente não ajustado, porque ele poderá ser executado em um tamanho da computação menor.
Um exemplo que é comum no SQL Server e que também se aplica à Instância Gerenciada de SQL do Azure é como o otimizador de consulta "detecta" parâmetros. Durante a compilação, o otimizador de consulta avalia o valor atual de um parâmetro para determinar se ele pode gerar um plano de consulta melhor. Embora muitas vezes essa estratégia possa levar a um plano de consulta significativamente mais rápido do que um plano compilado sem valores de parâmetro conhecidos, atualmente ele a funciona de modo imperfeito na Instância Gerenciada de SQL do Azure. (Um novo recurso de Desempenho de Consulta Inteligente introduzido com o SQL Server 2022 chamado Otimização do Plano de Sensibilidade de Parâmetro aborda o cenário em que um único plano armazenado em cache para uma consulta parametrizada não é ideal para todos os possíveis valores de parâmetros de entrada. No momento, a Otimização do Plano de Sensibilidade de Parâmetro não está disponível na Instância Gerenciada de SQL do Azure.)
Algumas vezes, o parâmetro não é detectado, e algumas vezes é detectado mas o plano gerado está abaixo do ideal para o conjunto completo de valores de parâmetro em uma carga de trabalho. A Microsoft inclui dicas (diretivas) de consulta para que você possa especificar a intenção mais deliberadamente e substituir o comportamento padrão da detecção de parâmetro. Você pode optar por usar dicas quando o comportamento padrão for imperfeito para uma carga de trabalho específica do cliente.
O exemplo a seguir demonstra como o processador de consultas pode gerar um plano que está abaixo do ideal para os requisitos de desempenho e recursos. Este exemplo também mostra que, se usar uma dica de consulta, você poderá reduzir requisitos de recursos e tempo de execução da consulta para o banco de dados:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
O código de configuração cria uma tabela que distribuiu dados irregularmente na tabela t1. O plano de consulta ideal varia dependendo do parâmetro selecionado. Infelizmente, o comportamento do cache de plano nem sempre recompila a consulta com base no valor do parâmetro mais comum. Portanto, é possível que um plano de qualidade inferior seja armazenado em cache e usado para vários valores, mesmo quando um plano diferente poderia ser uma opção melhor de modo geral. Em seguida, o plano de consulta cria dois procedimentos armazenados idênticos, com exceção de um que tem uma dica de consulta especial.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
É recomendável que você aguarde pelo menos 10 minutos antes de começar a parte 2 do exemplo para que os resultados sejam distintos nos dados de telemetria resultantes.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
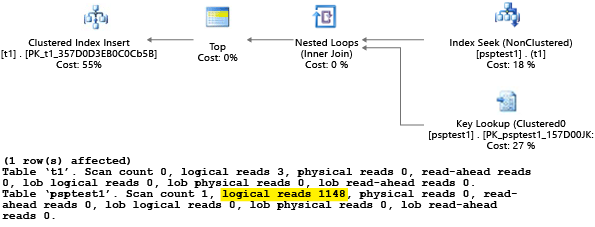
Cada parte deste exemplo tenta executar uma instrução insert com parâmetros 1.000 vezes (para gerar uma carga suficiente para usar como um conjunto de dados de teste). Ao executar procedimentos armazenados, o processador de consultas examina o valor do parâmetro passado ao procedimento durante a primeira compilação ("detecção" de parâmetros). O processador armazena em cache o plano resultante e o usa para invocações posteriores, mesmo que o valor do parâmetro seja diferente. É possível que o plano ideal não seja usado em todos os casos. Às vezes, você precisa orientar o otimizador a escolher um plano que seja melhor para o caso médio em vez do caso específico de quando a consulta foi compilada pela primeira vez. Neste exemplo, o plano inicial gera um plano de "verificação" que lê todas as linhas para localizar cada valor que corresponda ao parâmetro:

Como executamos o procedimento usando o valor 1, o plano resultante era ideal para o valor 1, mas de qualidade inferior para todos os outros valores da tabela. O resultado provavelmente não é o que você desejaria se fosse escolher cada plano aleatoriamente, porque o plano é mais lento e usa mais recursos.
Se você executar o teste com SET STATISTICS IO definido como ON, o trabalho de verificação lógica neste exemplo será feito em segundo plano. Você pode ver que há 1.148 leituras feitas pelo plano (o que não será eficiente, se o caso médio retornar apenas uma linha):

A segunda parte do exemplo usa uma dica de consulta para dizer ao otimizador para usar um valor específico durante o processo de compilação. Nesse caso, ele força o processador de consulta a ignorar o valor que é passado como parâmetro, e em vez disso pressupõe UNKNOWN. Isso se refere a um valor que tem a frequência média na tabela (ignorando a distorção). O plano resultante é um plano baseado em busca que é mais rápido e usa menos recursos, em média, do que o plano da parte 1 do exemplo:
Você pode ver o efeito na exibição do catálogo do sistema sys.server_resource_stats. Os dados são coletados, agregados e atualizados em intervalos de cinco a dez minutos. Há uma linha para cada relatório de 15 segundos. Por exemplo:
SELECT TOP 1000 *
FROM sys.server_resource_stats
ORDER BY start_time DESC
Você pode examinar sys.server_resource_stats para determinar se o recurso para um teste usa mais ou menos recursos do que outro teste. Ao comparar dados, separe os testes por tempo de modo que eles não fiquem na mesma janela de tempo de 5 minutos na exibição sys.server_resource_stats. O objetivo deste exercício é minimizar a quantidade total de recursos usados, não minimizar os recursos de pico. Em geral, a otimização de uma parte do código de latência também reduz o consumo de recursos. Certifique-se de que as alterações feitas em um aplicativo sejam necessárias e de que elas não afetem negativamente a experiência do cliente para alguém que possa estar usando dicas de consulta no aplicativo.
Se uma carga de trabalho tem um conjunto de consultas repetidas, normalmente faz sentido capturar e validar a natureza ideal dessas opções de plano, pois ela orienta a unidade de tamanho mínima de recursos necessária para hospedar o banco de dados. Depois de validar, volte a examinar os planos periodicamente para ter certeza de que eles não degradaram. Saiba mais sobre dicas de consulta (Transact-SQL).
Práticas recomendadas para arquiteturas de bancos de dados muito grandes na Instância Gerenciada de SQL do Azure
As duas seções a seguir discutem duas opções para a solução de problemas com bancos de dados muito grandes na Instância Gerenciada de SQL do Azure.
Fragmentação entre bancos de dados
Como a Instância Gerenciada de SQL do Azure é executada no hardware de mercadoria, há limites inferiores de capacidade para um banco de dados individual em relação a uma instalação do SQL Server local tradicional. Alguns clientes usam técnicas de fragmentação para distribuir operações de banco de dados por vários bancos de dados quando elas não se ajustam aos limites de um banco de dados individual na Instância Gerenciada de SQL do Azure. A maioria dos clientes que usam técnicas de fragmentação na Instância Gerenciada de SQL do Azure divide seus dados em uma única dimensão entre vários bancos de dados. Para esta abordagem, você precisa compreender que aplicativos OLTP executam com frequência transações que se aplicam somente a uma linha ou a um pequeno grupo de linhas no esquema.
Por exemplo, se um banco de dados contiver o nome do cliente, o pedido e os detalhes do pedido (como no banco de dados AdventureWorks), você poderá dividir esses dados em vários bancos de dados agrupando um cliente com o pedido relacionado e as informações de detalhes do pedido. É possível garantir que os dados do cliente permaneçam em um banco de dados individual. O aplicativo dividiria clientes diferentes entre os bancos de dados, distribuindo efetivamente a carga entre vários bancos de dados. Com a fragmentação, não apenas os clientes podem evitar o limite de tamanho máximo do banco de dados, mas a Instância Gerenciada de SQL do Azure também pode processar cargas de trabalho significativamente maiores do que os limites dos diferentes tamanhos da computação, desde que cada banco de dados individual caiba em sua DTU.
Embora a fragmentação do banco de dados não reduza a capacidade agregada de recursos de uma solução, ela é altamente eficaz para dar suporte a soluções muito grandes que são distribuídas em vários bancos de dados. Cada banco de dados pode ser executado em um tamanho da computação diferente para compatibilidade com bancos de dados “efetivos” muito grandes, com altos requisitos de recursos.
Particionamento funcional
Com frequência, os usuário combinam muitas funções em um banco de dados individual. Por exemplo, se um aplicativo tiver lógica para gerenciar o inventário de uma loja, esse banco de dados poderá ter lógica associada ao controle de inventário, acompanhamento de ordens de compra, procedimentos armazenados e exibições indexadas/materializadas que gerenciam os relatórios de final de mês. Essa técnica facilita a administração do banco de dados para operações como backup, mas também requer que você dimensione o hardware para lidar com a carga de pico em todas as funções de um aplicativo.
Se você usar uma arquitetura expandida na Instância Gerenciada de SQL do Azure, será útil dividir funções diferentes de um aplicativo em bancos de dados diferentes. Se você usar essa técnica, cada aplicativo será dimensionado de forma independente. À medida que um aplicativo se torna mais ocupado (e a carga no banco de dados aumenta), o administrador pode escolher tamanhos da computação independentes para cada função do aplicativo. No limite, com essa arquitetura, um aplicativo pode ficar maior do que a capacidade de um único computador de mercadoria porque a carga está distribuída por várias máquinas.
Consultas em lote
Para aplicativos que acessam dados usando consultas ad-hoc frequentes de alto volume, uma grande parte do tempo de resposta é gasto na comunicação de rede entre a camada do aplicativo e a camada do banco de dados. Mesmo quando o aplicativo e o banco de dados estiverem no mesmo data center, a latência de rede entre os dois poderá ser aumentada por um grande número de operações de acesso a dados. Para reduzir as viagens de ida e volta da rede para as operações de acesso a dados, considere usar a opção de processar as consultas ad hoc em lote ou compilá-las como procedimentos armazenados. Se processar as consultas ad hoc, você poderá enviar várias consultas como um lote grande em uma única viagem ao banco de dados. Se compilar consultas ad hoc em um procedimento armazenado, você poderá alcançar o mesmo resultado que teria processando-as em lote. O uso de um procedimento armazenado também oferece o benefício de aumentar as chances de armazenar em cache os planos de consulta no banco de dados para usar o procedimento armazenado novamente.
Alguns aplicativos apresentam gravação intensa. Às vezes, você pode reduzir a carga de E/S total em um banco de dados considerando como fazer as gravações em lote. Com frequência, essa técnica tão simples quanto usar transações explícitas em vez de transações de confirmação automática em procedimentos armazenados e lotes ad hoc. Para ver uma avaliação das diferentes técnicas que você pode usar, consulte Técnicas de envio em lote para aplicativos do banco de dados no Azure. Teste sua própria carga de trabalho para encontrar o modelo certo para envio em lote. Tenha em mente que um modelo pode ter garantias de consistência transacional ligeiramente diferentes. Para encontrar a carga de trabalho certa que minimiza o uso de recursos, é necessário encontrar a combinação certa de compensações de consistência e de desempenho.
Cache de camada de aplicativo
Alguns aplicativos de banco de dados têm cargas de trabalho de leitura pesada. Camadas de cache podem reduzir a carga no banco de dados e, potencialmente, reduzir o tamanho da computação necessário para oferecer compatibilidade com um banco de dados usando a Instância Gerenciada de SQL do Azure. Com o Cache do Azure para Redis, se tiver uma carga de trabalho com uso intensivo de leitura, você poderá ler os dados de uma vez (ou talvez uma vez por computador da camada de aplicativo, dependendo de como estiver configurado) e, em seguida, armazenar esses dados fora do seu banco de dados. Esta é uma forma de reduzir a carga do banco de dados (CPU e E/S de leitura), mas há um impacto na consistência transacional, porque os dados lidos do cache podem estar fora de sincronia com os dados no banco de dados. Embora em muitos aplicativos algum nível de inconsistência seja aceitável, isso não vale para todas as cargas de trabalho. É necessário compreender totalmente todos os requisitos do aplicativo antes de implementar uma estratégia de cache da camada do aplicativo.
Conteúdo relacionado
- Modelo de compra vCore – Instância Gerenciada de SQL do Azure
- Definir configurações do tempdb para Instância Gerenciada de SQL do Azure
- Monitoramento do desempenho da Instância Gerenciada de SQL do Microsoft Azure usando exibições de gerenciamento dinâmico
- Ajustar índices não clusterizados com sugestões de índice ausente
- Monitorar Instância Gerenciada de SQL do Azure com o Azure Monitor