Observação
O acesso a essa página exige autorização. Você pode tentar entrar ou alterar diretórios.
O acesso a essa página exige autorização. Você pode tentar alterar os diretórios.
Este artigo descreve como restaurar bancos de dados SAP HANA em execução em máquinas virtuais (VMs) do Azure que o serviço Backup do Azure copiou em backup em um cofre dos Serviços de Recuperação. O Backup do Azure permite que você use os dados restaurados para criar cópias para cenários de desenvolvimento e teste ou para retornar a um estado anterior. Você também pode restaurar o banco de dados usando a CLI do Azure.
O Backup do Azure agora dá suporte ao backup e à restauração da instância de HSR (Replicação de Sistema) do SAP HANA usando o portal do Azure. Você também pode fazer a operação de restauração usando a CLI do Azure.
Observação
- O processo de restauração de bancos de dados HANA com HSR é o mesmo que o da restauração de bancos de dados HANA sem HSR. De acordo com as recomendações da SAP, você pode restaurar bancos de dados com o modo HSR como bancos de dados autônomos. Se o sistema de destino tiver o modo HSR habilitado, primeiro desabilite esse modo e restaure o banco de dados. No entanto, se você estiver restaurando como arquivos, não é necessário desabilitar o modo HSR (interromper o HSR).
- Atualmente, não há suporte para Recuperação de Localização Original (OLR) para HSR. Como alternativa, selecione restauração de Local alternativo e, em seguida, selecione a VM de origem como o host na lista.
- Não há suporte para a restauração para a instância do HSR. No entanto, há suporte para a restauração apenas para a instância do HANA.
Para obter informações sobre as configurações e os cenários com suporte, confira a matriz de suporte de backup do SAP HANA.
Restaurar para um ponto no tempo ou ponto de recuperação
O Backup do Azure restaura bancos de dados SAP HANA que estão em execução em VMs do Azure. Ele pode:
Restaurá-los em uma data ou uma hora específica (com precisão de segundos) usando backups de log. O Backup do Azure determina automaticamente os backups completos, os backups diferenciais e uma cadeia de backups de log necessários para a restauração com base na hora selecionada. Saiba mais.
Restaurá-los em um backup completo ou diferencial específico para restauração em um ponto de recuperação específico. Saiba mais.
Pré-requisitos
Antes de iniciar a restauração de um banco de dados, observe o seguinte:
Você pode restaurar o banco de dados somente em uma instância SAP HANA que esteja na mesma região.
A instância de destino precisa ser registrada no mesmo cofre que a origem. Saiba mais sobre como fazer backup de bancos de dados SAP HANA.
O Backup do Azure não pode identificar duas instâncias diferentes do SAP HANA na mesma VM. Portanto, a restauração de dados de uma instância para outra na mesma VM não é possível.
Para garantir que a instância SAP HANA de destino esteja pronta para restauração, verifique seu status de Preparação de backup:
No portal do Azure, acesse o Centro de backup e clique em Fazer Backup.
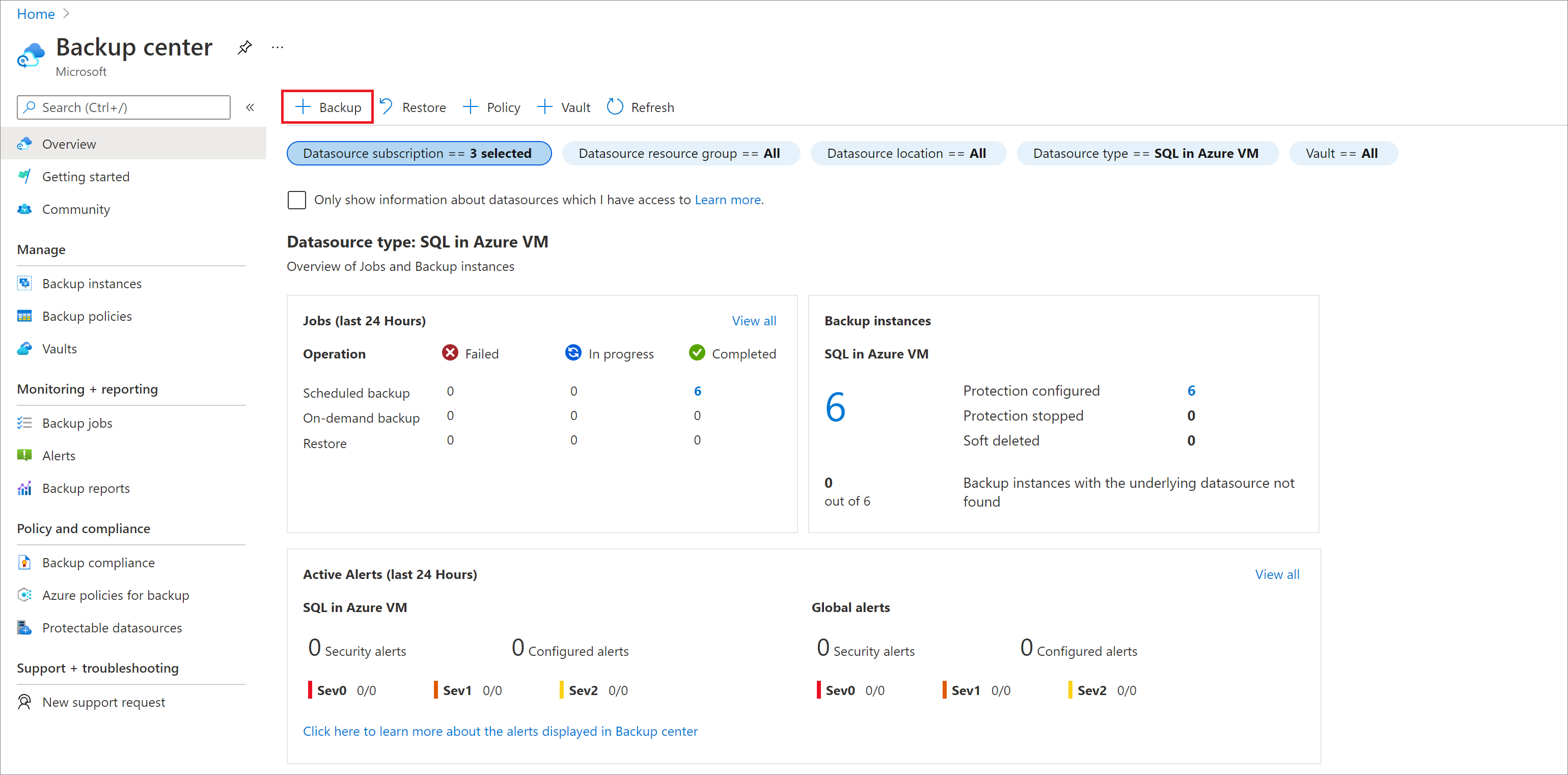
No painel Iniciar: configurar Backup, em Tipo de fonte de dados, selecione SAP HANA na VM do Azure, selecione o cofre no qual a instância do SAP HANA está registrada e clique em Continuar.
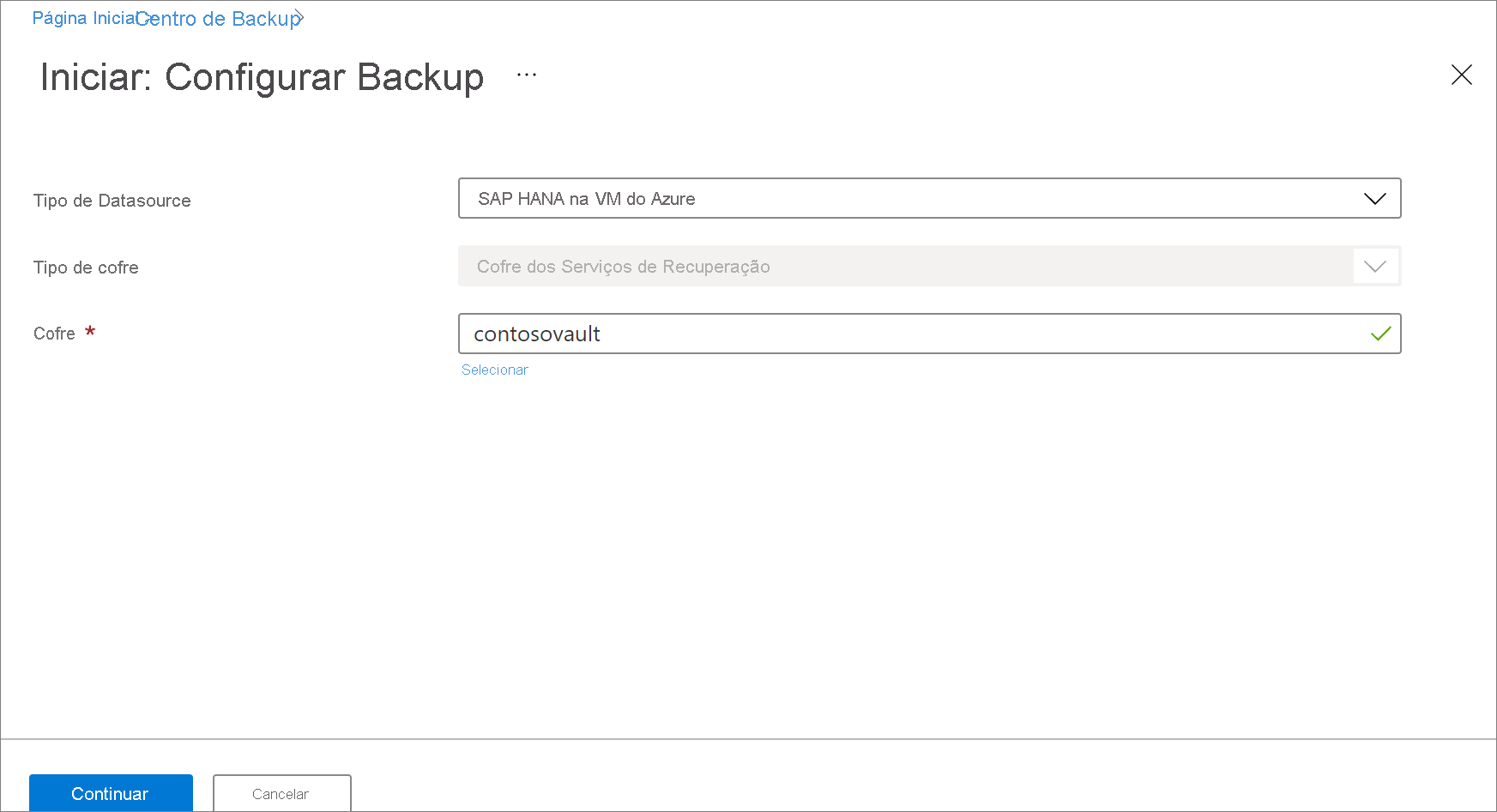
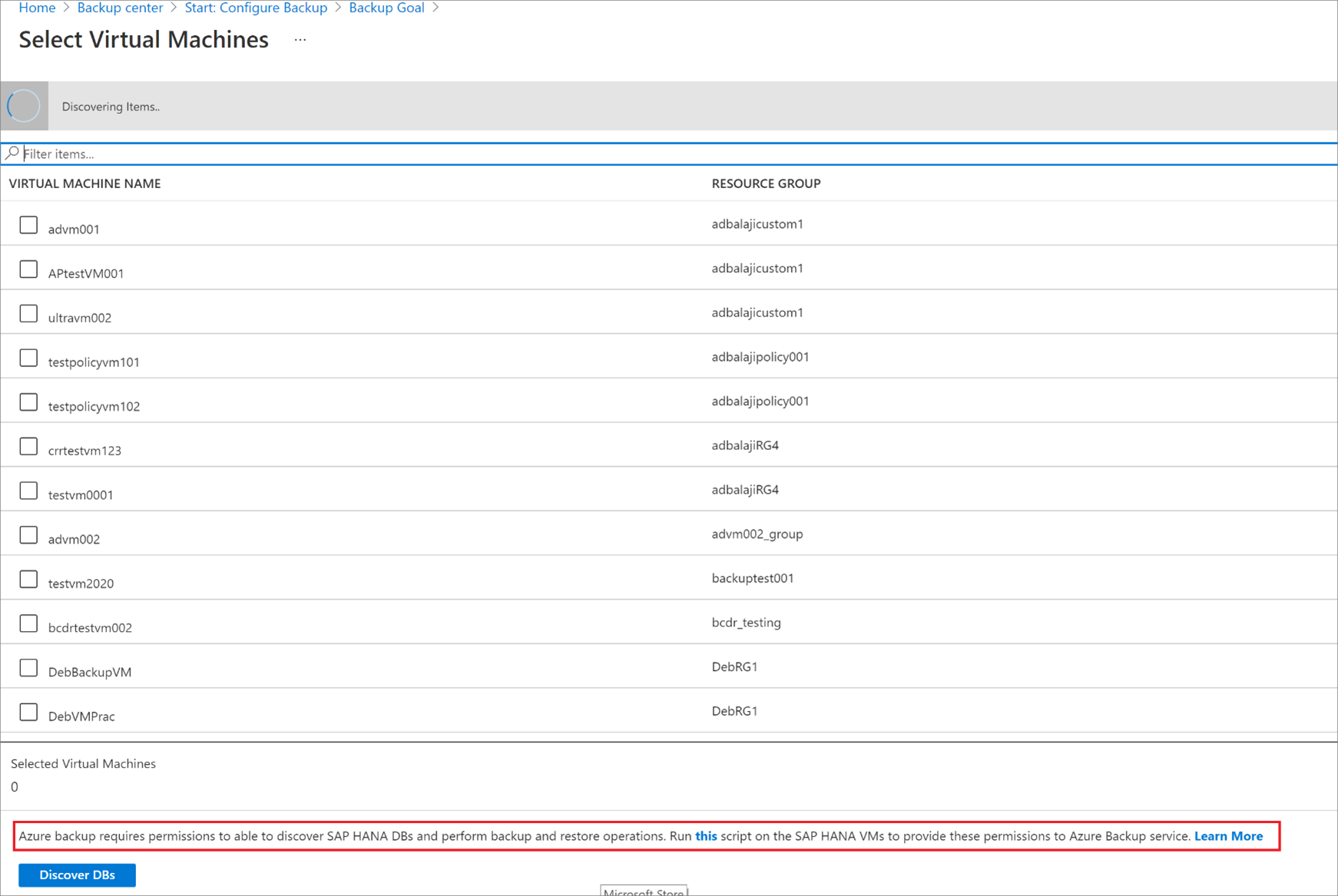
Em Descobrir bancos de dados em VMs, selecione Exibir detalhes.
Examine a Preparação de Backup da VM de destino.
Para saber mais sobre os tipos de restauração compatíveis com o SAP HANA, confira a Nota do SAP HANA 1642148.


Restaurar um banco de dados
Para restaurar um banco de dados, você precisará ter as seguintes permissões:
- Operador de Backup: fornece permissões no cofre em que você está fazendo a restauração.
- Colaborador (gravação): fornece acesso à VM de origem que está sendo submetida a backup.
-
Colaborador (gravação): fornece acesso à VM de destino.
- Se você estiver restaurando na mesma VM, esta é a VM de origem.
- Se você estiver restaurando em uma localização alternativa, esta é a nova VM de destino.
No portal do Azure, acesse o Centro de backup e clique em Restaurar.
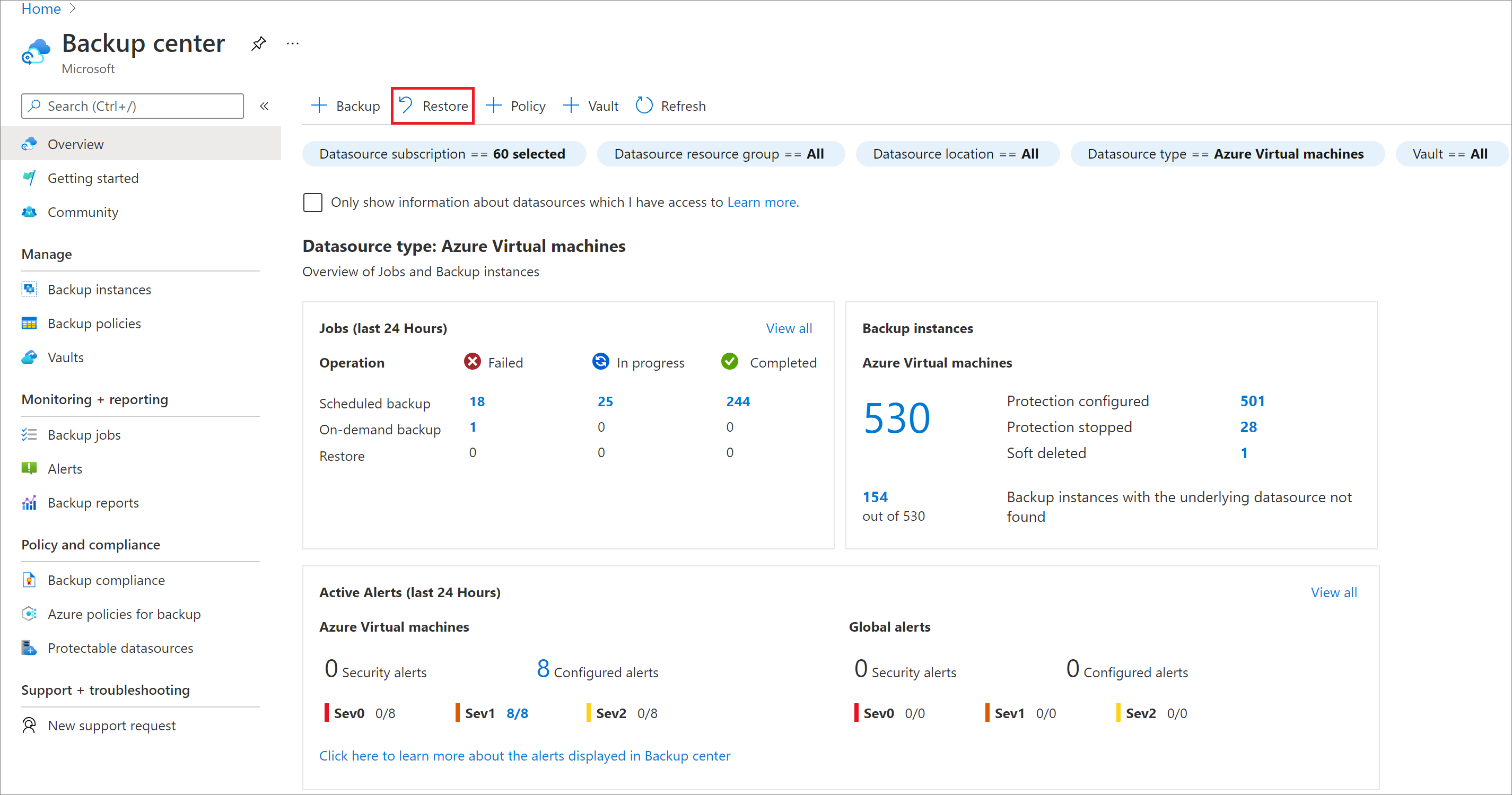
Selecione SAP HANA na VM do Azure como o tipo de fonte de dados, selecione o banco de dados que deseja restaurar e clique em Continuar.
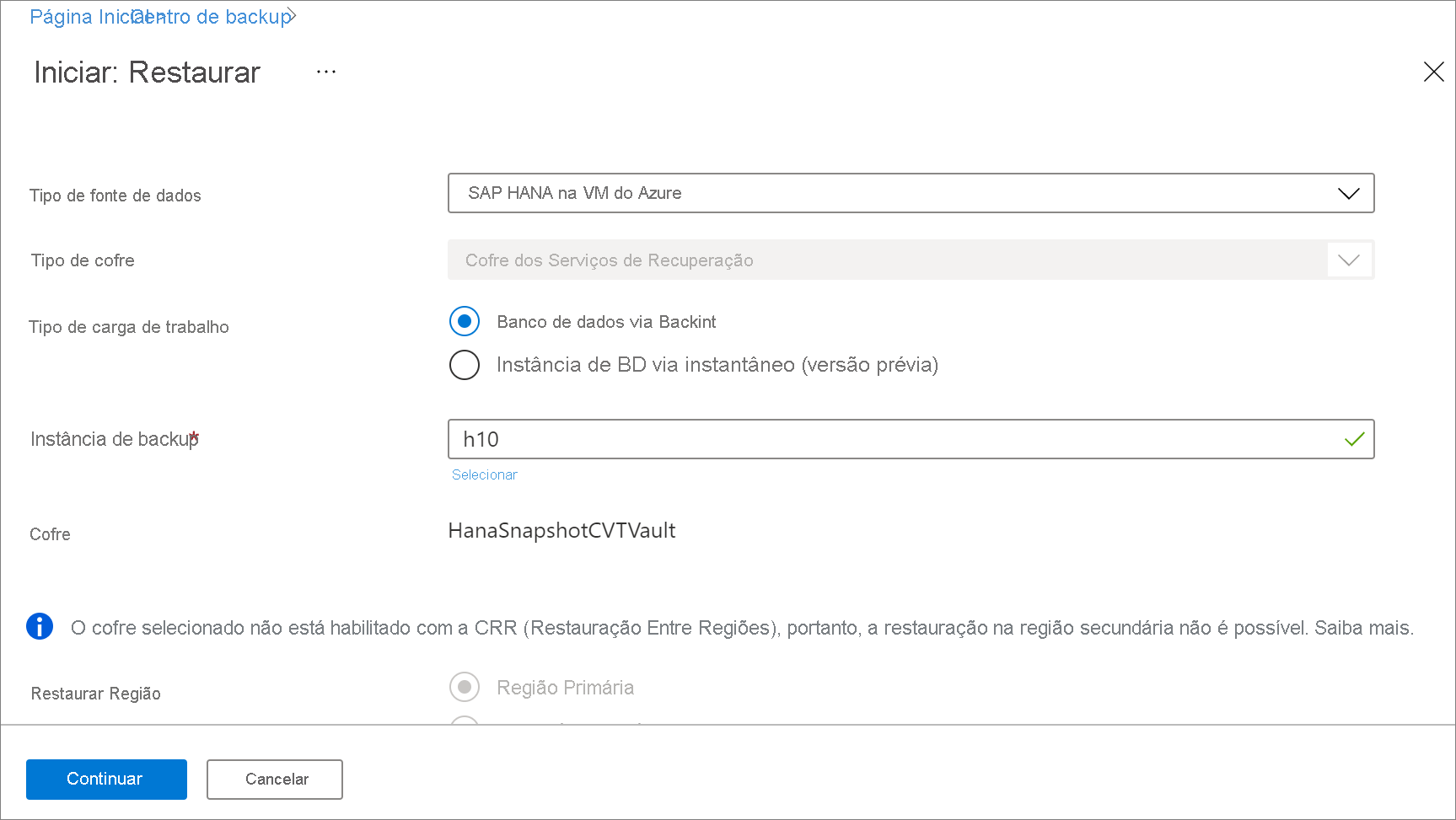
Em Restaurar Configuração, especifique onde ou como restaurar os dados:
- Local alternativo: restaure o banco de dados em um local alternativo e mantenha o banco de dados de origem original.
- Substituir Banco de Dados: restaure os dados para a mesma instância SAP HANA que a fonte original. Essa opção substitui o banco de dados original.

Observação
Durante a restauração (aplicável apenas ao cenário de IP virtual/IP de front-end do balanceador de carga), se você estiver tentando restaurar um backup para o nó de destino depois de alterar o modo HSR como autônomo ou interromper o HSR antes da restauração, conforme recomendado pelo SAP, certifique-se de que o Load Balancer esteja apontado para o nó de destino.
Cenários de exemplo:
- Se você estiver usando hdbuserstore set SYSTEMKEY localhost no script de pré-registro, não haverá problemas durante a restauração.
- Se o *hdbuserstore definir
SYSTEMKEY <load balancer host/ip>no script de pré-registro e você estiver tentando restaurar o backup para o nó de destino, verifique se o balanceador de carga está apontado para o nó de destino que precisa ser restaurado.
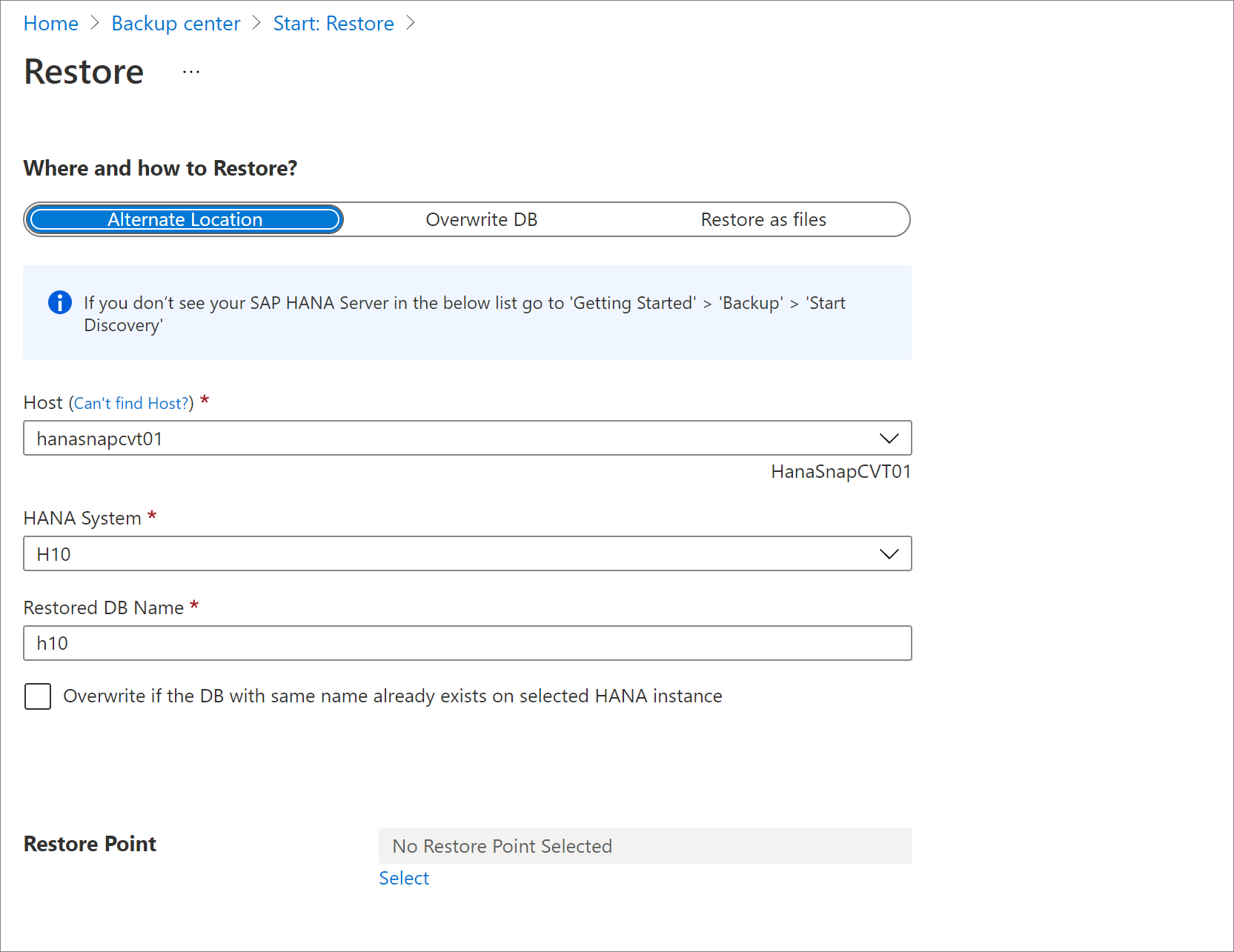
Restaurar para um local alternativo
No painel Restaurar, em Onde e como restaurar?, selecione Local Alternativo.
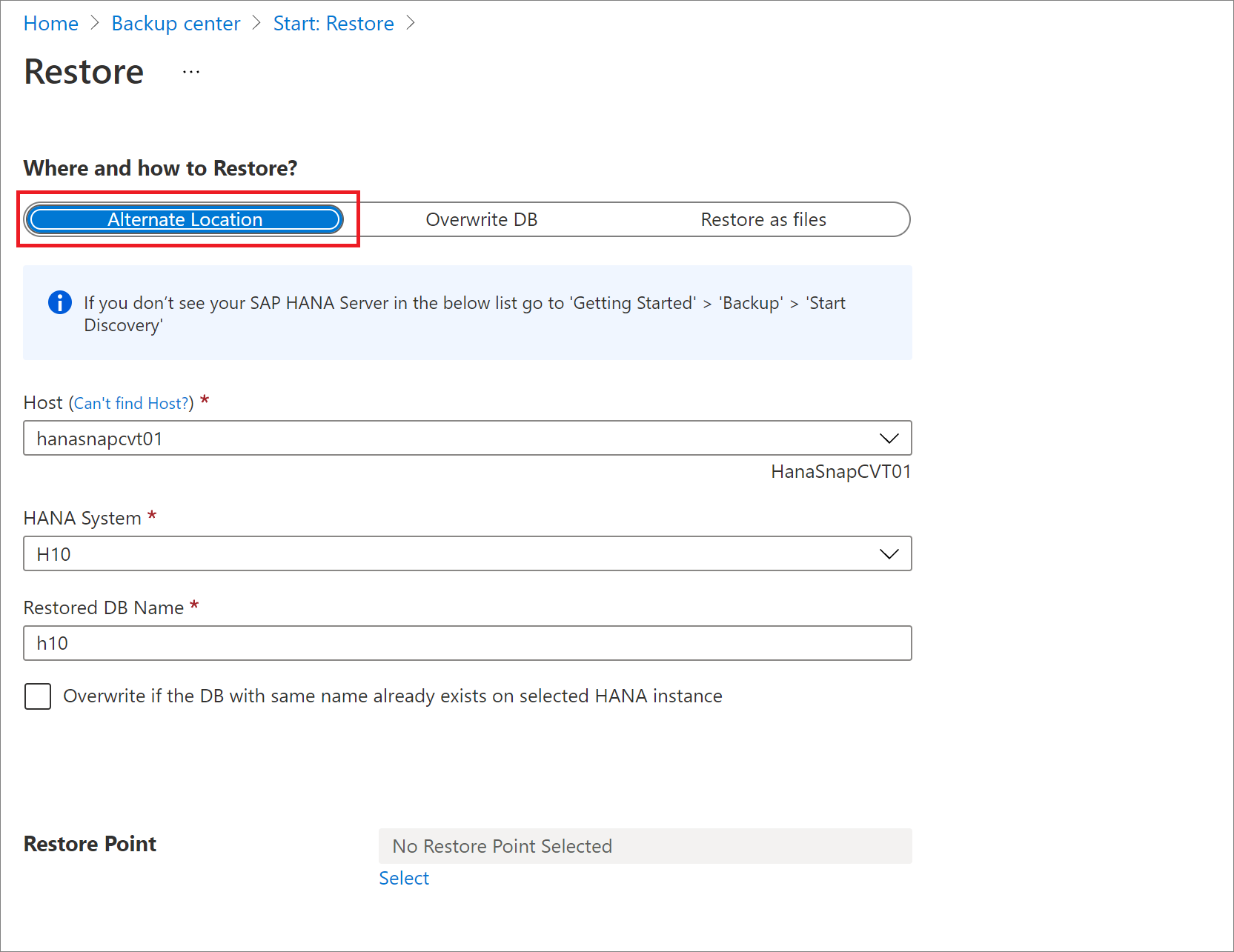
Selecione o nome do host do SAP HANA e o nome da instância na qual você deseja restaurar o banco de dados.
Verifique se a instância do SAP HANA de destino está pronta para ser restaurada verificando a preparação para backup. Para obter mais informações, veja Pré-requisitos.
Na caixa Nome do Banco de Dados Restaurado, digite o nome do banco de dados de destino.
Observação
As restaurações de SDC (contêiner de Banco de Dados Individual) devem seguir estas verificações.
Se aplicável, marque a caixa de seleção Substituir se um BD com o mesmo nome já existir na instância do HANA selecionada.
Em Selecionar ponto de restauração, selecione Logs (Ponto no Tempo) para restaurar para um ponto específico no tempo. Ou escolha Completo e diferencial para restaurar a um ponto de recuperação específico.
Restaurar como arquivos
Observação
A opção Restaurar como arquivos não funciona em compartilhamentos CIFS (Common Internet File System), mas funciona para o NFS (Sistema de Arquivos de Rede).
Para restaurar os dados de backup como arquivos, não como um banco de dados, escolha Restaurar como Arquivos. Depois que os arquivos são despejados em um caminho especificado, você pode colocá-los em qualquer computador SAP HANA em que queira restaurá-los como um banco de dados. Como você pode mover esses arquivos para qualquer computador, agora é possível restaurar os dados entre assinaturas e regiões.
No painel Restaurar, em Onde e como restaurar?, selecione Restaurar como arquivos.
Selecione o nome do host ou do servidor HANA em que você deseja restaurar os arquivos de backup.
Na caixa Caminho de destino no servidor, insira o caminho da pasta no servidor selecionado na etapa anterior. Esse é o local onde o serviço irá despejar todos os arquivos de backup necessários.
Os arquivos a serem despejados são:
- Arquivos de backup de banco de dados
- Arquivos de metadados JSON (para cada arquivo de backup envolvido)
Geralmente, um caminho de compartilhamento de rede (ou caminho de um compartilhamento de arquivo do Azure montado quando especificado como o caminho de destino) permite o acesso mais fácil a esses arquivos por outros computadores na mesma rede ou com o mesmo compartilhamento de arquivo do Azure montado neles.
Observação
Para restaurar os arquivos de backup de banco de dados em um compartilhamento de arquivo do Azure montado na VM registrada de destino, verifique se a conta raiz tem permissões de leitura/gravação no compartilhamento.
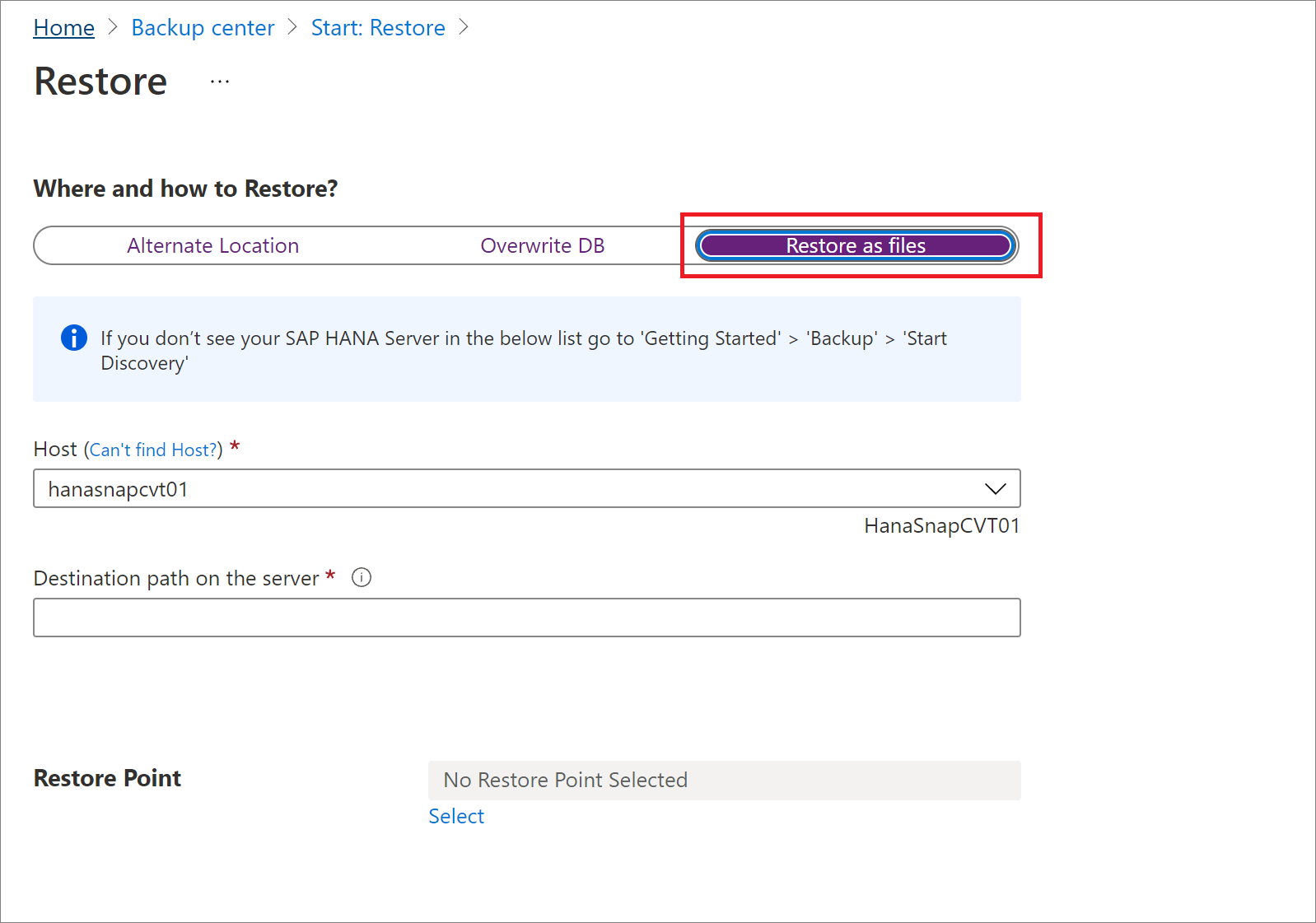
Selecione o Ponto de Restauração em que todos os arquivos e pastas de backup serão restaurados.
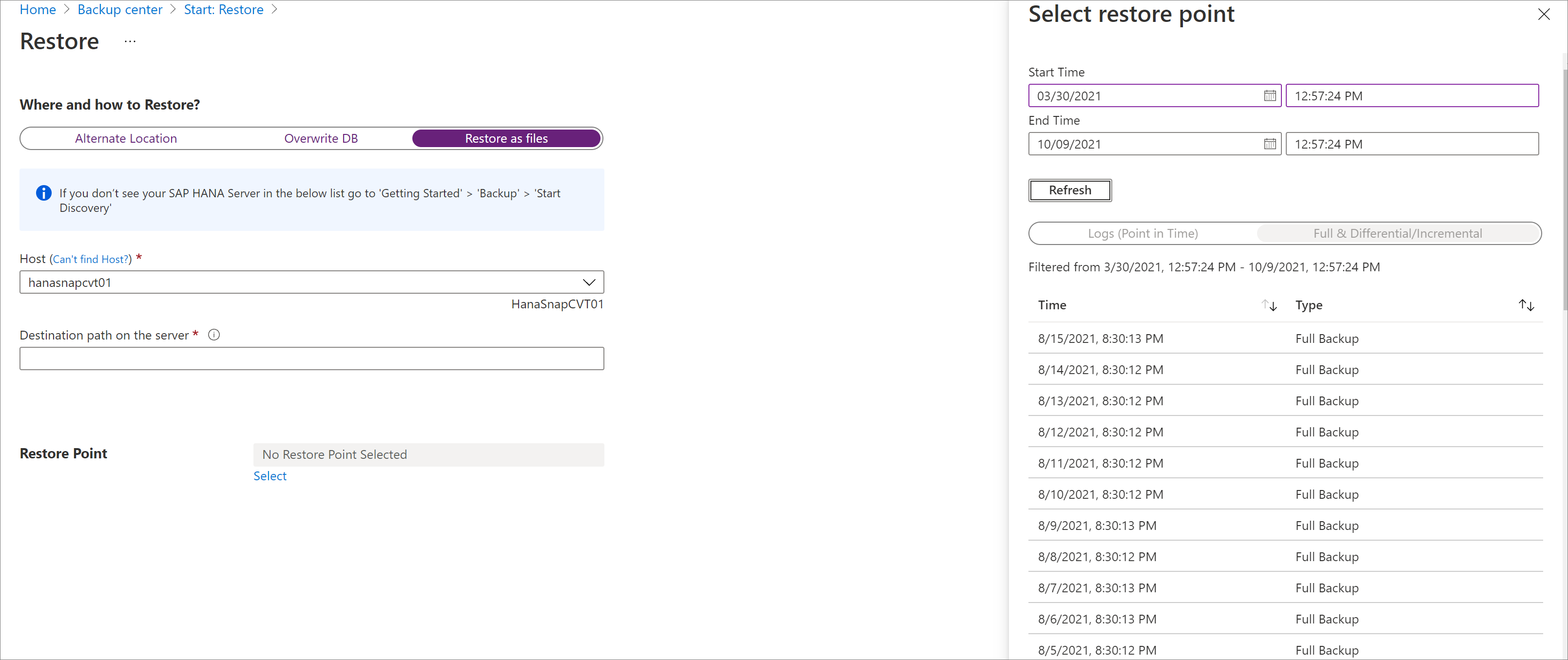
Todos os arquivos de backup associados ao ponto de restauração selecionado são despejados no caminho de destino.
Dependendo do tipo de ponto de restauração escolhido (Ponto no tempo ou Completo e Diferencial), você verá uma ou mais pastas serem criadas no caminho de destino. Uma das pastas, Data_<date and time of restore>, contém os backups completos e a outra pasta, Log, contém os backups de log e outros backups (como diferenciais e incrementais).
Observação
Se você selecionou Restaurar em um ponto no tempo, os arquivos de log (despejados na VM de destino) poderão conter logs além do ponto no tempo escolhido para restauração. O Backup do Azure faz isso para garantir que os backups de log de todos os serviços do HANA estejam disponíveis para restauração consistente e bem-sucedida no ponto no tempo escolhido.
Mova esses arquivos restaurados para o servidor SAP HANA no qual você deseja restaurá-los como um banco de dados e faça o seguinte:
um. Defina permissões na pasta ou no diretório em que os arquivos de backup são armazenados executando o seguinte comando:
chown -R <SID>adm:sapsys <directory>b. Execute o próximo conjunto de comandos como
<SID>adm:su: <sid>admc. Gere o arquivo de catálogo para restauração. Extraia a BackupId do arquivo de metadados JSON do backup completo, que será usado depois na operação de restauração. Verifique se os backups completo e de log (não presentes na recuperação de backup completo) estão em pastas diferentes e exclua os arquivos de metadados JSON dessas pastas. Execute:
hdbbackupdiag --generate --dataDir <DataFileDir> --logDirs <LogFilesDir> -d <PathToPlaceCatalogFile>-
<DataFileDir>: a pasta que contém os backups completos. -
<LogFilesDir>: a pasta que contém os backups de log, bem como os backups diferenciais e incrementais. Para Restauração completa de back-up, como a pasta de log não foi criada, adicione um diretório vazio. -
<PathToPlaceCatalogFile>: a pasta na qual o arquivo de catálogo gerado precisa ser colocado.
d. Você pode restaurar usando o arquivo do catálogo recém-gerado por meio do HANA Studio ou executar a consulta de restauração da ferramenta SAP HANA HDBSQL com esse catálogo recém-gerado. As consultas do HDBSQL estão listadas aqui:
Para abrir o prompt do HDBSQL, execute o seguinte comando:
hdbsql -U AZUREWLBACKUPHANAUSER -d systemDBPara restaurar para um momento determinado:
Se você estiver criando um banco de dados restaurado, execute o comando do HDBSQL para criar um banco de dados
<DatabaseName>e interrompa o banco de dados para restauração usando o comandoALTER SYSTEM STOP DATABASE <db> IMMEDIATE. No entanto, se você estiver restaurando apenas um banco de dados existente, execute o comando do HDBSQL para interromper o banco de dados.Em seguida, execute o seguinte comando para restaurar o banco de dados:
RECOVER DATABASE FOR <db> UNTIL TIMESTAMP <t1> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> USING BACKUP_ID <bkId> CHECK ACCESS USING FILE-
<DatabaseName>: o nome do novo banco de dados ou do banco de dados existente que você quer restaurar. -
<Timestamp>: o carimbo de data/hora exato da restauração pontual. -
<DatabaseName@HostName>: o nome do banco de dados cujo backup é usado para restauração e o nome do servidor host ou do SAP HANA em que esse banco de dados reside. A opçãoUSING SOURCE <DatabaseName@HostName>especifica que o backup de dados (usado para restauração) é de um banco de dados com um SID ou nome diferente do computador de SAP HANA de destino. Isso não precisa ser especificado para restaurações feitas no mesmo servidor HANA cujo backup é feito. -
<PathToGeneratedCatalogInStep3>: o caminho para o arquivo de catálogo gerado na "Etapa C". -
<DataFileDir>: a pasta que contém os backups completos. -
<LogFilesDir>: a pasta que contém os backups de log, bem como os backups diferenciais e incrementais (caso haja). -
<BackupIdFromJsonFile>: a BackupId que foi extraída na "Etapa C".
-
Para restaurar para um backup completo ou diferencial específico:
Se você estiver criando um banco de dados restaurado, execute o comando do HDBSQL para criar um banco de dados
<DatabaseName>e interrompa o banco de dados para restauração usando o comandoALTER SYSTEM STOP DATABASE <db> IMMEDIATE. No entanto, se você estiver restaurando apenas um banco de dados existente, execute o comando do HDBSQL para interromper o banco de dados:RECOVER DATA FOR <DatabaseName> USING BACKUP_ID <BackupIdFromJsonFile> USING SOURCE '<DatabaseName@HostName>' USING CATALOG PATH ('<PathToGeneratedCatalogInStep3>') USING DATA PATH ('<DataFileDir>') CLEAR LOG-
<DatabaseName>: o nome do novo banco de dados ou do banco de dados existente que você quer restaurar. -
<Timestamp>: o carimbo de data/hora exato da restauração pontual. -
<DatabaseName@HostName>: o nome do banco de dados cujo backup é usado para restauração e o nome do servidor host ou do SAP HANA em que esse banco de dados reside. A opçãoUSING SOURCE <DatabaseName@HostName>especifica que o backup de dados (usado para restauração) é de um banco de dados com um SID ou nome diferente do computador de SAP HANA de destino. Portanto, isso não precisa ser especificado para restaurações feitas no mesmo servidor HANA do qual o backup é feito. -
<PathToGeneratedCatalogInStep3>: o caminho para o arquivo de catálogo gerado na "Etapa C". -
<DataFileDir>: a pasta que contém os backups completos. -
<LogFilesDir>: a pasta que contém os backups de log, bem como os backups diferenciais e incrementais (caso haja). -
<BackupIdFromJsonFile>: a BackupId que foi extraída na "Etapa C".
-
Para fazer a restauração usando uma ID de backup:
RECOVER DATA FOR <db> USING BACKUP_ID <bkId> USING CATALOG PATH <path> USING LOG PATH <path> USING DATA PATH <path> CHECK ACCESS USING FILEExemplos:
Restauração do sistema SAP HANA no mesmo servidor:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILERestauração do locatário do SAP HANA no mesmo servidor:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILERestauração do sistema SAP HANA em outro servidor:
RECOVER DATABASE FOR SYSTEM UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILERestauração do locatário do SAP HANA em outro servidor:
RECOVER DATABASE FOR DHI UNTIL TIMESTAMP '2022-01-12T08:51:54.023' USING SOURCE <sourceSID> USING CATALOG PATH ('/restore/catalo_gen') USING LOG PATH ('/restore/Log/') USING DATA PATH ('/restore/Data_2022-01-12_08-51-54/') USING BACKUP_ID 1641977514020 CHECK ACCESS USING FILE
-

Restauração parcial como arquivos
O serviço Backup do Azure decide a cadeia de arquivos a ser baixada durante a restauração como arquivos. Mas há cenários em que talvez você não queira baixar todo o conteúdo novamente.
Por exemplo, talvez você já tenha uma política de backups completos semanais, diferenciais diários e de logs, e já tenha baixado arquivos de um backup diferencial específico. Você descobriu que esse não é o ponto de recuperação certo e decidiu baixar o diferencial do dia seguinte. Agora você só precisa do arquivo diferencial, pois já tem o backup completo inicial. Com a capacidade de restauração parcial como arquivos, fornecida pelo Backup do Azure, agora você pode excluir o backup completo da cadeia de download e baixar apenas o backup diferencial.
Excluindo tipos de arquivo de backup
O ExtensionSettingOverrides.json é um arquivo JSON (JavaScript Object Notation), que contém substituições para várias configurações do serviço Backup do Azure para SQL. Para uma operação de restauração parcial como arquivos, você precisa adicionar um novo campo JSON, RecoveryPointsToBeExcludedForRestoreAsFiles. Esse campo contém um valor de cadeia de caracteres que indica quais tipos de ponto de recuperação devem ser excluídos na próxima operação de restauração como arquivos.
No computador de destino em que os arquivos devem ser baixados, acesse a pasta opt/msawb/bin.
Crie um arquivo JSON chamado ExtensionSettingOverrides.JSON, se ele ainda não existir.
Adicione o seguinte par de valores de chave JSON:
{ "RecoveryPointsToBeExcludedForRestoreAsFiles": "ExcludeFull" }Altere as permissões e a propriedade do arquivo:
chmod 750 ExtensionSettingsOverrides.json chown root:msawb ExtensionSettingsOverrides.jsonNão é necessário reiniciar nenhum serviço. O serviço Backup do Azure tentará excluir os tipos de backup na cadeia de restauração, conforme mencionado neste arquivo.
O RecoveryPointsToBeExcludedForRestoreAsFiles só usa valores específicos que denotam os pontos de recuperação a serem excluídos durante a restauração. Para o SAP HANA, esses valores são:
-
ExcludeFull. Outros tipos de backup, como diferencial, incremental e de logs, serão baixados se estiverem presentes na cadeia de pontos de restauração. -
ExcludeFullAndDifferential. Outros tipos de backup, como incremental e de logs, serão baixados se estiverem presentes na cadeia de pontos de restauração. -
ExcludeFullAndIncremental. Outros tipos de backup, como diferencial e de logs, serão baixados se estiverem presentes na cadeia de pontos de restauração. -
ExcludeFullAndDifferentialAndIncremental. Outros tipos de backup, como backups de logs, serão baixados se estiverem presentes na cadeia de pontos de restauração.
Restaurar a um ponto específico no tempo
Se você tiver selecionado Logs (Pontual) como o tipo de restauração, faça o seguinte:
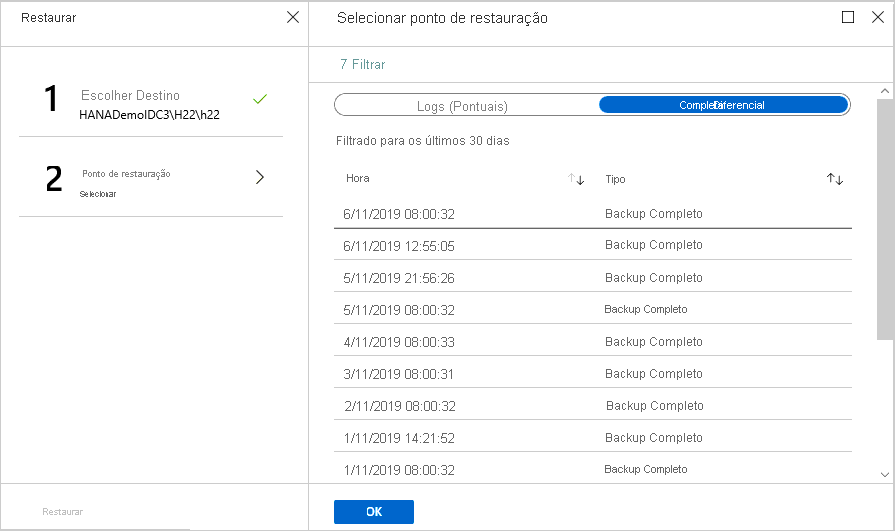
Selecione um ponto de recuperação no grafo de log e clique em OK para escolher o ponto de restauração.
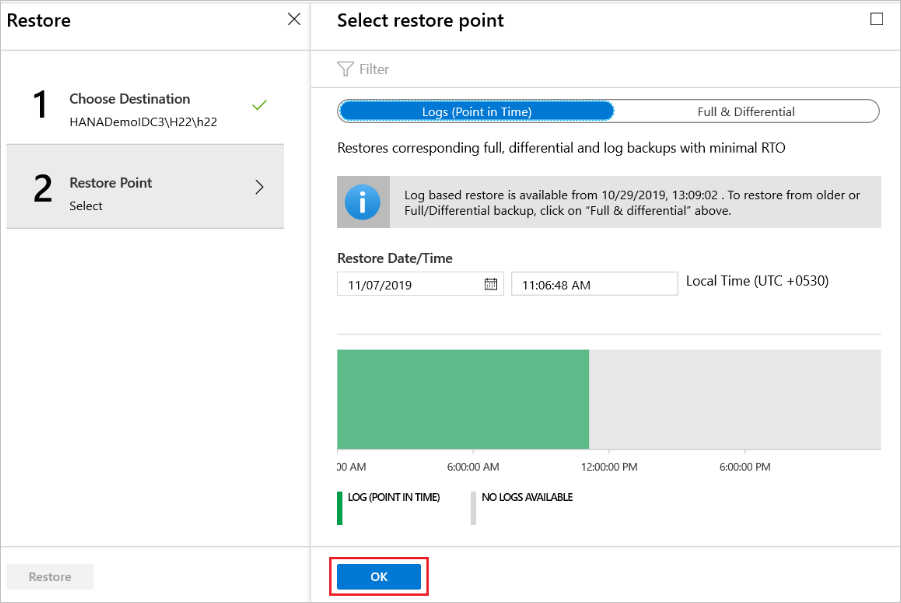
No menu Restaurar, selecione Restaurar para iniciar o trabalho de restauração.
Acompanhe o progresso da restauração na área Notificações ou selecionando Trabalhos de restauração no menu de banco de dados.

Restaurar para um ponto de recuperação específico
Se você tiver selecionado Completo e Diferencial como o tipo de restauração, faça o seguinte:
Selecione um ponto de recuperação na lista e clique em OK para escolher o ponto de restauração.
No menu Restaurar, selecione Restaurar para iniciar o trabalho de restauração.
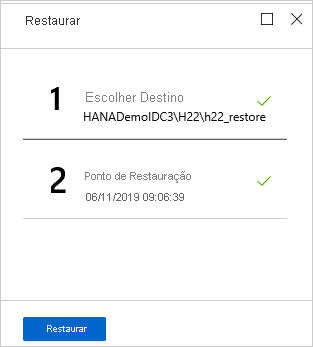
Acompanhe o progresso da restauração na área Notificações ou selecionando Trabalhos de restauração no menu de banco de dados.

Observação
Em restaurações de MDC (banco de dados de vários contêineres) depois que o banco de dados do sistema é restaurado em uma instância de destino, é necessário executar o script de pré-registro novamente. Depois, as próximas restaurações do banco de bancos de locatário serão realizadas com sucesso. Para saber mais, confira Solucionar problemas de restauração de banco de dados de vários contêineres.
Restauração Entre Regiões
Como uma das opções de restauração, a CRR (restauração entre regiões) permite que você restaure bancos de dados SAP HANA hospedados em VMs do Azure em uma região secundária, que é uma região emparelhada do Azure.
Para começar a usar o recurso, confira Definir a restauração entre regiões.
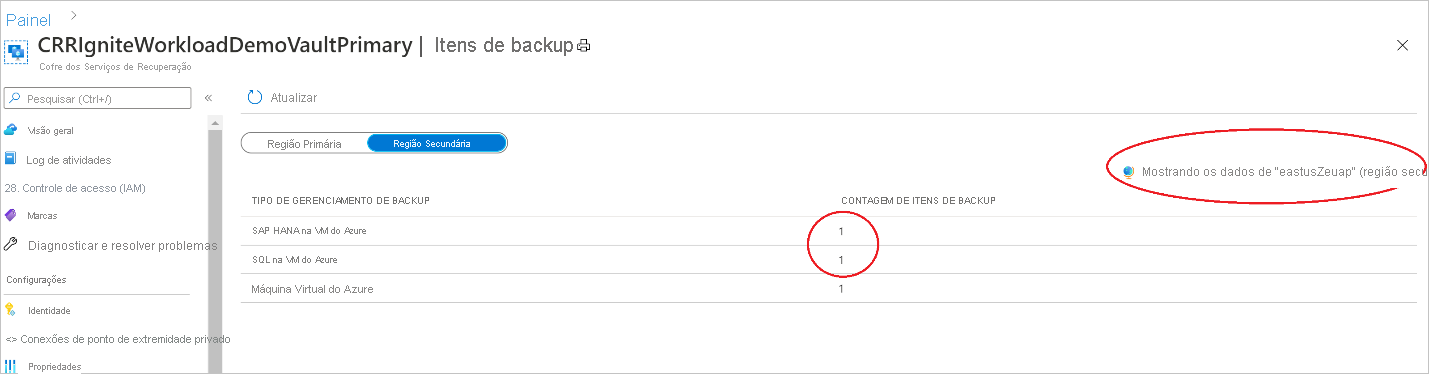
Exibir itens de backup na região secundária
Se a CRR estiver habilitada, você poderá exibir os itens de backup na região secundária.
- No portal do Azure, acesse Cofre dos Serviços de Recuperação e selecione Itens de backup.
- Selecione Região secundária para exibir os itens na região secundária.
Observação
Somente os tipos de gerenciamento de backup compatíveis com o recurso CRR serão mostrados na lista. Atualmente, é permitido somente o suporte para a restauração de dados de região secundária em uma região secundária.
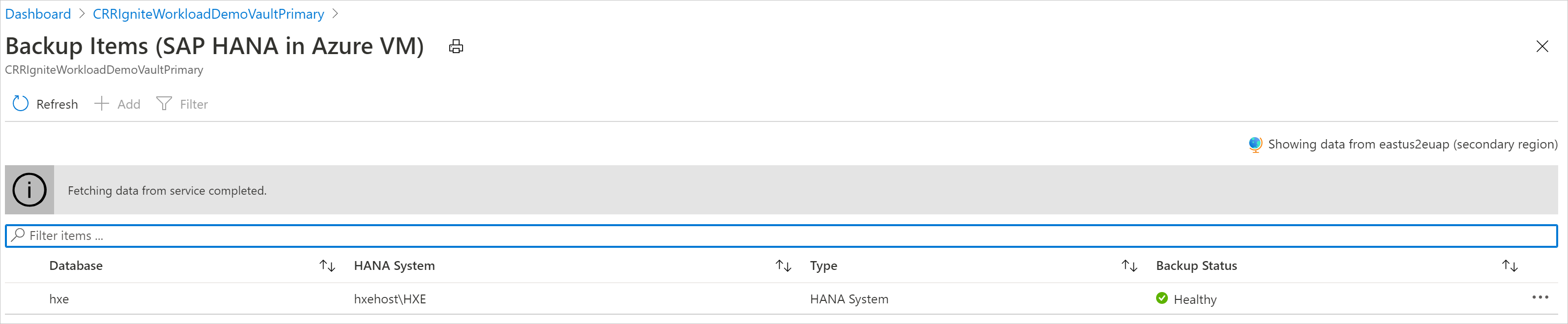
Restaurar na região secundária
A experiência do usuário de restauração na região secundária é semelhante à experiência do usuário de restauração na região primária. Quando você configurar os detalhes no painel Configuração de Restauração, precisará fornecer somente os parâmetros da região secundária. Deve haver um cofre na região secundária e o servidor SAP HANA deve estar registrado nele.
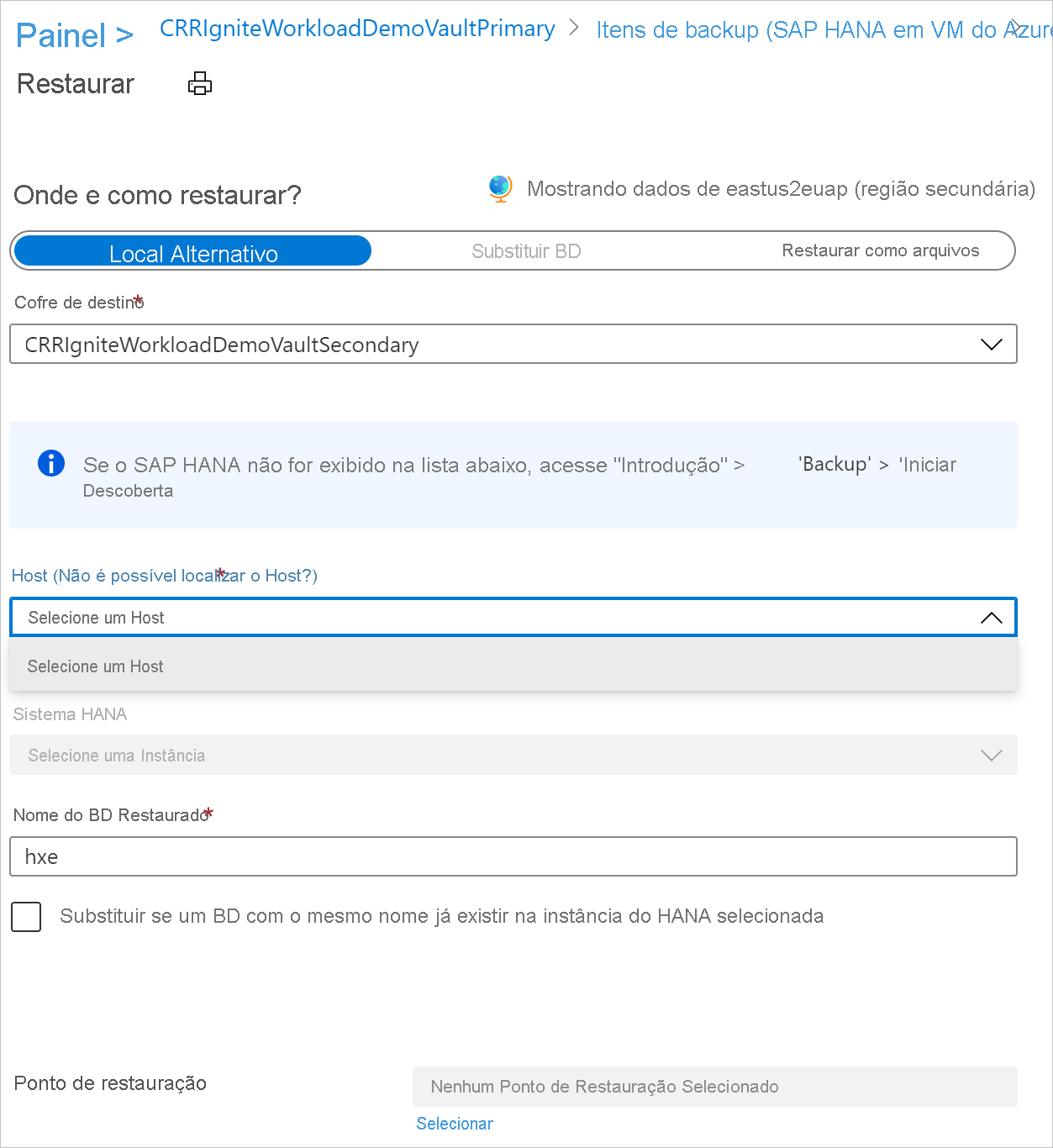
Observação
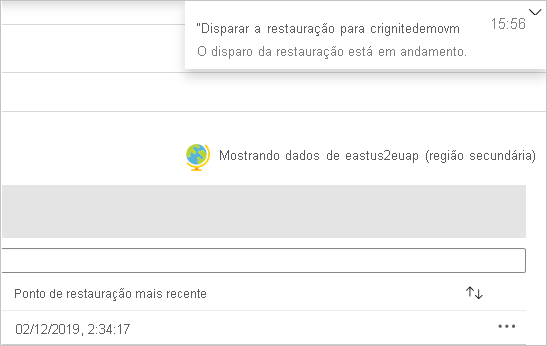
- Depois que a restauração é disparada e está na fase de transferência de dados, o trabalho de restauração não pode ser cancelado.
- O nível de função e de acesso necessário para executar uma operação de restauração entre regiões são a função Operador de Backup na assinatura e o acesso de Colaborador (gravação) nas máquinas virtuais de origem e de destino. Para ver os trabalhos de backup, Leitor de backup é a permissão mínima necessária na assinatura.
- O RPO (objetivo de ponto de recuperação) para que os dados de backup estejam disponíveis na região secundária é de 12 horas. Portanto, quando você ativa o CRR, o RPO da região secundária é de 12 horas + a duração de frequência de log (que pode ser definida para o mínimo de 15 minutos).
Saiba mais sobre os requisitos mínimos de função para restauração entre regiões.
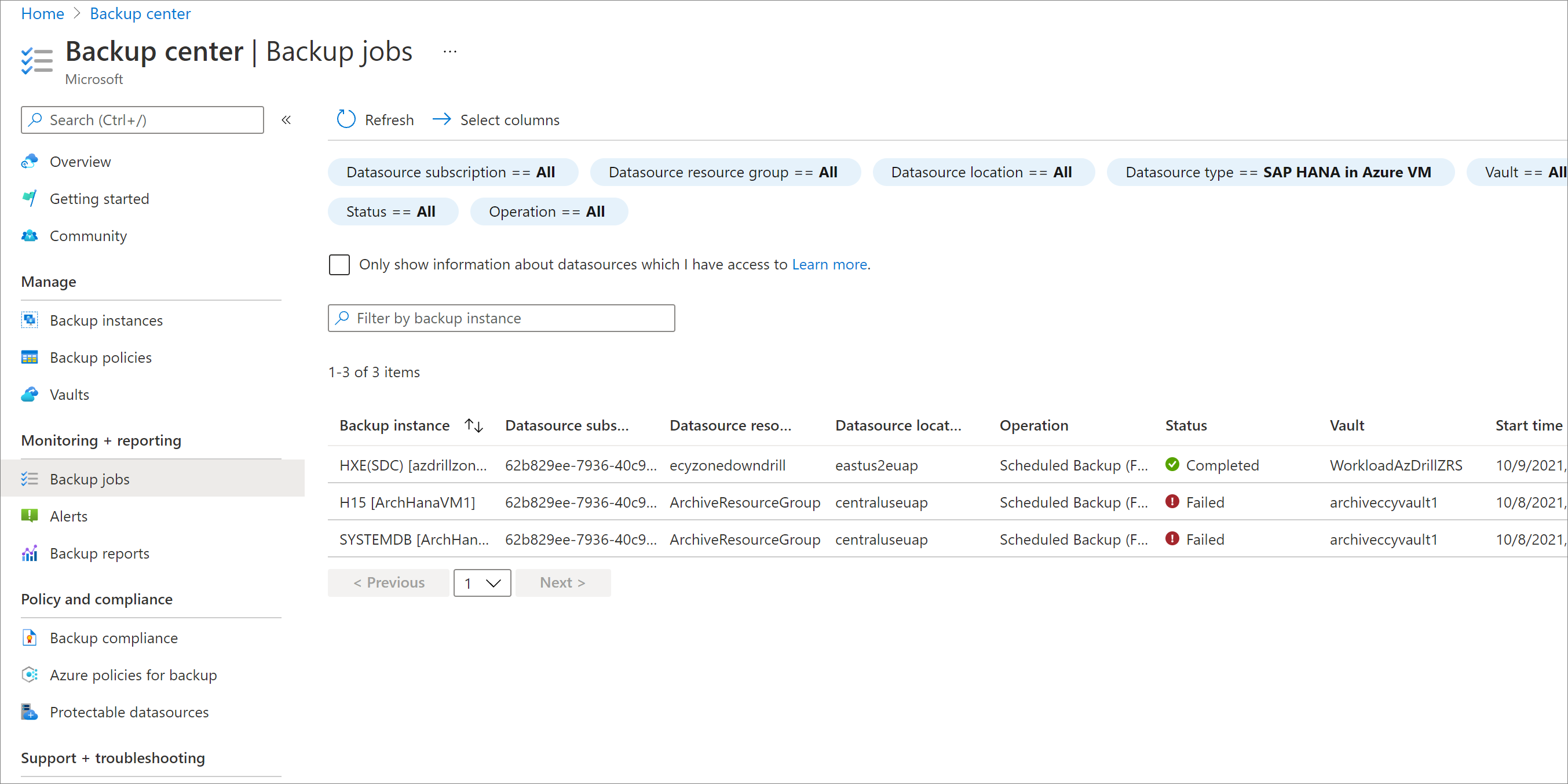
Monitorar os trabalhos de restauração na região secundária
No portal do Azure, acesse o Centro de backup e clique em Trabalhos de Backup.
Para ver os trabalhos na região secundária, filtre a operação para CrossRegionRestore.

Restauração Entre Assinaturas
O Backup do Azure agora permite que você restaure o banco de dados SAP HANA para qualquer assinatura (de acordo com os seguintes requisitos do RBAC do Azure) a partir do ponto de restauração. Por padrão, o Backup do Azure restaura para a mesma assinatura em que os pontos de restauração estão disponíveis.
Com a Restauração Entre Assinaturas (CSR), você tem a flexibilidade de restaurar para qualquer assinatura e qualquer cofre do seu locatário, se as permissões de restauração estiverem disponíveis. Por padrão, a CSR está habilitada em todos os cofres dos Serviços de Recuperação (cofres existentes e recém-criados).
Observação
- Você pode acionar a Restauração de Várias Assinaturas a partir do cofre dos Serviços de Recuperação.
- A CSR tem suporte apenas para backups baseados em fluxo/Backint e não tem suporte para backups baseados em instantâneos.
- Não há suporte para Restauração Entre Regiões (CRR) com CSR.
Restauração Entre Assinaturas para um cofre habilitado para Ponto de Extremidade Privado
Para executar a Restauração Entre Assinaturas em um cofre habilitado para Ponto de Extremidade Privado:
- No cofre dos Serviços de Recuperação de origem, acesse a guia Rede.
- Acesse a seção Acesso privado e crie Pontos de Extremidade Privados.
- Selecione a assinatura do cofre de destino que você quer restaurar.
- Na seção Rede Virtual, selecione a VNet da VM de destino que você quer restaurar na assinatura.
- Crie o Ponto de Extremidade Privado e dispare o processo de restauração.
Requisitos do RBAC do Azure
| Tipo de operação | Operador de backup | Cofre dos Serviços de Recuperação | Operador alternativo |
|---|---|---|---|
| Restaurar o banco de dados ou restaurar como arquivos | Virtual Machine Contributor |
VM de origem que foi submetida a backup | Em vez de uma função integrada, você pode pensar em uma função personalizada que tenha as seguintes permissões: - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
Virtual Machine Contributor |
VM de destino em que o banco de dados será restaurado ou os arquivos serão criados. | Em vez de uma função interna, você pode pensar em uma função personalizada com as seguintes permissões: - Microsoft.Compute/virtualMachines/write - Microsoft.Compute/virtualMachines/read |
|
Backup Operator |
Cofre dos Serviços de Recuperação do Destino |
Por padrão, o CSR está habilitado no cofre dos Serviços de Recuperação. Para atualizar as configurações de restauração do cofre dos Serviços de Recuperação, acesse Propriedades>Restauração Entre Assinaturas e faça as alterações necessárias.

Restauração Entre Assinaturas usando a CLI do Azure
az backup vault create
Adicione o parâmetro cross-subscription-restore-state, que permite que você configure o estado da CSR do cofre durante a criação e atualização do cofre.
az backup recoveryconfig show
Adicione o parâmetro --target-subscription-id, que permite que você forneça a assinatura visada como uma entrada ao acionar a Restauração de Várias Assinaturas para recursos de dados do SQL ou do HANA.
Exemplo:
az backup vault create -g {rg_name} -n {vault_name} -l {location} --cross-subscription-restore-state Disable
az backup recoveryconfig show --restore-mode alternateworkloadrestore --backup-management-type azureworkload -r {rp} --target-container-name {target_container} --target-item-name {target_item} --target-resource-group {target_rg} --target-server-name {target_server} --target-server-type SQLInstance --target-subscription-id {target_subscription} --target-vault-name {target_vault} --workload-type SQLDataBase --ids {source_item_id}